文章全文首发:码农的科研笔记(公众号)
RecBole是由AI Box团队开发的基于Pytorch的推荐系统算法库。该框架从数据处理、模型开发和算法训练都有涉及,能方便进行算法构建和实验对比。
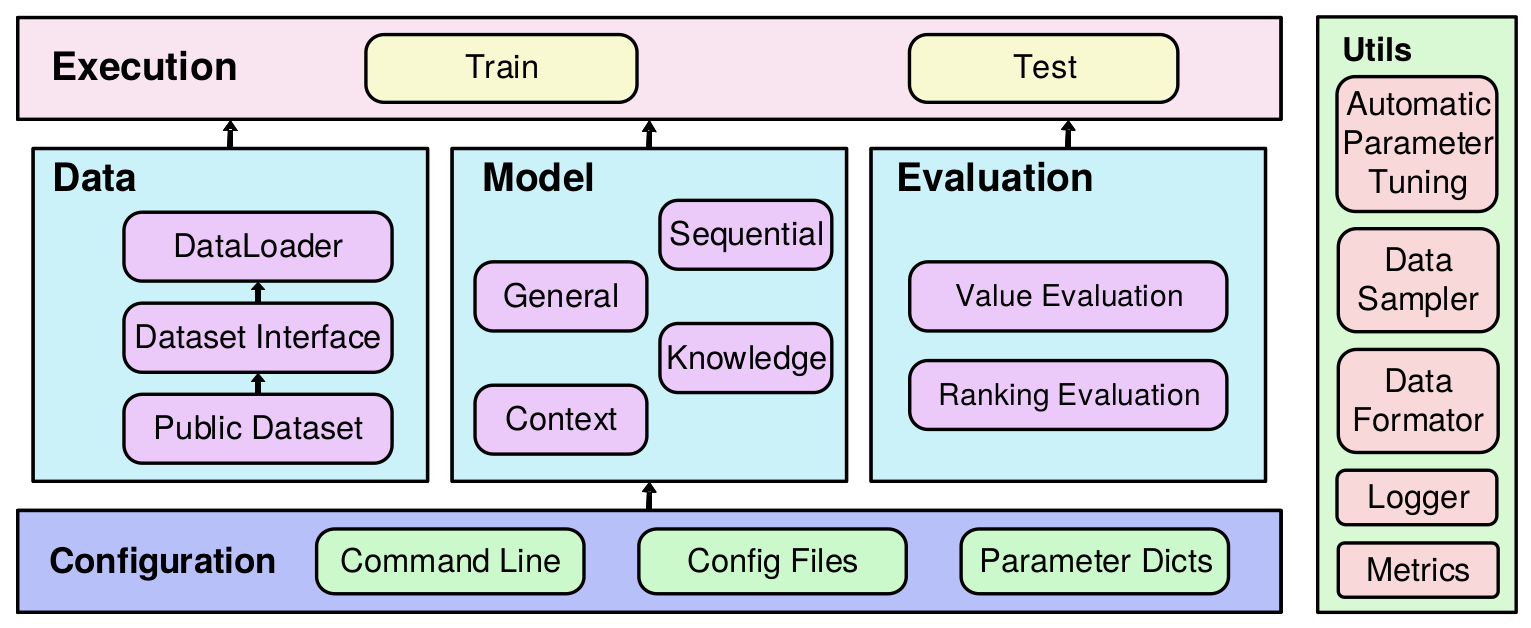
数据组织形式
RecBole约定了一个统一、易用的数据文件格式,并已支持 28 个 benchmark dataset。同时可以选择使用数据集预处理脚本,或直接下载已被处理好的数据集文件。recbole有一个默认的数据集 ml-100k 存在目录 ./RecBole/dataset/ml-100k中,官方doc给出的所有例子都是直接加载的这个数据集。
ml-100k.item:item_id:token movie_title:token_seq release_year:token class:token_seq
例如: 1 Toy Story 1995 Animation Children's Comedy
ml-100k.user: user_id:token age:token gender:token occupation:token zip_code:token
例如: 1 24 M technician 85711
ml-100k.inter: user_id:token item_id:token rating:float timestamp:float
例如: 196 242 3 881250949
RecBole典型数据文件如下,其中针对不同类型推荐算法所需数据文件会有所不同。
| 后缀 | 含义 | 例子 |
|---|---|---|
| .inter | 用户-商品交互特征 | user_id, item_id, rating, timestamp, review |
| .user | 用户特征 | user_id, age, gender |
| .item | 商品特征 | item_id, category |
| .kg | 知识图谱三元组 | head_entity, tail_entity, relation |
| .link | 知识图谱与推荐系统链接关系 | entity, item_id |
| .net | 社交网络图 | source, target |
针对使用其它数据场景,如何得到RecBole所需数据格式:
-
一种是下载数据源文件,并利用官方开源的脚本(https://github.com/RUCAIBox/RecSysDatasets)进行处理。
-
一种是直接下载官方处理好的原子文件的脚本,有两种方法,百度网盘 或者 google drive 。将已经下载好的原子文件保存在 ./RecBole/dataset 目录下。之后需要修改config。
from recbole.config import Config parameter_dict = { 'data_path': "./RecBole/dataset",#下载数据集的位置,这里只需要到dataset这一级就可以 'load_col': {'inter': ['user_id', 'product_id']}, #模型要加载的数据列,因为数据集中可能存在很多列,我们只选有需要的。 'USER_ID_FIELD': 'user_id', #写入user和item的id对应在数据集中的header 'ITEM_ID_FIELD': 'product_id' } config = Config(model="LightGCN", dataset='steam',config_dict=parameter_dict) # 初始化config,系统会调用default的config,并且利用自己定义的config_dict对default中相应的参数进行修改
Recbole—加载新的数据集Recbole—加载新的数据集
