文章目录
- 0 前言
- 1 并发、并行、同步、异步、阻塞、非阻塞
- 1.1 并发
- 1.2 并行
- 1.3 同步
- 1.4 异步
- 1.5 阻塞
- 1.6 非阻塞
- 2 多线程
- 2.1 Python线程的创建方式
- 2.1.1 方式一
- 2.1.2 方式二 继承Thread
- 2.1.3 通过线程池创建多线程
- 2.2 聊聊GIL
- 2.2.1 Python线程与操作系统线程的关系
- 2.3 线程同步
- 2.3.1 加同步锁处理
- 2.3.2 死锁问题
- 2.3.3 可重入锁
- 2.4 高级线程同步-Condtion
- 2.5 高级线程同步-Semphore
- 2.6 高级线程同步-Event
- 3 IO 多路复用+回调
- 3.1 用同步的方式访问服务
- 3.2 使用多线程提速
- 3.3 改写成IO多路复用+回调的方式
- 4 协程
- 4.1 yield关键字
- 4.1.1 给yield传值
- 4.1.2 给yield传异常
- 4.1.3 gen.close() 关闭生成器
- 4.2 yield from 关键字
- 5 asyncio
0 前言
高并发一直在软件开发遇到的老大难问题,软件承载并发的能力也是一个核心性能点之一,这篇文章主要讲解Python语言的高并发工具,主要包括多进程、多线程、协程等。同时聊聊python的全局解释器锁对多线程的影响。
1 并发、并行、同步、异步、阻塞、非阻塞
1.1 并发
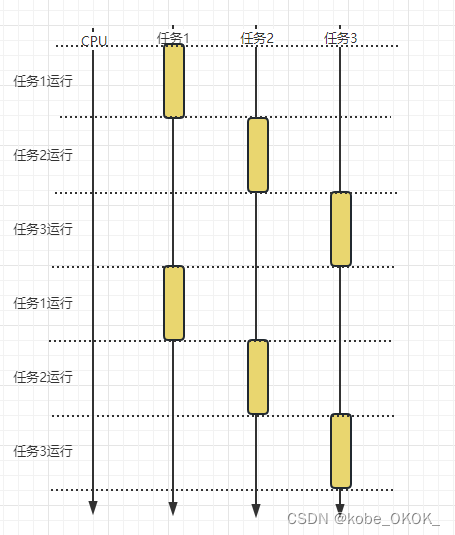
多任务在一个CPU上交替运行, 通过CPU的时间片机制,轮询调度多任务,由于CPU执行速度非常快,给人的感觉好像是多任务并行执行。
家里来客人了,我们需要泡壶茶水招待客人
需要有以下几个工作要做:
洗茶壶:5分钟
洗茶杯:3分钟
泡茶:2分钟
烧水:20分钟
主人这样做:
先烧水,烧水的同时洗茶壶和茶杯,最后在泡茶总计耗时间为22分钟
主要忘记烧水了,但是洗完茶杯又想起来了,烧水的同时洗茶壶,这样就需要消耗25分钟
其实这个生活小场景和并发非常相似,烧水的过程中,我们没有等水烧开再去做别的事情,这就类似于操作系统的IO操作,而是在烧水的过程中做一些其他的操作,进而提高了工作效率。
1.2 并行
并行是多个任务同时执行,真正的同时进行,而不是通过CPU轮询执行。
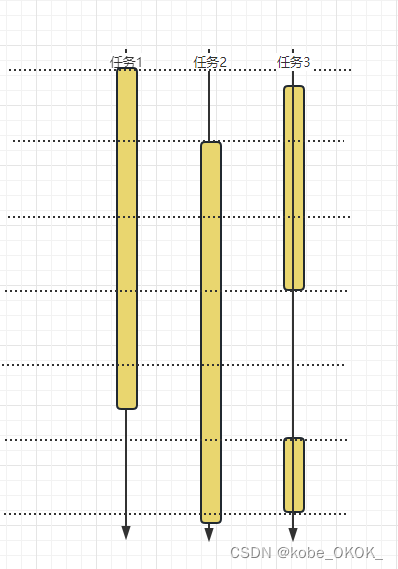
举个生活中的例子,一家人要吃晚饭,爸爸妈妈孩子一起做
孩子负责洗菜
妈妈负责切菜
爸爸负责炒菜
三个人同时做不同的事情,这就是并行。
1.3 同步
同步指的是不同任务同步进行,一个任务完成之后等待结果返回后,再开始另外一个任务。
import time
def task1():
print("task1 start")
time.sleep(1)
print("task1 end")
return "task1 end"
def task2():
print("task2 start")
time.sleep(2)
print("task2 end")
return "task2 end"
if __name__ == '__main__':
task1()
task2()
执行结果:task1和task2按顺序进行
task1 start
task1 end
task2 start
task2 end
1.4 异步
异步指的是不同任务一起进行,一个任务完成后不需要等待其返回结果,直接进行另外一个任务。
异步编程在IO密集型场景中效率很高。
1.5 阻塞
阻塞的意思是函数等在某个位置,直到达到某个条件后才往下走。
socket客户端的connect和recv都是阻塞点。
1.6 非阻塞
非阻塞是不必等待,直接往下进行,非阻塞一般会绑定回调函数进行工作,经典的应用场景就是IO多路复用和回调函数。但是这种编程模型也有很多问题,编程难度较高。
2 多线程
2.1 Python线程的创建方式
2.1.1 方式一
import time
import threading
def task1():
for i in range(10):
time.sleep(1)
print("一边看电视")
def task2():
for i in range(10):
time.sleep(1)
print("一边嗑瓜子")
t1 = threading.Thread(target=task1)
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
2.1.2 方式二 继承Thread
通过继承Thread类,重写run方法实现多线程
import time
import threading
class WatchThread(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
for i in range(10):
time.sleep(1)
print("一边看电视")
