有时需要对魔改源码前后的不同版本Trino引擎进行性能对比测试,提前发现改造前后是否有性能变差或变好的现象,避免影响数据业务的日常查询任务性能。而Trino社区正好提供了一个性能测试对比框架:GitHub - trinodb/benchto: Framework for running macro benchmarks in a clustered environmentFramework for running macro benchmarks in a clustered environment - GitHub - trinodb/benchto: Framework for running macro benchmarks in a clustered environment https://github.com/trinodb/benchto因此使用它可以较大程度上减少一通魔改后,看起来代码量很大且功能很牛,但是实际上线性能拉垮,改了个寂寞的现象。
https://github.com/trinodb/benchto因此使用它可以较大程度上减少一通魔改后,看起来代码量很大且功能很牛,但是实际上线性能拉垮,改了个寂寞的现象。
一、服务端部署
通过了解项目源码结构和.md文档发现,本质上是需要部署一个远程服务端,它可以灵活连接不同的Trino集群,并将性能测试的结果和指标信息写入到数据库中,其中benchto-service模块就是基于Spring Boot的服务端实现。可以修改resources目录中的application.yaml配置,指定Spring Boot后端需连接的数据库,社区默认是Postgres:
server:
port: 8081
spring:
datasource:
url: jdbc:postgresql://x.x.x.x:5432/postgres
username: postgres
password: postgres
driver-class-name: org.postgresql.Driver
jpa:
open-in-view: false
hibernate.ddl-auto: validate
properties:
hibernate.cache.region.factory_class: org.hibernate.cache.ehcache.EhCacheRegionFactory
hibernate.cache.use_second_level_cache: true
hibernate.cache.use_query_cache: true
javax.persistence.sharedCache.mode: ENABLE_SELECTIVE通过Maven编译打包后,会生成benchto-service.jar,可以通过java -jar命令的方式部署启动到具体的物理机上,也可以参考docs/getting-started/README.md中的提示一键启动相关各服务的docker容器。
