文章目录
- 1. 什么是线程池
- 2. 为什么使用线程池
- 3. 线程的作用
- 4. 如何创建线程池
- 5. 线程持底层是如何实现复用的
- 6. 手写一个简易的线程池
- 7. ThreadPoolExecutor构造函数原理
- 8. 线程池创建的线程会一直运行下去吗?
- 9. 线程池队列满了任务会丢失吗?
- 分析情况
- 有界队列情况下
- 如何解决?
- 1. 解决线程池队满
- 2. 服务宕机导致服务丢失
- 执行效果
- 10. 线程池的执行流程
- 11. 线程的状态都有哪些?
- 12. 线程状态之间的转换
- 13. 自定义线程池
- 14. Executors提供了哪些创建线程池的方法?
- 15. 使用队列有什么需要注意的吗?
- 16. 线程只能在任务到达时才启动吗?
- 17. 核心线程怎么实现一直存活?
- 18. 如何终止线程池?
- 19. 实际使用中,线程池的大小配置多少合适?
1. 什么是线程池
线程池和数据库连接池类似,可以统一管理维护线程,减少没有必要的开销,就是说你在需要启动线程的时候没有必要自己创建了,只需要从线程池拿就行了,如果用完了还回去就行了没必要创建一个新的,比如说我需要100个线程,我如果说直接创建100个线程一个任务占用一份,用完就扔跟方便筷子似的那就太浪费了。我可以创建一个线程池里面只有10个线程,然后用完了还回来,下一个任务来了接着用,那这样的话我就开10个线程就行了。至于说谁先用,怎么用可以通过线程池去维护。
2. 为什么使用线程池
如果我们在方法中直接new一个线程来处理,当这个方法被调用频繁时就会创建很多线程,不仅会消耗系统资源,还会降低系统的稳定性。
- 降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 增加线程的可管理型。线程是稀缺资源,使用线程池可以进行统一分配,调优和监控。
3. 线程的作用
- 降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
- 提高响应速度:任务到达时,无需等待线程创建即可立即执行。
- 提高线程的可管理性:线程时稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
- 提供更多更强大的功能:线程池具备可扩展性,允许开发人员向其中增加更多的功能,比如延时定时线程池,ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
4. 如何创建线程池
-
Executors new CachedThreadPool():可缓存线程池
-
Executors new FixedTheadPool():可定长度
-
Executors new ScheduledThreadPool():可定时
-
Executors new SingleTheadExecutor():单例
-
底层都是基于ThreadPoolExecutor构造函数封装
5. 线程持底层是如何实现复用的
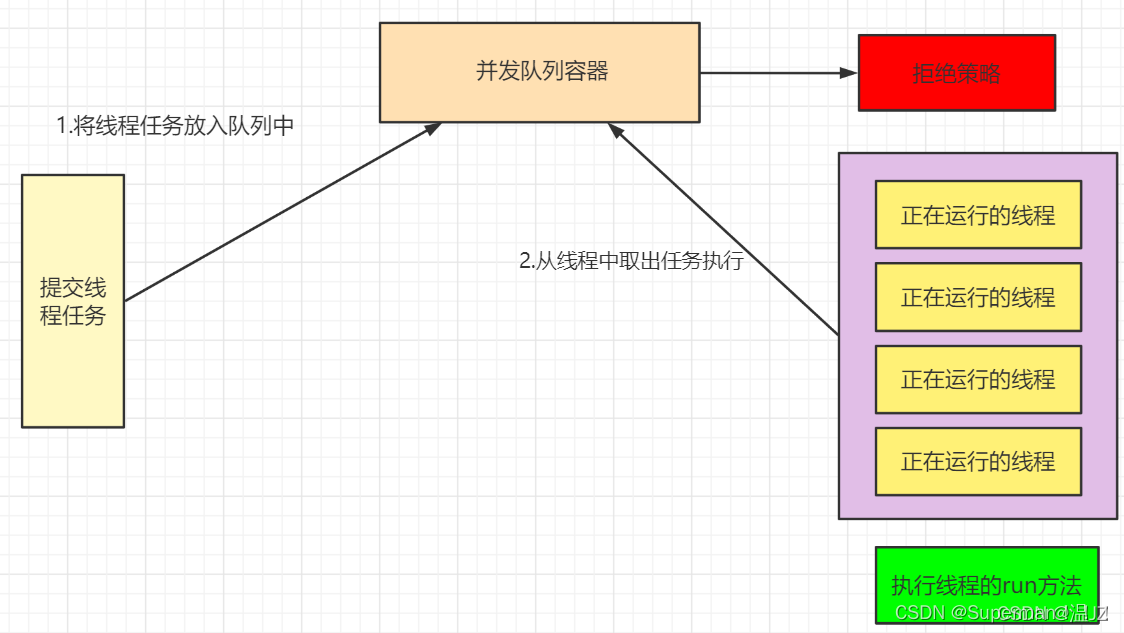
首先我先创建好固定的线程一直在运行状态,这个就相当于我们创建一个线程run方法里面写一个死循环,他就一直在运行状态了。然后提交的任务线程会缓存到一个并发队列集合中,交给我们正在运行的线程执行,正在运行的线程就从队列中获取该任务执行。当队列满了就执行拒绝策略。
6. 手写一个简易的线程池
手写一个线程池需要首先创建一个任务队列,存放各种任务,然后需要规定线程池中线程的个数,以及要执行的任务数。首先我们要创建一个工作线程的类,为了保证这些线程能够一直运行,我们要在里面写一个死循环while的两个条件一个他是否运行我们默认为true,当所有任务执行完我们可以手动改为false,然后就是任务队列的大小。如果任务队列里面有任务就把他取出来,执行run方法,如果没有就是死循环。
完整代码:
public class SJGExecutors {
