1、资源准备:
(1)jdk安装包:我的是1.8.0_202
(2)hadoop安装包:我的是hadoop-3.3.1
 注意这里不要下载成下面这个安装包了,我就一开始下载错了
注意这里不要下载成下面这个安装包了,我就一开始下载错了
错误示例:![]()
2、主机网络相关参数准备
这里主要涉及hostname改写、hosts修改和ip地址改写
(1)修改hostname。这里我用了3台虚拟机,1台改为master,另外2台分别改为node1和node2
cd /etc/ // 进入配置目录
vi hostname // 编程hostname 配置文件![]()
(2)修改hosts。这里根据每台虚机的ip选择相应的hostname就行
vi /etc/hosts (3)IP地址改写,这里需要修改虚机的配置,选择NAT模式,DHCP选择想要的网段就行。
(3)IP地址改写,这里需要修改虚机的配置,选择NAT模式,DHCP选择想要的网段就行。

注意:以上的操作需要在每台虚机上分别执行 !!!
3、配置ssh免密登陆
这一步在master主机上操作,一直按回车:
ssh-keygen 会生成以下4个文件:
![]()
之后使用以下命令将密钥分发到node1和node2:
ssh-copy-id root@node1
ssh-copy-id root@localhost
ssh-copy-id root@node2成功后就应该能免密登陆node1和node2了:
![]()
4、配置java环境
我将jdk安装包和hadoop安装包都放在master主机/opt目录下了,同时新建一个bigdata目录:

(1)首先需要解压jdk安装包,并将解压后的文件夹放进bigdata目录:
tar -zxvf jdk-8u202-linux-x64.tar.gz
mv jdk1.8.0_202/ bigdata/(2)然后配置java环境变量:
vi /etc/profile 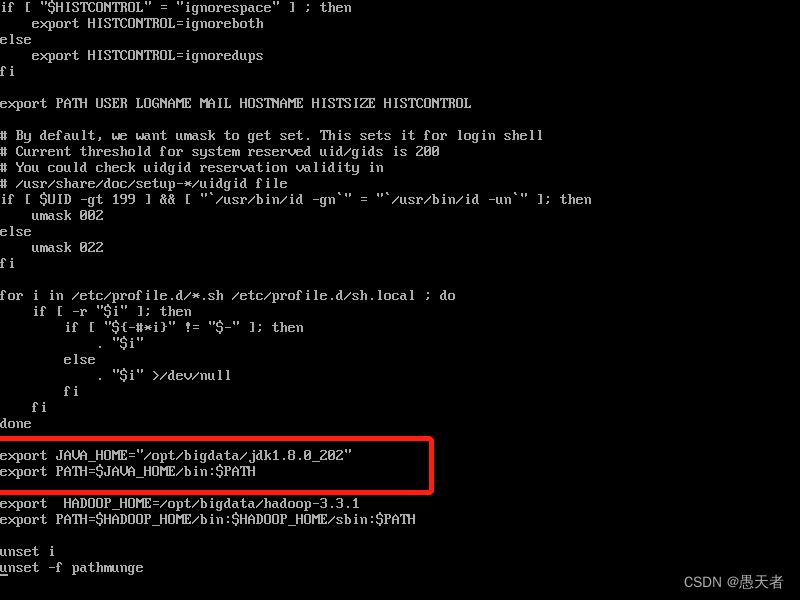
配置完生效并验证是否成功:
source /etc/profile
java -version #验证环境是否配置成功 
5、安装hadoop
同样是先解压然后移动到bigdata目录:
tar -zxvf hadoop-3.1.1.tar.gz
mv hadoop-3.1.1 bigdata/接着同样是配置环境变量:
vi /etc/profile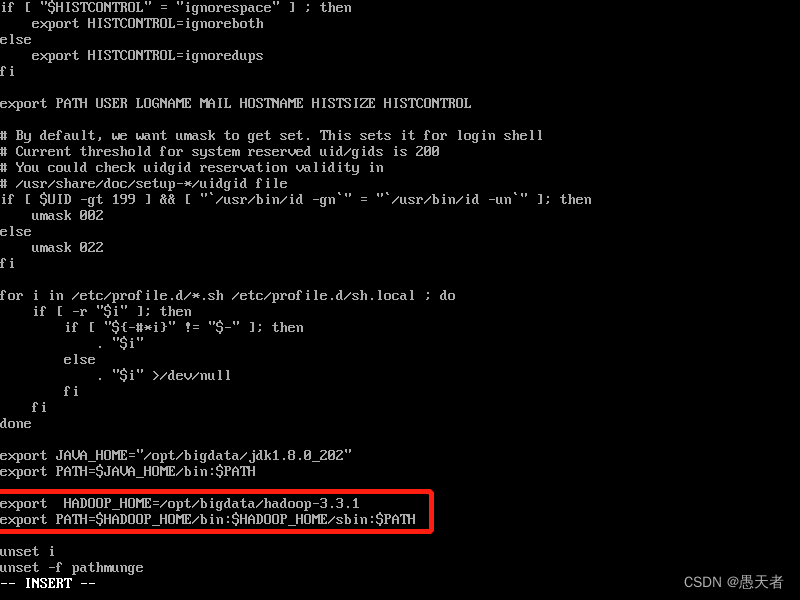
配置完生效并验证是否成功:
source profile
hadoop verison 
6、配置hadoop
这一步需要对hadoop下的 core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml、yarn-site.xml等文件进行配置。
首先进入存放文件的目录:
cd /opt/bigdata/hadoop-3.3.1/etc/hadoop/ 
(1)配置hadoop-env.sh
vi命令打开文件,输入 :/export JAVA_HOME 查找需要修改的地方并修改(注意将版本号换成自己的):
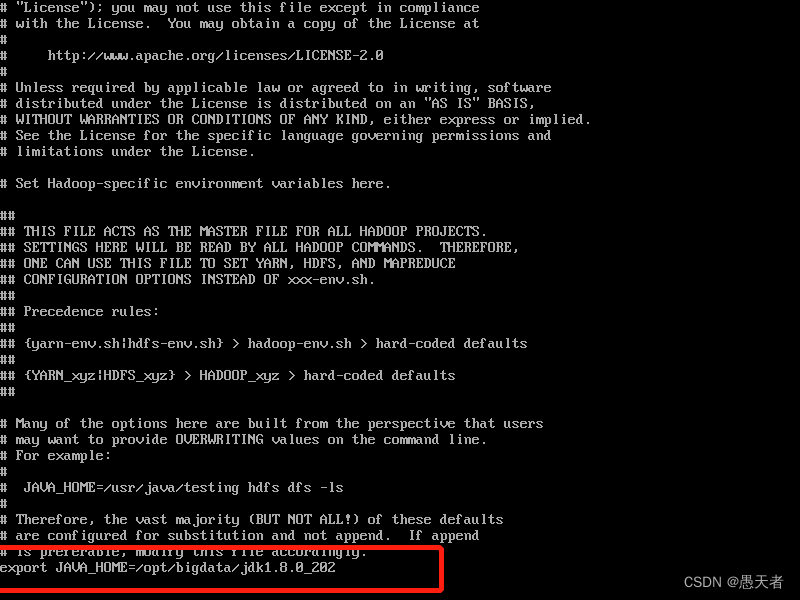
(2)配置 core-site.xml
vi命令打开文件,找到一对尖括号框起来的configuration位置,插入(注意将版本号换成自己的):
<configuration>
<property>
<name>fs.default.name</name>
<value>localhost:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/opt/bigdata/hadoop-3.3.1/temp</value>
</property>
</configuration>修改成如下:

(3)配置hdfs-site.xml
vi打开文件同样在configuration处插入(注意将版本号换成自己的):
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/opt/bigdata/hadoop-3.3.1/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.3.1/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>(4)配置mapred-site.xml
同样的操作:
<configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/opt/bigdata/hadoop-3.3.1/etc/hadoop,
/opt/bigdata/hadoop-3.3.1/share/hadoop/common/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/common/lib/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/hdfs/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/hdfs/lib/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/mapreduce/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/mapreduce/lib/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/yarn/*,
/opt/bigdata/hadoop-3.3.1/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
(5)配置下yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>(6)配置workers
在当前目录修改workers文件:
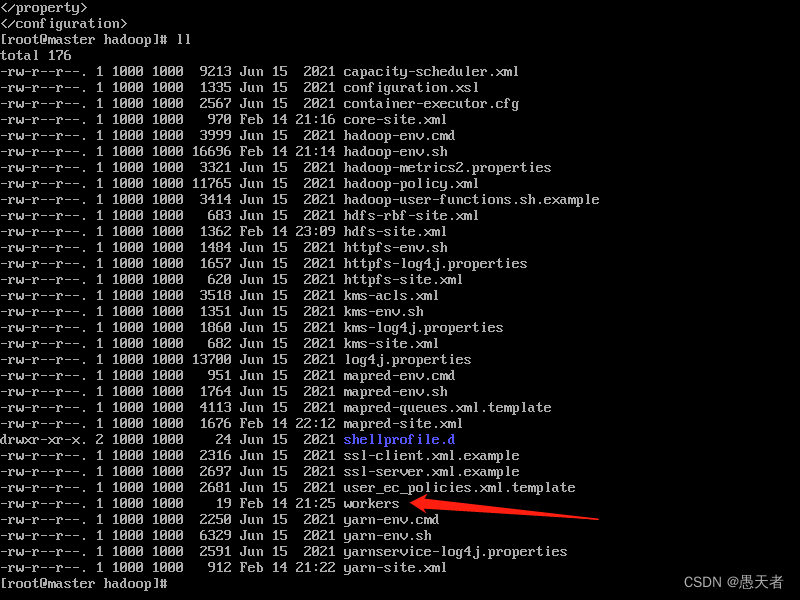
最后只有master、node1和node2:

7、环境的配置已经改完了。接着还需要修改一下启动脚本的参数:
进入到sbin目录:
cd /opt/bigdata/hadoop-3.3.1/sbin(1) 在start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(2)start-yarn.sh,stop-yarn.sh顶部也需添加以下参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
至此,所有的配置都已经做完了,现在需要将配置文件分发到两个子节点去(子节点没有bigdata文件夹需要新建一个):
scp -r /opt/bigdata/hadoop-3.3.1 node1:/opt/bigdata
scp -r /opt/bigdata/hadoop-3.3.1 node2:/opt/bigdata接着分别在两个子节点上执行下面命令生效配置:
source /etc/profile
source ~/.bashrc最后就可以开始准备启动hadoop集群了。
(1)第一次启动需要初始化hdfs,在 /opt/bigdata/hadoop-3.3.1/bin目录下执行:
./hdfs namenode -format出现如下语句表示初始化成功:
![]()
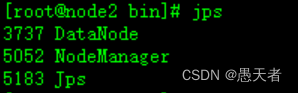
(2)进入/opt/bigdata/hadoop-3.3.1/sbin目录执行最后的集群启动命令:
./start-all.sh 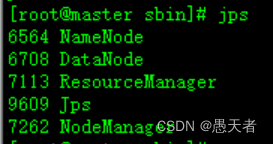

参考:Hadoop 平台搭建完整步骤