pyecharts官方文档:https://pyecharts.org//#/zh-cn/
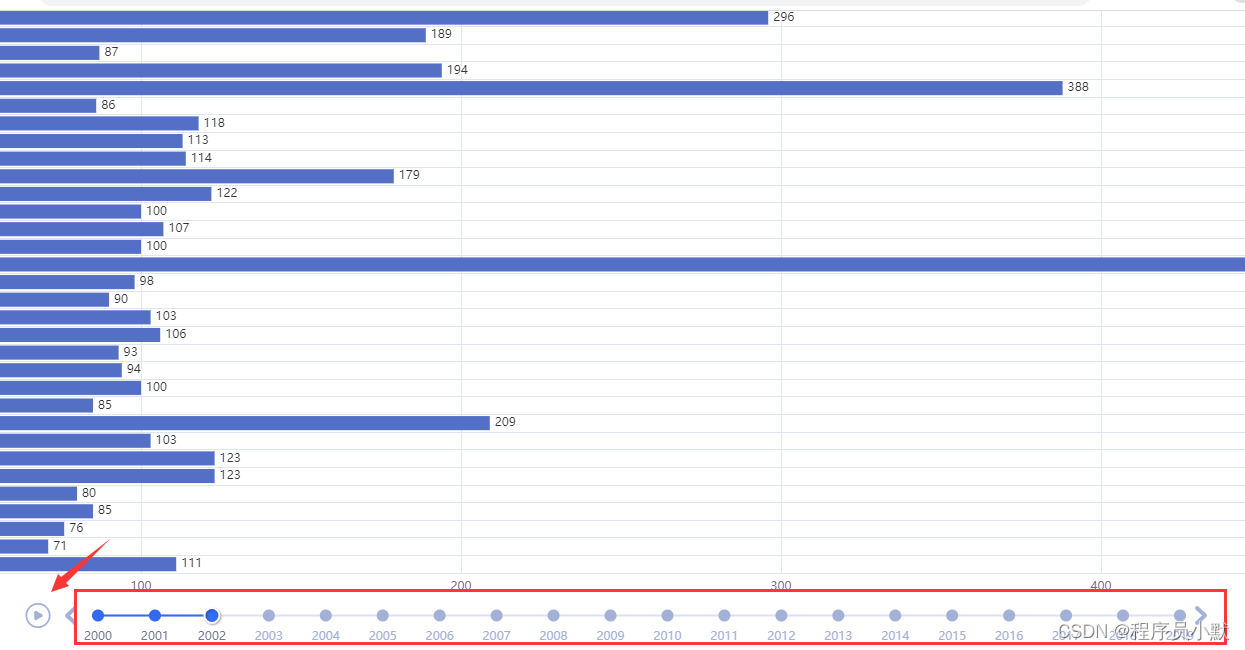
【1】Timeline
其是一个时间轴组件,如下图红框所示,当点击红色箭头指向的“播放”按钮时,会呈现动画形式展示每一年的数据变化。
data格式为DataFrame,数据如下图所示:

# 初始化Timeline 设置全局宽高
timeline = Timeline(init_opts=opts.InitOpts(width="2000px", height="800px"))
# data['ReleaseNum'].shape[0] 获取所有行数 这里是20
# range(data['ReleaseNum'].shape[0]) 得到一个[0,20)的列表
for index, year in zip(range(data['ReleaseNum'].shape[0]), data.index.tolist()):
bar = (
Bar()
.add_xaxis(data['ReleaseNum'].columns.tolist()) #放所有类型
.add_yaxis("销量", data['ReleaseNum'].iloc[index,].tolist(), label_opts=opts.LabelOpts(position="right"))#数值
.reversal_axis()# 翻转
.set_global_opts(title_opts=opts.TitleOpts(title="%d年各类型音乐专辑发行数量" % year, pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="发行数量"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="音乐专辑类型")
