JVM 执行引擎在执行 Java 代码时有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种选择;
HotSpot 实际的实现中,模版解释器工作时,并不是按照概念模型中进行机械式计算,而是动态生成每一条字节码对应的汇编代码来运行;
文章目录
- 1. 解释执行
- 2. 基于栈的指令集与基于寄存器的指令集
- 3. 基于栈的解释器执行过程
1. 解释执行
笼统的说 Java 是解释执行是没有意义的,需要结合具体 JVM 实现版本和执行引擎运行模式来看;
Java 还发展出了直接生成本地代码的编译器(Jaotc、GCJ、Excelsior JET),C/C++ 语言也出现了通过解释器执行的版本(CINT);
大部分程序语言(基于物理机、Java 虚拟机、其他非 Java 高级语言虚拟机 HLLVM)代码转换成物理机的目标代码或虚拟机能执行的指令集之前,需要经过如下步骤;
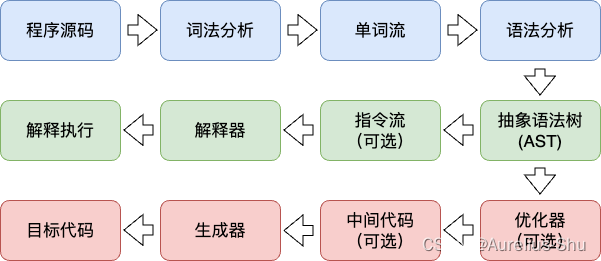
Java 中 javac 编译器完成了程序代码的词法分析、语法分析最终经过抽象语法树生成字节码指令流;这部分是独立于 JVM 之外完成,而解释器实在 JVM 内部,所以 Java 的编译是半独立实现的;
2. 基于栈的指令集与基于寄存器的指令集
基于栈的指令架构(Instruction Set Architecture,ISA),大部分指令是零地址指令,依赖于操作数栈进行工作;
基于寄存器的指令集,典型的如 x86 的二地址指令集,主流 PC 机物理硬件直接支持的指令集架构,依赖于寄存器进行工作;
1 + 1 演示
// 基于栈的指令集
iconst_1
iconst_1
iadd
istore_0
iconst_1 指令将常量 1 压入栈,连续两次,iadd 指令将栈顶两个值出栈、相加、把结果放回栈顶;最后 istore_0 指令把栈顶的值放回局部变量表的第 0 个变量槽;
// 基于寄存器的指令集
mov eax, 1
add eax, 1
mov 指令将 EAX 寄存器的值设置为 1,add 指令再把这个值加 1,结果就保存在 EAX 寄存器中;每个指令包含两个单独的输入参数,依赖于寄存器来访问和存储数据;
基于栈的指令集 vs. 基于寄存器的指令集
- (优点)由于寄存器与硬件绑定,基于栈的指令集不直接使用寄存器,因此可移植,而基于寄存器的指令集的代码受硬件的约束;
- (优点)基于栈的指令集可以有 VM 自行实现,可将一些访问最频繁的数据(程序计数器、栈顶缓存等)放到寄存器以获得更好的性能;
- (优点)基于栈的指令集代码更紧凑,编译器实现更简单(不需要考虑空间分配问题);基于计数器的指令集还要存参数;
- (缺点)基于栈的指令集理论上稍慢于寄存器架构的指令集(解释执行状态),完成相同功能所需的指令数量一般也会更多(出入站操作都需要相应指令);
- (缺点)基于栈的指令集操作在内存中,相对处理器来说,内存是执行速度的瓶颈;
3. 基于栈的解释器执行过程
算术代码演示
public int calc() {
