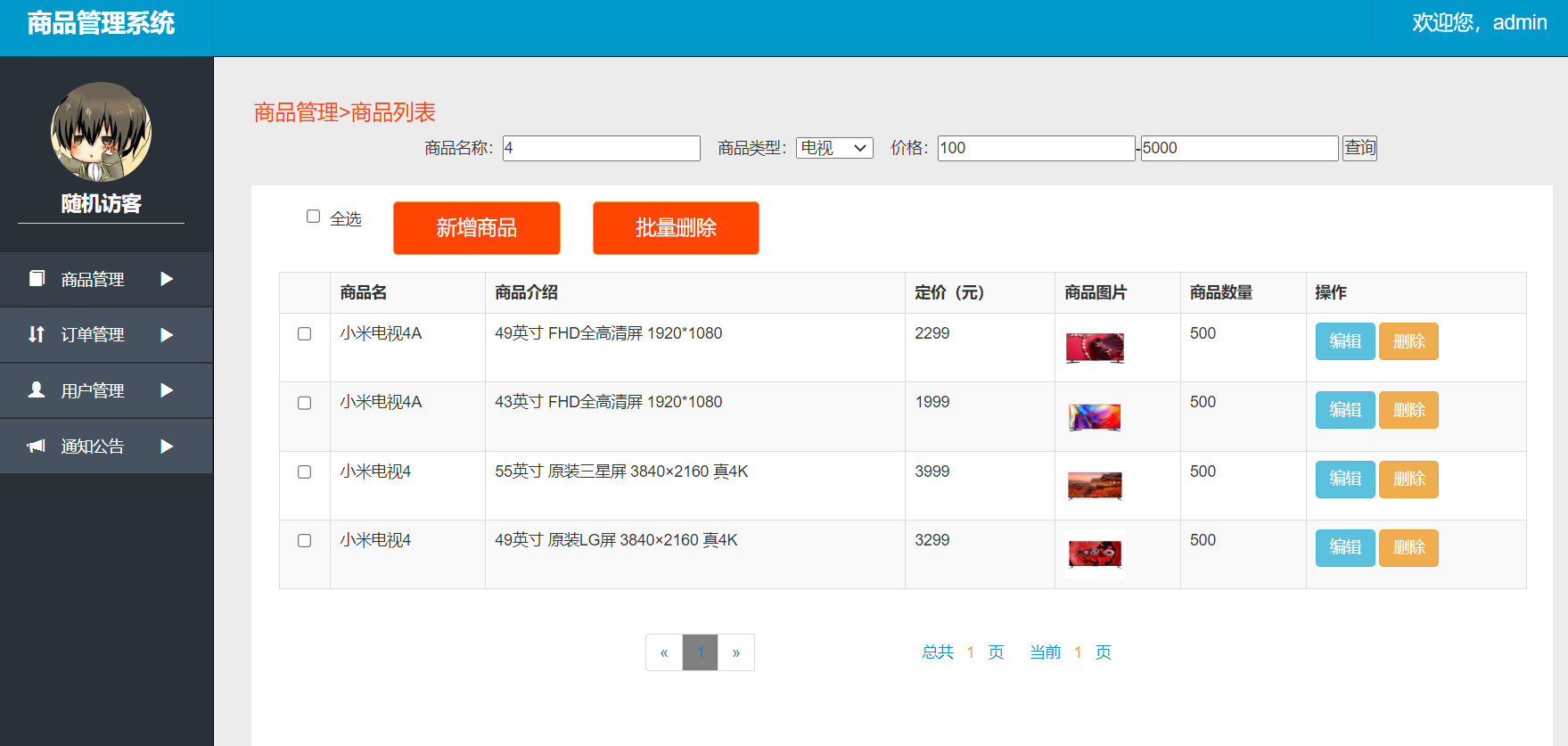
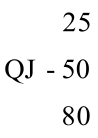栈是编程中使用内存最简单的方式。例如,下面的简单代码中的局部变量 n 就是在堆栈中分配内存的。
#include <stdio.h>
void main()
{
int n = 0;
printf("0x%x\n",&v);
}那么我有几个问题想问问大家,看看大家对于堆栈内存是否真的了解。
- 堆栈的物理内存是什么时候分配的?
- 堆栈的大小限制是多大?这个限制可以调整吗?
- 当堆栈发生溢出后应用程序会发生什么?
如果你对以上问题还理解不是特别深刻,今天来带你好好修炼进程堆栈内存这块的内功!
一、进程堆栈的初始化
进程启动调用 exec 加载可执行文件过程的时候,会给进程栈申请一个 4 KB 的初始内存。我们今天来专门抽取并看一下这段逻辑。
加载系统调用 execve 依次调用 do_execve、do_execve_common 来完成实际的可执行程序加载。
//file:fs/exec.c
static int do_execve_common(const char *filename, ...)
{
bprm_mm_init(bprm);
...
}在 bprm_mm_init 中会申请一个全新的地址空间 mm_struct 对象,准备留着给新进程使用。
//file:fs/exec.c
static int bprm_mm_init(struct linux_binprm *bprm)
{
//申请个全新的地址空间 mm_struct 对象
bprm->mm = mm = mm_alloc();
__bprm_mm_init(bprm);
}还会给新进程的栈申请一页大小的虚拟内存空间,作为给新进程准备的栈内存。申请完后把栈的指针保存到 bprm->p 中记录起来。
//file:fs/exec.c
static int __bprm_mm_init(struct linux_binprm *bprm)
{
bprm->vma = vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
vma->vm_end = STACK_TOP_MAX;
vma->vm_start = vma->vm_end - PAGE_SIZE;
...
bprm->p = vma->vm_end - sizeof(void *);
}我们平时所说的进程虚拟地址空间在 Linux 是通过一个个的 vm_area_struct 对象来表示的。

