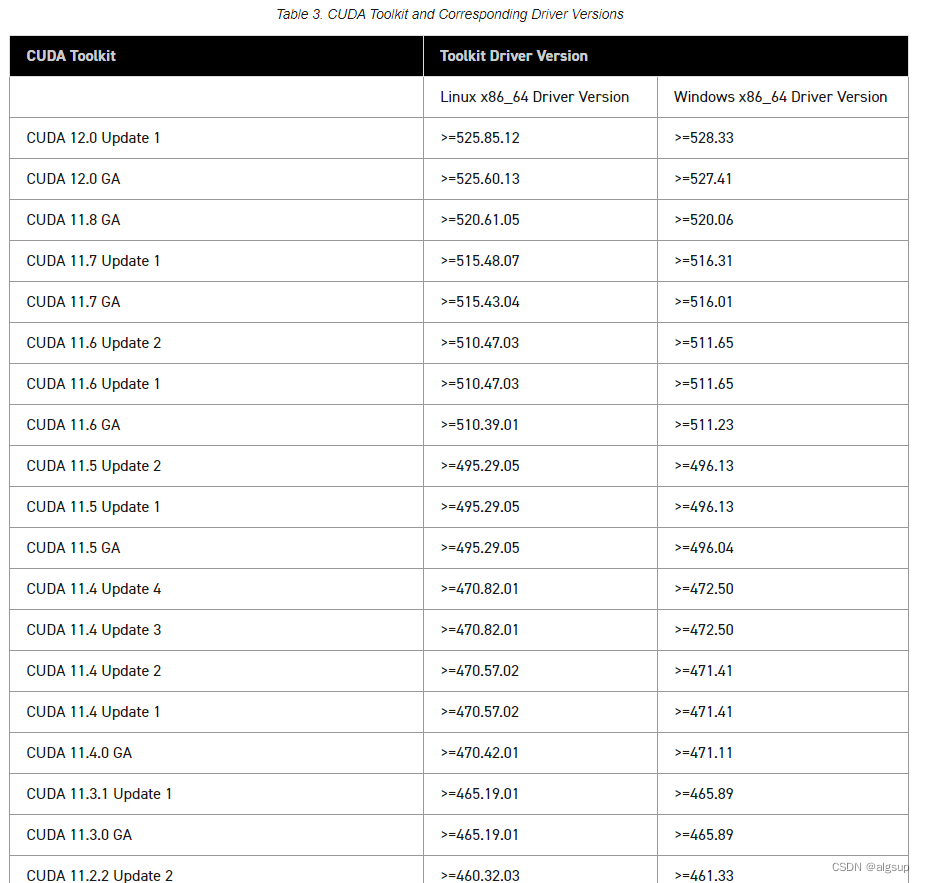
I. Speech Codecs
语音编码的目的是在保持语音质量的前提下尽可能地减少传输所用的带宽,主要是利用人的发声过程中存在的冗余度和人的听觉特性达到压缩的目的。经过了多年的发展,目前语音编解码器大致可以分为以下几类:
波形编码,将时域波形经过采样量化编码,常见的就是PCM编码格式
参数编码,根据人的发声机制建立数学模型,然后对语音进行压缩,常见的是LPC-10
混合编码,结合波形编码和参数编码的压缩方式,常见的AMR等
深度学习编码,利用神经网络将语音编码成隐向量,然后利用神经网络将其恢复成语音信息,微软的Satin以及今天要介绍的Lyra就是其代表
虽然目前很多领域仍是直接把PCM封装成IP包进行传输,但是在带宽限制的领域,如VoIP语音会议,语音编解码是较为关键的技术之一。
II. Lyra
Lyra去年就已经在Github上开源了,并且同时支持Linux和Android系统。当时年轻的我使用VM创建了一个Ubuntu的虚拟机,许多个夜晚睡觉前敲下编译命令:
bazelbuild-copt:encoder_main第二天兴冲冲地醒来却发现虚拟机已经卡死。如今我吸取了以前的教训,首先我升级了硬件,给我的暗影精灵增加了4G的内存条,然后我抛弃了VM转投双系统的怀抱,关于如何装双系统可以参考我的博客。本以为天时地利人和皆在我,但还是由于一些环境和网络问题花了很多精力才编译成功,如果你不想自己编译的话,本文末尾有对应链接。如果你想自行编译的话,这里给你一些我踩过的坑:1)删除WORKSPACE中关于Android SDK和NDK的repo;2)科学上网采用全局模式。
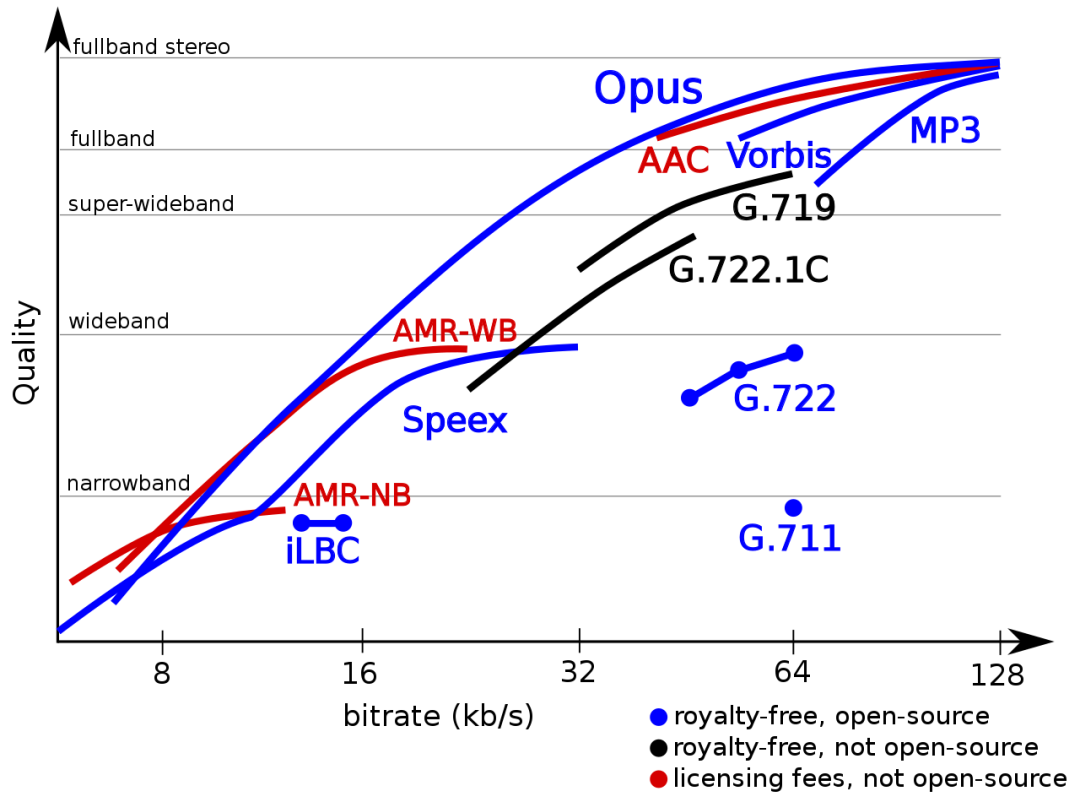
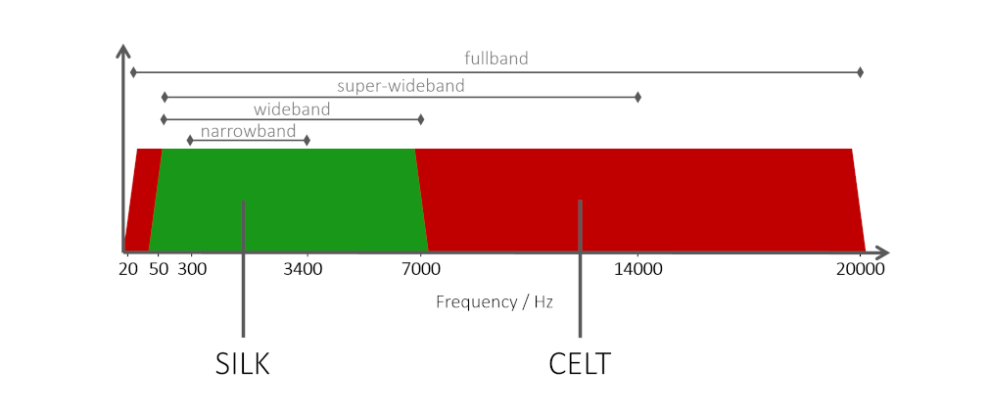
废话不多说了,我们直接进入正题。目前常用的编解码器Opus是一种混合编解码器,对于窄带语音信号使用SILK进行编码,对于宽带和超宽带使用CELT编码。
而Lyra的整体流程如下所示:
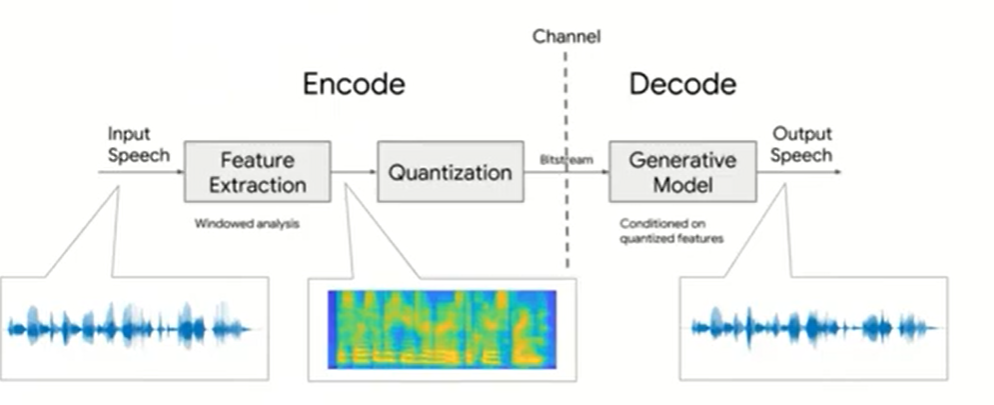
可以看出Lyra整体流程非常简单,在编码过程中,Lyra每40ms提取一次特征,所使用的特征是160维的log melspectrum,然后将它们量化到3kbps;在解码过程中,则使用生成模型将量化后的特征重构语音信号,如果读者对语音合成或者语音转换等任务有所了解的话,那么对解码部分应该不会感到陌生。可惜的是Google只开源了应用,没有开源如何训练这个模型,因此具体的网络结构也不得而知,只能从部分代码中窥探一二。
