文章目录
- Spark on hive & Hive on spark
- Hive 架构与基本原理
- Spark on hive
- Hive on spark
Spark on hive & Hive on spark
Hive 架构与基本原理

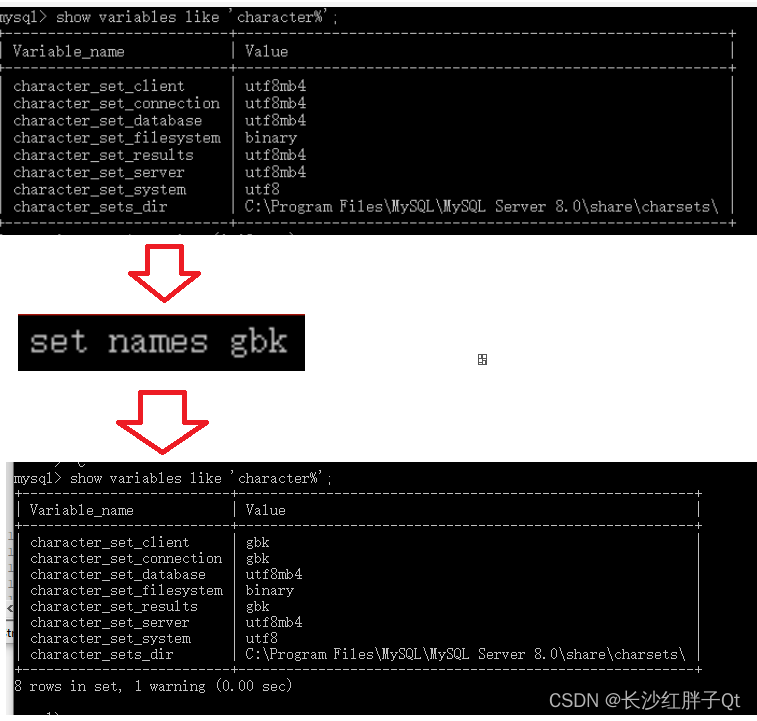
Hive 的核心部件主要是 User Interface(1)和 Driver(3)。而不论是元数据库(4)、存储系统(5),还是计算引擎(6),Hive 都以“可插拔”的方式交给第三方独立组件。
Hive sql查询工作流程:
-
接收到 SQL 查询之后, Hive 的 Driver 首先使用其 Parser 组件,将查询语句转化为 AST(Abstract Syntax Tree,查询语法树)。
-
Planner 组件根据 AST 生成执行计划,而 Optimizer 则进一步优化执行计划。要完成这一系列的动作,Hive 必须要拿到相关数据表的元信息,比如表名、列名、字段类型、数据文件存储路径、文件格式,等等;元信息存储在“Hive Metastore”(4)的数据库中。
Hive Metastore 是一个普通的关系型数据库(RDBMS),它的作用:
- 辅助SQL 语法解析、执行计划的生成与优化;
- 帮助底层计算引擎高效地定位并访问分布式文件系统中的数据源;
Spark on hive

Spark on Hive是spark做sql解析并转换成RDD执行,hive仅仅是做为外部数据源
Spark SQL 对 SQL 查询语句先后进行语法解析、语法树构建、逻辑优化、物理优化、数据结构优化、以及执行代码优化,等等。然后Spark SQL 将优化过后的执行计划,交付给 Spark Core执行引。
Hive on spark

“Hive on Spark” 指的是 Hive 采用 Spark 作为其后端的分布执行引擎。
Hive on Spark 是由 Hive 的 Driver 来完成 SQL 语句的解析、规划与优化,还需要把执行计划“翻译”成 RDD 语义下的 DAG,然后再把 DAG 交付给 Spark Core执行。【Spark on hive是由Spark SQL + Spark Core执行,性能更好】