)
)
timeline.add(bar, year)#添加到时间轴
timeline.render('releaseNumOfYear.html') # 渲染视图
data['ReleaseNum'] 用来去掉ReleaseNum获取一个二维表,如下图所示:

data.index.tolist() 获取所有年,得到一个list:
<class 'list'>: [2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
data['ReleaseNum'].columns.tolist() 得到所有的列label:
<class 'list'>: ['Alternative', 'Ambient', 'Black Metal', 'Blues', 'Boy Band', 'Brit-Pop', 'Compilation', 'Country', 'Dance', 'Death Metal', 'Deep House', 'Electro-Pop', 'Folk', 'Gospel', 'Hard Rock', 'Heavy Metal', 'Holy Metal', 'Indie', 'Indietronica', 'J-Rock', 'Jazz', 'K-Pop', 'Latino', 'Live', 'Lounge', 'Metal', 'Parody', 'Pop', 'Pop-Rock', 'Progressive', 'Punk', 'Rap', 'Retro', 'Rock', 'Techno', 'Trap', 'Unplugged', 'Western']
data['ReleaseNum'].iloc[index,].tolist() 用来获取目标index行的所有列。假设index=0,也就是说获取第一行所有列的数据。
【2】柱状图
原始数据格式如下:
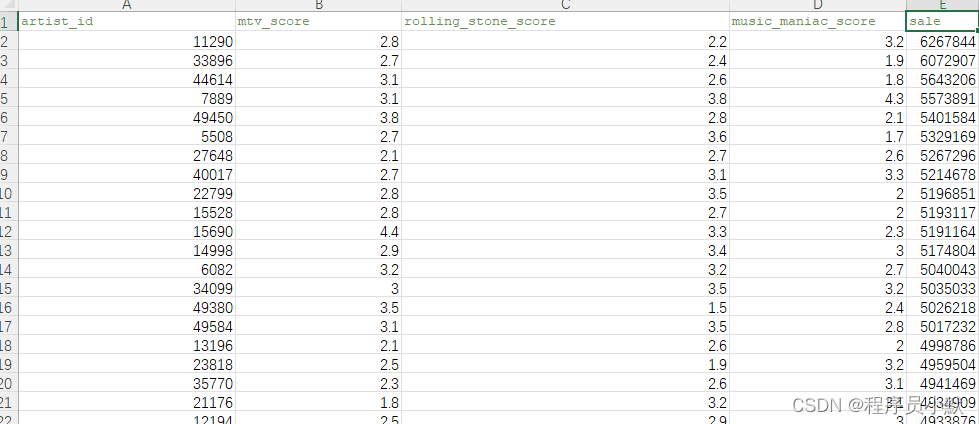
① 单个柱状图
如下图所示,只有一项发行量。
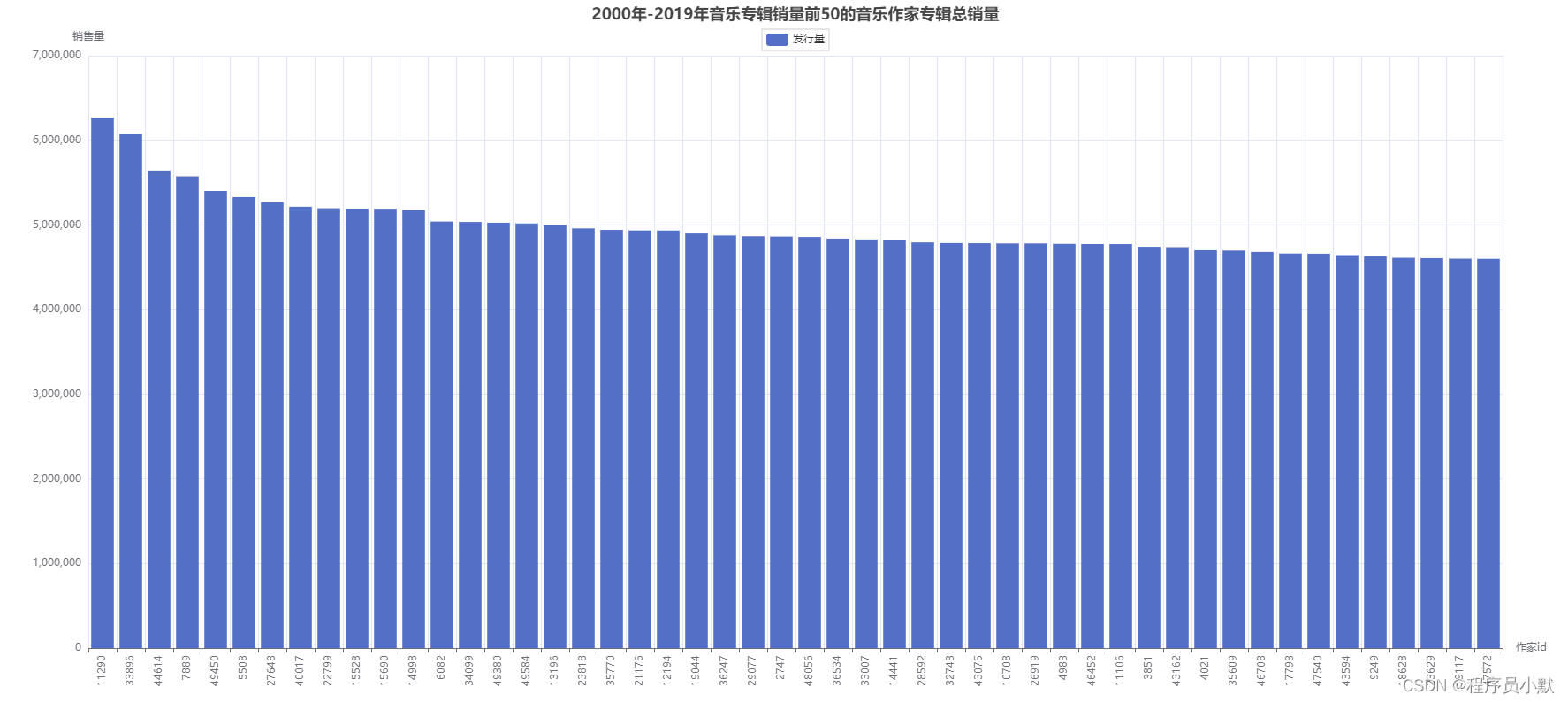
index = [str(x) for x in salesAndScoreOfArtist['artist_id']]
bar = (
Bar(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add_xaxis(index) #作家ID
.add_yaxis("发行量", salesAndScoreOfArtist['sale'].tolist()) #获取发行量列表
.set_global_opts(title_opts=opts.TitleOpts(title="2000年-2019年音乐专辑销量前50的音乐作家专辑总销量", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90, font_size=12), name="作家id"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="销售量"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
② 多项柱状图
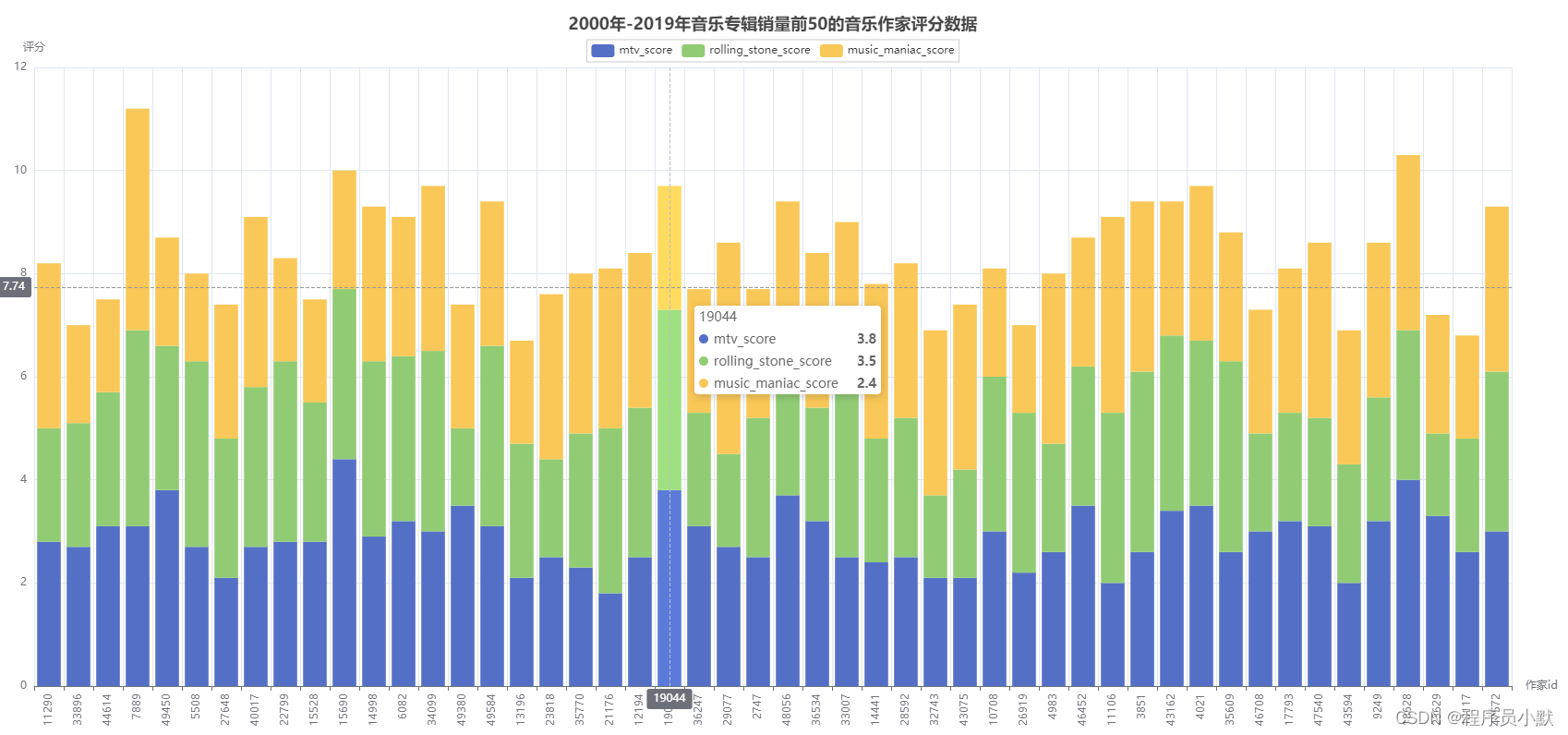
mult_bar = (
Bar(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add_xaxis(index)
