引言:
北京时间:2023/2/12/18:04,昨天下午到达学校,摆烂到现在,该睡睡,该吃吃,该玩玩,在一顿操作之下,目前作息调整好了一些,在此记录,2月11,开学之日,是比较搞笑、难忘的一天。简洁记录之后,此时我们就开始新知识的学习,一起来看一看什么是C++中的内存管理。

C++中的内存管理
复习C语言中的内存管理
谈到内存管理,我们必须要想到的就是内存的三个基本大区,栈区、堆区、静态区,但当我们一想到这些东西的时候,我们还应该想到的就是,C语言中的动态内存规划,谈到动态内存规划,此时我们就应该想到其中的4大天王,4个有关动态内存规划的函数,malloc、calloc、realloc,所以接下来我们就来复习看一下这三个函数的使用和特性。
| 函数 | 使用方法和特性 |
|---|---|
| malloc: | int*p1 = (int*)malloc(10*sizeof(int));不会初始化空间 |
| calloc: | int*p1 = (int*)calloc(10,sizeof(int));会初始化空间 |
| realloc: | int*p2 = (int*)realloc(p1,40);用于扩容场景 |
| free: | 释放我动态开辟的空间 |
搞定了C语言中的知识之后,此时我们就开始我们C++中有关内存管理知识的学习啦!首先在我们内存中,我们的常量区也叫作数据区,并且我们的栈区是从高地址向低地址存放数据的,我们的堆区是从低地址向高地址存放数据的,如图所示:
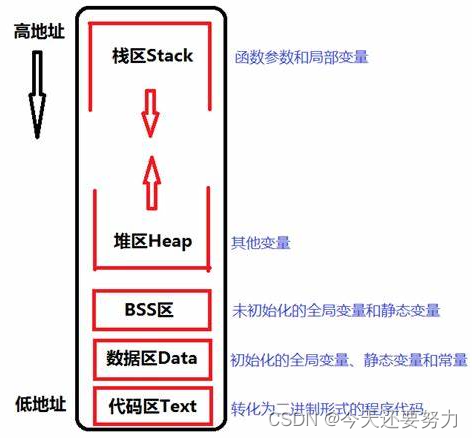
所以此时我们就带着这幅图去学习一下什么C++中的内存规划,C++中的内存规划主要就是涉及到两个关键字,new和delete搞定了这两个关键字的特性和使用方法,我们就把C++中的内存规划给学的差不多了,首先,C++中为什么要提出new和delete这两个关键字呢?其实目的主要就是因为在C语言中并没有专门针对于自定义类型使用的内存开辟函数和释放函数,有的只是针对于内置类型的函数(malloc、realloc、malloc、free),并没有专门给自定义类型使用的函数,所以在我们的C++中有了类和对象的概念之后,自定义类型变得是更加的重要,所以为了专门给自定义类型的内存申请和释放,C++中就提出了new和delete这两个函数,并且我们的new和delete不仅针对自定义类型可以使用,对我们内置类型也是同样适用的,例如:int* p1 = new int;意思就是开辟一个整形类型给p1指针,但注意,此时的该内存是没有被初始化的,只有这样写:int* p1 = new int(10);此时的该整形内存才会被初始化为10,所以我们的new关键字开辟的空间,不管是自定义类型还是内置类型,此时你自己都是可以决定要不要进行初始化,决定初始化的值到底是给多少,所以这就是new的好处,不仅可以对所有类型开辟空间,还可以决定初始化,注意:此时上句代码一定要区别于下面这句代码:int* p1 = new int[10],上述代码的意思是开辟一个整形空间给p1,并且将该空间初始化为10,而该句代码的意思却是,开辟10个整形空间给p1,并且无初始化效果,若你想要有初始化效果,那么此时你就可以写成这样:int* p1 = new int[10] {1,2,3,4,5,6,7,8,9,10};
具体使用如图所示:

