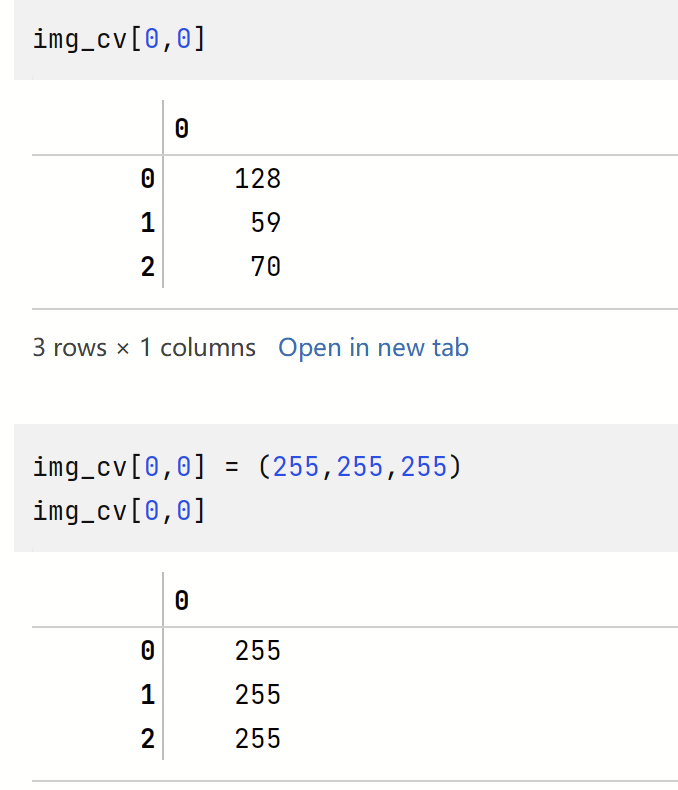
前言:
在上一个生产项目中,有个单表数据超249G了,里面存储的数据时间跨度就1年左右,那为啥会出现这种情况呢?数据来源为,一个生产基地所有电表的每分钟读数,一个基地大概500个电表左右,然后乘以1天24小时,一天1440分钟,一年365天,所以就出现了前面说的单表超249G的情况。真的是单表顶10库。因业务部门想看到每个时间点的电耗来安排排产,虽然当时满足了业务需求,但随着时间的推移对应数据量是越来越大,前端查询和后端数据抽取的耗时越来越大,因此怎么让如果大表实现快速的数据分析和数据处理呢?更换非关系型数据库?分表分库?
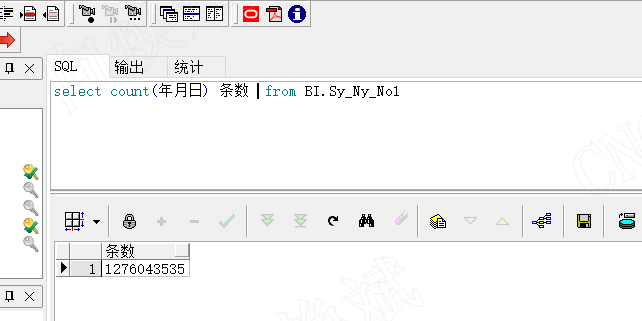
十二亿七千六百零四万三千五百三十五数据量
一、亿级数据处理
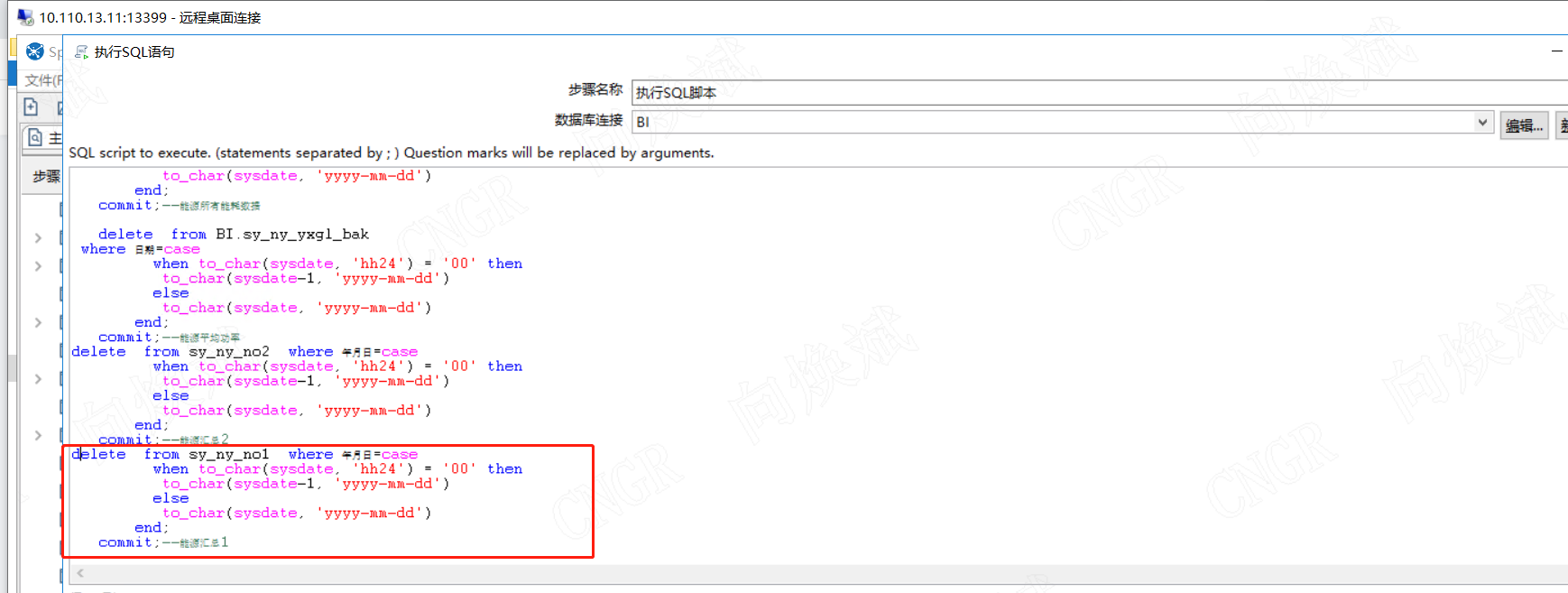
如上图所示,目前数据量已经是13亿左右,因此此时我们进行数据删除、更新、排序、分组等耗时会比较长。但我们看电耗都是默认看最新的读数,因此我们必然需要用到排序操作,因此怎么在0.1s内完成亿级的数据排序呢?同样的我们知道在kettle做数据抽取时,我们经常更新当日数据时,会进行先delete后insert的操作,如我们更新2023年2月13日16点的数据,我们需先删除2023年2月13日0点至16点的当天数据,再插入2023年2月13日的数据。