int a = 100;
int b = 200;
int c = 300;
return (a + b) * c;
}
javap 查看字节码
public int calc();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=4, args_size=1
0: bipush 100
2: istore_1
3: sipush 200
6: istore_2
7: sipush 300
10: istore_3
11: iload_1
12: iload_2
13: iadd
14: iload_3
15: imul
16: ireturn
LineNumberTable:
line 18: 0
line 19: 3
line 20: 7
line 21: 11
LocalVariableTable:
Start Length Slot Name Signature
0 17 0 this Ledu/aurelius/jvm/clazz/GrandFather;
3 14 1 a I
7 10 2 b I
11 6 3 c I
解释执行过程演示
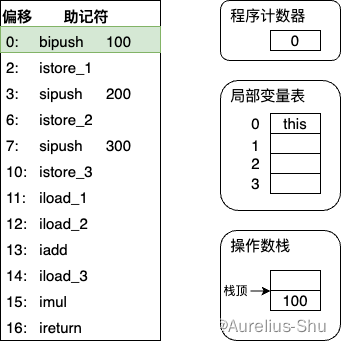
- 执行偏移地址为 0 的指令,bipush 将单字节的整型常量(-128 ~ 127)压入操作数栈顶,这里是 100;
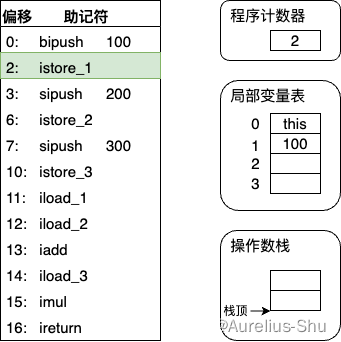
- 执行偏移地址为 2 的指令,istore_1 将操作数栈栈顶的整型值出栈并放入第 1 个局部变量槽(后续 4 条指令做相同的事情,这里略过);
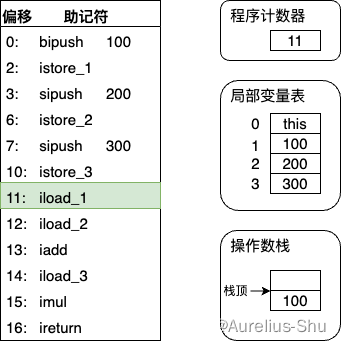
- 执行偏移地址为 11 的指令,iload_1 指令将局部变量表第 1 个变量槽的整型值压入操作数栈(后续 1 条指令做相同事情,这里略过);

- 执行偏移地址为 13 的指令,iadd 将操作数栈的头两个栈顶元素出栈,做整型加法,并将结果压入栈顶;
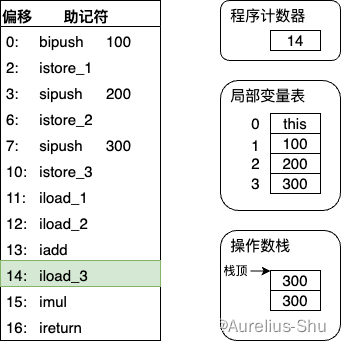
- 执行偏移地址为 14 的指令,iload_3 指令将局部变量表第 3 个变量槽的整型值压入操作数栈(后续 1 条指令对栈顶头两个元素做出栈、整型乘法、结果入栈的操作,与 iadd 类似,这里略过);
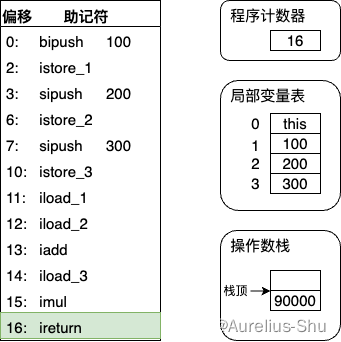
- 执行偏移地址为 16 的指令,ireturn 指令是方法返回指令,结束方法执行,并将操作数站定的整型值返回给方法的调用者;
实际执行过程会经过解释器(对字节码指令做合并、替换)和即时编译器对字节码的一系列性能优化,与上面的概念模型差距可能非常大,这里仅演示栈架构指令集的一般运行过程(中间变量以操作数栈的出入栈交换信息);
上一篇:「JVM 执行引擎」动态类型语言支持
下一篇:「JVM 原理使用」 实际开发中的应用
PS:感谢每一位志同道合者的阅读,欢迎关注、评论、赞!
参考资料:
- [1]《深入理解 Java 虚拟机》