来源:投稿 作者:魔峥
编辑:学姐
起源回顾
有关Attention的论文早在上世纪九十年代就提出了。
在2012年后的深度学习时代,Attention再次被翻了出来,被用在自然语言处理任务,提高RNN模型的训练速度。但是由于结果Attention效果太好。谷歌的科学家们在2017年提出了抛弃RNN全用Attention的神经网络结构[2],并把这种结构取名为Transformer。
Transformer的基础元件是一种名叫Self-Attention的计算方式。假设现在一个有隐式逻辑的序列a=(a1, a2, a3, ..., ai, ...),例如文章的文字序列,语音的声谱序列,甚至可以是心电图信号序列。我们的目标是:为每个token(元素)找到与其他token的关系权重(图1),找到这样的权重信息组合就是Transformer需要做的。

大杀四方
我们可以发现,Transformer在NLP语音识别这样的序列任务上有天生的结构优势。 但是在图片识别任务中,因为序列信息不明显而很难简单使用。
事情的发展也是这样,在Transformer在NLP任务中火了3年后,VIT网络[4]提出才令Transformer正式闯入CV界,成为新一代骨干网络。
VIT的思想很简单:
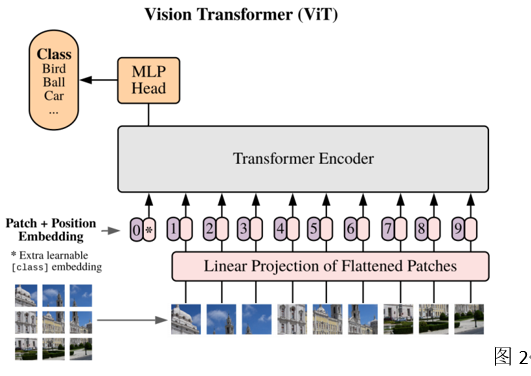
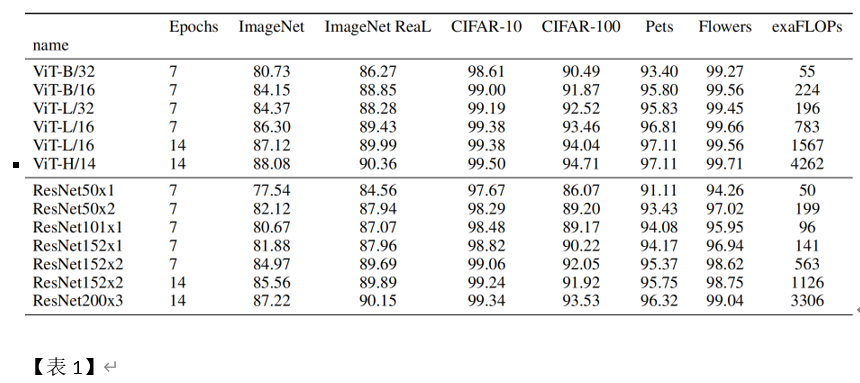
没有序列就创造序列,把一个图片按序切成一个个小片(Patch)不就是有序列与token了吗(图2)?这样的想法很简单很粗暴,但效果就是好。一种全新思路设计的网络,结果直接逼近甚至超过研究多年的ResNet CNN结果【表1】。
但这种简单粗暴的切片结果是有明显的缺点。(包括但不限于以下几点)如:
新网络训练难度大,论文中几乎没告诉调参方法 因为VIT的直筒式结构,对接下游任务时表现很难 使用图片切开的方法,导致切口处的关联性一些影响。
后来衍生
所谓”缺陷趋生进化,完美亦是终结”。
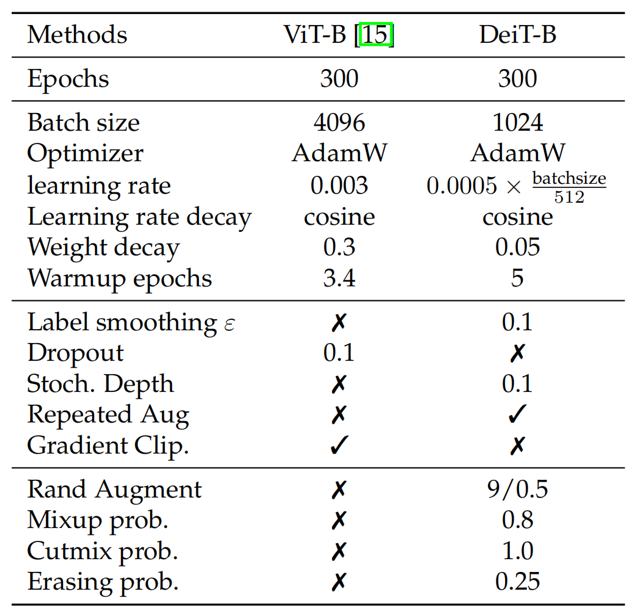
VIT的优异表现让驱使继者进行深入持续研究。直接导致了如今Transformer在CV界大火的局面。在DeiT论文[6]中,作者提出了VIT网络的训练方案【表2】。以表2的参数为基准进行数据微调即可以得到很好的结果。
