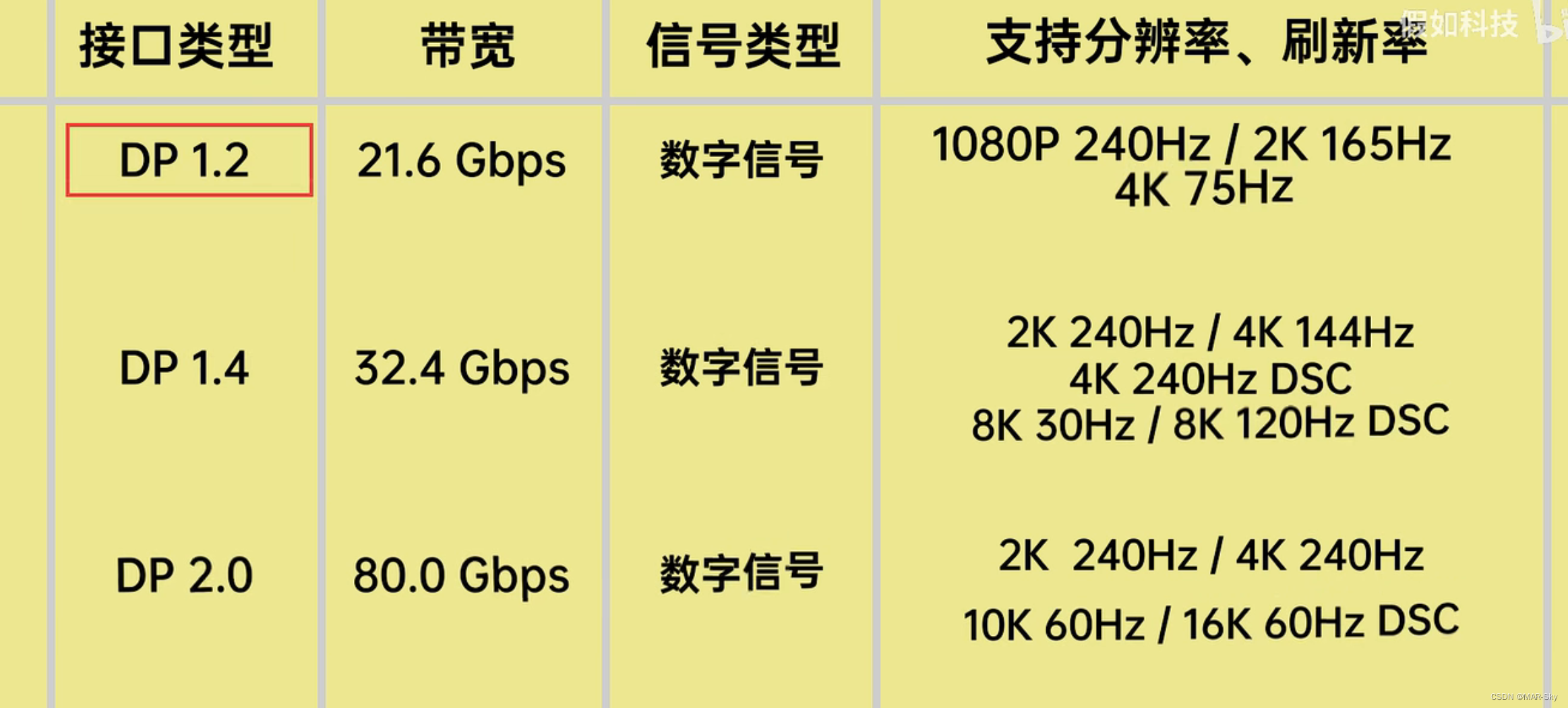
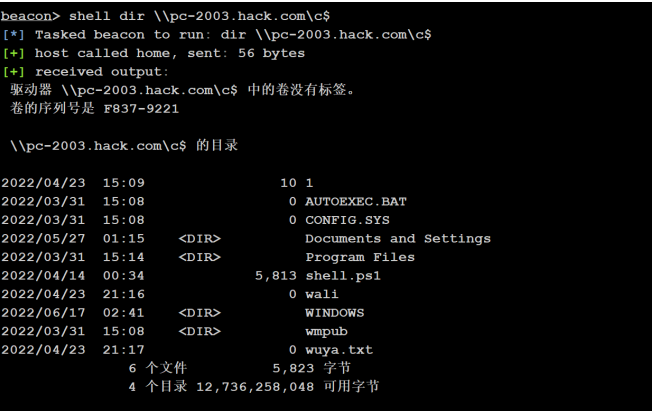
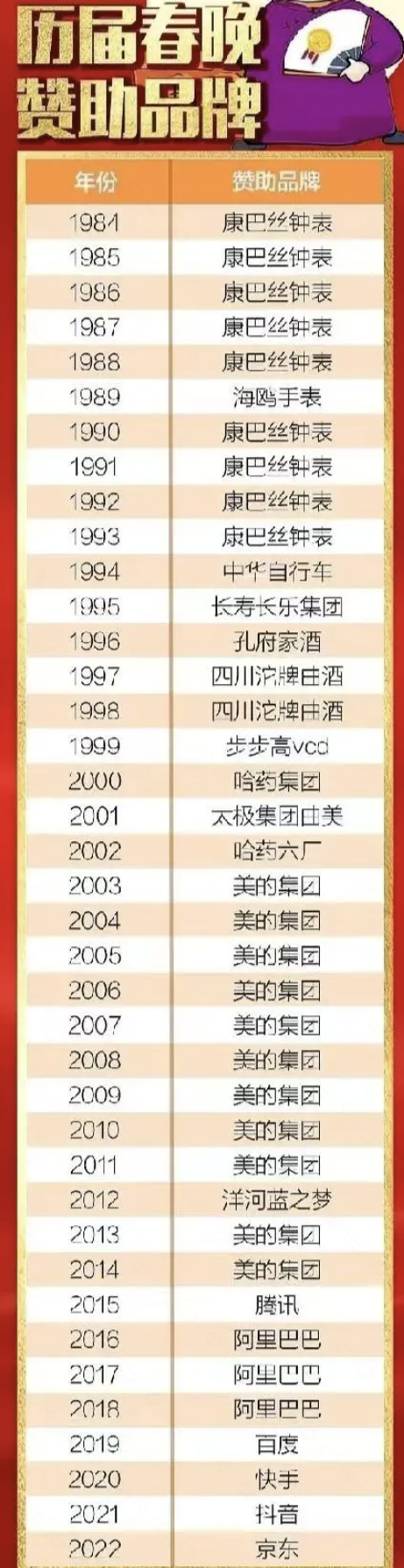
【1】读取CSV并进行透视
我们的原始数据格式:
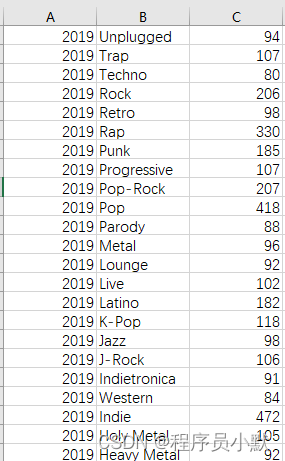
① 读取数据
pd.read_csv 会读取csv表格并使用names指定读取后的列名称。
import pandas as pd
releaseNumOfYear = pd.read_csv("data/releaseNumOfYear.csv", header=None, names=['Year', 'Genre', 'ReleaseNum'])
这里会呈现什么格式呢?如下所示:
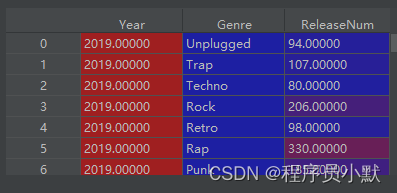
② 使用pivot进行透视
pivot函数用于从给定的表中创建出新的派生表,pivot有三个参数:索引、列和值
data = pd.pivot(releaseNumOfYear, index='Year', columns='Genre')
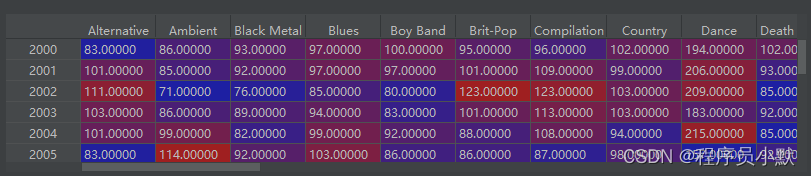
这里得到的data是什么呢?如下图所示:

也就是把①中读取的纵表透视为了横表(宽表)。
如何去掉ReleaseNum呢?如下所示
data['ReleaseNum']
如上得到的data格式为pandas.core.frame.DataFrame,我们如何遍历呢?
【2】DataFrame的遍历
① 按行遍历
for index,row in releaseNumOfYear.iterrows():
print(index,row)
这里index不用说了,就是每一行的索引。但是row,可不是你看到的一行数据而是如下图所示格式:
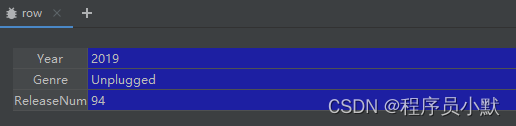
也就是 print(index,row)每次只需打印如下所示:
0 Year 2019
Genre Unplugged
ReleaseNum 94
Name: 0, dtype: object
也可以根据列名获取数据不打印label,如下所示:
for index,row in releaseNumOfYear.iterrows():
print(row['Year'] , row['Genre'] , row['ReleaseNum'])
# 如第一行打印结果
2019 Unplugged 94
② shape 函数
pandas.DataFrame.shape 返回数据帧的形状。假设data为Dataframe格式数据有2行3列:
- data.shape 返回data形状(2,3) 2行3列
- data.shape[0] 返回行数 2
- data.shape[1] 返回列数 3