本文是阅读《Rust程序设计语言》的学习记录,配合视频《Rust编程语言入门教程》食用更佳
环境搭建
-
windows下载
rustup_init.exe,点击安装,默认选择msvc的toolchain,一路default即可 -
解决下载慢的问题,在
powershell中修改环境变量$ENV:RUSTUP_DIST_SERVER='https://mirrors.ustc.edu.cn/rust-static' $ENV:RUSTUP_UPDATE_ROOT='https://mirrors.ustc.edu.cn/rust-static/rustup' -
使用vscode作为ide开发,安装rls或ra插件,推荐ra(rust编程语言服务器,承担语法检查等工作)
-
使用原生的cargo进行new、build和run的操作
-
下载第三方包速度慢的问题,在
~/.cargo/config中换源[source.crates-io] registry = "https://github.com/rust-lang/crates.io-index" replace-with = 'ustc' [source.ustc] registry = "git://mirrors.ustc.edu.cn/crates.io-index" ## registry = "https://mirrors.ustc.edu.cn/crates.io-index" -
配置文件,包名等信息,添加依赖,由ra自动拉取
[package] name = "hello" version = "0.1.0" edition = "2018" [dependencies] rand = "0.3.14" -
vscode的task.json和launch.json配置,参考cargo-tutorial
Hello world
Rust 程序设计语言能帮助你编写更快、更可靠的软件。开发者正在使用Rust在系统和工具领域对当前已有的项目进行重构。Rust的编译器将内存和代码的检查聚焦在程序逻辑方面。不可否认的是,Rust是一门面向未来的语言,在操作系统,嵌入式,音视频分析等领域大展身手。同时,Rust吸收了前辈的诸多优势,正在不断修补并增加新的特性来完善自身。
本文在学习Rust编程指南过程中的一些记录,参考资料为
-
rust-lang/book
-
Rust程序设计语言(中文版)
Rust 是一门预编译(ahead-of-time compiled)语言,可以直接分享和运行编译后的可执行文件
通常使用cargo工具创建Rust项目,具备完善易用的工具链(区别于C/CPP),cargo是Rust的构建系统和包管理器,可以胜任构建代码、下载依赖库,以及编译这些库等任务。
$ cargo new rusttour # 自动创建git项目
$ ll -al
drwxr-xr-x 1 Administrator 197121 0 Feb 7 10:01 .git/
-rw-r--r-- 1 Administrator 197121 8 Feb 7 10:01 .gitignore
-rw-r--r-- 1 Administrator 197121 152 Feb 7 10:01 Cargo.lock
-rw-r--r-- 1 Administrator 197121 177 Feb 7 10:01 Cargo.toml
drwxr-xr-x 1 Administrator 197121 0 Feb 7 10:01 src/
drwxr-xr-x 1 Administrator 197121 0 Feb 7 10:01 target/
Cargo.toml为cargo项目的配置文件,和golang非常类似,使用TOML格式进行配置
$ cargo check # 快速编译检查,比build快得多
$ cargo build
$ cargo run
$ cargo build --release #优化编译
cargo使得不同平台下Rust项目的管理方式统一,便于项目的开发和维护
通用概念
参考官方文档给出的示例程序学习基本的语法概念。如果对其他语言的语法有所接触,会发现导入依赖包和c#相似,而语法和cpp类似。
语法的细节不用过多的纠结(和熟练度相关),只需要关注一些比较特殊的语法即可
- 导入外部模块(crate)的方式为use,通过
::区分名称空间。库 crate 可以包含任意能被其他程序使用的代码,但是不能独自执行。rand为外部依赖,需要在Cargo.toml的dependencies中添加 - 使用
println!打印到标准输出 - 变量的初始化,涉及到Rust的静态强类型系统,具备自动类型推断。
- 由于是强类型语言因而需要考虑类型转换。类型通过
:标识,和python类似的类型标注 - 创建新的变量类型时可以复用已有的变量名,即类型遮蔽(shadow)
- Rust的错误处理的语法比较特殊,流式写法的风格
- Rust的模式匹配语法
use rand::Rng;
use std::cmp::Ordering;
use std::io;
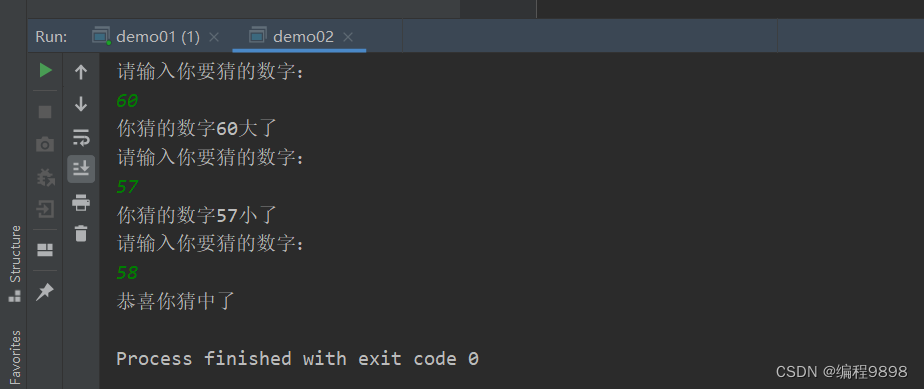
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..101);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {}", guess);