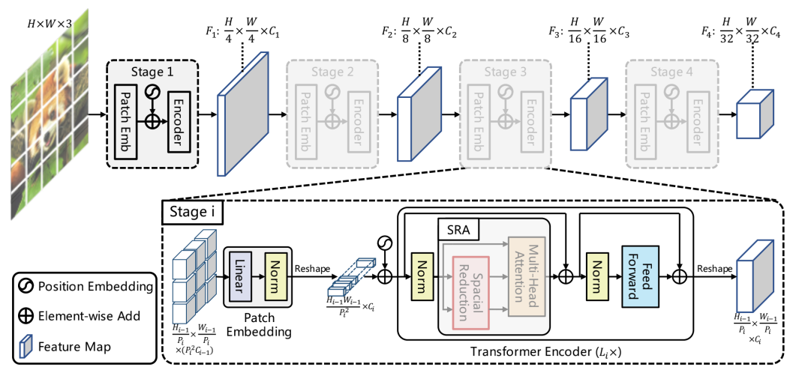
在ICCV2021上提出的PVT(Pyramid Vision Transformer)论文【5】中,将类FPN的结构(图3)因为FPN。该方案大大方便了Transformer网络接入CV下游任务,同时减少了大目标的内存计算的消耗。
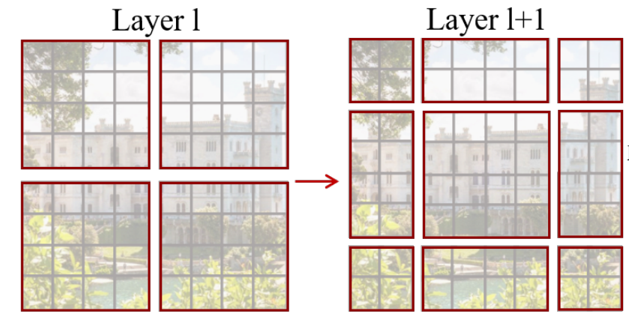
在同时期ICCV2021的Swim Transformer论文[7]中,提出了W-MSA。SW-MSA交替使用(图4)的切片方案(Swim Transformer论文中还有很多重要的开创性贡献)。该方案防止了被切片处一直分开关联性差的情况。
自去年以来,CV Transformer发展更加迅速俨然成为CV界继CNN的下一代神经网络。看来新一轮的知识更新又开始了。
引文:
[1] Jay Alammar:The Illustrated Transformer https://jalammar.github.io/illustrated-transformer/
[2] Attention Is All You Need https://arxiv.org/abs/1706.03762
[3] 台湾大学李宏毅教授Attention课程ppt
[4] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale https://arxiv.org/abs/2010.11929
[5] Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions https://arxiv.org/abs/2102.12122
[6] Training data-efficient image transformers & distillation through attention https://arxiv.org/abs/2012.12877
[7] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows https://arxiv.org/abs/2103.14030
关注下方卡片《学姐带你玩AI》🚀🚀🚀
回复“CVPR”
600+篇CVPR必读论文免费领
码字不易,欢迎大家点赞评论收藏!