文章目录
- 一、Numpy概述
- 1. 优势
- 2. numpy历史
- 3. Numpy的核心:多维数组
- 4. 内存中的ndarray对象
- 4.1 元数据(metadata)
- 4.2 实际数据
- 二、numpy基础
- 1. ndarray数组
- 2. arange、zeros、ones、zeros_like
- 3. ndarray对象属性的基本操作
- 3.1 修改数组维度
- 3.2 修改数组元素类型
- 3.3 数组的size
- 4. 数组元素索引
- 5. Numpy内部基本数据类型
- 5.1 基本数据类型简写的应用案例
- 5.2 将列表强转为数组
- 方式1 通过字符串的方式指定dtype(不常用)
- 方式2:通过列表套元组(不常用)
- 方式3:通过字典的固定键设置dtype
- 5.3 datetime64
- 6. ndarray数组维度操作
- 6.1 视图变维(数据共享):reshape()与ravel()
- 6.2 赋值变维(数据独立)
- 6.3 就地变维:直接改变原数组的维度,不返回新数组
- 7. ndarray数组切片操作
- 7.1 一维数组切片
- 7.2 多维数组切片
- 7.3 ndarray数组的掩码操作
- 布尔掩码
- 布尔掩码操作案例:求100以内3的倍数的数字
- 标签掩码:掩码数组中为索引值
- 7.4 多维数组的组合与拆分
- stack and split
- concatenate
- 长度不等的数组组合
- 简单一维数组组合方案
- ndarray类的其他属性
一、Numpy概述
1. 优势
- Numpy(Nummerical Python),补充了Python语言所欠缺的数值计算能力;
- Numpy是其它数据分析及机器学习库的底层库;
- Numpy完全标准的C语言实现,运行效率充分优化(Python 1989年出现,1991年发布);
- Numpy开源免费。
2. numpy历史
- 1995年,Numeric,Python语言数值计算扩充;
- 2001年,Scipy->Numarray,多维数组运算;
- 2005年,Numeric+Numarray->Numpy。
- 2006年,Numpy脱离Scipy成为独立的项目。
3. Numpy的核心:多维数组
- 代码简洁:减少Python代码中的循环
- 底层实现: 厚内核©+薄接口(Python),保证性能.
4. 内存中的ndarray对象
4.1 元数据(metadata)
存储对目标数组的描述信息,如: ndim、shape、dtype、data等.
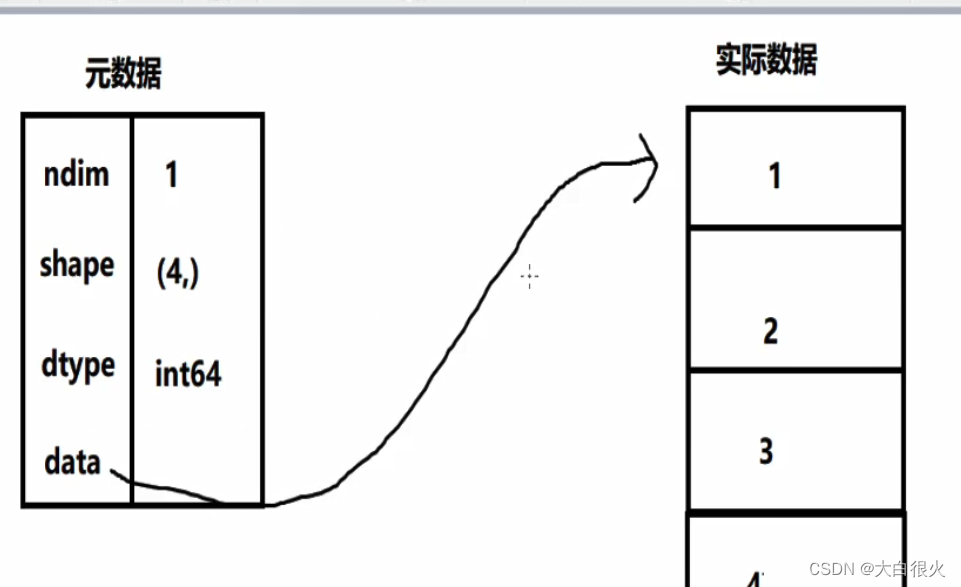
4.2 实际数据
完整的数组数据
将实际数据与元数据分开存放,一方面提高了内存空间的使用效率另一方面减少对实际数据的访问频率,提高性能。
ndarray数组对象的特点
- Numpy数组是同质数组,即所有元素的数据类型必须相同
- Numpy数组的下标从0开始,最后一个元素的下标为数组长度减1
ndarray数组对象的特点 - Numpy数组是同质数组,即所有元素的数据类型必须相同
- Numpy数组的下标从0开始,最后一个元素的下标为数组长度-1
二、numpy基础
1. ndarray数组
import numpy as np
# 通过array创建ndarray
ary = np.array([1, 2, 3 , 4, 5])
print(ary)
print(type(ary))
# 数组与元素的运算是数组与每个元素分别运算
print(ary+2)
print(ary*2)