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}
Rust语法中较为特殊的部分
-
默认变量不可变,可变需要用mut修饰,但是变量终究和常量(const)不同。
let x = 10; let x = x + 1; // 遮蔽,创建了新的变量 let mut x = 10; x = x + 1; // 可变 const y = 10; // 常量 -
数组在栈上分配的已知固定大小的单个内存块,此处可能会产生索引越界错误,
panicked at 'index out of bounds'。 -
函数签名中,必须明确声明每个参数的类型。返回值可以是表达式(没有分号)
fn plus_one(x: i32) -> i32 { x + 1 } -
三种循环语句的写法,break的特殊用途(标签跳转,循环语句返回值)
for element in a { println!("the value is: {}", element); }
所有权
Rust的所有权系统,使得无需垃圾回收器(garbage collector)即可保证内存安全。“没有手动管理内存的经历可能无法体会Rust所有权系统的良苦用心”
编程语言对于内存的管理无非以下三种
- 垃圾回收机制
- 手动分配和释放内存
- 编译器检查内存管理
Rust采用第三种方式(通过所有权系统管理内存),考虑堆和栈内存的区别。所有权系统的目的是最大限度对堆内存进行管理。内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer),即分配堆内存。
所有权规则
(1)Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
(2)当所有者(变量)离开作用域,这个值将被丢弃
永远记得在alloc之后使用free释放内存,这通常是由gc来完成的。程序编译过程中可能需要将申请一段未知大小的内存,这段内存使用可能随着程序运行而变化,因而必须在堆中申请。
Rust通过作用域判断变量是否继续使用(自动释放这部分内存),在变量离开作用域是调用drop函数释放内存
(3)值在任一时刻有且只有一个所有者。
以下代码在堆中申请字符串内存,并将指针赋值给变量s1,之后将s1赋值给s2。在main函数执行完毕后,s1和s2失效被丢弃,因而这段内存可能会被连续释放两次(二次释放)
Rust 永远也不会自动创建数据的 “深拷贝”,Rust的以上行为被成为移动操作(而非浅拷贝)
let s1 = String::from("hello");
let s2 = s1; // 移动 move
println!("{}, world!", s1); // 报错
如果需要深拷贝,可以使用clone
let s1 = String::from("hello");
let s2 = s1.clone(); // 深拷贝
println!("s1 = {}, s2 = {}", s1, s2);
Rust 有一个叫做 Copy trait 的特殊标注,如果一个类型实现了 Copy trait,那么一个旧的变量在将其赋值给其他变量后仍然可用。实现了 Drop trait 的类型就不能再使用 Copy trait。
实现了copy trait的类型有:整型,布尔,浮点,字符和元组(当且仅当元素为前四种)
let x = 5;
let y = x; // 在栈上拷贝数据
println!("x = {}, y = {}", x, y);
当变量为函数的参数时,以上的结论仍旧有效
fn main() {
let s = String::from("hello");
takes_ownership(s); // s没有实现copy trait,s移动到函数中,之后不可用
}
fn takes_ownership(some_string: String) {
println!("{}", some_string);
// drop 方法,释放some_string内存
}
当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有。以下函数中所有权在函数内外转移,如果在函数后仍旧需要使用变量,则必须将变量作为返回值转移出来(否则失效)。这种操作显然很繁琐
fn takes_and_gives_back(a_string: String) -> String {
a_string // 返回 a_string 并移出给调用的函数
}
引用和借用
使用引用,可以使用值但不获取其所有权(意味着变量不会失效),这种操作称为借用
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1); // 传引用
println!("The length of '{}' is {}.", s1, len); // string仍可用
}
fn calculate_length(s: &String) -> usize {
s.len()
// string没有转移
}
如果需要修改引用的值,需要将引用标注为可变的。有以下原则
-
在同一时间,只能有一个对某一特定数据的可变引用(避免数据竞争产生的未定义行为)
let r1 = &mut s; let r2 = &mut s; -
无法在拥有不可变引用的同时拥有可变引用(避免写行为影响读操作)
