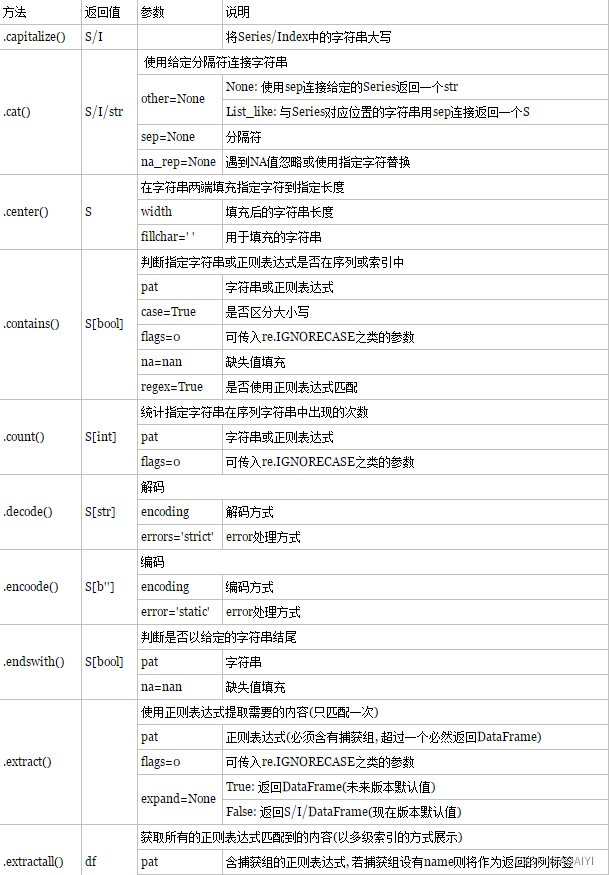
pandas——字符串处理
作者:AOAIYI
创作不易,如果觉得文章不错或能帮助到你学习,记得点赞收藏评论一下哦
文章目录
- pandas——字符串处理
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 1.cat() 拼接字符串
- 2.split()切片字符串
- 3.get() 获取指定位置的字符串
- 4.contains() 是否包含表达式,返回True或False。
- 5.replace() 字符串替换
- 6.slice() 按字符串下标的开始结束位置切割字符串。
- 7.count() 计算给定单词出现的次数
- 8.len() 计算字符串的长度
- 9.strip()去除前后的空白字符
- 10.lower() 全部小写
- 11.upper() 全部大写
- 12.index() 查找给定字符串的位置
- 13.capitalize() 首字符大写
- 14.swapcase()大小写互换
- 15.islower()至少包含一个小写字符, 且不包含大写字符。
- 16.isupper()至少包含一个大写字符, 且不包含小写字符。
- 总结
一、实验目的
熟练掌握pandas中字符串操作
二、实验原理
在使用pandas框架的DataFrame的过程中,如果需要处理一些字符串的特性,例如判断某列是否包含一些关键字,某列的字符长度是否小于3等等这种需求,如果掌握str列内置的方法,处理起来会方便很多。
三、实验环境
Python 3.6.1以上
Jupyter
四、实验内容
下面我们来详细了解一下,Series类或DataFrame的字符串String自带的方法有哪些。
五、实验步骤
1.cat() 拼接字符串
import pandas as pd
pd.Series(['a', 'b', 'c']).str.cat(['A', 'B', 'C'], sep=',')

pd.Series(['a','b','c']).str.cat(sep=',')

2.split()切片字符串
import numpy as np
s=pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'])
print(s)
s.str.split('_')
s.str.split('_',-1)
s.str.split('_',1)

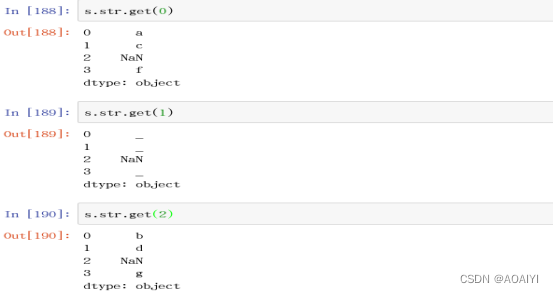
3.get() 获取指定位置的字符串
import numpy as np
s=pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'])
s.str.get(0)
s.str.get(1)
s.str.get(2)
4.contains() 是否包含表达式,返回True或False。
s.str.contains('d')