.add_yaxis("mtv_score", salesAndScoreOfArtist['mtv_score'].tolist(), stack='stack1')
# 这里stack意思 数据堆叠,同个类目轴上系列配置相同的 stack 值可以堆叠放置。
.add_yaxis("rolling_stone_score", salesAndScoreOfArtist['rolling_stone_score'].tolist(), stack='stack1')
.add_yaxis("music_maniac_score", salesAndScoreOfArtist['music_maniac_score'].tolist(), stack='stack1')
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90, font_size=12), name="作家id"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12), name="评分"),
title_opts=opts.TitleOpts(title="2000年-2019年音乐专辑销量前50的音乐作家评分数据", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
)
③ WordCloud:词云图
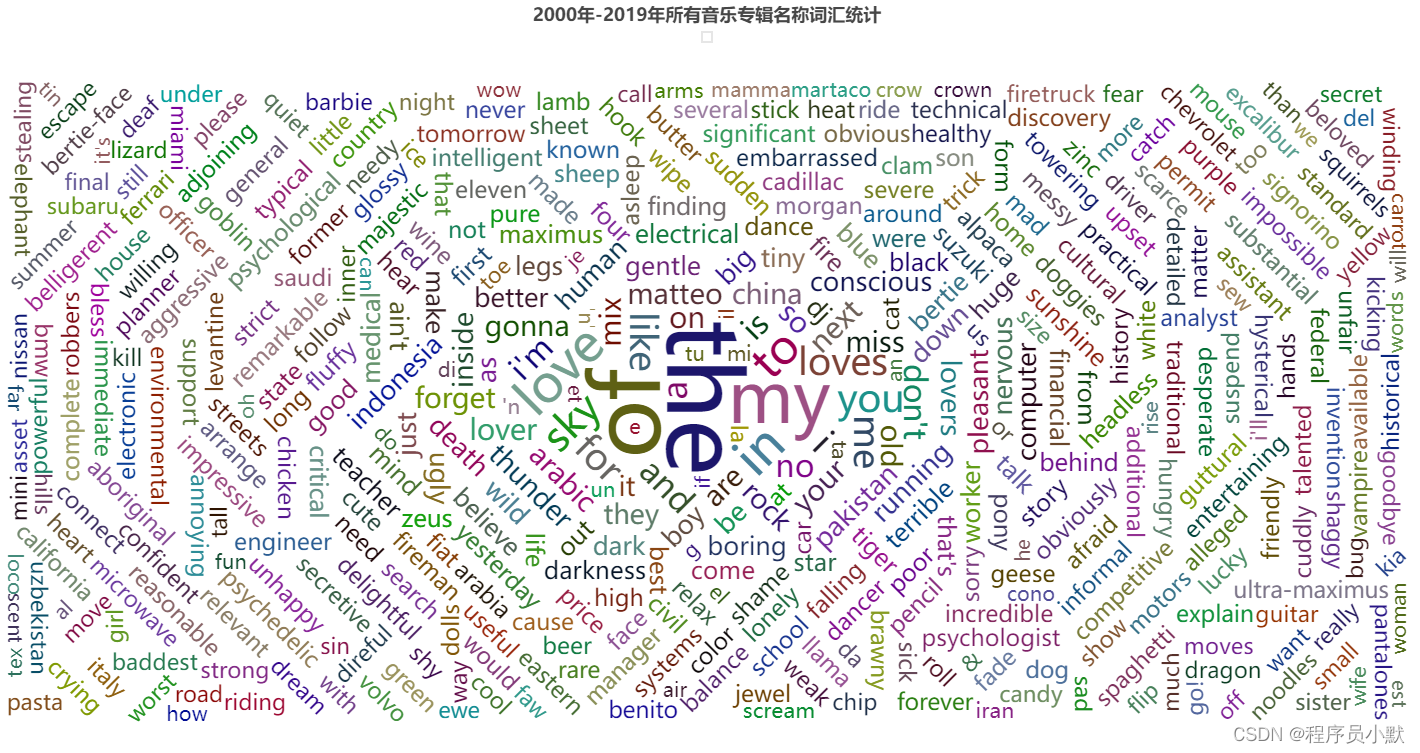
def drawCloud():
words = pd.read_csv("data/frequencyOfTitle.csv", header=None, names=['word', 'count'])
data = [(i, j) for i, j in zip(words['word'], words['count'])]