III. Experiment
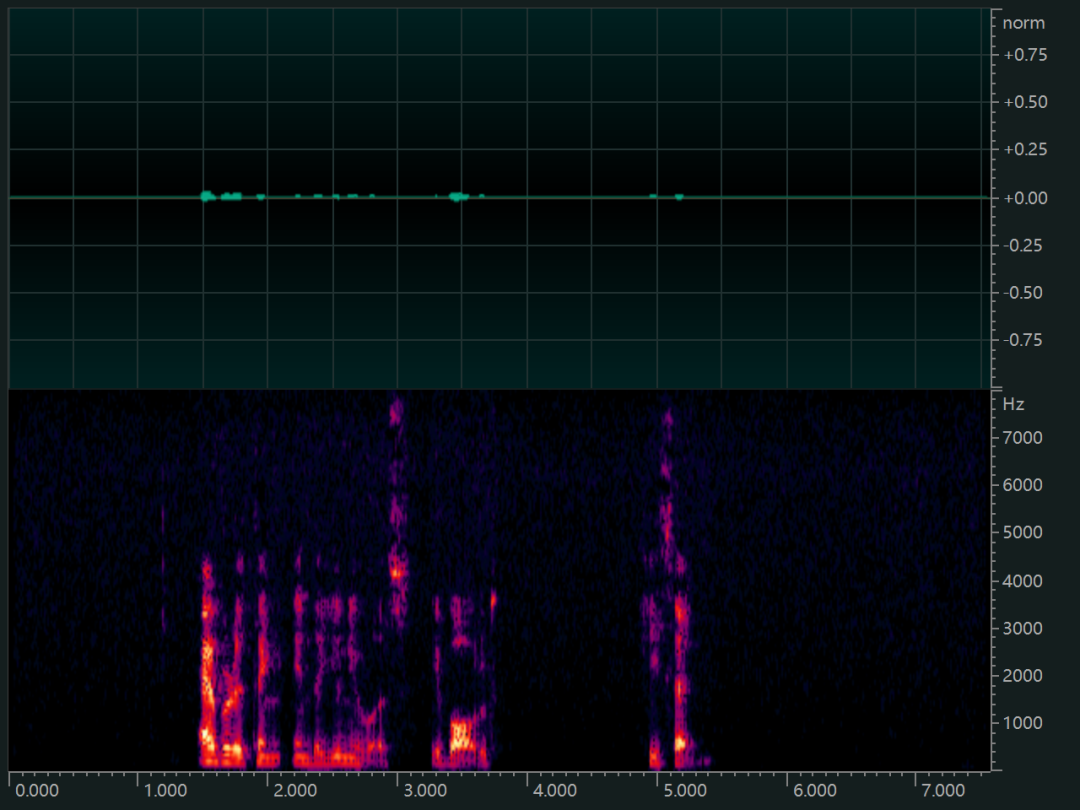
下面我们看下Lyra编解码的效果,原始音频如下所示,可以看到原始音频音量比较小,并且能量大多集中在5K以下,该样本PCM格式文件大小的为236KB。
Lyra编码后的文件大小为2.77KB,解码后的音频如下所示,可以看到Lyra一些原始音频中的频率成分没有正确的重构,但同时一些背景噪声也被抑制干净。
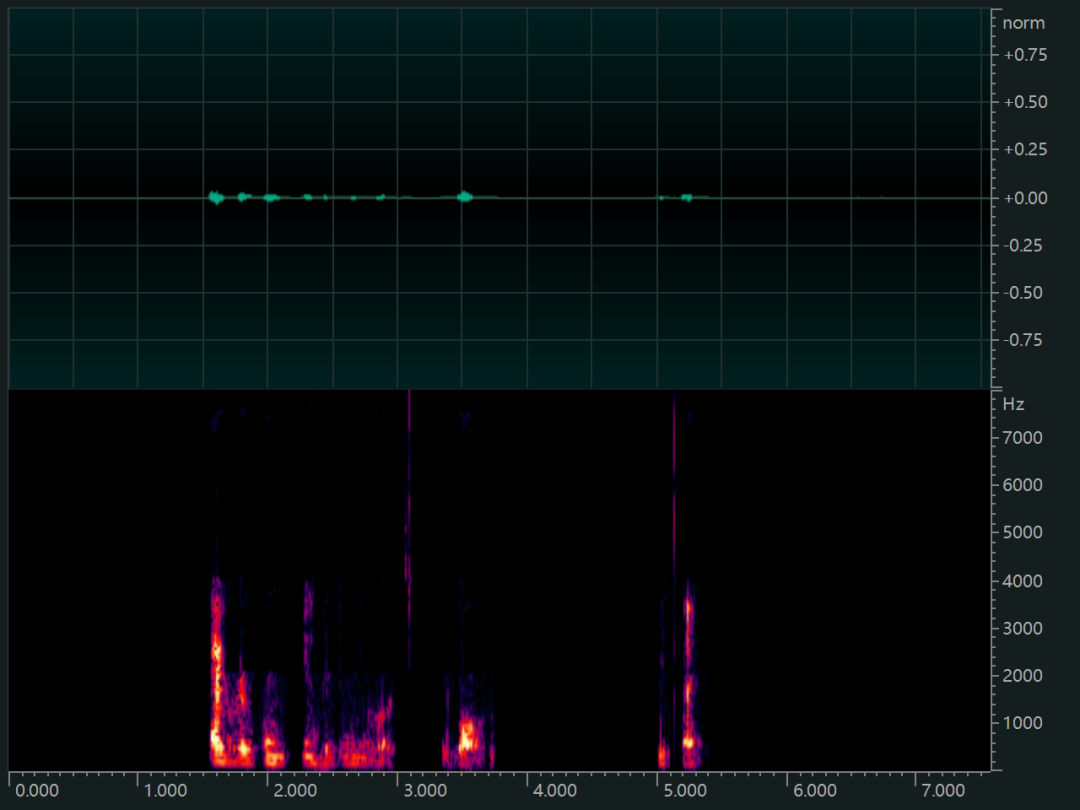
从频响曲线中看得更明显:
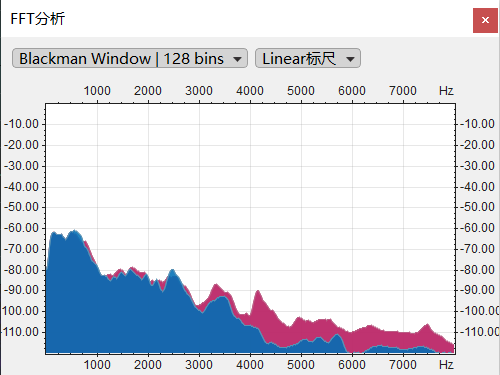
Lyra中高频部分明显低于原始音频,但是低频部分保留的较为完整,这就可以满足听得懂这个最低的要求。但是由于高频的缺失会导致,听起来声音很闷,不够明亮。由于本人精力有限,没有办法进行较为详细的评测,读者要是有兴趣可以自行实验。
IV. Conclusion
总的来说,对于一个实用的语音编解码应该满足两个部分:
合理的时间复杂度
处理多种多样的语音输入
对于第一点可以通过轻量化模型的方法比如稀疏模型或者使用GRU的生成模型代替WaveNet这种计算量巨大的模型;对于第二点,可以使用频谱特征,并且在训练的过程设计损失函数对待噪声的样本进行一定程度的惩罚。
那么语音编解码的终极模式是什么样子的呢?

本文相关代码在公众号语音算法组菜单栏点击Code获取
参考文献:
[1]. https://ai.googleblog.com/2021/02/lyra-new-very-low-bitrate-codec-for.html
[2]. https://github.com/google/lyra
[3]. https://wenku.baidu.com/view/9be752ee5bf5f61fb7360b4c2e3f5727a5e92466.html
[4]. https://en.wikipedia.org/wiki/Category:Speech_codecs
[5]. On the information rate of speech communication
[6]. GENERATIVE SPEECH CODING WITH PREDICTIVE VARIANCE REGULARIZATION