概述
四大特点:大量化、快速化、多元化、价值化
关键技术:采集、存储管理、处理分析、隐私和安全
计算模式:批处理、流、图、查询分析计算
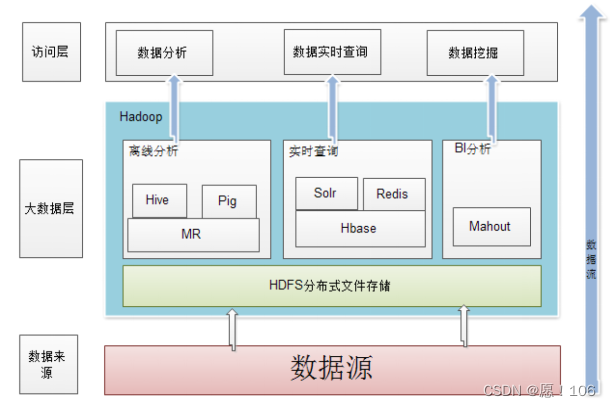
Hadoop处理架构
了解就好
- 2007年,雅虎在Sunnyvale总部建立了M45——一个包含了4000个处理器和1.5PB容量的Hadoop集群系统

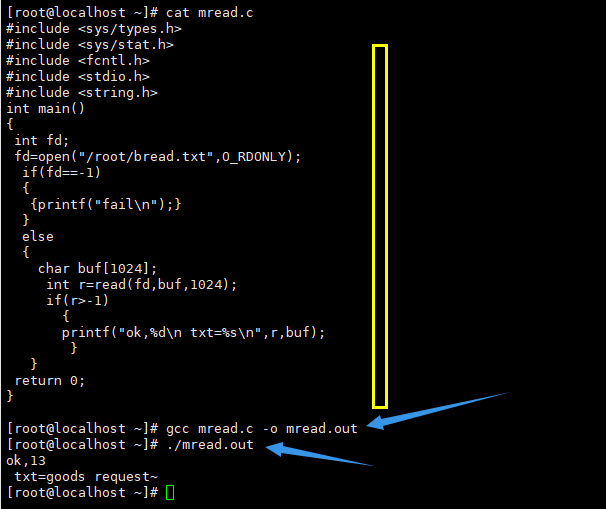
启动haoop: Start-all.sh
查看状态: jps
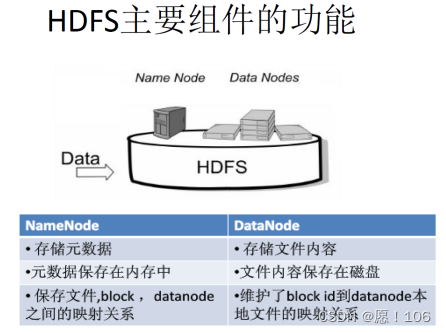
NameNod:负责协调数据存储
DataNod:存储被拆分的数据块
JobTracker:协调计算
TaskTracker:负责完成JobTrack的计算
SecondaryNameNod 帮助NameNod收集系统运行数据
Hadoop特点:
-
高可靠性
-
高效性
-
高可扩展性
-
高容错性
-
成本低
-
运行在Linux平台上
-
支持多种编程语言
HDFS
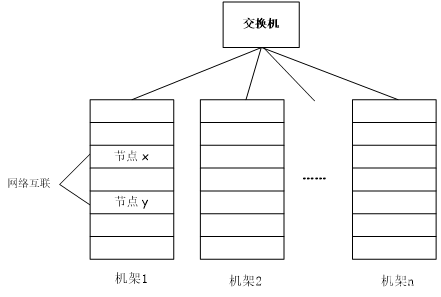
计算机集群结构
分布式文件系统把文件存储在多个计算机节点上、所有的计算机节点构成一个集群
相比多个处理器和专用高级硬件的并行化处理装置 大大降低的成本开销
图无需记忆,仅仅帮助理解
分布式文件系统的结构
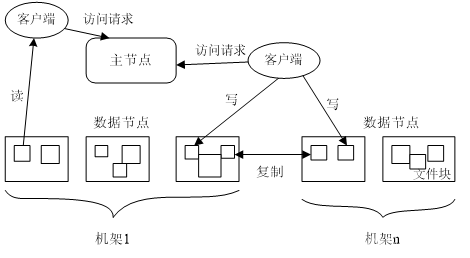
由: MasterNode NameNode SlaveNode DataNode构成
图无需记忆,仅仅帮助理解
HDFS实现目标:
-
廉价设备
流数据读写
大数据集
简单文件模型
跨平台
HDFS 局限:
无法 多用户写入和修改任意文件
不适 低延迟数据访问
很难高效存储打大量小文件
HDFS默认一个块64MB
寻址方式:
从NameNode中找到构成目标文件的数据快的位置列表、从位置列表中得到存储各数据块的数据节点位置,数据节点找到文件返回给客户端
HDFS采用抽象数据块好处
-
支持大规模文件存储
一个大文件会被拆分成小文件分发到各个节点、所以文件大小不受单个节点影响
简化系统设计
适合数据备份
每个文件都可以冗余存储到各个节点、提高了容错性
三个副本如何存储
第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
第二个副本:放置在与第一个副本不同的机架的节点上
第三个副本:与第一个副本相同机架的其他节点上
更多副本:随机节点
NameNod & DataNode
FsImage
-
维护整个系统的所有目录和文件信息
-
保存了最新的元数据检查点、包含了整个系统的所有目录和文件信息(扩展)
EditLog
- 存储了对所有文件 操作(编辑、删除、添加……) 的日志
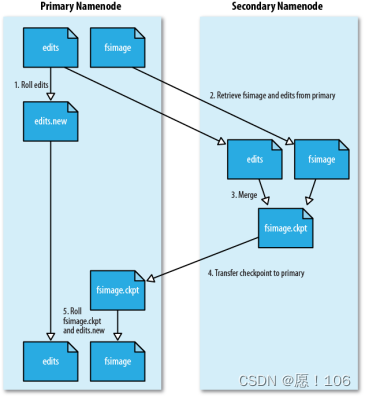
FsImage EditLog 的备份(其备份在secondaryNamenode上)
-
NameNode暂停使用EditLog,创建 EditLong.new.