cloud = (
WordCloud(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add("次数", data, word_size_range=[20, 100], shape=SymbolType.ROUND_RECT)
.set_global_opts(title_opts=opts.TitleOpts(title="2000年-2019年所有音乐专辑名称词汇统计", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
tooltip_opts=opts.TooltipOpts(is_show=True))
)
cloud.render("wordCloud.html")
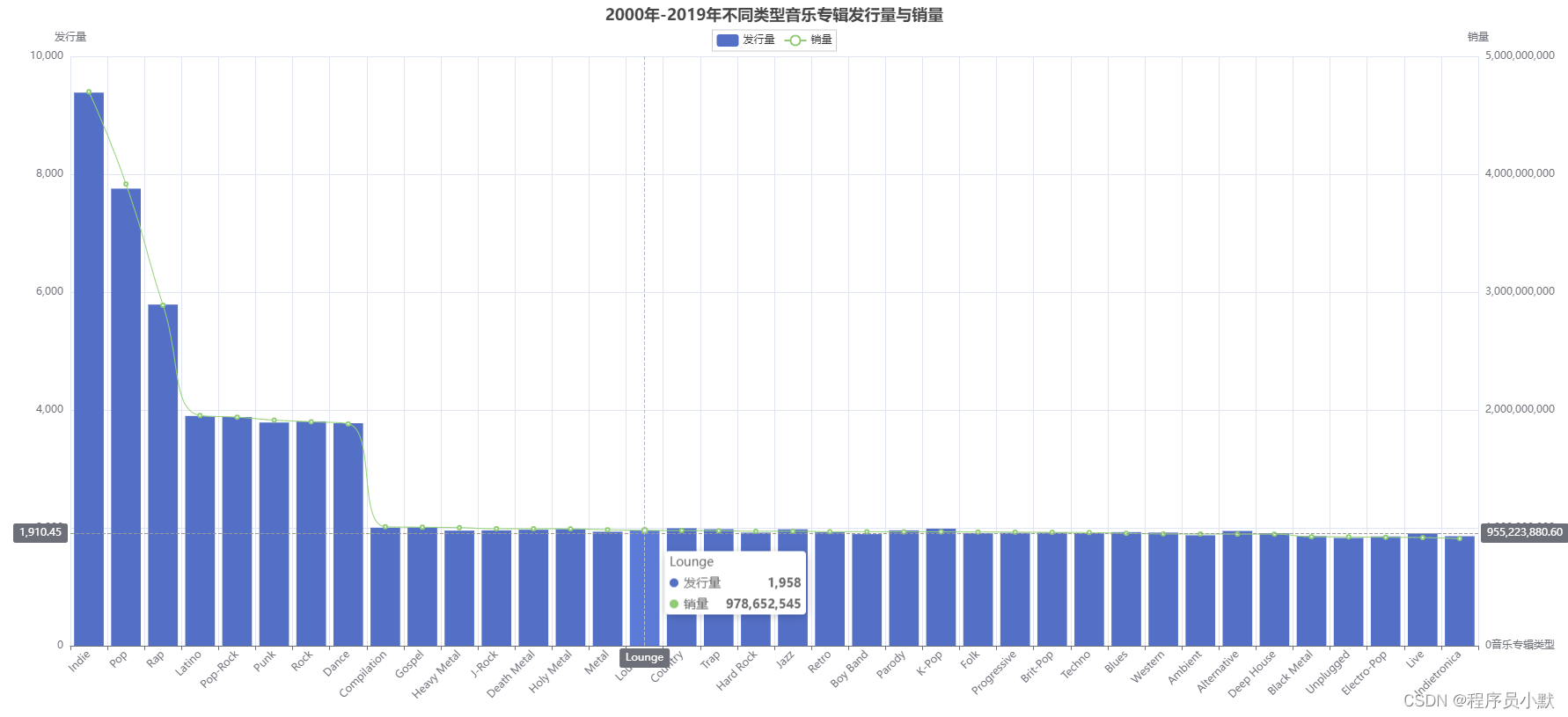
④ 柱状图+折线图
# 绘制2000年至2019年各类型的音乐专辑的发行数量和销量
def drawReleaseNumAndSalesOfGenre():
releaseNumAndSalesOfGenre = pd.read_csv("data/releaseNumAndSalesOfGenre.csv", header=None,
names=['Type', 'Sale', 'Num'])
bar = (
Bar(init_opts=opts.InitOpts(width="2000px", height="800px"))
.add_xaxis(releaseNumAndSalesOfGenre['Type'].tolist())
.add_yaxis("发行量", releaseNumAndSalesOfGenre['Num'].tolist(), label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="2000年-2019年不同类型音乐专辑发行量与销量", pos_left="center"),
legend_opts=opts.LegendOpts(pos_top="30px"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45, font_size=12), name="音乐专辑类型"),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=12),
name="发行量"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
# 添加右侧y轴
.extend_axis(
yaxis=opts.AxisOpts(
name="销量",
)
)
)
line = (
Line()
.add_xaxis(releaseNumAndSalesOfGenre['Type'].tolist())
.add_yaxis("销量",
releaseNumAndSalesOfGenre['Sale'],
yaxis_index=1,
z=2,
label_opts=opts.LabelOpts(is_show=False), is_smooth=True)
)
bar.overlap(line).render("releaseNumAndSalesOfGenre.html")
这里yaxis_index=1, 表示使用的 y 轴的 index,在单个图表实例中存在多个 y 轴的时候有用。
这里z=2表示 折线图组件的所有图形的z值。控制图形的前后顺序。z值小的图形会被z值大的图形覆盖。z 相比 zlevel 优先级更低,而且不会创建新的 Canvas。