并且此时看见上述的代码是,我们要意识到,我们的new和delete要配套使用,malloc和free要配套使用,不可以交叉使用,不然会出问题。
总:new对于自定义类型的使用就是new+类型+圆括号(初始化)或者中括号(个数),对于自定义类型的使用就是,new单个对象就是调用构造函数,new多个对象就是调多次构造函数,所以new/delete和malloc/free最大的区别就是它们对于自定义类型使用时,new会自动调用构造函数,delete会自动调用析构函数。
operator new 和operator delete的使用
new是用户,也就是我们写代码的时候进行动态内存申请和释放的操作符,operator new和operator delete是系统提供的全局函数(并不是什么重载,就是一个库里的函数而已),也就是编译器使用的函数,所以new申请空间使用的就是底层函数operator new,delete释放空间使用的就是底层函数operator delete,并且此时operator new 实际上使用的却又是malloc来申请空间,operator delete实际上使用的是free来释放空间,所以operator new和operator delete本质上就是malloc和free的封装。搞懂了这些,此时我们就再来看一下,C++中为什么要有new和delete。
再谈new出现的意义
1.要满足空间申请(因为C语言中已经有该功能,所以申请空间的功能就不需要重新实现了,直接原样的使用malloc就行)
2.满足自动调用构造函数去初始化自定义类型(C语言中没有该功能,所以该功能是需要自己去实现的,所以此时就要在malloc的基础之上再加上这一功能,这也就是new出现的原因)
所以在上述的基础上,我们就知道了new出现的原因,就是帮助用户去使用C语言中的malloc功能,并且实现自动调用构造函数的功能的一个封装函数。并且此时因为malloc失败之后返回的是空指针,不符合我们面向对象的过程,所以我们如果想要失败之后返回的是异常的话,就需要重新去写一个函数出来,该函数就是operator new,这也就是operator new出现的原因。所以operator new就是为了封装malloc前提下,也可以实现自动调用构造函数和开辟失败之后可以返回一个异常给我们而不是返回空指针的作用,这些适合自定义类型使用的开空间特性。所以这就是operator new出现的原因,当然此时的operator delete是同理如此使用的。只是此时delete在使用之前必须先调用析构函数而已,只有把所有的空间资源调用析构函数释放完了之后,delete才会去释放该对象,原理和new调用operator new是一样的,本质就是去调用free函数和malloc函数。
并且此时除了operator new和operator delete 还有一个operator new[];
一个原理,此时的调用原则就是:operator nwe[ ]->operator new->malloc
new和delete对于内置类型和自定义类型的区别
好的,搞懂了这些,此时我们就来看一下new和delete对于内置类型和自定义类型的区别,主要就是为了研究一下怎么写代码才不会出问题,到底需不需配套使用,例如:此时我有一个栈,我用这个栈在main函数中创建了一个局部对象 st(Stack st),此时的这个对象是因为它是一个自定义类型,所以此时它是不需要我自己去释放的,因为自定义类型都会去自己调用构造函数和析构函数,只有内置类型才是因为栈帧的销毁而销毁的,但一定要去注意指针这个内置类型, 因为指针变量都是一个内置类型的变量,无论是什么类型的指针都是一样的,例如:Stack* ptr和int* p1,此时的ptr和p1在本质上都是一个内置类型对象,所以不需要我们自己去销毁,它会自己随着栈帧的销毁而销毁,明白了这个东西,此时重点就来了。
重点:虽然如上述所说,指针都是内置类型,会自己销毁,但是指针指向的那块空间是不会自己销毁的,所以此时如果你不仔细做处理的话,此时你的程序就会因为没有释放内存而崩溃,所以,当我们创建了一个指针变量的时候,就一定要考虑到,指针指向的空间存放在什么位置,例如:此时的该栈,栈中的数据中有一个数组,此时的该数组是一个动态数组,是通过new关键字开辟出来的,所以此时可以明显的知道,该空间是在堆区上的,所以此时ptr指针指向的该空间是不会自己释放的,所以需要我们进行手动释放,例如:(delete ptr;),所以此时一个自定义类型的指针ptr,例如:Stack* ptr = new Stack;此时就不可以像Stack* st;一样,想要使用free和delete都可以释放指针指向的空间。因为Stack st;并没有多余的空间需要清理,此时它只要把在栈中的成员变量中的那个指针,new开辟出来的那块动态数组的空间清理掉就可以了(因为该空间是栈中的new开辟出的一个动态数组),所以free可以直接把st对象中的那块Stack中的动态开辟的数组空间直接给释放掉。然而,我们的Stack* ptr = new Stack;此时指针ptr是在内存中的栈帧上的,但ptr指向了一块new出来的Stack,该Stack是在堆区的,并且Stack中还有一个指针,该指针指向的空间又是new出来的,所以此时这块空间也是在堆区上的,所以此时ptr指向的空间又指向了一块空间,所以此时不可以直接free(ptr),会有内存泄露问题,只有把Stack中new出来的空间给先释放才可以把ptr指向的空间释放,所以此时就不可以使用free去直接释放,而是要使用delete ptr;去释放,因为delete会先去调用析构函数(但是前提是该指针指向的空间的类型为自定义类型),把ptr指针指向的空间中又开辟的空间给先析构掉,然后再去operator delete,调用free,去释放ptr指针指向的空间,但如果上述的情况你写成free ptr;也是可以的,只是少调用了一次析构函数而已,然后造成内存泄露的问题,因为在C和C++中并不会帮助我们检查内存泄露问题,所以综上,我们在释放内存的时候,一定要匹配使用,并且并不是自定义类型就一定有问题,主要是还要看该自定义类型中是否存在指针指向的另一块空间。
浅浅的摸一下泛型编程
从模板看泛型编程
写了这么久的代码,我们知道在C++中有一个东西叫函数重载,可以让我们把一个函数名(Swap)给重复使用,通过参数类型的不同来区别函数的不同,但是会发现,有一种类型的参数,我就需要写一个该类型的Swap函数,这样是比较麻烦的,所以C++中就又提出了模板的概念,该概念的意思就是可以让我们实现一个与类型无关的Swap函数,别的函数就通过该模板进行使用,就是相当于存在一个模具,通过给这个模具填充不同的材料(类型),来获得不同的铸件(既生成具体类型的代码),这样就可以节省很多的代码量了,所以总的来说:泛型编程就是编写与类型无关的通用代码,是代码复用的一种手段,模板就是泛型编程的基础。
什么是模板
首先模板分成两类,一个是函数模板,一个是模板类:
| 函数模板 |
|---|
| 类模板 |
什么是函数模板
概念:函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
具体模板的实现:如图