-
secondaryNamenode 获取到NameNode上的fsimage 和 editlog(通过get方式)
-
secondaryNamenode 将fsimage存入内存,一条一条执行editlog中的更新操作,将fsimage和editlog合并
-
SecondaryNameNode 通过(post方式)将 Fsimage发送到 NameNode上
-
Namenode 用Editlog.new 替代 Editlog
数据节点出错
-
每个数据节点会定期的向NameNode发送“心跳”(报告自己的状态)
-
当数据节点出错,“心跳”将停止、这时数据节点就会被标记为“宕机”,NameNode将不再向该节点发送任何I/O
-
由于数据节点不可用可能会出现数据块的副本数量小于****冗余因子****
-
当系统检测到莫数据节点出现 3.这种情况,就会为该节点生成新的副本
建议看视频:15分钟左右
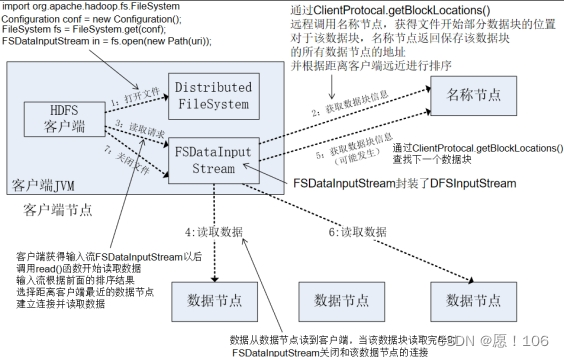
读数据的过程
和寻址方式有一定 类似
重要
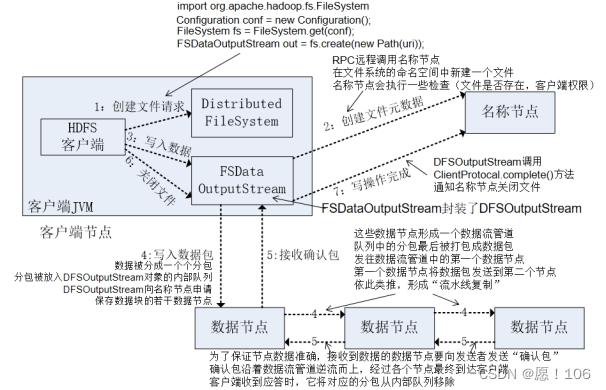
写数据的过程
HDFS常用命名
建议命名头使用 hadoop fs
运用
Hdfs dfs -ls <指定路径>
显示指定路径的所有文件
Hdfs dfs -madir <指定路径>
创建指定路径下的指定name的文件夹
…… -put <本地文件> <目标位置>
…… -get <目标文件> <指定位置>
复制文件到本地文件系统
hadoop fs -copyFromLocal <localsrc> <dst>
将本地源文件<localsrc>复制到路径<dst>指定的文件或文件夹中
…… -cat <指定文件>
查看指定文件
MapReduce
-
MapReduce将计算过程抽象到了两个函数:Map和Reduce
-
MapReduce采用“分而治之”策略,将大量数据分割成片,这些片可以被map处理
-
MapReduce计算向数据靠拢因为: 移动数据需要大量网络传输开销
-
I MapReduce 采用Master/slave 架构,及一master和若干slave。
- Master上运行JobTracker,slave上运行TaskTracker
- JobTracker:协调计算
- TaskTracker:负责完成JobTrack的计算
Habse
Habse是对bigtable的实现

Habse是一个稀疏、多维、排序的映射表。根据行键排序
表的索引是行键、列族、列限定符、时间戳确定
Habse存储的是 字符串,没有数据类型
更新操作时不会删除旧的版本(总版本数达到建立表时所设立的版本数时会删除最旧的版本)
habse功能组件
- 库函数
- 一个Master主服务器
- 许多region(区域、分区)服务器
region服务器:存储和维护Master服务器分配给自己region、处理客户端请求
Master服务器:管理维护Habse表分区信息、维护region队列、分配region、维持整体Habse
region
-
一个region 1G-2G
-
同一个Region不会被拆分到多个Region服务器上
-
每个Region服务器可以有10-1000Region及 10G–1T
region定位
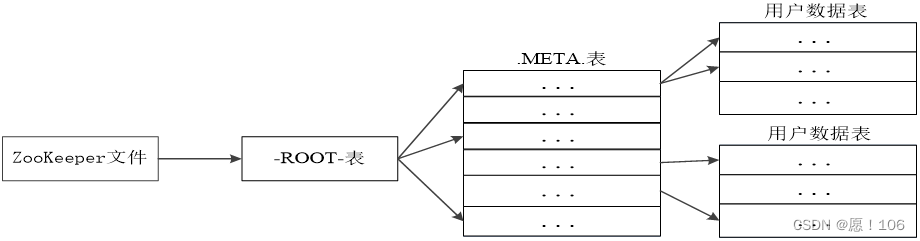
原数组表(META表)存放region和region服务器的映射关系
当数据Habse表过大时,META也会被分成多个region
Root表记录元数据的具体位置,其只有一个region
zookeepre记录root表位置
- HBase有三层结构
计算方式
假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为128MB,那么,上面的三层结构可以保存的用户数据表的Region数目的计算方法是:
root最多有 128MB/1kB = 2^17行
每个mate最大只有 128MB/1kB = 2^17行
所有最多只能存2^17 * 2^17
HLong工作原理
采用预写式日志,及先写日志在存入数据
Habse 命令
启动Habse、先启动hadoop(start-all.sh)再启动habse
start-habse.sh
通过habse shell打开habse 的shell界面
通过exit退出shell界面
stop-habse.sh停止habse
创建表