let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 let r3 = &mut s; // 大问题 -
一个引用的作用域从声明的地方开始一直持续到最后一次使用为止。意味着只要使用过一次,上面的两个引用即离开作用域,规则刷新。
let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 println!("{} and {}", r1, r2); // 此位置之后 r1 和 r2 不再使用 let r3 = &mut s; // 没问题 -
Rust编译器会检测悬垂指针(指向的内存可能已经被分配给其它持有者)
fn dangle() -> &String { let s = String::from("hello"); &s // 返回字符串 s 的引用,报 }
切片
同样是为了避免已经存在的索引失效,通过使用切片让编译器主动检查
字符串切片时String 中部分值的引用,“字符串 slice” 的类型声明写作 &str,实际上字符串的字面值就是切片。切片也是引用(指向部分数据),默认不可变。
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // 返回切片 &str
s.clear(); // s.clear()会获取s的可变引用,从而报错
println!("the first word is: {}", word);
}
结构体和枚举
结构体
不得不说各种语言的数据结构都是类似的,Rust的结构体类似于golang的结构体。结构体是一种类型,每部分可以分别对应不同类型。
结构体不允许只将某个字段标记为可变,想要修改成员必须将整个结构体声明为可变
fn main() {
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}
复用其他的结构体,.. 语法指定了剩余未显式设置值的字段应有与给定实例对应字段相同的值
fn main() {
let user2 = User {
email: String::from("another@example.com"),
..user1
};
}
为了方便调试,直接使用println!宏需要结构体实践display trait。但是可以指定debug模式显示更多信息
#[derive(Debug)] // 指定结构体实现Deubg trait
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {:?}", rect1);
// println!("rect1 is {:#?}", rect1);
}
继续看结构体的方法实现,类似于golang和python
impl Rectangle {
fn area(&self) -> u32 { // &self 实际上是 self: &Self 的缩写
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool { // 多个参数
self.width > other.width && self.height > other.height
}
}
在vscode中借助插件能够看到结构体目前实现了两个implementation
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7OUh1nt7-1676200228390)(assets/image-20230208145057388.png)]
不指定self为第一个参数的称为关联函数,使用结构体名和 :: 语法来调用这个关联函数
impl Rectangle {
fn square(size: u32) -> Rectangle {
Rectangle {
width: size,
height: size,
}
}
}
枚举
枚举类型能够增强代码的可读性,咋一看和结构体类似。但是枚举能够在同一种类型中定义不同的结构,尽管可以用4个结构体(4种类型)实现和以下相同的逻辑,但是无疑增加了复杂度。
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
同样可以为枚举实现方法
impl Message {
fn call(&self) {
// 在这里定义方法体
}
}
在标准库中Option枚举类型处理空值(空指针)。空值(Null )是一个值,它代表没有值。在有空值的语言中,变量总是这两种状态之一:空值和非空值。
Option枚举类型被包含在了 prelude(预导入模块),可以不需要 Option:: 前缀来直接使用 Some 和 None。
在对 Option<T> 进行 T 的运算之前必须将其转换为 T,确保该变量不为空,确保代码的安全性
enum Option<T> {
Some(T),
None,
}
包管理和crate
Rust的包管理主要涉及到以下模块系统
- 包(Packages): Cargo 的一个功能,它允许你构建、测试和分享 crate。
- Crates :一个模块的树形结构,它形成了库或二进制项目。
- 模块(Modules)和 use: 允许你控制作用域和路径的私有性。
- 路径(path):一个命名例如结构体、函数或模块等项的方式
回顾下cargo new 创建的新项目结构,如果src/main.rs 存在则是二进制crate,如果 src/lib.rs 存在则是库crate。根crate和包的名称相同