class EatThread(threading.Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
for i in range(10):
time.sleep(1)
print("一边嗑瓜子")
def main():
wt = WatchThread(name="看电视线程")
et = EatThread(name="嗑瓜子线程")
wt.start()
et.start()
if __name__ == '__main__':
main()
这两种实现多线程的方式中,第二种是比较常用的,第一种多用于测试或者一些初级应用场景
2.1.3 通过线程池创建多线程
通过python内置并发库里面的线程池开启多线程也是一种常用的方式,线程池免去创建线程和销毁线程的开销,对于那种频繁需要创建多线程和场景是比较合适的,并且多线程之间的来回切换也会造成很大的系统级性能开销,线程池维护指定数量的线程,可以降低线程切换带来的性能开销,同时可以控制线程的数量,线程的数量并不是越多越好的。
map接口的例子
import time
from concurrent.futures import ThreadPoolExecutor, Executor, Future
def task1(sleep_time):
print("hello......")
time.sleep(sleep_time)
return "world"
executor = ThreadPoolExecutor(max_workers=3)
fu = executor.map(task1, [1,2,3,2,1]) # 同一个函数,不同的参数
print(fu) # <generator object Executor.map.<locals>.result_iterator at 0x00000285EADDCD40>
for i in fu: # 获取结果
print(i)
submit结果的例子
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
2.2 聊聊GIL
python的GIL一直被大家所诟病,Python的执行速度确实很慢,但是GIL不能完全背锅,GIL只是不能发挥CPU的多核优势,但是在非多线程环境下,或者是IO密集型任务下,跟GIL就没有关系了,只是在计算密集型任务时,会有一些比较慢的情况,但是可以使用多进程加速程序的运行。
Python慢的本质原因是其所有的对象都被创建在堆内存中,为了增加灵活性和动态性,牺牲了运行速度,这种设计理念也造成了Python的运行速度偏慢,同时也因为Python的动态性和灵活性才能让他这么受欢迎,有利有弊,如果真的有项目语言运行速度成为瓶颈,那可以更换其他编译型语言,比如Go。
2.2.1 Python线程与操作系统线程的关系
Python通过内置的threading模块进行线程的创建,threading模块是底层的_thread模块,_thread模块是用C语言编写的,编译之后,内嵌到解释器中的。
所以Python创建线程对应C语言的线程,C语言通过OS接口启动操作系统的线程,所以Python的线程与操作系统的线程是一一对应的关系。
Python与CPython之间的关系
cpython是python语言的解释器,cpython是c语言实现的,python代码在执行前,会被编译成字节码,然后cpython解释器逐行执行字节码。
GIL跟python语言没有关系,是cpython在实现的时候考虑到垃圾回收中的计数和C语言实现函数的原子性而设计的,如果是Jpython解释器没有GIL。
重点:GIL说的是Cpython解释器,而不是python语言本身
GIL保证同一时刻,只有一个Python线程能够执行字节码,所以GIL是字节码级别的锁,一条字节码对应一个或者多个C语言实现的函数,GIL保证了C函数的原子性。
GIL并不能保证Python源码是线程安全性。
看下面这个程序:
import dis
class Ob:
pass
obj = Ob()
def add():
global obj
del obj
dis.dis(add)
通过dis模块的dis方法,获取add函数的字节码
其中第一列是源代码行号,第二列是字节码偏移量,第三列是操作指令(也叫操作码),第四列是指令参数(也叫操作数)。Python 的字节码指令都是成对出现的,每个指令都会带有一个指令参数。
11 0 RESUME 0
13 2 DELETE_GLOBAL 0 (obj)
4 LOAD_CONST 0 (None)
6 RETURN_VALUE
每个操作码都对应一个C函数:
Python/bytecodes.c
inst(DELETE_GLOBAL, (--)) {
PyObject *name = GETITEM(names, oparg);
int err;
err = PyDict_DelItem(GLOBALS(), name);
// Can't use ERROR_IF here.