二、客户端部署
项目中benchto-driver模块本质上是提交性能测试任务的客户端,代替了Trino 363版本之前trino-benchmark-driver-363-executable.jar直连Trino集群的方式。Maven编译打包后会生成benchto-driver-exec.jar,也是同样以java -jar的命令启动,同时在该jar的所在目录下,需要准备如下配置:
(1)描述具体Trino集群信息的application-环境名.yaml配置文件,样例如下:
# application-dev.yaml
data-sources:
test-env:
url: jdbc:trino://x.x.x.x:8080
username: benchto
driver-class-name: io.trino.jdbc.TrinoDriver
benchmarks: benchmarks
sql: sql
query-results-dir: results
benchmark-service:
url: http://x.x.x.x:18801
environment:
name: DEV
benchmark:
feature:
presto:
metrics.collection.enabled: true
queryinfo.collection.enabled: true
presto:
url: http://x.x.x.x:8080
username: benchtodata-sources代表可以连接哪些trino集群环境,这里有个叫test-env的Trino JDBC连接信息,是后面提到的(3)中会引用到的。
benchmarks代表部署benchto-driver-exec.jar客户端后,在客户端所在目录下的哪个子目录放置了SQL集配置文件,这里就放在名为benchmarks的子目录里。
sql代表各.sql文件放在哪个子目录,这里延续了老版trino-benchmark-driver jar的传统,也放在sql子目录里。
query-results-dir代表跑性能测试后的结果放在哪个子目录里。
benchmark-service代表benchto服务端的地址,以及可以代表什么环境名称。
benchmark标签下可以配置一些接入Presto引擎的参数,例如是否针对Presto开启指标收集。
presto下配置连接哪个trino coordinator,以及提交查询时的user是谁。
(2)名为sql的目录,其中存放需要的.sql文件。
(3)名为benchmarks的目录,其中存放配置trino集群标识和涉及SQL集的.yaml文件,样例如下:
# tpch.yaml
datasource: test-env
query-names: tpch/${query}.sql
runs: 3
prewarm-runs: 1
variables:
1:
query: q01,q02,q03,q04,q05,q06,q07,q08,q09,q10,q11,q12,q13,q14,q15,q16,q17,q18,q19,q20,q21,q22
schema: tpch_orc_100
database: hivedatasource代表连接哪个trino集群,test-env标识在(1)中代表环境信息的application-环境名.yaml系列配置中已编写引用。
query-names代表涉及哪些SQL文件,可以使用动态变量。
runs代表每条SQL除warm up外要正式跑并统计几次。
prewarm-runs代表每条SQL不计入指标统计的初期热身运行次数。
variables代表可以配置的环境变量,例如${query}引用到的.sql文件前缀、.sql中的表所来源的catalog和库名等。
variables中1:和2:等数字代表了每个sql可单独进行配置,其中schema为.sql文件中动态替换的库名。
三、使用姿势
3.1、提交自动查询任务
在benchto-driver-exec.jar所在目录执行如下命令可以查看能自定义的参数:
java -jar benchto-driver-exec.jar -h常用的执行命令例子如下:
# 测试dev环境的tpch sql集
java -jar benchto-driver-exec.jar --profile dev --activeBenchmarks tpch其中--profile指定提交任务的Trino环境(即之前的application-dev.yaml),--activeBenchmarks指定需要执行的SQL用例集(即之前的tpch.yaml)。