// 任务队列,存放各种任务
private BlockingQueue<Runnable> threadJobQueue;
// 最大线程数
private int maxThreadCount;
// 是否在运行
public boolean isRun = true;
/**
* 构造函数里边需要规定最大线程数以及这个任务数
* 创建线程之前我们需要先创建任务队列,不然的话执行到threadJobQueue.poll的时候会出现空指针异常。
*
* @param maxThreadCount 最大线程数
* @param jobCount 任务数
*/
public SJGExecutors(int maxThreadCount, int jobCount){
this.maxThreadCount = maxThreadCount;
threadJobQueue = new LinkedBlockingDeque<Runnable>(jobCount);
for (int i = 0; i < maxThreadCount; i++) {
new workThread().start();
}
}
/**
* 创建一个任务队列,存放各种任务
*/
private class workThread extends Thread{
@Override
public void run(){
while(isRun || threadJobQueue.size() > 0){
Runnable command = threadJobQueue.poll();
if (command != null){
command.run();
}
}
}
}
/**
* 首先先把这个任务入队,然后线程正在运行的时候从队列里取出执行他的run()方法
*
* @param job 任务
* @return
*/
private boolean execute(Runnable job){
return threadJobQueue.offer(job);
}
public static void main(String[] args) {
SJGExecutors sjgExecutors = new SJGExecutors(2, 10);
for (int i = 0; i < 10; i++) {
final int num = i;
sjgExecutors.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "----" + num);
}
});
}
sjgExecutors.isRun = false;
}
}
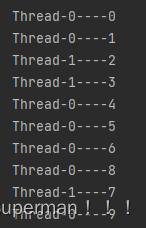
运行结果:
7. ThreadPoolExecutor构造函数原理
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
- corePoolSize:核心线程数即一直运行的线程数
- maximumPoolSize:最大线程数
- keepAliveTime:超出corePoolSize后创建线程的存活时间
- unit:KeepAliveTime的时间单位
- workQueue:任务队列,用于保存待执行的任务
- threadFactory:线程池内部创建线程所用的工厂
- handler:任务无法执行时的处理器
8. 线程池创建的线程会一直运行下去吗?
不会。参数中有两个东西一个是corePoolSize核心线程数,一个是maximumPoolSize最大线程数,核心线程数会一直运行,但是如果超过超时时间(keepAliveTime)还没有任务执行那就停止该线程。如果任务太多,corePoolSize忙不过来了,就会再额外创建线程,但不能超过(maximumPoolSize - corePoolSize)个。
9. 线程池队列满了任务会丢失吗?