paakage的要点
- 包含一个cargo.toml,描述如何构建crate
- 只能包含0或1个库crate
- 可以包含任意数量binary create(在src/bin路径下)
惯例
- binary create 的 create root 为 /src/main.rs,编译的入口,和package 名称相同
- library create 的 create root 为 /src/lib.rs,编译的入口,和package 名称相同

将mod拆分为多个文件
file not found for module `hosting`
to create the module `hosting`, create file "src\front_of_house\hosting.rs" or "src\front_of_house\hosting\mod.rs"
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pufesco9-1676200228396)(assets/image-20230208163540664.png)]
错误处理
Rust将错误分为可恢复的错误(Result)与panic
默认情况下Rust会进行调用栈回溯,清理调用栈数据会有性能损耗,也可以 配置不需要清理调用栈(交给os清理)
[profile.release]
panic = 'abort'
当主动触发panic时,报错会提示开启backtrace,例如宏 panic!("crash and burn");,只有在debug模式下才能看到栈的回溯信息
thread 'main' panicked at 'crash and burn', src/main.rs:2:5
note: Run with `RUST_BACKTRACE=1` for a backtrace.
其他语言中通过try…catch捕获异常,而Rust则具备Result枚举类型(同样是预导入的)对结果进行模式匹配。Result有两个成员Ok和Err例如
let f = File::open("hello.txt");
let f = match f {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("world.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {:?}", e),
},
other_error => panic!("Problem opening the file: {:?}", other_error),
}
};
当异常嵌套时,match语法会变得难以理解,因而有unwrap和expect的写法(实际上和match结果相同)
-
如果
Result值是成员Ok,unwrap会返回Ok中的值。如果Result是成员Err,unwrap会为我们调用panic! -
expect和unwrap的用法一致,但是在触发
panic!可以指定error信息
let f = File::open("hello.txt").unwrap();
let f = File::open("hello.txt").expect("Failed to open hello.txt");
此外,错误可以不在当前作用域处理,而是向上传播(将Result作为函数返回值),仍旧可以用?简写
- 如果
Result的值是Ok,这个表达式将会返回Ok中的值而程序将继续执行。 - 如果值是
Err,Err将作为整个函数的返回值,就好像使用了return关键字一样
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut f = File::open("hello.txt")?; // 和上面的代码一致
泛型和trait
泛型太常见了,主要目的是使用泛型来编写不重复的代码,听说隔壁golang也要支持泛型了.
主要考虑在以下方式使用的泛型
- 函数
- 结构体
- 枚举
- 方法
Rust 实现了泛型,使得使用泛型类型参数的代码相比使用具体类型并没有任何速度上的损失
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程
trait 告诉Rust编译器某种类型具有哪些可以与其他类型共享的功能
- trait bounds 指定泛型是任何拥有特定行为的类型
- trait和接口(interface)的概念类似但是有所区别
不同类型可能具有相同的方法,称为共享相同行为,原则如下
- 只有方法签名没有实现
- trait有多个方法,每个独占一行
- 实现trait的类型需要提供方法实现(在trait中没有默认实现时),如果有默认实现会进行方法重载
- 类型或trait必须至少有一个是本地crate中定义的
- 无法为外部类型实现外部trait(为标准库vec实现标准库的display trait)
以上的定义实际上和接口一致,下面的各种概念可以直接联系接口理解
// src/lib.rs
pub trait Summary {
fn summarize1(&self) -> String;
fn summarize2(&self) -> String { // 默认实现
String::from("(Read more...)")