(这是网上经典的kettle数据处理方案)。但是实际情况下,我们删除带条件的亿级数据时耗时最小在10分钟以上。再包括插入数据的时间,我们至少要10分钟才能完成一个表的数据处理,这在实际应用情况下,是必然不能接受的,因为业务需要看到1分钟的数据变化,因此我们需要将作业执行的耗时控制在1分钟之内,并且在前端数据分析展现速度控制在3秒以内,因为用户的耐心阀值为3秒。
二、方案与效果对比
下面我们分析最常用的三种kettle数据处理方案,并进行方案对比。
方案 | 效果分析 | 应用场景 |
插入更新 | 无删除、不影响前端展现、耗时长 | 需有标准主键,每次更新数据量在5千行内。 |
先delete后insert | 目标表数据在100万行内,不影响前端展现,效率是插入更新的100倍以上 | 每次更新数据量在1-10万行内,目标表总数据量在100万行内。 |
插入变量范围数据 | 开发相对复杂、基本在2s内可完成作业,只需读取源表数据耗时,插入更新基本无耗时 | 适合有明确主键的场景,适合任何场景,但需在源表做好规范,源表有对应主键或者联合主键。 |
2.1原因分析
kettle的工作原理是定时处理数据流,数据是以数据流的形式在kettle作业中执行,数据流耗时主要表现在源表读取耗时、分组、求和等计算耗时、update、delete、insert数据库耗时。插入耗时最短、其次为查询耗时,因采用数据流的形式,当将批量的数据保存至数据流中时,可在零点几秒内完成亿万级数据插入。因此想达到效率最大化,我们在数据处理时只采用插入操作。
2.2案例分析
我们进行数据处理时,需要的不仅仅是速度快,而且需要精准。因此我们怎么避免冗余的数据呢?特别是在亿万级数据时,快速定位需要删除的数据。因此此时我们需要做的是,找出有规律的主键,如时间,如我们源数据库中,数据已更新至2023年2月13日15:56:45时,现在时间是2023年2月13日18:07:32因此从数据分析的角度分析,我们只需更新2023年2月13日15:56:45至2023年2月13日18:07:32的数据即可。因此我们需快速定位至2023年2月13日15:56:45的主键,然后在插入数据时,查询大于2023年2月13日15:56:45主键的数据即可完成我们的目的了。
2.3步骤分解
从上面可知,我们需要做两步操作:
1、第一步是快速找出2023年2月13日15:56:45的主键(读目标表)
2、插入2023年2月13日15:56:45至现在(2023年2月13日18:07:32)的数据
因此我们在读取最新主键时耗时需可知在0.1内,插入数据耗时控制在2s内,这样我们就可以将整个数据处理耗时控制在3秒内,并不影响前端展现,且数据精确。
2.4实现思路