分析情况
- 如果使用的是无界队列 LinkedBlockingQueue,也就是无界队列的话,没关系,继续添加任务到阻塞队列中等待执行,因为 LinkedBlockingQueue 可以近乎认为是一个无穷大的队列,可以无限存放任务
- 如果使用的是有界队列比如 ArrayBlockingQueue,任务首先会被添加到ArrayBlockingQueue中,ArrayBlockingQueue 满了,会根据maximumPoolSize 的值增加线程数量,如果增加了线程数量还是处理不过来,ArrayBlockingQueue 继续满,那么则会使用拒绝策略RejectedExecutionHandler处理满了的任务,默认是 AbortPolicy
有界队列情况下
不会!如果队列满了,而且任务总数>最大线程数则当前线程走拒绝策略。可以自定义拒绝异常,将该任务缓存到redis,本地文件,mysql中后期项目启动实现补偿。同时你也可以在构造函数中传入参数,决定如何处理。
return new ThreadPoolExecutor(corePoolSize, maximumPoolSize,
60L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(blockingQueue), (RejectedExecutionHandler) new ThreadPoolExecutor.DiscardPolicy ());
- AbortPolicy:中止策略。丢弃任务,抛运行时异常。
- CallerRunsPolicy:调用者运行策略。在调用者线程中执行该任务。该策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将任务回退到调用者(调用线程池执行任务的主线程),由于执行任务需要一定时间,因此主线程至少在一段时间内不能提交任务,从而使得线程池有时间来处理完正在执行的任务。
- DiscardPolicy:抛弃策略。忽视,什么都不会发生
- DiscardOldestPolicy:抛弃最老策略。从队列中踢出最先进入队列(最后一个执行)的任务。
- 实现RejectedExecutionHandler接口,可自定义处理器。
自己定义处理器
public class MayiktExecutionHandler implements ThreadFactory, RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(r.getClass()+":自定义拒绝线程任务");
r.run();
}
@Override
public Thread newThread(Runnable r) {
return null;
}
}
如何解决?
- 改写拒绝策略,延迟任务重新投向线程池
- 打印对应任务参数,可以做塞回数据库,或者打印出来方便排查问题。
1. 解决线程池队满
- 可以根据自己的业务需求,通过RejectedExecutionHandler接口自定义拒绝策略,比如把线程无法执行的任务持久化到数据库中,后台专门启动一个线程,后续线程池的负载降低了,可以慢慢从数据库中读取持久化的任务到线程池。
2. 服务宕机导致服务丢失
- 如果队列里的任务请求只存在于内存,没有持久化的话,服务宕机队列中的请求肯定会宕机。可以在提交到线程池前,先把任务信息插到数据库,状态为未提交,提交到线程池之后改为已提交,任务完成之后改为已完成。服务器宕机后通过后台线程把未提交和已提交的任务重新加入到线程池中。
代码
public class ThreadPoolPolicy {
/**
* 重写拒绝策略
*/
static class RetryPolicy implements RejectedExecutionHandler {
private DelayQueue<PullJobDelayTask> queue = new DelayQueue<>();
private int i = 0;
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
if(r instanceof MyThread){