if (err != 0) {
if (_PyErr_ExceptionMatches(tstate, PyExc_KeyError)) {
format_exc_check_arg(tstate, PyExc_NameError,
NAME_ERROR_MSG, name);
}
goto error;
}
}
如果两个线程同时操作add函数
线程1,在执行完err = PyDict_DelItem(GLOBALS(), name);这句之后刚好发生了线程切换
线程2,又会重新删除这个地址,python中的对象对应C语言中的一个结构体,这就造成了重复删除,这个地址可能被其他程序使用了,也可能是空的,最终会造成什么问题,没人知道。
为了保护C语言操作的原子性和引用计数,所以才有了GIL这把大锁。
2.3 线程同步
刚说完GIL是字节码层面的锁,保证cpython在同一时刻只能有一个线程执行字节码。但是python语言的层面还是会存在线程不安全的情况,比如两个线程竞争同一个资源,会造成数据不安全,这就需要线程同步机制,在python代码层面通过加锁来实现。
一个线程不安全的例子
from threading import Thread
num = 0
def add_num():
global num
for i in range(1000000):
num += 1
if __name__ == '__main__':
t1 = Thread(target=add_num)
t2 = Thread(target=add_num)
t3 = Thread(target=add_num)
t1.start()
t2.start()
t3.start()
print(num)
每次得到的数据都不一样
2316753
2.3.1 加同步锁处理
from threading import Thread, Lock
num = 0
lock = Lock()
def add_num():
global num
global lock
for i in range(1000000):
lock.acquire()
num += 1
lock.release()
if __name__ == '__main__':
t1 = Thread(target=add_num)
t2 = Thread(target=add_num)
t3 = Thread(target=add_num)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(num)
加锁之后都是3000000,不管运行多少次
3000000
很明显加锁之后的速度变慢了,加锁和释放锁一定有性能消耗,所以能不加锁尽量不要加锁。
不加锁的时间是:消耗的时间:0.14963150024414062
加锁的时间是:消耗的时间是:3.216205358505249
相差的时间将近30倍了。
2.3.2 死锁问题
import threading
lock = threading.Lock()
def task_a():
lock.acquire()
lock.acquire()
print("死锁了。。。。")
lock.release()
lock.release()
threading.Thread(target=task_a).start()
观察控制点会发现,代码没有执行也没有结束,这就是死锁,当线程没有释放锁,又去取另一把锁的时候会造成死锁。
2.3.3 可重入锁
对于同一个线程,允许同时获取多把锁,但是一定要保证获取锁和释放锁的次数是相同的。
import threading
rlock = threading.RLock()
def task_a():
global rlock
rlock.acquire()
rlock.acquire()
print("相同线程可以同时获取多把锁,但是一定要与释放次数相同")
rlock.release()
rlock.release()
print("end")
threading.Thread(target=task_a).start() # 同一个线程可以获取多次锁,不会死锁
输出结果:
相同线程可以同时获取多把锁,但是一定要与释放次数相同
end
2.4 高级线程同步-Condtion
主人与小爱同学对话:
主人:小爱同学
小爱:在,请问有什么需要帮您
主人:今天天气怎么样?