print(ary == 3)
# 数组与数组之间的运算 是 对应位置对应计算,数组不等不能计算
print(ary + ary)
print(ary * ary)
# 输出:
# [1 2 3 4 5]
# <class 'numpy.ndarray'>
# [3 4 5 6 7]
# [ 2 4 6 8 10]
# [False False True False False]
#[ 2 4 6 8 10]
#[ 1 4 9 16 25]
数组与元素的运算是数组与每个元素分别运算;
数组与数组之间的运算是对应位置对应计算
数组长度不等不能计算
2. arange、zeros、ones、zeros_like
import numpy as np
ary = np.array([1, 2, 3 , 4, 5])
print(ary)
print(ary + ary)
print(ary * ary)
aryrange = np.arange(1,3)
print(aryrange)
aryrange = np.arange(1,3,0.1)
print(aryrange)
ary = np.zeros(10) # 生成0数组
print(ary)
ary = np.zeros(10, dtype='int64') # 设置数据类型
print(ary)
ary = np.zeros((2 ,2)) # 生成2*2的矩阵
print(ary)
print(ary.shape)
ary = np.array([1, 2, 3 , 4, 5]) # 拿到一个数组,用0填充
print(np.zeros_like(ary))
# 输出
# [1 2 3 4 5]
# [ 2 4 6 8 10]
# [ 1 4 9 16 25]
# [1 2]
# [1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7
# 2.8 2.9]
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
# [0 0 0 0 0 0 0 0 0 0]
# [[0. 0.]
# [0. 0.]]
# (2, 2)
# [1 2 3 4 5]
# [0 0 0 0 0]
python的range只能生成整数,而arange可生成浮点数
zeros_like拿到一个数组,用0填充
ones_like用法类似
3. ndarray对象属性的基本操作
3.1 修改数组维度
import numpy as np
ary = np.arange(1, 9)
print(ary)
# 直接修改原始数据的维度
ary.shape = (2, 4)
print(ary)
print(ary.shape)
# 修改为3维数据
ary.shape = (2, 2, 2)
print(ary)
print(ary.shape)
# [1 2 3 4 5 6 7 8]
# [[1 2 3 4]
# [5 6 7 8]]
# (2, 4)
# [1 2 3 4 5 6 7 8]
# [[[1 2]
# [3 4]]
#
# [[5 6]
# [7 8]]]
# (2, 2, 2)
可
直接使用shape修改数组的形状
3.2 修改数组元素类型
ary = np.arange(1, 9)
ary.dtype = "float64" # 只能修改解析方式,修改数据类型只能用astype
print(ary)
ary = np.arange(1, 9)
c = ary.astype(float) # 不会修改原始数据,可用一个变量去接收
print(c)