MyThread thread = (MyThread) r;
System.out.println("异常线程参数:{}"+ thread);
}
// 将任务投放到线程池
queue.offer(new PullJobDelayTask(5, TimeUnit.SECONDS, r));
System.out.println("等待5秒...");
if(i>0){
return;
}
CompletableFuture.runAsync(()-> {
System.out.println("新增线程池...");
while (true) {
try {
System.out.println("拉取任务...");
PullJobDelayTask task = queue.take();
executor.execute(task.runnable);
} catch (Exception e) {
System.out.println("抛出异常,{}"+e);
}
}
});
i++;
}
}
static class MyThread implements Runnable{
int count;
public MyThread(int count) {
this.count = count;
}
@Override
public void run() {
System.out.println("数量 = "+ count);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 延迟任务
*/
static class PullJobDelayTask implements Delayed {
private long scheduleTime;
private Runnable runnable;
public PullJobDelayTask(long scheduleTime, TimeUnit unit, Runnable runnable) {
this.scheduleTime = System.currentTimeMillis() + (scheduleTime > 0 ? unit.toMillis(scheduleTime) : 0);
this.runnable = runnable;
}
@Override
public int compareTo(Delayed o) {
return (int) (this.scheduleTime - ((PullJobDelayTask) o).scheduleTime);
}
@Override
public long getDelay(TimeUnit unit) {
return scheduleTime - System.currentTimeMillis();
}
}
/**
* 验证
*/
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 2, 10, TimeUnit.SECONDS, new ArrayBlockingQueue<>(1),Executors.defaultThreadFactory(),new RetryPolicy());
executor.execute(() -> {
try {
System.out.println("1");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executor.execute(() -> {
try {
System.out.println("2");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executor.execute(() -> {
try {
System.out.println("3");
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
MyThread thread = new MyThread(4);
executor.execute(thread);
}
}
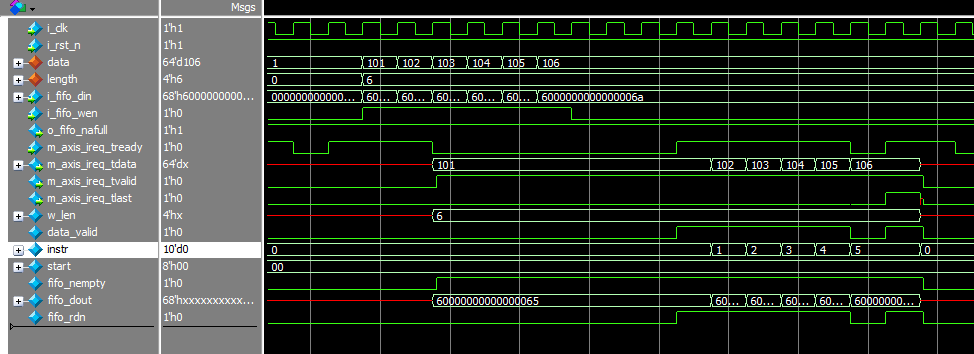