SQL集中的每一条SQL默认都会先跑一次warm up,然后再跑3次正式执行(这4次算作一轮),获得各项指标的最小最大和平均值等。
3.2、查看查询执行的明细信息
除了benchto-driver-exec.jar不断打印的控制台日志外,benchto-service.jar所在机器ip的Benchto UI可以查看提交到具体环境上的SQL执行时长等信息,进入后可以选择自己提交sql集所在的集群环境,如下图所示:

以dev环境为例,点击进入DEV标签后可以看到执行过的SQL概览,如下图所示:
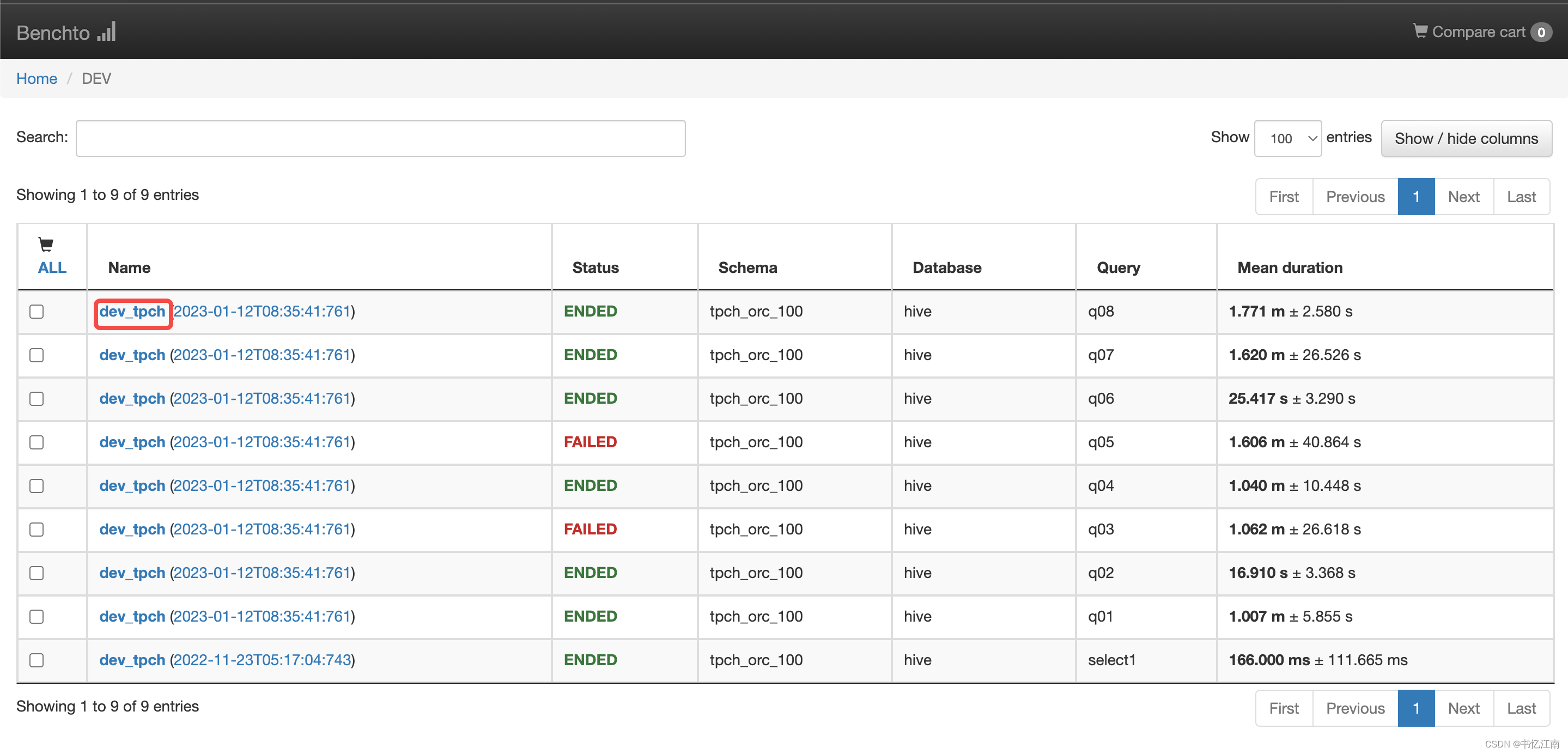
Name代表SQL集的名称,Schema为库名,Database其实是catalog名,Query就是sql文件的名称,Mean Duration为平均查询时长。
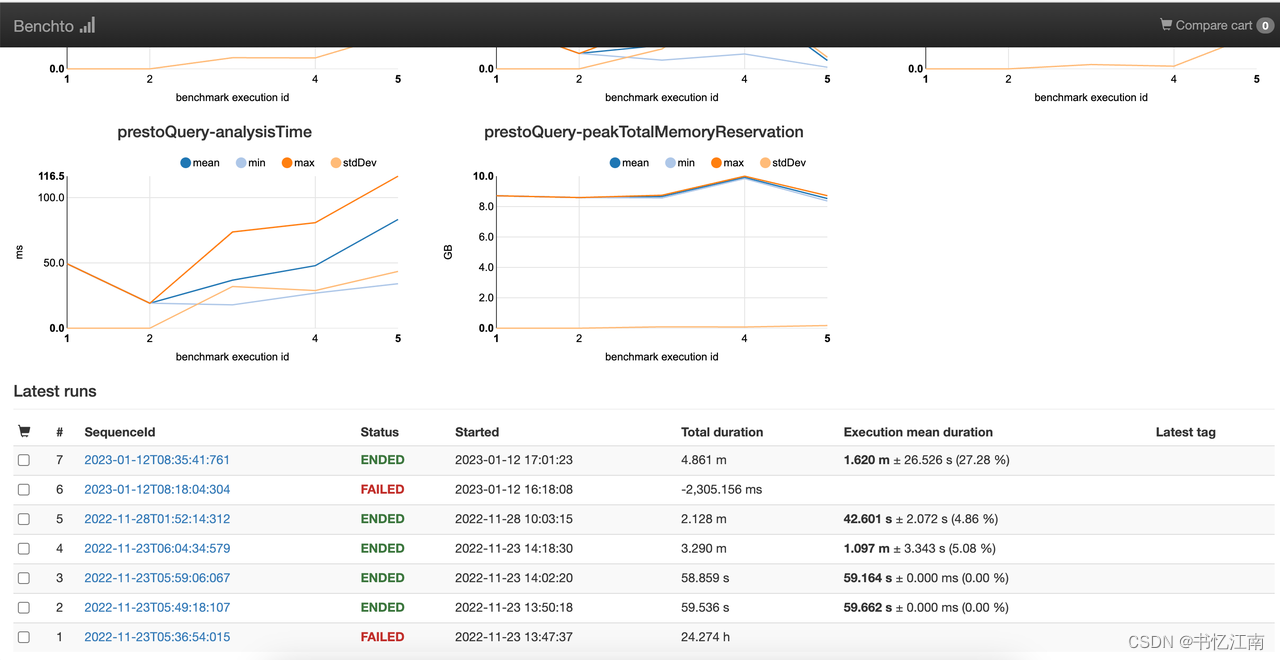
点击Name列中的某行SQL集名称(这里是dev_tpch),会进入对应sql的明细界面,可以看到同一条sql被统计了3次(不包含第一次warm up),下方的各种图表展示了该sql各方面的最小最大值,平均值与标准差等指标,横轴的execution id指的是这一轮中几次相同sql所执行的id:

在各种图表的最下方可以看到同一个SQL多次执行的快照信息,按id来最近时间排序,如下图所示:
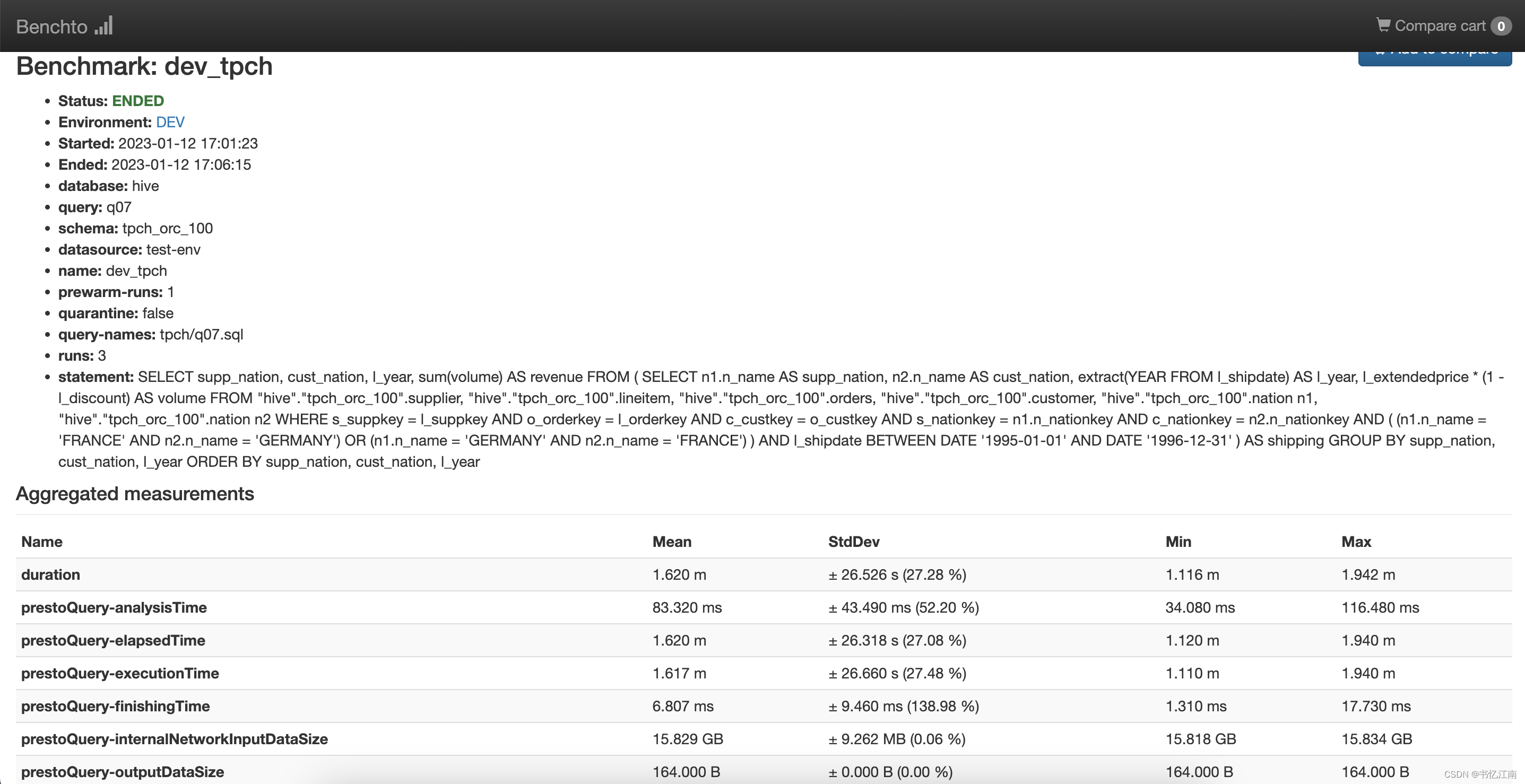
点击某一次执行的时间链接,就会看到这一轮3次执行的更详细指标,如下图所示:
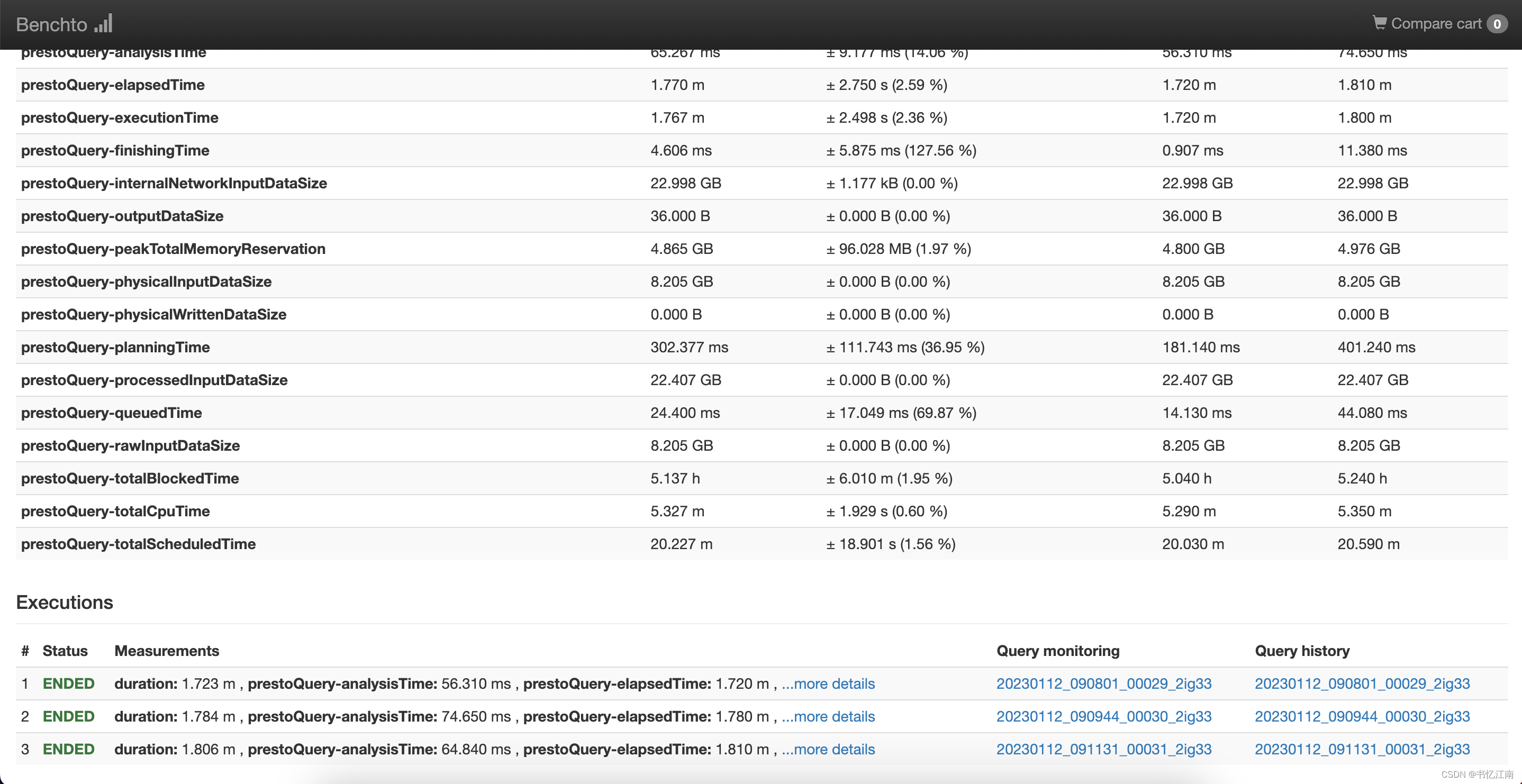
在明细指标的末尾还可以看到该SQL在这一轮3次执行的trino query id链接,可以进入trino UI查看一些原生信息:
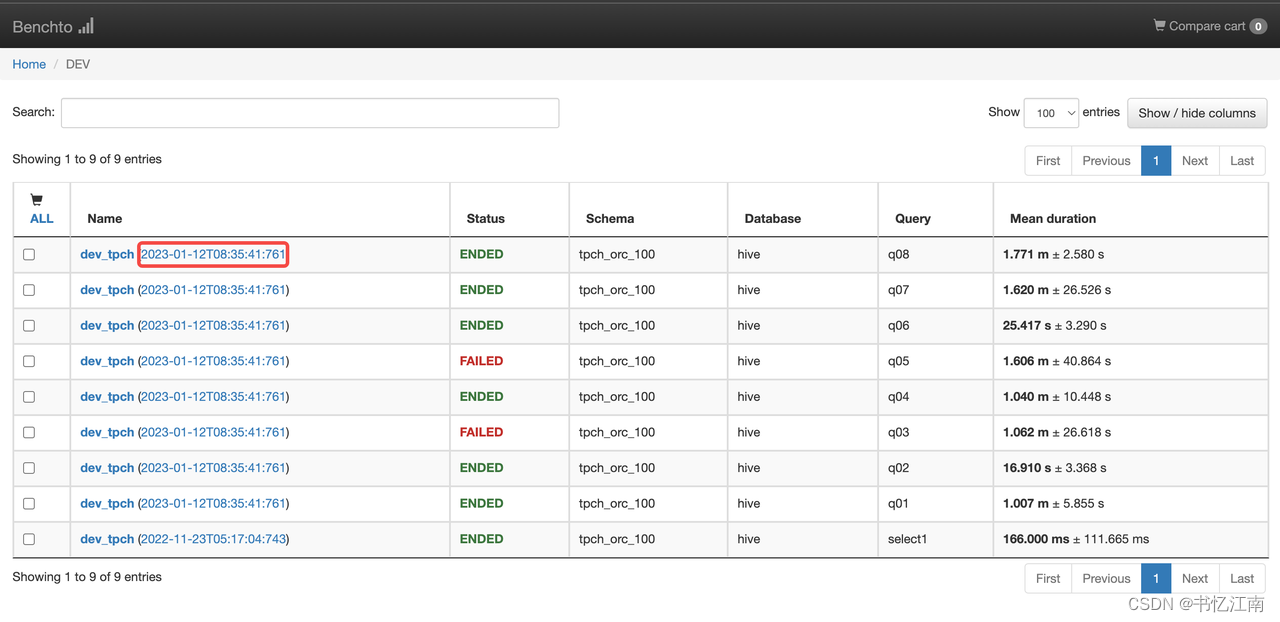
上图的界面也可以通过对应环境的首页,点击对应行的时间链接进入,如下图所示:
3.3、对比组件版本前后性能
目前Benchto只能做到SQL粒度的前后对比,无法展示总体版本的前后对比,因此建议先利用集群环境上的老版本Trino先提交一轮SQL集,整轮跑完后关注下Benchto UI上提交的时间,再发布新版组件,再提交第二轮相同SQL集。
Benchto UI上有了2轮相同SQL集(分别由新老版本Trino执行)的记录后,在对应环境的首页先进入对应的SQL链接,然后在SQL明细页底部勾选要对比的两次执行时刻条目(也可以选多个时刻),再点击右上角的Compare all,如下图所示:
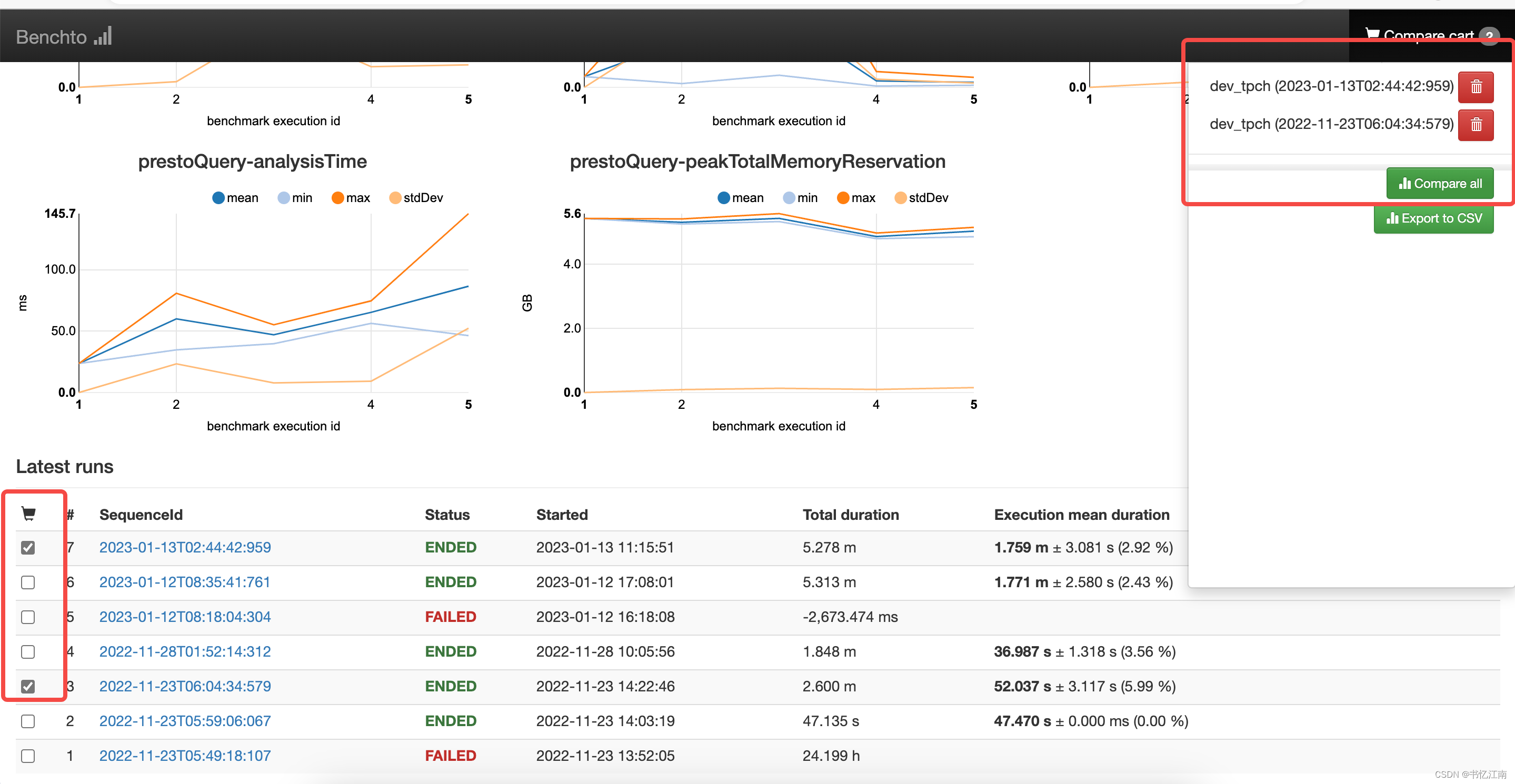
当然对比数据也可以导出为CSV进行其他处理,Compare all之后可以看到该SQL对应两次执行的对比图,如下所示:
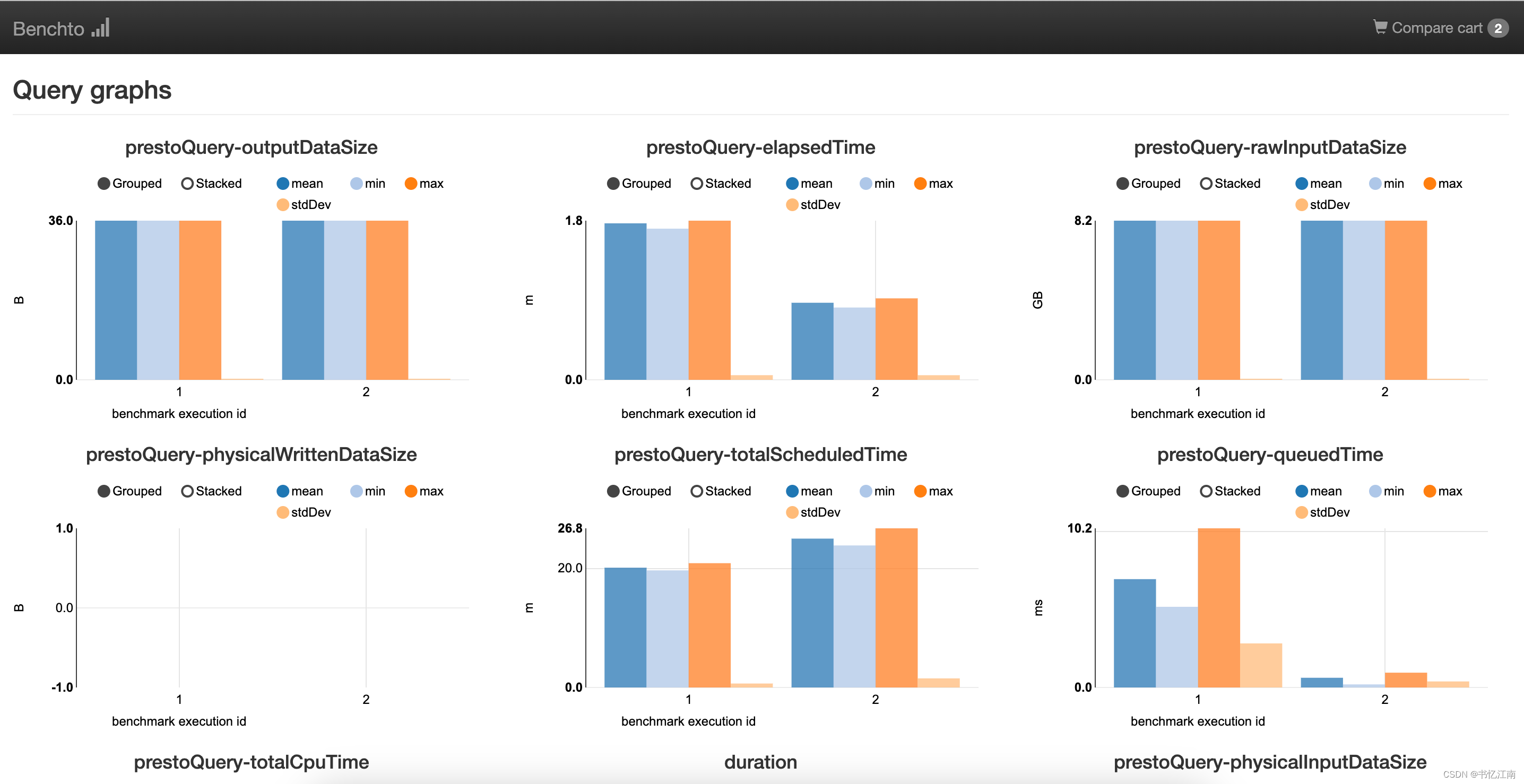
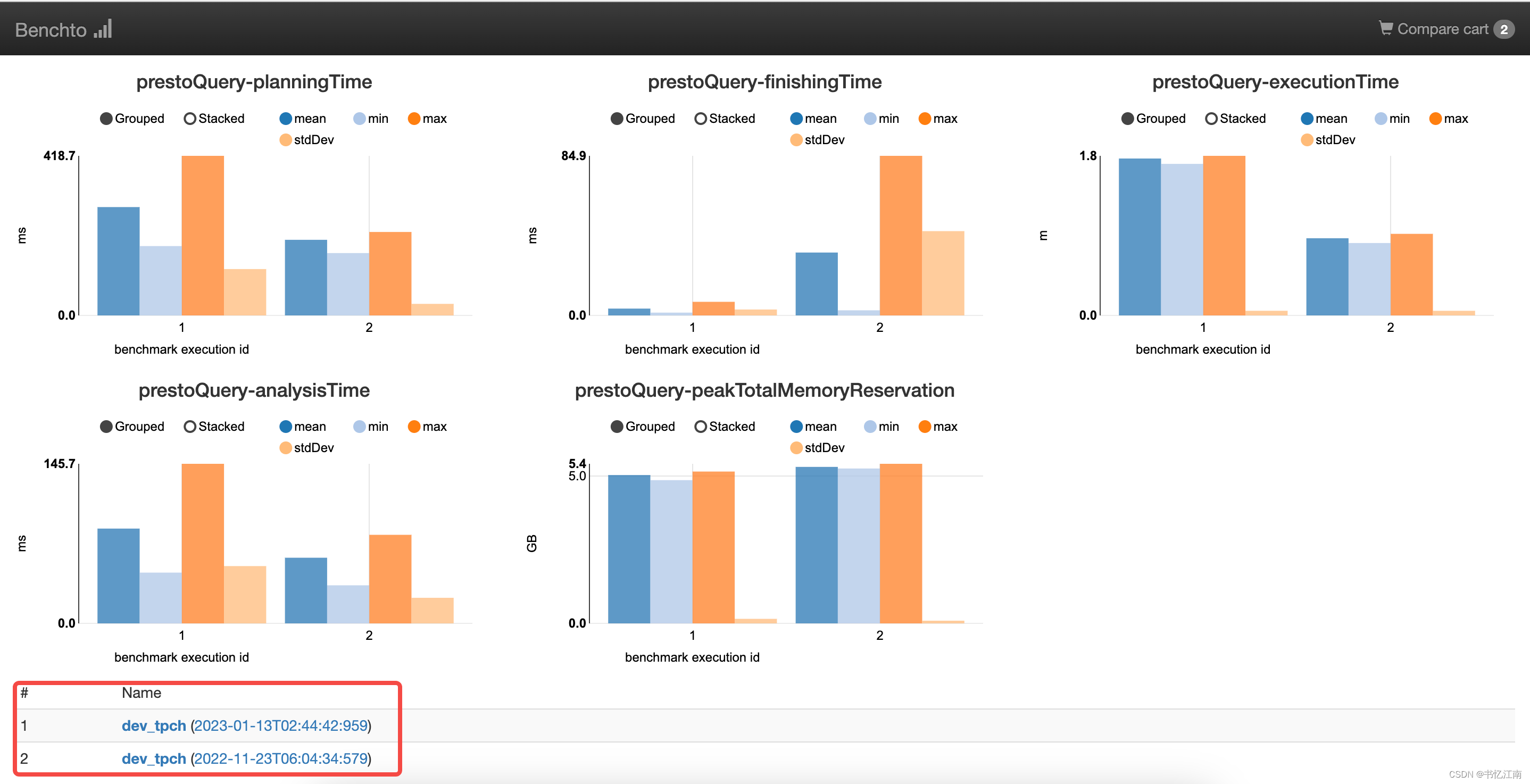
比较常关注的就是elapsedTime,代表体感查询时间,其他指标例如queuedTime(在等待执行队列中的时间)、planningTime(执行计划生成时间)、finishingTime(commit元数据与等待客户端消费结果等时间)、analysisTime(从存储引擎拉取元数据并赋予执行计划的时间)、executionTime(从结束queued状态起到执行结束的时间,包括planning)等也值得关注。
id1和id2代表的执行时刻在对比图表页面的底部有展示,如下所示:
3.4、清理历史查询信息
benchmark运行一段时间后,会生成非常多的查询历史记录,对比报告的可读性会下降,此时可以在确定之前的历史信息已经不需要的前提下,清理记录benchto查询历史信息的Postgres数据库,操作步骤为:
su - postgres
psql
-- 从这里开始已经进入了pg的sql命令行界面
\c postgres; --切换数据库到postgres,等同于use postgres
\dt; --等同于show tables
truncate table benchmark_runs cascade;这样Benchto UI上的图表也都清空了。