# 输出
# [4.24399158e-314 8.48798317e-314 1.27319747e-313 1.69759663e-313]
# [1. 2. 3. 4. 5. 6. 7. 8.]
修改数组类型时不可使用dtype,此方式只能修改解析方式,会得到一个错误的值
可使用astype()去修改,此方式不会修改原始数据,可用一个新变量去接收
3.3 数组的size
import numpy as np
ary = np.arange(1, 9)
print(ary)
print(ary.shape)
print(ary.size)
print(len(ary))
ary.shape = (2, 4)
print(ary.shape)
print(ary.size)
print(len(ary))
# 输出
# [1 2 3 4 5 6 7 8]
# (8,)
# 8
# 8
# (2, 4)
# 8
# 2
size是指数组元素的个数,一维数组的len和size是一样的,二多维数组则不一样,在二维数组时,size是指二维数组中第二维度的个数。
4. 数组元素索引
import numpy as np
ary = np.arange(1, 9)
ary.shape = (2, 2, 2)
print(ary)
print(ary[0]) # 访问三维数组的第一个二维数组
print(ary[0][0]) # 访问二维数组的第一一维数组
print(ary[0][0][0]) # 访问一维数组的第一个元素
print(ary[0,0,0]) # numpy的全新写法
# 输出
# [[[1 2]
# [3 4]]
#
# [[5 6]
# [7 8]]]
# [[1 2]
# [3 4]]
# [1 2]
# 1
# 1
5. Numpy内部基本数据类型

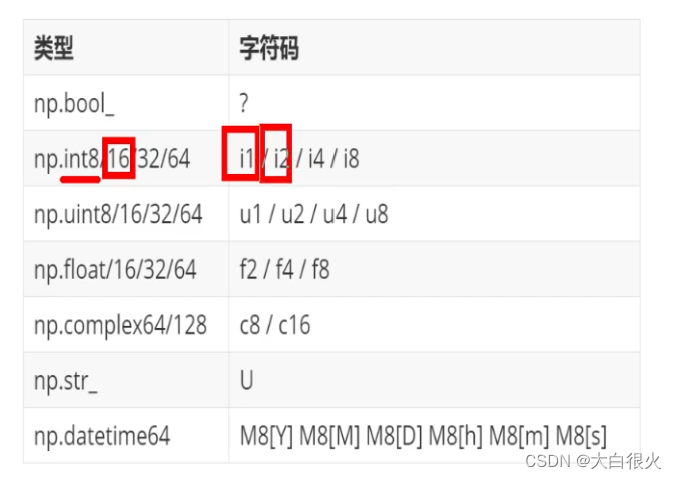
5.1 基本数据类型简写的应用案例
import numpy as np
data = [('zs', [100, 90, 95], 18),
('ls', [100, 95, 93], 22),
('ww', [98, 98, 98], 20)]
print(data)
ary = np.array(data)
print(ary)
ary = np.array(data, dtype='U2, 3int8, int8')
print(ary)
5.2 将列表强转为数组
方式1 通过字符串的方式指定dtype(不常用)
import numpy as np
data = [('zs', [100, 90, 95], 18),
('ls', [100, 95, 93], 22),
('ww', [98, 98, 98], 20)]
ary = np.array(data, dtype='U2, 3int8, int8')
sum = 0
for i in data:
sum = i[2]+sum
print(sum/3)
print(ary['f2'].mean())
以上代码使用2种方式求年龄的平均值
方式2:通过列表套元组(不常用)
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = [('zs', [100, 90, 95], 18),
('ls', [100, 95, 93], 22),
('ww', [98, 98, 98], 20)]
# print(data)
ary = np.array(data)
# print(ary)
ary = np.array(data, dtype=[('name', 'str', 2),
('score', 'int32', 3),
('age', 'int32', 1)])
print(ary['score'].mean())
# 输出
# 20
方式3:通过字典的固定键设置dtype
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = [('zs', [100, 90, 95], 18),
('ls', [100, 95, 93], 22),
('ww', [98, 98, 98], 20)]
# print(data)
ary = np.array(data)
# print(ary)
ary = np.array(data, dtype={'names': ['name', 'score', 'age'], 'formats': ['U2', '3int32', 'int32']})
print(ary['age'])
# 输出
# [18 22 20]
5.3 datetime64