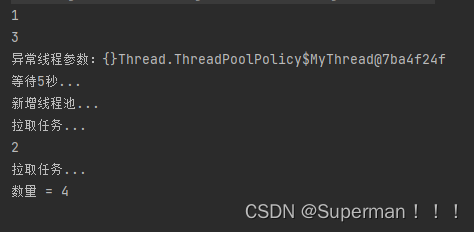
执行效果
10. 线程池的执行流程
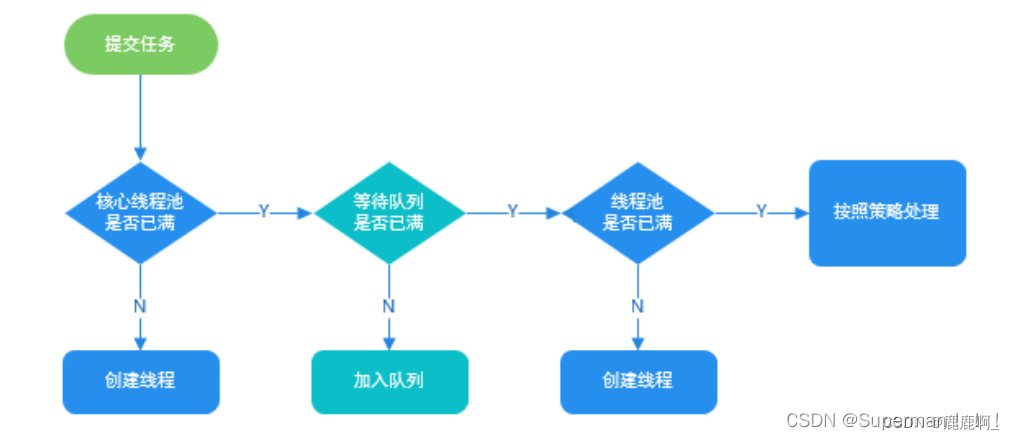
- 线程池实现原理
//线程池实现原理
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// 1.⾸先判断当前线程池中之⾏的任务数量是否小于 corePoolSize
// 如果小于的话,通过addWorker(command, true)新建⼀个线程,并将任务(command)
//添加到该线程中;然后,启动该线程从⽽执⾏任务。
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.如果当前执行的任务数量⼤于等于 corePoolSize 的时候就会⾛到这
// 通过 isRunning ⽅法判断线程池状态,线程池处于 RUNNING 状态才会被阻塞队列加⼊任务,该任务才会被加⼊进去
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执⾏完毕。同时执⾏拒绝策略。
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果当前线程池为空就新创建⼀个线程并执⾏
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//3. 通过addWorker(command, false)新建⼀个线程,
//并将任务(command)添加到该线程中;然后,启动该线程从⽽执⾏任务。
//如果addWorker(command, false)执⾏失败,则通过reject()执⾏相应的拒绝策略的内容。
else if (!addWorker(command, false))
reject(command);
}
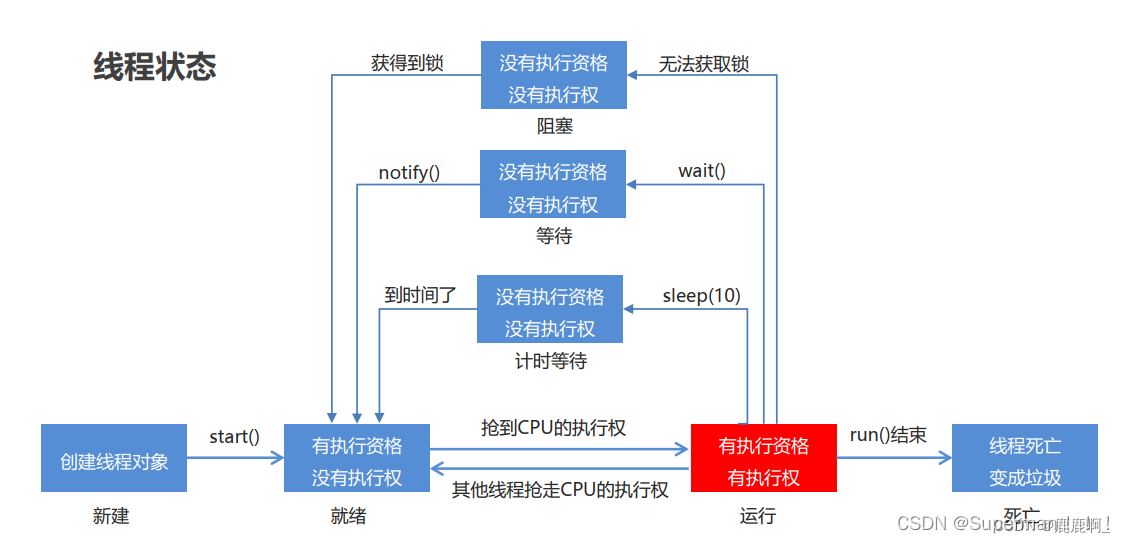
11. 线程的状态都有哪些?
- NEW – 尚未启动的线程处于此状态(创建线程对象)
- RUNNABLE – 在Java虚拟机中执行的线程处于此状态(start()开启线程)
- BLOCKED – 被阻塞等待监视器锁定的线程处于此状态(无法获得锁)
- WAITING – 正在等待另一个线程执行特定动作的线程处于此状态(wait()等待)
- TIMED_WAITING – 正在等待另一个线程执行动作达到指定等待时间的线程处于此状态(sleep)
- TERMINATED – 已退出的线程处于此状态(线程执行完毕任务)
12. 线程状态之间的转换
13. 自定义线程池
//TreadPoolExecutor(自定义参数线程池)(推荐使用)
public class ThreadPoolDemo {
public static void main(String[] args) {
//1. 使用ThreadPoolExecutor指定具体参数的方式创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2, //核心线程数
5, //池中允许的最大线程数
2, //空闲线程最大存活时间
TimeUnit.SECONDS, //秒
new ArrayBlockingQueue<>(10),//被添加到线程池中,但尚未被执行的任务
Executors.defaultThreadFactory(), //创建线程工厂,默认
new ThreadPoolExecutor.AbortPolicy()//,如何拒绝任务
);
//2. 执行具体任务
poolExecutor.submit(new MyRunnable());
poolExecutor.submit(new MyRunnable());
//3. 关闭线程池
poolExecutor.shutdown();
}
}
public class MyRunnable implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"执行了");