小爱:今天天气晴朗,阳光明媚
主人:小爱同学
小爱:在
主人:今天是星期几
小爱:今天是星期三
。。。
这种对话通过两个线程来交互实现,通过加锁很难实现,因为python多线程的调度机制用的是操作系统的线程调度机制,python没办法直接控制操作系统如何调度线程,所以,使用默认的调度机制通过加锁来实现交替运行是不能保证百分百实现的,还有人想通过延时操作实现,因为遇到延时操作线程都会发生切换,但是在处理多线程问题的时候,基本都不能通过时间处理,这是一个经验总结。
我们创建两个线程,通过condition来实现这种复杂的锁机制:
Condition类是在threading内置模块下的一个类,常用的 API有如下几个:
- acquire 内部维护了一把可重入锁,获取可重入锁
- release 释放可重入锁
- wait 线程等待调度
- notify 通知python开始调度线程
import threading
class Owner(threading.Thread):
def __init__(self, name, cond: threading.Condition):
super().__init__()
self.name = name
self._cond = cond
def run(self) -> None:
with self._cond:
print("主人:小爱同学")
self._cond.notify()
self._cond.wait()
print("主人:今天天气怎么样?")
self._cond.notify()
self._cond.wait()
print("主人:小爱同学")
self._cond.notify()
self._cond.wait()
print("主人:今天是星期几?")
self._cond.notify()
self._cond.wait()
# 唤醒所有线程,结束程序
self._cond.notify_all()
class XiaoAi(threading.Thread):
def __init__(self, name, cond: threading.Condition):
super().__init__()
self.name = name
self._cond = cond
def run(self) -> None:
with self._cond:
self._cond.wait()
print("小爱:在,请问有什么需要帮您")
self._cond.notify()
self._cond.wait()
print("小爱:今天天气晴朗,阳光明媚")
self._cond.notify()
self._cond.wait()
print("小爱:在")
self._cond.notify()
self._cond.wait()
print("小爱:今天是星期三")
self._cond.notify()
def main():
condition = threading.Condition()
owner_thread = Owner(name="主人", cond=condition)
xa_thread = XiaoAi(name="小爱同学", cond=condition)
xa_thread.start() # 注意这两个线程的启动顺序特别重要,不能反了,反了就错了
owner_thread.start()
owner_thread.join()
xa_thread.join()
if __name__ == '__main__':
main()
2.5 高级线程同步-Semphore
控制线程并发的数量
import random
import threading
import time
class Task(threading.Thread):
def __init__(self, sem):
super().__init__()
self.sem = sem
def run(self):
with self.sem:
print(f"{threading.current_thread().name}:task")
time.sleep(random.randint(1, 3))
def main():
sem = threading.Semaphore(3)
for i in range(10):
t = Task(sem=sem)
t.start()
main()
2.6 高级线程同步-Event
Event与Condition类似,看源码可以发现Event也是通过Condition实现的,Event具有如下接口:
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
通过Event可以控制两个线程的调度机制,进而实现高级别的线程同步。
from threading import Thread,Event
import time
event=Event()
def light():
print('红灯正亮着')
time.sleep(3)
event.set() #绿灯亮
def car(name):
print('车%s正在等绿灯' %name)
event.wait() #等灯绿 此时event为False,直到event.set()将其值设置为True,才会继续运行.
print('车%s通行' %name)
if __name__ == '__main__':
# 红绿灯
t1=Thread(target=light)
t1.start()
# 车
for i in range(10):
t=Thread(target=car,args=(i,))
t.start()
3 IO 多路复用+回调
平常常提起的selelct,poll,epoll都是IO多路复用的底层实现,IO多路复用从OS层面了用户态和内核态的管理,通过通知和回调的方式避免程序进行等待。
为了本节的测试工作,首先使用flask启动一个web服务:
flask服务端代码
import time
from flask import Flask
app = Flask(__name__)
@app.route('/sleep/<int:sleep_second>')
def index(sleep_second):
time.sleep(sleep_second)
return f"sleeping {sleep_second}s......"
if __name__ == '__main__':
app.run(host='0.0.0.0')
客户端代码
import socket
def get_url():
host = "192.168.8.133"
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 5000))
client.send(f'GET /sleep/2 HTTP/1.1\r\nHost:{host}\r\nConnection:close\r\n\r\n'.encode('utf-8'))
response_byte = b''
while True:
response = client.recv(1024)
response_byte += response
if not response:
break
response = response_byte.decode('utf-8').split('\r\n\r\n')[1]
print(response)
client.close()
if __name__ == '__main__':
get_url()
运行程序之后可以获取到返回值:
D:\Envs\py_venvs\venv_py3.11\Scripts\python.exe D:\code\高并发测试代码\coders\get_url.py
sleeping 2s......