注意:此时虽然在调试期间,我们看到的是同一个函数,但是只是编译器处理过之后的,本质在系统内部,是两个不同的函数,从栈帧的大小和汇编代码这些方面都是可以看出来的。
并且此时我们知道在C++类和对象中,有一个对象实例化的过程,所以此时模板的使用也是有一个模板实例化的过程的,此时的该过程的理解,就可以让我们更好的理解为什么模板使用的是两个不同的函数,如图:

模板实例化的一些小问题:
主要是分为自动推演模板类型和显示实例化两种
什么是自动推演模板类型:例, cout << Add((double)b, d) << endl;cout << Add(a, (int)c) << endl;此时就是我们自己去进行强制类型转换,把不是同类型的两个数据给转换成同一类型,这样才可以去实现模板,不会出现无法识别模板的问题,
显示实例化: cout << Add<double>(a, c) << endl; cout << Add<int>(b, d) << endl;这两句代码就是显示实例化,直接把该数据的类型写在函数名的后面,确定了该函数数据的类型,此时这样模板就可以很好的识别参数了。
如图:
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a = 1, b = 2;
double c = 1.1, d = 2.2;
swap(a, b);
swap(c, d);
//实参传递给形参,自动推演模板类型
cout << Add((double)b, d) << endl;
cout << Add(a, (int)c) << endl;
//显示实例化
cout << Add<double>(a, c) << endl;
cout << Add<int>(b, d) << endl;
return 0;
}
并且此时强调,我们的库中已经用模板给我们实现了一个swap函数,所以以后我们可以直接使用。
并且对于非模板函数和同名函数模板,如果其它条件都相同,在调用时会优先调用非模板函数而不会从该模板产生出一个实例,如果模板可以产生一个具有更好匹配的函数,那么选择模板(如类型不相同的两个数据);并且模板函数是不允许自动类型转换的,只有普通函数才可以进行自动类型转换。
如图:

什么是类模板
使用模板类,直接就可以把我们以前使用的typedef的方法给淘汰掉了,模板类直接就可以搞定每个数据结构的类型,直接使用显示实例化的方式,把该数据结构的类型给确定,根本不需要去改什么typedef定义的类型,一个尖括号(<>) 直接搞定了,剩下的交给编译器去完成就行了。
如图:

强调:类模板只能使用显示实例化的方式去使用