每一个 vm_area_struct(就是上面 __bprm_mm_init 函数中的 vma)对象表示进程虚拟地址空间里的一段范围,其 vm_start 和 vm_end 表示启用的虚拟地址范围的开始和结束。
//file:include/linux/mm_types.h
struct vm_area_struct {
unsigned long vm_start;
unsigned long vm_end;
...
}要注意的是这只是地址范围,而不是真正的物理内存分配 。
在上面 __bprm_mm_init 函数中通过 kmem_cache_zalloc 申请了一个 vma 内核对象。vm_end 指向了 STACK_TOP_MAX(地址空间的顶部附近的位置),vm_start 和 vm_end 之间留了一个 Page 大小。也就是说默认给栈准备了 4KB 的大小 。最后把栈的指针记录到 bprm->p 中。

接下来进程加载过程会使用 load_elf_binary 真正开始加载可执行二进制程序。在加载时,会把前面准备的进程栈的地址空间指针设置到了新进程 mm 对象上。
//file:fs/binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{ //ELF 文件头解析
//Program Header 读取
//清空父进程继承来的资源
retval = flush_old_exec(bprm);
...
current->mm->start_stack = bprm->p;
}
这样新进程将来就可以使用栈进行函数调用,以及局部变量的申请了。
前面我们说了,这里只是给栈申请了地址空间对象,并没有真正申请物理内存。我们接着再来看一下,物理内存页究竟是什么时候分配的。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
二、物理页的申请
当进程在运行的过程中在栈上开始分配和访问变量的时候,如果物理页还没有分配,会触发缺页中断。在缺页中断种来真正地分配物理内存。
为了避免篇幅过长,触发缺页中断的过程就先不展开了。我们直接看一下缺页中断的核心处理入口 __do_page_fault,它位于 arch/x86/mm/fault.c 文件下。
//file:arch/x86/mm/fault.c
static void __kprobes
__do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
...
//根据新的 address 查找对应的 vma
vma = find_vma(mm, address);
//如果找到的 vma 的开始地址比 address 小
//那么就不调用expand_stack了,直接调用
if (likely(vma->vm_start <= address))
goto good_area;
...
if (unlikely(expand_stack(vma, address))) {
bad_area(regs, error_code, address);
return;
}
good_area:
//调用handle_mm_fault来完成真正的内存申请
fault = handle_mm_fault(mm, vma, address, flags);
}当访问栈上变量的内存的时候,首先会调用 find_vma 根据变量地址 address 找到其所在的 vma 对象。接下来调用的 if (vma->vm_start <= address) 是在判断地址空间还够不够用。