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = np.array(['2011', '2012-12-12', '2023-02-13 08:08:08'])
# 将字符串转成时间日期(精确到日)类型
pretty_data = data.astype("datetime64[D]")
print(pretty_data)
# 转成整形
res = pretty_data.astype('int64')
print(res) # 返回距1970年1月1日的天数
# 将字符串转成时间日期(精确到秒)类型
pretty_data = data.astype("datetime64[s]")
print(pretty_data)
# 转成整形
res = pretty_data.astype('int64')
print(res) # 返回距1970年1月1日的秒数
# 输出
# ['2011-01-01' '2012-12-12' '2023-02-13']
# [14975 15686 19401]
# ['2011-01-01T00:00:00' '2012-12-12T00:00:00' '2023-02-13T08:08:08']
# [1293840000 1355270400 1676275688]
numpy的日期格式要求严格
字符串的格式不能形如2021-1-1也不能形如2021/01/01
6. ndarray数组维度操作
容器:酒瓶 元素:酒
赋值拷贝:酒瓶装旧酒
浅拷贝:新瓶装旧酒
深拷贝:新瓶装新酒
6.1 视图变维(数据共享):reshape()与ravel()
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary = np.arange(1, 9)
print(ary)
# 视图变维
bry = ary.reshape(2, 4)
print(bry)
print(ary)
ary[0] = 123
print("修改后的ary:", ary)
print("bry:", bry)
# 输出
# [1 2 3 4 5 6 7 8]
# [[1 2 3 4]
# [5 6 7 8]]
# [1 2 3 4 5 6 7 8]
# 修改后的ary: [123 2 3 4 5 6 7 8]
# bry: [[123 2 3 4]
# [ 5 6 7 8]]
只是形状发生了改变,修改了原始数据,变维后的数据跟着变,这就是所谓的
数据共享
变维后的数据虽然在形状上发生了变化,但不影响变维前的数据
ravel将数组(不管几维)拉伸为1维
6.2 赋值变维(数据独立)
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary = np.arange(1, 9).reshape(2, 4)
print(ary)
bry = ary.flatten()
print(bry)
ary[0] = 666
print(ary)
print(bry)
# 输出
# [[1 2 3 4]
# [5 6 7 8]]
# [1 2 3 4 5 6 7 8]
# [[666 666 666 666]
# [ 5 6 7 8]]
# [1 2 3 4 5 6 7 8]
6.3 就地变维:直接改变原数组的维度,不返回新数组
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary = np.arange(1, 9)
ary.resize(2, 2, 2)
print(ary)
ary = np.arange(1, 9)
ary.resize(2, 2, 2)
print(ary)
7. ndarray数组切片操作
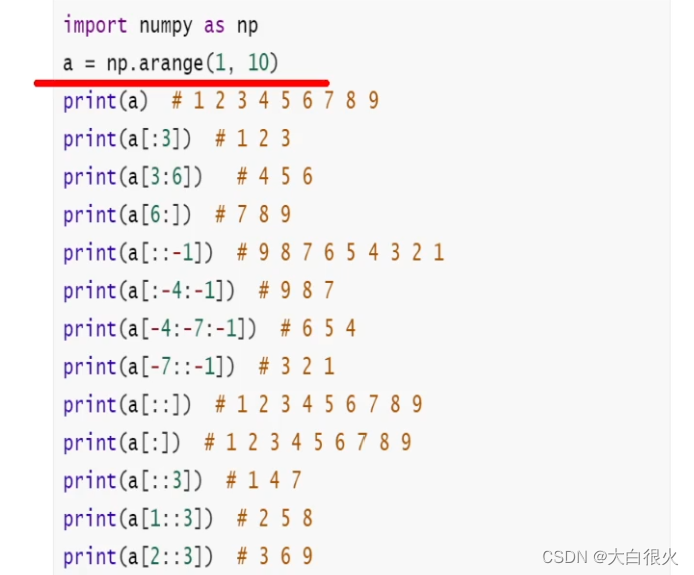
7.1 一维数组切片
数组对象切片的参数设置与列表切片参数类似
步长+:默认切从首到尾
步长-:默认切从尾到头
数组对象[起始位置:终止位置:步长,…]
默认步长:1
7.2 多维数组切片
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary = np.arange(1, 9)
ary.resize(3,3)
print(ary)
print(ary[:2]) # 前两行
print(ary[:2, :2]) # 前两行的前两列
print(ary[::2, ::2]) # 1 3行,1 3列