从前面可知,我们一直在强调快速和定位,因此此时让我们想到了数据库一个常用功能就是索引。因为索引就是为了快速和定位而生。因此我们只需要在我们查询和过滤的字段上加上索引,我们就可以在0.1s内完成数据的快速定位。

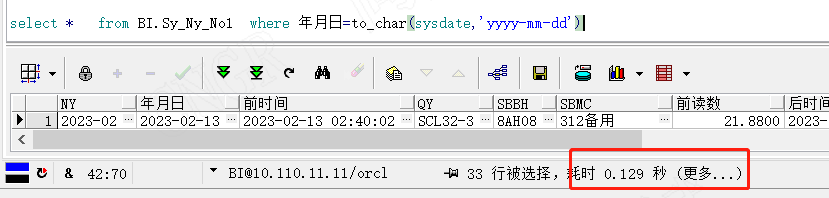
为了方便大家的理解,我在上面的13亿数据表中,增加了年月日的字段索引,看我们查找出最大的年月日需要多少耗时,对应增加索引的语句为,create index seq_name on table (column_name)。如增加BI.SY_NY_NO1表索引语句为create index seq_SY_NY_NO1 on BI.SY_NY_NO1(年月日)。

如上图所示我们查询出最新的年月日只需用了0.052秒,稳稳控制在0.1s内,如果我没告诉你它数据量在13亿,你肯定觉得它数据量在1万以内,这就是索引带来的改变。
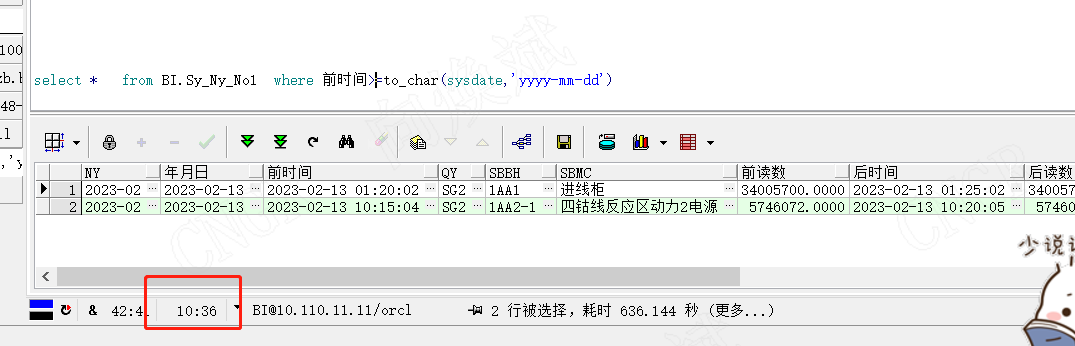
同样我们在0.1秒左右完成了最新数据的过滤,这就是索引带来的改变,当然为了区分效果我们使用另外一个不带索引的字段来过滤看下效果。如下图所示使用了10分36秒才过滤出我们需要的数据。对应效率提高(10x60+36)/0.129=3069倍。
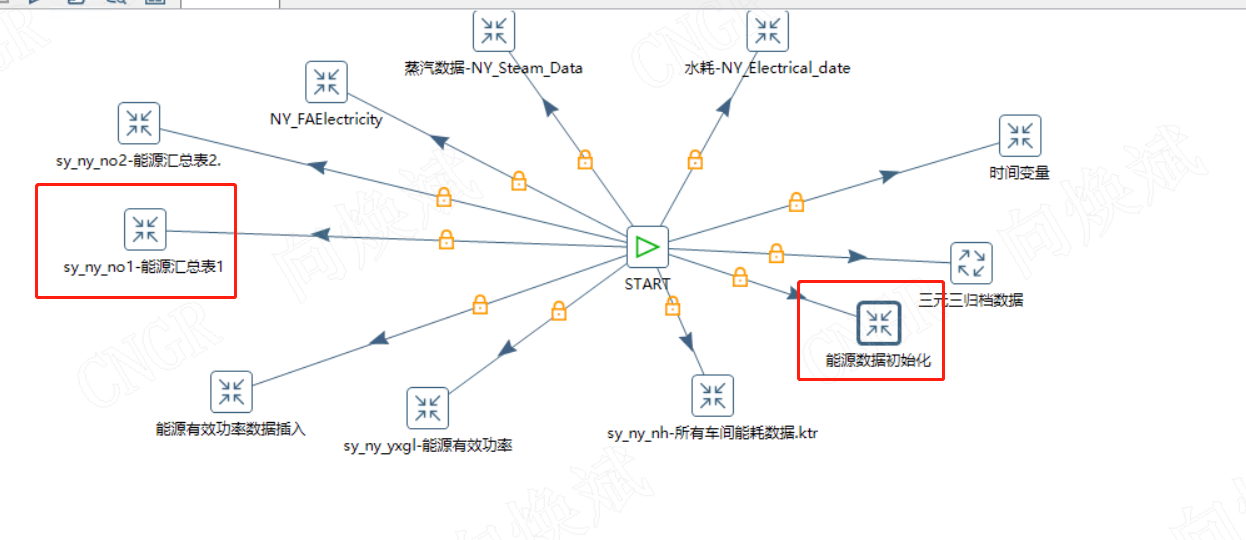
三、实际应用