如果栈内存 vma 的 start 比要访问的 address 小,则证明地址空间够用,只需要分配物理内存页就行了。如果栈内存 vma 的 start 比要访问的 address 大,则需要调用 expand_stack 先扩展一下栈的虚拟地址空间 vma。扩展虚拟地址空间的具体细节我们在第三节再讲。
这里先假设要访问的变量地址 address 处于栈内存 vma 对象的 vm_start 和 vm_end 之间。那么缺页中断处理就会跳转到 good_area 处运行。在这里调用 handle_mm_fault 来完成真正物理内存的申请 。
//file:mm/memory.c
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
...
//依次查看每一级页表项
pgd = pgd_offset(mm, address);
pud = pud_alloc(mm, pgd, address);
pmd = pmd_alloc(mm, pud, address);
pte = pte_offset_map(pmd, address);
return handle_pte_fault(mm, vma, address, pte, pmd, flags);
}Linux 是用四级页表来管理虚拟地址空间到物理内存之间的映射管理的。所以在实际申请物理页面之前,需要先 check 一遍需要的每一级页表项是否存在,不存在的话需要申请。
为了好区分,Linux 还给每一级页表都起了一个名字。
- 一级页表:Page Global Dir,简称 pgd
- 二级页表:Page Upper Dir,简称 pud
- 三级页表:Page Mid Dir,简称 pmd
- 四级页表:Page Table,简称 pte
看一下下面这个图就比较好理解了

//file:mm/memory.c
int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
{
...
//匿名映射页处理
return do_anonymous_page(mm, vma, address,
pte, pmd, flags);
}在 handle_pte_fault 会处理很多种的内存缺页处理,比如文件映射缺页处理、swap缺页处理、写时复制缺页处理、匿名映射页处理等等几种情况。我们今天讨论的主题是栈内存,这个对应的是匿名映射页处理,会进入到 do_anonymous_page 函数中。
//file:mm/memory.c
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags)
{
// 分配可移动的匿名页面,底层通过 alloc_page
page = alloc_zeroed_user_highpage_movable(vma, address);
...
}在 do_anonymous_page 调用 alloc_zeroed_user_highpage_movable 分配一个可移动的匿名物理页出来。在底层会调用到伙伴系统的 alloc_pages 进行实际物理页面的分配。
内核是用伙伴系统来管理所有的物理内存页的。其它模块需要物理页的时候都会调用伙伴系统对外提供的函数来申请物理内存。

到了这里,开篇的问题一就有答案了,堆栈的物理内存是什么时候分配的?进程在加载的时候只是会给新进程的栈内存分配一段地址空间范围。而真正的物理内存是等到访问的时候触发缺页中断,再从伙伴系统中申请的。
三、栈的自动增长
前面我们看到了,进程在被加载启动的时候,栈内存默认只分配了 4 KB 的空间。那么随着程序的运行,当栈中保存的调用链,局部变量越来越多的时候,必然会超过 4 KB。
我回头看下缺页处理函数 __do_page_fault。如果栈内存 vma 的 start 比要访问的 address 大,则需要调用 expand_stack 先扩展一下栈的虚拟地址空间 vma。

