目录
- 1.Java 有哪些常用容器(集合)?
- 2.Collection 和 Collections 有什么区别?
- 3.List、Set、Map 之间的区别是什么?
- 4.HashMap 的长度为什么是 2 的 N 次方?源码中是如何保证的?
- 5.HashMap 和 Hashtable 的异同有哪些?
- 6.HashMap 与 ConcurrentHashMap 的异同有哪些?
- 7.poll() 方法和 remove() 方法有什么异同?
- 8.ArrayList 和 LinkedList 有什么区别?
1.Java 有哪些常用容器(集合)?
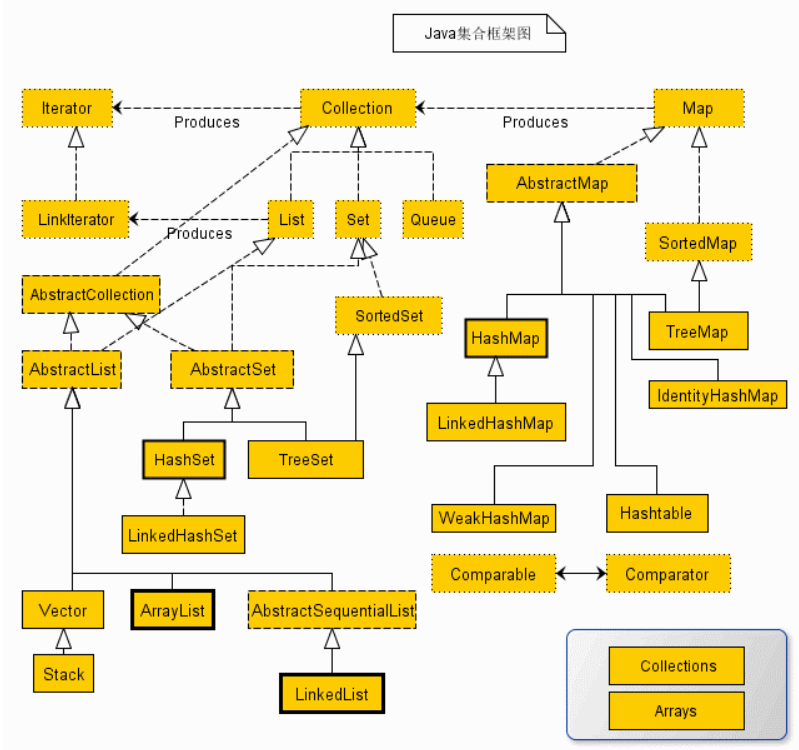
(1)从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
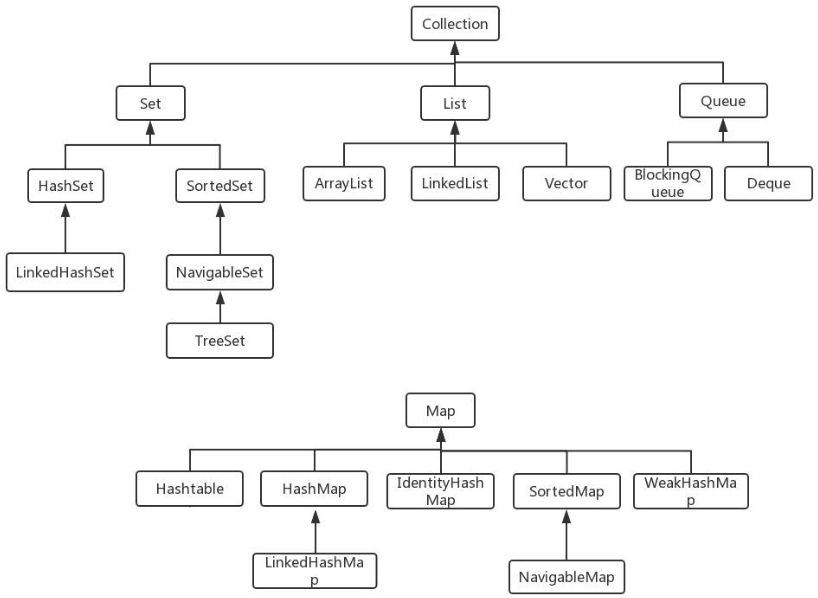
(2)集合框架体系如下图所示:
2.Collection 和 Collections 有什么区别?