3.1 用同步的方式访问服务
import socket
import time
def get_url(sleep_time):
host = "192.168.8.133"
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 5000))
client.send(f'GET /sleep/{sleep_time} HTTP/1.1\r\nHost:{host}\r\nConnection:close\r\n\r\n'.encode('utf-8'))
response_byte = b''
while True:
response = client.recv(1024)
response_byte += response
if not response:
break
response = response_byte.decode('utf-8').split('\r\n\r\n')[1]
print(response)
client.close()
if __name__ == '__main__':
start_time = time.time()
for i in range(10):
get_url(i)
print(f"消耗的时间:{time.time()-start_time}")
运行结果:
sleeping 0s......
sleeping 1s......
sleeping 2s......
sleeping 3s......
sleeping 4s......
sleeping 5s......
sleeping 6s......
sleeping 7s......
sleeping 8s......
sleeping 9s......
消耗的时间:45.03647589683533
3.2 使用多线程提速
import socket
import threading
import time
def get_url(sleep_time):
host = "192.168.8.133"
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 5000))
client.send(f'GET /sleep/{sleep_time} HTTP/1.1\r\nHost:{host}\r\nConnection:close\r\n\r\n'.encode('utf-8'))
response_byte = b''
while True:
response = client.recv(1024)
response_byte += response
if not response:
break
response = response_byte.decode('utf-8').split('\r\n\r\n')[1]
print(response)
client.close()
if __name__ == '__main__':
start_time = time.time()
for i in range(10):
threading.Thread(target=get_url, args=(i,)).start()
while len(threading.enumerate())-1:
pass
print(f"消耗的时间:{time.time()-start_time}")
运行结果
sleeping 0s......
sleeping 1s......
sleeping 2s......
sleeping 3s......
sleeping 4s......
sleeping 5s......
sleeping 6s......
sleeping 7s......
sleeping 8s......
sleeping 9s......
消耗的时间:9.092759370803833
3.3 改写成IO多路复用+回调的方式
import time
import socket
from selectors import DefaultSelector, EVENT_READ, EVENT_WRITE
select = DefaultSelector()
urls = []
stop = False
class GetSource:
def __init__(self, _url):
self.host = "192.168.8.133"
self.port = 5000
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False)
self.url = _url
self.response_byte = b''
def get_connect(self):
try:
self.client.connect((self.host, self.port))
except OSError:
pass
select.register(self.client.fileno(), EVENT_WRITE, self.send_msg)
def send_msg(self, key):
select.unregister(key.fd)
self.client.send(f'GET {self.url} HTTP/1.1\r\nHost:{self.host}\r\nConnection:close\r\n\r\n'.encode('utf-8'))
select.register(self.client.fileno(), EVENT_READ, self.recv_msg)
def recv_msg(self, key):
response = self.client.recv(1024)
if response:
self.response_byte += response
else:
select.unregister(key.fd)
response = self.response_byte.decode('utf-8').split('\r\n\r\n')[1]
print(response)
self.client.close()
urls.remove(self.url)
if not urls:
global stop
stop = True
def loop():
global stop
while not stop:
ready = select.select()
for key, mask in ready:
call_back = key.data
call_back(key)
if __name__ == '__main__':
start = time.time()
for i in range(0, 10):
url = f"/sleep/{i}"
urls.append(url)
gs = GetSource(url)
gs.get_connect()
loop()
print(f"消耗的时间:{time.time() - start}")
运行结果
sleeping 0s......
sleeping 1s......
sleeping 2s......
sleeping 3s......
sleeping 4s......
sleeping 5s......
sleeping 6s......
sleeping 7s......
sleeping 8s......
sleeping 9s......