回顾 __do_page_fault 源码,看到扩充栈空间的是由 expand_stack 函数来完成的。
//file:arch/x86/mm/fault.c
static void __kprobes
__do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
...
if (likely(vma->vm_start <= address))
goto good_area;
//如果栈 vma 的开始地址比 address 大,需要扩大栈
if (unlikely(expand_stack(vma, address))) {
bad_area(regs, error_code, address);
return;
}
good_area:
...
}我们来看下 expand_stack 的内部细节。
其实在 Linux 栈地址空间增长是分两种方向的,一种是从高地址往低地址增长,一种是反过来。大部分情况都是由高往低增长的。本文只以向下增长为例。
//file:mm/mmap.c
int expand_stack(struct vm_area_struct *vma, unsigned long address)
{
...
return expand_downwards(vma, address);
}
int expand_downwards(struct vm_area_struct *vma, unsigned long address)
{
...
//计算栈扩大后的最后大小
size = vma->vm_end - address;
//计算需要扩充几个页面
grow = (vma->vm_start - address) >> PAGE_SHIFT;
//判断是否允许扩充
acct_stack_growth(vma, size, grow);
//如果允许则开始扩充
vma->vm_start = address;
return ...
}在 expand_downwards 中先进行了几个计算。
- 计算出新的堆栈大小。计算公式是 size = vma->vm_end - address;
- 计算需要增长的页数。计算公式是 grow = (vma->vm_start - address) >> PAGE_SHIFT;
然后会判断此次栈空间是否被允许扩充, 判断是在 acct_stack_growth 中完成的。如果允许扩展,则简单修改一下 vma->vm_start 就可以了!

我们再来看 acct_stack_growth 都进行了哪些限制判断。
//file:mm/mmap.c
static int acct_stack_growth(struct vm_area_struct *vma, unsigned long size, unsigned long grow)
{
...
//检查地址空间是否超出限制
if (!may_expand_vm(mm, grow))
return -ENOMEM;
//检查是否超出栈的大小限制
if (size > ACCESS_ONCE(rlim[RLIMIT_STACK].rlim_cur))
return -ENOMEM;
...
return 0;
}在 acct_stack_growth 中只是进行一系列的判断。may_expand_vm 判断的是增长完这几个页后是否超出整体虚拟地址空间大小的限制。rlim[RLIMIT_STACK].rlim_cur 中记录的是栈空间大小的限制。这些限制都可以通过 ulimit 命令查看到。
# ulimit -a
......
max memory size (kbytes, -m) unlimited
stack size (kbytes, -s) 8192
virtual memory (kbytes, -v) unlimited上面的这个输出表示虚拟地址空间大小没有限制,栈空间的限制是 8 MB。如果进程栈大小超过了这个限制,会返回 -ENOMEM。如果觉得系统默认的大小不合适可以通过 ulimit 命令修改。
# ulimit -s 10240
# ulimit -a
stack size (kbytes, -s) 10240到这里开篇的第二个问题也有答案了,堆栈的大小限制是多大?这个限制可以调整吗?
进程堆栈大小的限制在每个机器上都是不一样的,可以通过 ulimit 命令来查看,也同样可以使用该命令修改。
至于开篇的问题3,当堆栈发生溢出后应用程序会发生什么?写个简单的无限递归调用就知道了,估计你也遇到过。报错结果就是
'Segmentation fault (core dumped)本文总结
来总结下本文的内容,本文讨论了进程栈内存的工作原理。
第一,进程在加载的时候给进程栈申请了一块虚拟地址空间 vma 内核对象。vm_start 和 vm_end 之间留了一个 Page ,也就是说默认给栈准备了 4KB 的空间。
第二,当进程在运行的过程中在栈上开始分配和访问变量的时候,如果物理页还没有分配,会触发缺页中断。在缺页中断中调用内核的伙伴系统真正地分配物理内存。
第三,当栈中的存储超过 4KB 的时候会自动进行扩大。不过大小要受到限制,其大小限制可以通过 ulimit -s来查看和设置。
注意,今天我们讨论的都是进程栈。线程栈和进程栈有些不一样。
在回顾和总结下开篇我们抛出的三个问题:
问题一:堆栈的物理内存是什么时候分配的?进程在加载的时候只是会给新进程的栈内存分配一段地址空间范围。而真正的物理内存是等到访问的时候触发缺页中断,再从伙伴系统中申请的。
问题二:堆栈的大小限制是多大?这个限制可以调整吗?
进程堆栈大小的限制在每个机器上都是不一样的,可以通过 ulimit 命令来查看,也同样可以使用该命令修改。
问题3:当堆栈发生溢出后应用程序会发生什么?当堆栈溢出的时候,我们会收到报错 “Segmentation fault (core dumped)”
最后,抛个问题大家一起思考吧。你觉得内核为什么要对进程栈的地址空间进行限制呢?