67 自注意力【动手学深度学习v2】
深度学习学习笔记
学习视频:https://www.bilibili.com/video/BV19o4y1m7mo/?spm_id_from=autoNext&vd_source=75dce036dc8244310435eaf03de4e330
给定长为n 的序列,每个xi为长为d的向量,自注意力将xi 既当key又当value又当query,这样对每个序列抽取特征得到y1-yn。
yi对应xi抽取的特征,xi是query , key-value是x1~xn。
给定一个序列,对序列中的每个元素输出,有点像RNN,不需要额外的key’-value,query都是一个东西,都是self就不要decode encode。

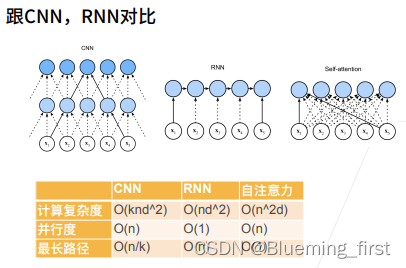
跟CNN,RNN对比
CNN 计算复杂度O(knd^2) K 是看的窗口大小(每次看K大小)。并行度是每个输出可以做并行计算。最长路径是假设有个信息要传递到很后的地方,最长序列传过去是n/k。
RNN计算复杂度O(nd^2) 每次矩阵乘法是d^2,并且要做n次。并行度O(1) 也就是很糟糕,必须等上一个时刻做完才能做下一个。最长路径是 x1的信息要一直传递到xn,要经过O(n)的序列。 RNN强时序的模型对序列的记忆比较好,特别擅长记忆一下序列。
自注意力机制(self attention) O(n^2d) 算output时query要和所有的input的做乘法,input长度是d,所有自注意力在序列比较长时,计算量比较大。并行度O(n)每次算yi 时不影响,可以继续算别的。 最长路径O(1)到任何的信息到任何一个输出直接就过去了,不需要再绕,即使在很远的地方也立即抓取过来。
于是自注意力机制比较适合长的序列,是因为设计使得它可以看得比较宽,最长路径是O(1)。
TPU是巨大的矩阵乘法做运算,非常适合attention /transformer这样的架构。
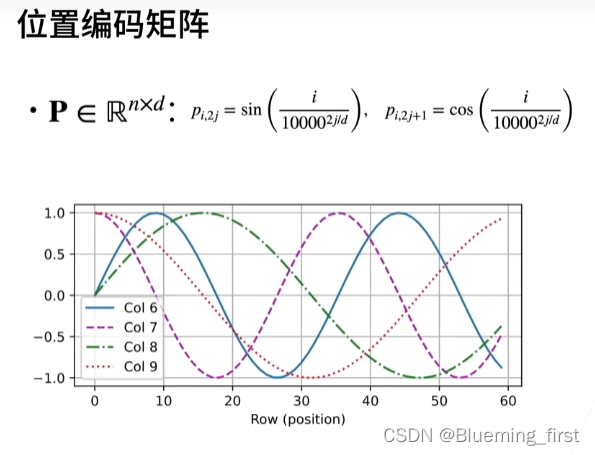
位置编码
和CNN/RNN相比,自注意力没有记录位置信息。加入位置信息的办法是位置编码,不改变注意力机制本身,将位置编码信息放到输入里面。假设有n个输入序列,每个序列d 个特征(n*d),位置编码矩阵也是同样大小的P,包含很多位置信息,将P+X再作为自编码的输入。
奇数列是个sin函数,偶数列是一个cos函数。

x坐标是行数(对应每个样本),曲线分别对应第6-9维。每次加进去一点点信息。
用sin,cos的好处是编码的是相对的位置信息,位置编码i+q可以线性的投影到i的位置信息,投影矩阵和序列中位置i是不相关的 ,这样在一个序列中假设一个词在序列中后两个位置相对应的时候,他们 不论出现在序列的哪个位置,对于位置信息,他们可以通过同样的线性变换w找出来。这样编码,用线性w 建模会比较好找这些句子的相对位置。

自注意力池化层将 xi 既当key,value又当query来抽取对应的yi 作为特征,自注意力池化层就可以给一个序列就能输出它的元素。可以完全并行,最长序列为1,也就说可以看到整个序列的信息。
计算复杂度比较高。
没有位置信息,在输入里面加入位置编码,这样在处理时是有时序信息的。编码用的sin,cos函数,使得序列在哪里相对位置都没有变。

QA:
- 给一篇文章,给几个问题,在文章中找到答案,类似于nlp中的问答。做一些推理会比较困难(chatGPT?)
- 自注意力机制可以理解为一个网络层,就像CNN或RNN的一层理解,他就是一个layer