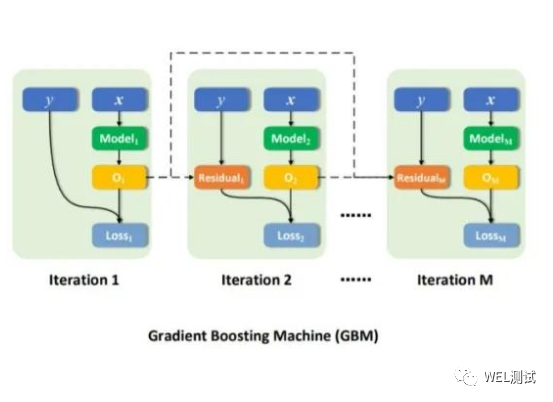
梯度提升法(Gradient Boosting Machine,简记 GBM)以非参数方法(不假设函数形式)估计基函数,并在“函数空间”使用“梯度下降”进行近似求解。非参数方法包括K近邻法、决策树、以及基于决策树的装袋法、随机森林与提升法等。

01 梯度提升决策树(GBDT)不足

梯度提升决策树(GBDT) 的常规实现需要针对每个功能扫描所有数据实例,以估计所有可能的分割点的信息增益(对于 GBDT,通常通过分割后的方差来衡量信息增益),因此计算复杂度与特征数量和实例数量成正比,这使得在处理大数据时非常耗时。为解决GBDT在处理大数据耗时较长的问题,最直接的想法就是减少数据实例的数量和特征的数量。
02 GOSS: 减少数据实例
基于梯度的单边采样(Gradient-based One-Side Sampling ,简称GOSS),GOSS 会保留所有具有大梯度的实例(具有较大梯度1的实例(即,训练不足的实例)将为信息增益做出更大的贡献),并对具有小梯度的实例执行随机采样。具体算法如下:

为了补偿对数据分布的影响,在计算信息增益时,GOSS 为具有小梯度的数据实例引入了一个常数乘法器。

03 EFB:减少特征
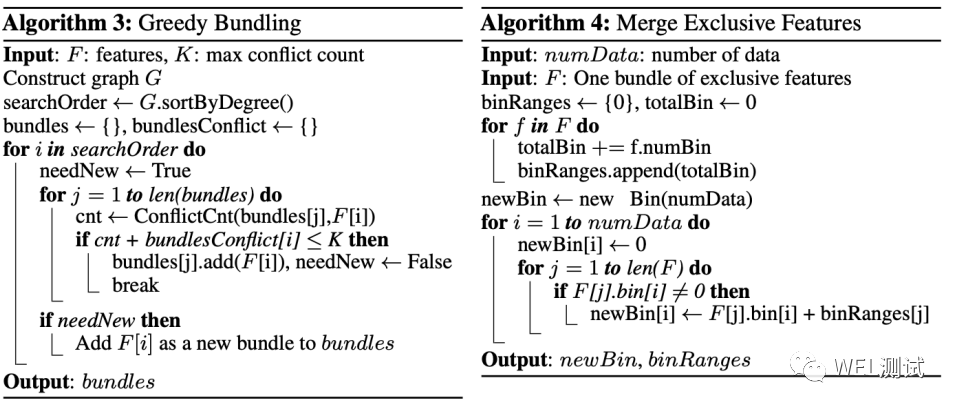
独占功能捆绑(Exclusive Feature Bundling ,简称EFB),EFB 算法可以将许多互斥特征捆绑到少得多的密集特征中,从而可以有效地避免不必要的零特征值计算。高维数据通常非常稀疏,在稀疏的特征空间中,许多特征是互斥的,可以安全地将互斥特征捆绑为一个特征(称为互斥特征捆绑exclusive feature bundle)。但是有两个问题要解决:第一个是确定应将哪些特征捆绑在一起,第二个是如何构造捆绑包。解决上述两个问题采用的算法如下:
具体来说,GOSS 首先根据数据实例的梯度的绝对值对它们进行排序,然后选择前a × 100%的实例。然后,它从其余数据中随机采样b× 100%实例。此后,GOSS 在计算信息增益时,将小梯度的采样数据通过常数(1-a)/b放大。通过这样做,将更多的精力放在训练不足的实例上,而没有太多改变原始数据的分布。
04 lightGBM是什么?
LightGBM=GOSS+EFB+GBDT:基于梯度的单边采样(GOSS )和互斥特征捆绑(EFB)的GBDT 算法,称为 LightGBM,它在计算速度和内存消耗方面可以显著优于 XGBoost 和 SGB,同时可以将训练过程加速多达 20 倍,同时达到几乎相同的准确性。