# 输出
# [[1 2 3]
# [4 5 6]
# [7 8 0]]
# [[1 2 3]
# [4 5 6]]
# [[1 2]
# [4 5]]
# [[1 3]
# [7 0]]
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary =np.arange(1, 101).reshape(20, 5)
print(ary)
# 所有行不要最后一列
print("所有行不要最后一列")
print(ary[:, :-1])
# 所有行只要最后一列
print(ary[:, -1])
7.3 ndarray数组的掩码操作
布尔掩码
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary = np.arange(1, 10)
mask = [True, False, True, True, False, True, True, True, False]
res = ary[mask]
print(res)
# 输出
# [1 3 4 6 7 8]
布尔掩码操作案例:求100以内3的倍数的数字
import numpy as np
import warnings
warnings.filterwarnings('ignore')
ary = np.arange(1, 101)
print(ary[ary % 3 == 0])
标签掩码:掩码数组中为索引值
import numpy as np
import warnings
warnings.filterwarnings('ignore')
car = np.array(['bwm', 'benzi', 'audi', 'hongqi'])
mask = [0, 2, 1, 3]
res = car[mask]
print(res)
mask = [0, 0, 0, 0, 0, 2, 1, 1, 1, 1, 1, 1, 3]
res = car[mask]
print(res)
# 输出
# ['bwm' 'audi' 'benzi' 'hongqi']
# ['bwm' 'bwm' 'bwm' 'bwm' 'bwm' 'audi' 'benzi' 'benzi' 'benzi' 'benzi' 'benzi' 'benzi' 'hongqi']
7.4 多维数组的组合与拆分
stack and split
垂直方向 vstack vsplit
水平方向 hstack hsplit
深度方向 dstack dsplit
import numpy as np
ary = np.arange(1, 7).reshape(2, 3)
bry = np.arange(7, 13).reshape(2, 3)
res = np.dstack((ary, bry))
print(ary)
print(bry)
print(res)
print(res.shape)
print("-"*30)
ary, bry = np.dsplit(res, 2)
print(ary)
print(bry)
# 输出
[[1 2 3]
[4 5 6]]
[[ 7 8 9]
[10 11 12]]
[[[ 1 7]
[ 2 8]
[ 3 9]]
[[ 4 10]
[ 5 11]
[ 6 12]]]
(2, 3, 2)
------------------------------
[[[1]
[2]
[3]]
[[4]
[5]
[6]]]
[[[ 7]
[ 8]
[ 9]]
[[10]
[11]
[12]]]
三维数组拆分后依然是3维数组,想变成2维只能采用变维的方式。
concatenate
若待组合的数组都是二维数组:
0:垂直方向组合
1:水平方向组合
若待组合的数组都是三维数组:
0:垂直方向组合
1:水平方向组合
2:深度方向组合
np.concatenate((a,b),axis=0)
通过给出的数组与要拆分的份数,按照某个方向进行拆分,axis的取值同上
np.split(c,2,axis=0)
长度不等的数组组合
先填充,再组合
简单一维数组组合方案
a = np.arange(1,9)
b = np.arange(9,17)
#把两个数组摞在一起成两行
c = np.row_stack((a,b))
print(c)
#把两个数组组合在一起成两列
d = np.column_stack((a,b))
print(d)
ndarray类的其他属性
- shape-维度
- dtype-元素类型
- size-元素数量
- ndim-维数,len(shape)
- itemsize-元素字节数
- nbytes -总字节数= size x itemsize
- real-复数数组的实部数组
- imag-复数数组的虚部数组
- T-数组对象的转置视图
- flat-扁平选代器