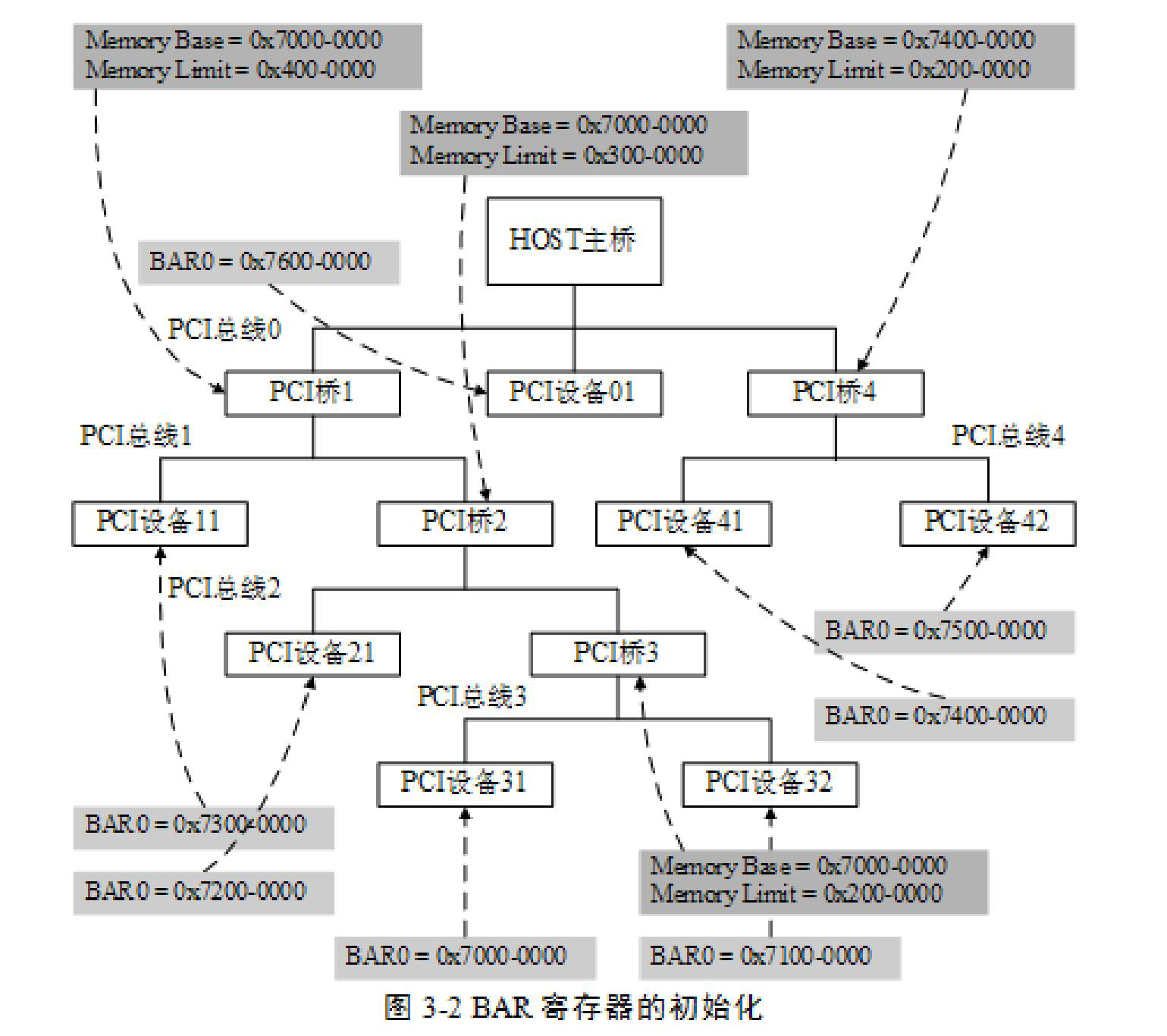
本文是博主对《Reinforcement Learning- An introduction》的阅读笔记,不涉及内容的翻译,主要为个人的理解和思考。
前文我们了解了强化学习主要是为了实现最大化某个特定目标(收益),而学习如何通过环境进行交互。 而学习的主体被称为agent,其可以是一个模型或者一系列决策函数,其用于产出同环境交互的动作决策。agent同环境的交互主要包含了三种信号的来回传递:
- the Actions:agent对环境的行为;
- the Rewards:环境的对agent状态的目标反馈,代表了状态或动作变化,环境所带来的奖励;
-
the States:agent在环境中状态,行为也会带来状态的变化。
MDP是上述以目标为导向从交互学习的过程的建模,其状态、动作和奖励的集合都是一个有限元素的集合,同环境的交互所引起状态序列,可以展开为一个马尔可夫链过程,由特定的状态间转换概率来描述状态间变化。
前文所提到强化学习的核心在于学习动作决策函数,使最终的累积收益最大化。对于MDP来说,动作决策函数实际上是指当在状态S情况下如何采取动作A,即,而目标累积收益表示为
,这处的t表示状态序列中某一个时刻,
表示时刻t之后的未来目标累积收益,n表示终结时刻。
如何求解决策函数,MDP主要是通过价值函数value function来解决,价值函数用于描述不同状态
或不同状态动作
下未来累积奖励的期望。
确定价值函数后,就可以很容易选出决策函数,即选择使价值最大的动作,在选择动作时有两种形式,这在训练时两种决策函数的选择,分别将强化学习算法区分为on-policy和off-policy两种。
- Deterministic:确定性动作
- Stochastic:随机概率性动作
,可以由价值函数来确定选择概率。
现在的问题是如何来确定价值函数:
同理状态动作价值函数可以表示为:
上面的价值函数计算公式中(Bellman equation),除了需要确定下一状态的价值函数外,还需要决策函数,同一方面在计算决策函数时又需要价值函数,因此训练是通过两阶段来进行训练的(Generalized Policy Iteration (GPI) 算法)
- evaluation:根据当前决策函数
计算价值函数
- improvement:根据 状态动作价值函数
来计算最优的决策函数

而这个学习迭代过程的收敛条件是当决策函数不发生变化improve时,即为最优决策函数,而换句话说,当一个决策函数
是最优决策函数时,对于所有其他决策函数
或所有状态s下,都有
,此时所有价值函数V(s)也是最优价值函数,表示为:
在MDP中,我们把决策函数视为一个确定性动作(on-policy方法),即
此时将上述的价值函数计算公式Bellman equation改写为,称之为Bellman optimality equation
此时整体evaluation的过程可以由一个反向求解来表示,每一轮的计算可能通过回溯来更新,而不需要考虑policy就能求解,所以improvement过程实际上并不需要了。这种方法是类似于贪心算法的启发性搜索算法,只满足所有的状态和动作都能经过足够多次数的遍历计算,是可以求解出最优解的。

其他的重要性问题
-
continuing tasks VS episodic tasks
continuing tasks是指没有终态的任务,即之前累积目标奖励是无限大的,此时为了保存收敛性,会加一个打折系数,即
。而episodic tasks即表示存在最终点步骤(终态),而这个最终点步骤(终态)将agent-环境的交互过程分为一个个Episodes的,称之为轮,当这个步骤特征长时,也可能通过添加打折系数。
-
complete knowledge
在上述Bellman equation式子中存在我们并没有计算,实际上是我们对环境的先验知识,所以应用Bellman equation式必须要求我们有这种先验知识,同时另一个要求是状态、奖励、动作是有限的,另外其组合是有一个限度的,否则对计算空间和计算时间都有压力。