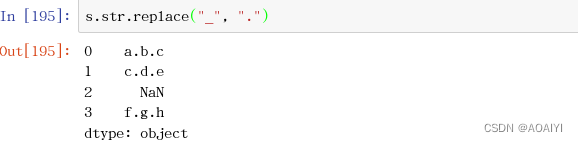
5.replace() 字符串替换
s.str.replace("_", ".")
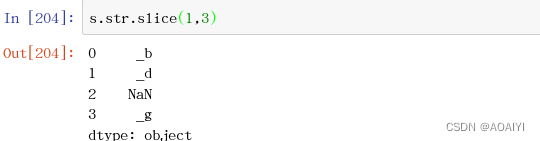
6.slice() 按字符串下标的开始结束位置切割字符串。
s.str.slice(1,3)
7.count() 计算给定单词出现的次数
s.str.count("a")

8.len() 计算字符串的长度
s.str.len()

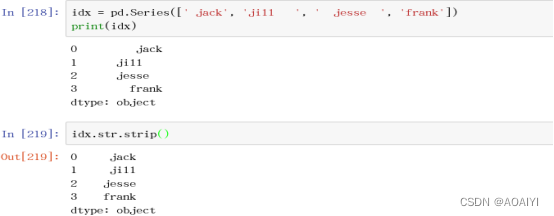
9.strip()去除前后的空白字符
idx = pd.Series([' jack', 'jill ', ' jesse ', 'frank'])
print(idx)
idx.str.strip()
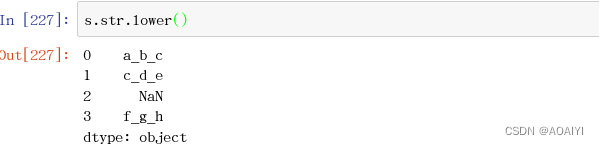
10.lower() 全部小写
s.str.lower()
11.upper() 全部大写
s.str.upper()

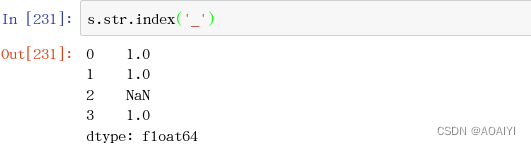
12.index() 查找给定字符串的位置
注意,如果不存在这个字符串,那么会报错!
s.str.index('_')
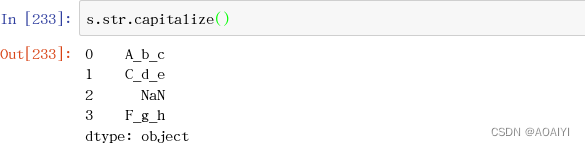
13.capitalize() 首字符大写
s.str.capitalize()
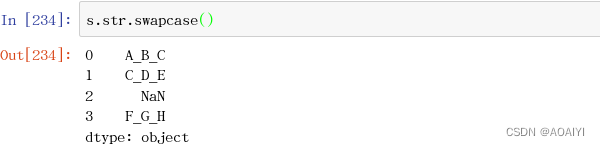
14.swapcase()大小写互换
s.str.swapcase()
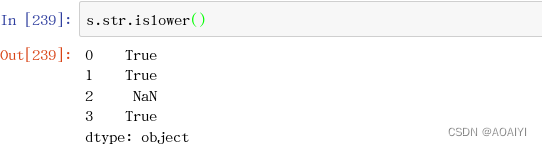
15.islower()至少包含一个小写字符, 且不包含大写字符。
s.str.islower()
16.isupper()至少包含一个大写字符, 且不包含小写字符。
s.str.isupper()

总结
为什么纸上谈兵不行?纸上谈兵太理想化了,把自己没有发现的问题隐藏了,当成了不存在的问题。只有实际多多亲自动手,才会发现有太多的问题是书上没提到的,也是自己没想到的。才会发现,一个小小的问题也要搞上半天。当然,如果你基础巩固的话,那这些问题应该都是可以被你解决的。熟练后,就不认为这些问题了。
不要看代码不难就感觉会了,只有自己的手打一遍,没有错误,编程的严谨些决定了,你错一个字母都不行。所以大家一定要注意,编程是自己打出来的,不是复制,粘贴你就会了,以后碰到了,还是不会。