create 'student','name','sex',{NAME=>'course',VERSIONS=>2}
插入数据
put 'student','95001','name','xiaog'
put 'student','95001','name','xiaoming'
列族下可以再分
put 'student','95001','course:math','31'
删除指定数据
delete 'student','95001','name'
删除指定一行
deleteall 'student','95001'
查看指定一行
get 'studet','95001'
查看指定版本数据
get 'student','95001',{COLUMN=>'name',VERSIONS=>1}
查看整个表
scan 'student'
停用表
disable 'student'
删除表
drop 'student'
eixt
Hive
因为使用java编程效率比较低、提供一种利用sql的语言进行查询
操作
Hive可以用自带的derby来存储元数据
启动 hadoop在启动hive
start-all.sh
hive
数据类型;
TINYINT 1个字节
SMALLINT 2个字节
INT 4个字节
BIGINT 8个字节
FLOAT 4个字节
Double 8个
ARRAY:有序字段
MAP: 无序字段
STRUCT:一组命名的字段
与sql不同的是hive有时需要指定分隔符和数据位置
指定分隔符
row format delimited fields terminated by ','
指定是数据位置
location '/C/……'
分区,不能在创建表中写
partitioned by(city string,state string)
创建数据库
create database if not exists hive;
使用数据库
use hive
创建表
create table if not exists hiveusr(
name string comment 'username',
sex string,
course int)
创建外部表关键字external
create external if not exists usr2(
name string,
address struct<street:string,city:string,QQ:string,weixi:string>,
identyfy map<int,tinytin>
ff map<int,int>)
row format delimited filds terminated by ','
location '/usr/....'
增加列
alter table hiveusr add columns(age int);
删除列
alter table hiveusr replace columns(age int);
导入数据
load data local inpath 'usr/local/....' overwrite table hiveusr.
如果数据在本地要加上local关键字,利用overwrite可以让追加效果变成覆盖
插入数据
insert overwrite table hivesur values('xx','man','1')
从其他表中导入
insert overwirte table hivesur select name,age,course from stu where (条件)
map<int,int>)
row format delimited filds terminated by ‘,’
location ‘/usr/…’
增加列
alter table hiveusr add columns(age int);
删除列
alter table hiveusr replace columns(age int);
导入数据
load data local inpath ‘usr/local/…’ overwrite table hiveusr.
如果数据在本地要加上local关键字,利用overwrite可以让追加效果变成覆盖
插入数据
insert overwrite table hivesur values(‘xx’,‘man’,‘1’)
从其他表中导入
insert overwirte table hivesur select name,age,course from stu where (条件)