(1)Collection 是 JDK 中集合层次结构中的最根本的接口,定义了集合类的基本方法。Collection 接口在 Java 类库中有很多具体的实现,其意义是为各种具体的集合提供了最大化的统一操作方式。
(2)Collections 是一个包装类,是 Collection 集合框架的工具类。它包含有各种有关集合操作的静态多态方法,不能实例化,比如排序方法: Collections. sort(list)。
3.List、Set、Map 之间的区别是什么?
(1)List:有序集合,元素可重复;
(2)Set:不重复集合,LinkedHashSet 按照插入排序,SortedSet 可排序,HashSet 无序;
(3)Map:键值对集合,存储键、值和之间的映射;Key无序且唯一;value 不要求有序,允许重复。
4.HashMap 的长度为什么是 2 的 N 次方?源码中是如何保证的?
(1)为了能让 HashMap 存数据和取数据的效率高,尽可能地减少 hash 值的碰撞,也就是说尽量把数据均匀地分配,每个链表或者红黑树的长度尽量相等。我们首先可能会想到通过取模操作来实现。取余 (%) 操作中如果除数是 2 的幂次,则等价于与其除数减一的与(&)操作,也就是说 hash % length == hash & (length - 1) 的前提是 length 是 2 的 N 次方。并且,采用二进制位操作 & ,相对于 % 能够提高运算效率。
注:HashMap 的初始长度是 16。
(2)在扩容迁移的时候不需要再重新通过哈希定位新的位置了。扩容后元素新的位置,要么在原脚标位,要么在原脚标位 + 扩容长度的位置。
(3)HashMap 源码中的 tableSizeFor(int cap) 可以保证其长度永远是是 2 的 N 次方
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
具体分析可参考这篇文章。
5.HashMap 和 Hashtable 的异同有哪些?
(1)出现的版本不一样,Hashtable 出现于 Java 发布的第一版本 JDK 1.0,HashMap 出现于 JDK 1.2。
(2)都实现了 Map、Cloneable、Serializable(当前 JDK 版本 1.8)。
(3)HashMap 继承的是 AbstractMap,并且 AbstractMap 也实现了 Map 接口。Hashtable 继承Dictionary。
(4)Hashtable 中大部分 public 修饰普通方法都是 synchronized 字段修饰的,是线程安全的,HashMap 是非线程安全的。
(5)Hashtable 的 key 不能为 null,value 也不能为 null,这个可以从 Hashtable 源码中的 put 方法看到,判断如果 value 为 null 就直接抛出空指针异常,在 put 方法中计算 key 的 hash 值之前并没有判断 key 为 null 的情况,那说明,这时候如果 key 为空,照样会抛出空指针异常。
(6)HashMap 的 key 和 value 都可以为 null。在计算 hash 值的时候,有判断,如果 key==null ,则其 hash=0 ;至于 value 是否为 null,根本没有判断过。
(7)Hashtable 直接使用对象的 hash 值。hash 值是 JDK 根据对象的地址或者字符串或者数字算出来的 int 类型的数值。然后再使用除留余数法来获得最终的位置。然而除法运算是非常耗费时间的,效率很低。HashMap 为了提高计算效率,将哈希表的大小固定为了 2 的幂,这样在取模预算时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。
(8)Hashtable、HashMap 都使用了 Iterator。而由于历史原因,Hashtable 还使用了 Enumeration 的方式。
(9)默认情况下,初始容量不同,Hashtable 的初始长度是 11,之后每次扩充容量变为之前的 2 * n+1(n 为上一次的长度)而 HashMap 的初始长度为 16,之后每次扩充变为原来的两倍。
具体细节可参考这篇文章。
6.HashMap 与 ConcurrentHashMap 的异同有哪些?