消耗的时间:9.008429527282715
IO多路复用比多线程快10倍。
4 协程
协程的概念很早就被提出了,大家都知道进程的切换,会消耗很多系统资源,所以为了提高系统的并发性,又出现了多线程,操作系统在创建多线程的时候会在用户态和内核态分别创建内存空间,供线程使用,线程在执行过程中存在内核态和用户态的切换,这个过程同样是需要消耗时间的。为了降低多线程切换的性能开销和用户态,内核态的相互拷贝,前辈们提出了协程的概念,协程其实是用户态的多线程,协程的调度完全由程序员负责,操作系统是完全感觉不到的。协程的关键是函数能够在指定的位置停止,并且能够恢复到停止之前的状态继续执行。
4.1 yield关键字
在函数中使用yield关键字,调用函数之后返回一个生成器对象。
def gen_func():
yield 1
yield 2
gen = gen_func()
print(gen) # <generator object gen_func at 0x000001EFE4B9B1C0>
生成器函数的生命周期
- GEN_CREATED 生成器被创建
- GEN_RUNNING 生成器运行中
- GEN_SUSPENDED 生成器运行中
- GEN_CLOSED 生成器已停止
def gen_func():
yield 1
yield 2
gen = gen_func()
print(gen) # <generator object gen_func at 0x000001EFE4B9B1C0>
import inspect
print(inspect.getgeneratorstate(gen)) # GEN_CREATED
res = gen.send(None)
print(res)
print(inspect.getgeneratorstate((gen))) # GEN_SUSPENDED
res = gen.send(None)
print(res)
try:
res = gen.send(None)
print(res)
except StopIteration:
pass
print(inspect.getgeneratorstate(gen)) # GEN_CLOSED
当函数定义中包括yield关键字后,这就是一个生成器函数,生成器函数调用后会返回一个生成器对象,生成器对象必须驱动才能够运行,驱动生成器有两种方式:
- gen_object.send(None)
- next(gen_object)
上面这两种方式是相同的作用,生成器驱动之后,第一次调用会停留在第一个yield之后,并把yield后面的值返回给调用方,第二次调用会停在第二个yield后面,生成器函数执行结束后会抛出一个StopIteration异常。
同样,生成器也是一个特殊的迭代器,可以通过for语句进行遍历
def gen_func():
yield 1
yield 2
for i in gen:
print(i)
输出结果:
1
2
其实for语言的本质是:
while True:
try:
val = next(gen)
print(val)
except StopIteration:
break
4.1.1 给yield传值
调用方不仅能够收到yield出来的值,还能够将值传递给生成器函数。
def gen_func():
a = yield 1
print(f"接收到的第一个值 a=:{a}")
b = yield 2
print(f"接收到的第二个值 b=: {b}")
return "gen return"
gen = gen_func()
# 激活生成器对象
res = gen.send(None)
# 获取第一个yield后面的值
print(res)
# 给生成器对象传递值,同时获取第二个yield后面的值
res = gen.send("hello")
# 生成器函数向下执行
print(res)
try:
res = gen.send("world")
except StopIteration as e:
print(e.value) # gen return
执行结果:
1
接收到的第一个值 a=:hello
2
接收到的第二个值 b=: world
gen return
4.1.2 给yield传异常
python中一切皆对象,既然能够传值,当然也能够传递异常。
def gen_func():
a = None
try:
a = yield 1
except ValueError: # 如果不处理直接报错
pass
print(f"接收到的第一个值 a=:{a}")
b = yield 2
print(f"接收到的第二个值 b=: {b}")
return "gen return"
gen = gen_func()
# 激活生成器对象
res = gen.send(None)
# 获取第一个yield后面的值
print(res)
# 给生成器对象传递值,同时获取第二个yield后面的值
res = gen.throw(ValueError("值传递错误"))
4.1.3 gen.close() 关闭生成器
def gen_func():
yield 1
yield 2
gen = gen_func()
import inspect
print(inspect.getgeneratorstate(gen)) # GEN_CREATED
gen.send(None)
gen.close()
print(inspect.getgeneratorstate(gen)) # GEN_CLOSED
4.2 yield from 关键字
在一个生成器中yield另外一个生成器
def gen1():
yield 1
yield 2
def gen2():
yield gen1()
gen2 = gen2()
print(gen2) # <generator object gen2 at 0x00000185E6115180>
res = gen2.send(None)
for i in res:
print(i)
输出结果:
<generator object gen2 at 0x00000185E6115180>
1
2
使用yield from 关键字更简单的实现这个功能
def gen1():
yield 1
yield 2
def gen2():
yield from gen1()
gen2 = gen2()
print(gen2) # <generator object gen2 at 0x00000185E6115180>
for i in gen2:
print(i)
直接遍历父生成器就可以获取到子生成器中的值
<generator object gen2 at 0x000001606D2D5180>
1
2
yield from 可以作为委派生成器,在调用方和子生成器之间搭建一个桥梁,让调用方可以获取到子生成器的数据,同时可以将数据或者异常直接通过委派生成器传送到子生成器中,yield from也是python实现原生协程的根本所在。