}
}
14. Executors提供了哪些创建线程池的方法?
- newFixedThreadPool:固定线程数的线程池。corePoolSize = maximumPoolSize,keepAliveTime为0,工作队列使用无界的LinkedBlockingQueue。适用于为了满足资源管理的需求,而需要限制当前线程数量的场景,适用于负载比较重的服务器。
- newSingleThreadExecutor:只有一个线程的线程池。corePoolSize = maximumPoolSize = 1,keepAliveTime为0, 工作队列使用无界的LinkedBlockingQueue。适用于需要保证顺序的执行各个任务的场景。
- newCachedThreadPool: 按需要创建新线程的线程池。核心线程数为0,最大线程数为 Integer.MAX_VALUE,keepAliveTime为60秒,工作队列使用同步移交 SynchronousQueue。该线程池可以无限扩展,当需求增加时,可以添加新的线程,而当需求降低时会自动回收空闲线程。适用于执行很多的短期异步任务,或者是负载较轻的服务器。
- newScheduledThreadPool:创建一个以延迟或定时的方式来执行任务的线程池,工作队列为 DelayedWorkQueue。适用于需要多个后台线程执行周期任务。
- newWorkStealingPool:JDK 1.8 新增,用于创建一个可以窃取的线程池,底层使用 ForkJoinPool 实现。
15. 使用队列有什么需要注意的吗?
- 使用有界队列时,需要注意线程池满了后,被拒绝的任务如何处理。
- 使用无界队列时,需要注意如果任务的提交速度大于线程池的处理速度,可能会导致内存溢出。
16. 线程只能在任务到达时才启动吗?
默认情况下,即使是核心线程也只能在新任务到达时才创建和启动。但是我们可以使用 prestartCoreThread(启动一个核心线程)或 prestartAllCoreThreads(启动全部核心线程)方法来提前启动核心线程。
17. 核心线程怎么实现一直存活?
阻塞队列方法有四种形式,它们以不同的方式处理操作,如下图。
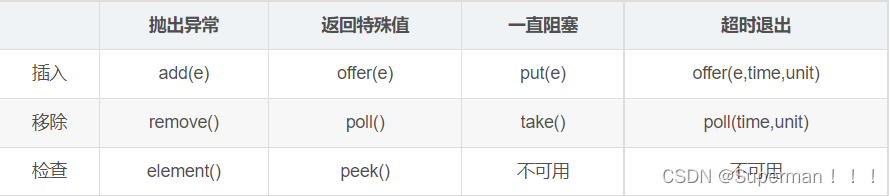
核心线程在获取任务时,通过阻塞队列的 take() 方法实现的一直阻塞(存活)。
18. 如何终止线程池?
- shutdown:“温柔”的关闭线程池。不接受新任务,但是在关闭前会将之前提交的任务处理完毕。
- shutdownNow:“粗暴”的关闭线程池,也就是直接关闭线程池,通过 Thread#interrupt() 方法终止所有线程,不会等待之前提交的任务执行完毕。但是会返回队列中未处理的任务。
19. 实际使用中,线程池的大小配置多少合适?
要想合理的配置线程池大小,首先我们需要区分任务是计算密集型还是I/O密集型。
对于计算密集型,设置线程数 = CPU数 + 1,通常能实现最优的利用率。
对于I/O密集型,网上常见的说法是设置 线程数 = CPU数 * 2 ,这个做法是可以的,但个人觉得不是最优的。
在我们日常的开发中,我们的任务几乎是离不开I/O的,常见的网络I/O(RPC调用)、磁盘I/O(数据库操作),并且I/O的等待时间通常会占整个任务处理时间的很大一部分,在这种情况下,开启更多的线程可以让 CPU 得到更充分的使用,一个较合理的计算公式如下:
线程数 = CPU数 * CPU利用率 * (任务等待时间 / 任务计算时间 + 1)
例如我们有个定时任务,部署在4核的服务器上,该任务有100ms在计算,900ms在I/O等待,则线程数约为:4 * 1 * (1 + 900 / 100) = 40个。
并且I/O的等待时间通常会占整个任务处理时间的很大一部分,在这种情况下,开启更多的线程可以让 CPU 得到更充分的使用,一个较合理的计算公式如下:
线程数 = CPU数 * CPU利用率 * (任务等待时间 / 任务计算时间 + 1)
例如我们有个定时任务,部署在4核的服务器上,该任务有100ms在计算,900ms在I/O等待,则线程数约为:4 * 1 * (1 + 900 / 100) = 40个。
当然,具体我们还要结合实际的使用场景来考虑。如果要求比较精确,可以通过压测来获取一个合理的值。