(1)都是 key-value 形式的存储数据;
(2)HashMap 是线程不安全的,ConcurrentHashMap 是 JUC 下的线程安全的;
(3)HashMap 底层数据结构是数组 + 链表(JDK 1.8 之前)。JDK 1.8 之后是数组 + 链表 + 红黑树。当链表中元素个数达到 8 的时候,链表的查询速度不如红黑树快,链表会转为红黑树,红黑树查询速度快;
(4)HashMap 初始数组大小为 16(默认),当出现扩容的时候,变为原来的两倍;
(5)ConcurrentHashMap 在 JDK 1.8 之前是采用分段锁来现实的 Segment + HashEntry,
(6)Segment 数组大小默认是 16,2 的 n 次方;JDK 1.8 之后,采用 Node + CAS + Synchronized 来保证并发安全进行实现。
具体细节可参考这篇文章
7.poll() 方法和 remove() 方法有什么异同?
(1)相同点:poll() 和 remove() 都是从队列中取出一个元素;
(2)不同点:poll() 在获取元素失败的时候会返回空,但 remove() 失败的时候会抛出异常。
8.ArrayList 和 LinkedList 有什么区别?
(1)底层数据结构
ArrayList 是基于动态数组实现的,在一片连续的内存空间中存储数据。
LinkedList 是基于链表实现的,数据可以存储在分散的内存空间中。
(2)读取、插入、删除操作
由于底层数据结构的不同,读取、插入、删除操作的性能也会有所不同。
① 在读取方面 ArrayList 的性能比 LinkedList 高,ArrayList 支持通过索引访问(也称随机访问),可以在 O(1) 的时间复杂度内进行随机读取。而 LinkedList 需要从头开始遍历直到找到目标元素为止,其时间复杂度为 O(n)。
② 对于插入、删除操作,一般来说,LinkedList 的性能要比 ArrayList 高。ArrayList 在插入和删除元素时,可能需要进行元素移动甚至扩容操作;而 LinkedList 只需找到要插入的位置并实例化对象,然后修改节点指针即可。不过需要注意的是如果 ArrayList 使用尾插法并指定初始容量,这可以极大地提升性能,甚至超过 LinkedList。
(3)遍历操作
ArrayList 和 LinkedList 常见的遍历方式有 3 种:for(结合 get(i) 方法)、foreach、iterator。
① 在数据量比较小时,不同遍历方式的性能差别不大。
② 但是在数据量比较大时:
对于 ArrayList 来说,3 种遍历方式差距不是很大,其中 for 循环的效率最高,因为采用直接的下标运算。对于 LinkedList 来说,迭代器效率最高,因为其相当于维护一个当前状态指针,遍历只需要扫描一遍双向链表即可,而 for 效率最低,因为需要扫描 n 遍链表。不难看出,两种 List 中,foreach 的效率都比迭代器略低,因为其底层就是由迭代器实现的,只不过为了方便书写,做了简单的封装。
具体细节可参考 ArrayList 和 LinkedList 的三种遍历方式 这篇文章。
(4)内存空间利用率
一般来说,存储相同类型、相同大小的数据时,LinkedList 比 ArrayList 更占内存,其内存空间利用率更低,因为 LinkedList 为每一个节点存储了两个引用节点,一个指向前一个元素,另一个指向下一个元素。不过有时在 ArrayList 列表的结尾预留一定的容量空间,这也会造成一定的内存空间的浪费。
(5)扩容问题
ArrayList 使用动态数组实现,无参构造函数中默认初始化长度为 10,当需要扩容时会将原数组中的元素重新拷贝到长度为原数组的 1.5 倍的新数组中,扩容代价比较高;LinkedList 通过链表实现,所以不存在扩容问题,新增元素直接放到集合尾部,并修改相应的指针节点即可。