}
}
impl Summary for NewsArticle {
fn summarize1(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
有了trait我们可以实现多态了,方法的类型为实现的trait,参数可以将实现该trait的类型传入
pub fn notify(item: impl Summary) {
println!("Breaking news! {}", item.summarize());
}
trait实现适用于较为简单的情景,较为复杂的情景可以使用语法糖(trait boundary)简化,以下代码和上面的代码意义相同
pub fn notify<T: Summary>(item: T) {
println!("Breaking news! {}", item.summarize());
}
对于实现多个trait的情形,trait boundary 的写法如下,参数同时实现了Summary和Display
pub fn notify(item: impl Summary + Display) {
pub fn notify<T: Summary + Display>(item: T) {
fn some_function<T: Display + Clone, U: Clone + Debug>(t: T, u: U) -> i32 {
对于上面的第三行中写法较为冗长,可以继续通过语法糖简化,类似C#的写法
fn some_function<T, U>(t: T, u: U) -> i32
where T: Display + Clone,
U: Clone + Debug
{
将trait作为参数返回 ,函数的返回类型只能为同一种(即使实现了同样的trait )
fn returns_summarizable() -> impl Summary {
甚至可以在有条件指定泛型方法的实现,以下只有实现了Display + PartialOrd的类型才有cmp_display方法
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
总结一下,trait 和 trait bound 让我们使用泛型类型参数来减少重复,并仍然能够向编译器明确指定泛型类型需要拥有哪些行为。
在动态类型语言中,如果我们尝试调用一个类型并没有实现的方法,会在运行时出现错误。Rust 将这些错误移动到了编译时,甚至在代码能够运行之前就强迫我们修复错误
生命周期
https://rustwiki.org/zh-CN/book/ch10-03-lifetime-syntax.html
生命周期的概念时Rust与众不同的地方之一,较为难以理解(需要更多例子说明),Rust每个引用都有自己的生命周期(在作用域内保持有效)。总的来说感觉是通过复杂的语法标注减少安全隐患
大多数情况下生命周期都能够隐式推断,在特定情况下需要手动标注生命周期
生命周期存在的目的是避免悬垂引用(指向已经释放的内存)
Rust借用检查器会判断引用的生命周期(作用域范围)是否小于被借用的对象,如果不小于说明对象已经释放但是借用仍然存在,出现悬垂引用。
let r: &i32;
{
let x = 5;
r = &x;
} // r的生命周期大于x,出现悬垂引用
println!("r: {}", r);
更复杂的例子例如,函数返回参数借用,但是不确定返回x和y,x和y的生命周期不一定是相同的,所以无法推断需要手动标注
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
生命周期标注并不会改变引用的生命周期,只是描述多个引用之间的生命关系
// 泛型生命周期
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
// 表示参数和返回值的生命周期一致
// 泛型中的'a, 表明任何标注了'a的引用,其生命周期都不能短于'a
// 任何不满足这个约束条件的值都将被借用检查器拒绝
// 借用检查器并不知道具体引用的生命周期,只是检查是否符合约束条件
// 整个的检查都是在编译阶段完成的
if x.len() > y.len() {
x
} else {
y
}
}
对于以下示例,尽管string1的生命周期满足result的要求,但是string2的生命周期在打印result之前就已经结束,由于生命周期会取两者重叠的部分(较小值)作为返回引用的生命周期,因此借用检查器不允许编译通过,显示错误string2 does not live long enough,borrowed value does not live long enough
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {}", result);
}
因此,逻辑上只对x参数进行标注即可,但是由于y同样是返回引用,因此编译器需要标注生命周期,编译器报错^ lifetime 'a required。修改为以下可以通过编译
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}
对于结构提来说,引用可以是成员,为了避免悬垂需要保证成员的生命周期不小于结构体本身
struct ImportantExcerpt<'a> {
part: &'a str,
}