从上面我们了解到,索引可以快速提高查询效率,因此我们在数据分析、数据抽取的时候怎么灵活应用索引呢?
3.1数据分析应用
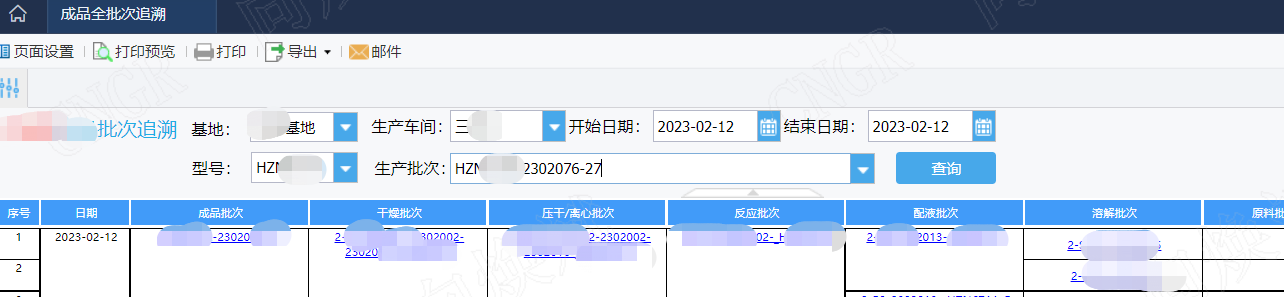
如我们在做生产的批次追溯时,我们需要查看整个过程任何时间段的批次的数据追溯,从前端展现来看,对应涉及的字段较多,涉及的展现逻辑较复杂,那我们怎么在最短的时间(3S)内完成数据分析呢?因此我们在前端的控件加载耗时控制在1秒内,因对应的生产批次需根据前面的基地、车间、日期、型号进行过滤,因此我们需增加基地、车间、日期、型号的索引,对应展示的明细表需根据基地、车间、日期、型号、批次进行过滤,因此此时我们需增加基地、车间、日期、型号、批次的索引。。不难发现我们为了完成这个需求,我们需要增加很多索引组,这就是为什么前面那个亿万级表通过年月日查询很快,但通过另外一个字段查询就大打折扣的原因,因此,此时我们需根据需求进行联合索引的创建来大大提高展现效率。如下图所示在表中增加了三组索引,这样在前端展现就能在3s内完成任一时间的数据分析了。

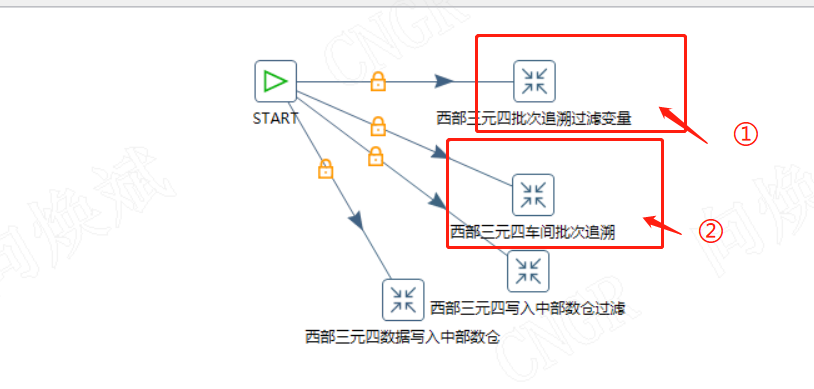
3.2数据抽取应用
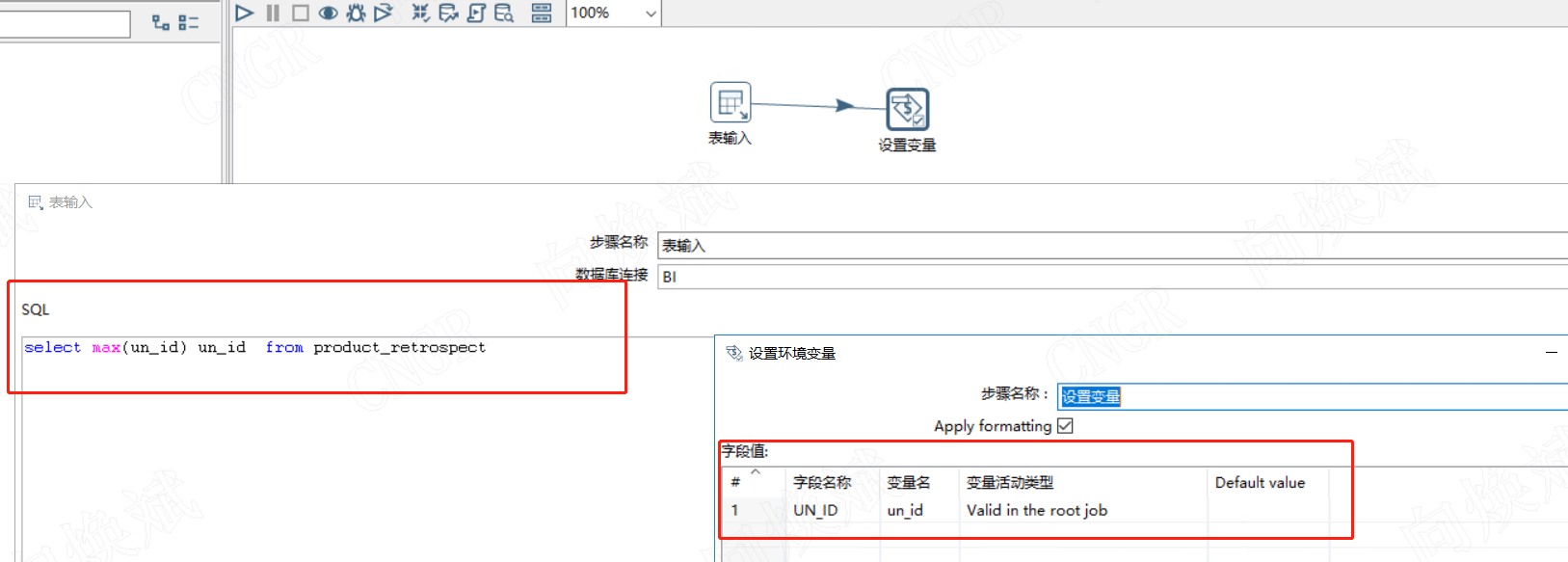
基本思路在前面已经阐述,对应获取最新主键,然后插入过滤对应主键即可。

对应作业为下图所示,通过变量过滤,再执行数据插入即可。