生命周期省略的规则在一定程度上减轻了编码者的心智负担。例如对于方法定义来说,self参数的生命周期会自动赋给所有输出参数的生命周期。规则如下
- 每一个是引用的参数都有它自己的生命周期参数
- 如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数
- 如果方法有多个输入生命周期参数并且其中一个参数是
&self或&mut self,那么所有输出生命周期参数被赋予self的生命周期
静态生命周期('static)是一个特殊的生命周期,在程序的持续时间内都有效,例如字符串生命值,但是这个要慎用
下面有一个综合泛型,trait和生命周期的例子
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str
where T: Display
{
println!("Announcement! {}", ann);
if x.len() > y.len() {
x
} else {
y
}
}
最终总结就是
- 返回的引用必须和某个参数的生命周期匹配
- 生命周期标注不影响生命周期,只是静态的检查
- 函数生命周期的目的在于描述参数和返回值之间的关系,一旦有联系那么必须通过明确标注的方式进行描述
- 结构体引用成员的生命周期不小于结构体实例本身
可见为了避免悬垂引用的问题,编译器将压力给到了编码者,尽管有生命周期省略的规则,但是负担仍旧很重
单元测试
测试函数的三个操作
- 准备数据
- 运行被测试的代码
- 断言结果
Rust 中的测试就是一个带有 test 属性标注的函数。属性(attribute)是关于 Rust 代码片段的元数据
使用assert!宏,可以额外指定自定义信息
assert!
assert_eq! // 失败时自动使用debug格式打印参数,要求参数实现了PartialEq和Debug trait
assert_ne!
示例如下
pub fn add_tow(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use crate::add_tow;
#[test]
fn if_add_twos() {
assert_eq!(4, add_tow(2));
}
#[test]
fn if_add_twos_info() {
let result = add_tow(2);
// assert!(5 == result,"failed to add two for 3, get wrong value {}",result);
assert_eq!(5,result,"failed to add two for 3, get wrong value {}",result);
}
}
测试代码预期的panic行为
#[test]
#[should_panic]
// #[should_panic(exepcted = "should include this txt")] // 检测发生panic具体的panic内容匹配
fn test_panic() {
panic!("shoule panic");
// panic!("should include this txt");
}
在测试中,也可以通过返回Result枚举的方式作为返回类型编写测试
- 返回OK,测试通过
- 返回Err,测试失败
#[test]
fn test_result() -> Result<(),String>{
if 1 == 1 {
Ok(())
} else {
Err(String::from("error info"))
}
}
控制测试的运行逻辑
cargo test会构建一个Test Runner的可执行文件,逐个运行测试函数并报告结果
Cargo测试的默认行为
- 并行测试
- 执行所有测试
- 捕获(不显示)所有输出
cargo test -- --test_threads=1 // 并行测试的线程数
cargo test -- --show-output // 默认通过的测试不会打印pringln!宏的内容
cargo test
运行忽略的测试
cargo test -- --ignored // 执行被忽略标记的测试
// lib.rs
#[test]
#[ignore] // 忽略耗时测试
fn test_panic() {
panic!("shoule panic");
// panic!("should include this txt");
}
#[cfg(test)] 单元测试标注测试mod,只有执行test操作才会编译此部分
测试模块的
#[cfg(test)]标注告诉 Rust 只在执行cargo test时才编译和运行测试代码,而在运行cargo build时不这么做
Rust允许测试私有函数,未导出
对于集成测试,在项目根目录下创建test文件夹,每个文件都被视作单独的crate
可以创建common文件夹作为集成测试的公用逻辑,不在测试范围内
注意:
- 如果是binary create ,则不能在 tests 目录下创建集成测试,无法把main.rs导入作用域
- 只有 library crate 才能暴露函数给其他crate用
最后,总结下,Rust将程序安全相关的问题从运行时提前到了编译期间,迫使开发者思考程序中可能存在的不安全因素
- 默认不可变即只读的变量,写需要单独声明
- 尽可能避免无效,未定义内存的使用
- 尽可能避免数据争夺和未定义行为(悬垂指针,空指针)
- 主动触发panic(可恢复错误),避免缓冲区溢出(例如索引越界)