原子文件是 RecBole 约定的一类通用的数据格式,支持灵活的数据输入。
认识RecBole
【模型】
RecBole 包含百余种经典推荐模型,同时包括八个基准工具包: 通用推荐、 序列推荐、 基于内容的推荐、 基于知识的推荐、 元学习、 数据增强、 去偏、 公平性、 跨域推荐、 基于Transformer的模型、 基于图神经网络的模型 和人岗匹配模型。
【Evaluation Settings】
一般包括评价指标包括: metrics: ["Recall", "MRR","NDCG","Hit","Precision"]
【调参】
打开RecBole/hyper.test 然后设置一系列你想要调整的超参数进行自动搜索。下面有两种方式来进行超参搜索:
- loguniform:参数会遵循均匀分布随机选取。
- choice: 参数会从所设置的列表中选择每个离散值进行搜索。
下面是一个hyper.test的例子
learning_rate loguniform -8, 0
embedding_size choice [64, 96 , 128]
train_batch_size choice [512, 1024, 2048]
mlp_hidden_size choice ['[64, 64, 64]','[128, 128]']
然后在命令行中运行:
python run_hyper.py --model=[model_name] --dataset=[data_name] --config_files=xxxx.yaml --params_file=hyper.test
e.g.
python run_hyper.py --model=BPR --dataset=ml-100k --config_files=test.yaml --params_file=hyper.test
同时官方给出了模型相应在数据上的最优超参数:https://recbole.io/hyperparameters/index.html
安装和使用demo
安装:可以使用pip安装 pip install recbole ,也可以下载源文件安装依赖包并进行运行,记住针对其它模型(例如基于RecBole的图网络推荐系统)则需要先安装recbole库进行支持。
使用demo:直接运行**run_recbole.py这个文件,默认使用的模型是BPR**,默认使用的数据集是ml-100k。
模型运行流程
RecBole小白入门系列博客总览(保持更新)RecBole小白入门系列博客总览(保持更新)
主要包括四类模型的运行流程——General, Context, Sequential 和Knowledge。例如General模型中 Pop 和 ItemKNN 等。模型默认参数在源码目录RecBole/recbole/properties/model 中
【可能需要设定的文件】
-
模型默认参数:
RecBole/recbole/properties/model -
数据集默认参数:
RecBole/recbole/properties/dataset
【Knowledge类模型运行流程】
-
例如选定Knowledge类的模型;
-
选定数据集:Context模型顾名思义会用到各种上下文,因此会用到的文件可能有多个 .inter、.item和**.user** 。
| 后缀 | 含义 | 例子 |
|---|---|---|
| .inter | 用户-商品交互特征 | user_id, item_id, rating, timestamp, review |
| .user | 用户特征 | user_id, age, gender |
| .item | 商品特征 | item_id, category |
Knowledge类模型会用到.kg和.link文件,这些需要根据.inter文件生成,生成方式请参照RecBole数据集生成工具。
基于GCN的推荐实例
关键词搜索:GCN、Hyper、graph
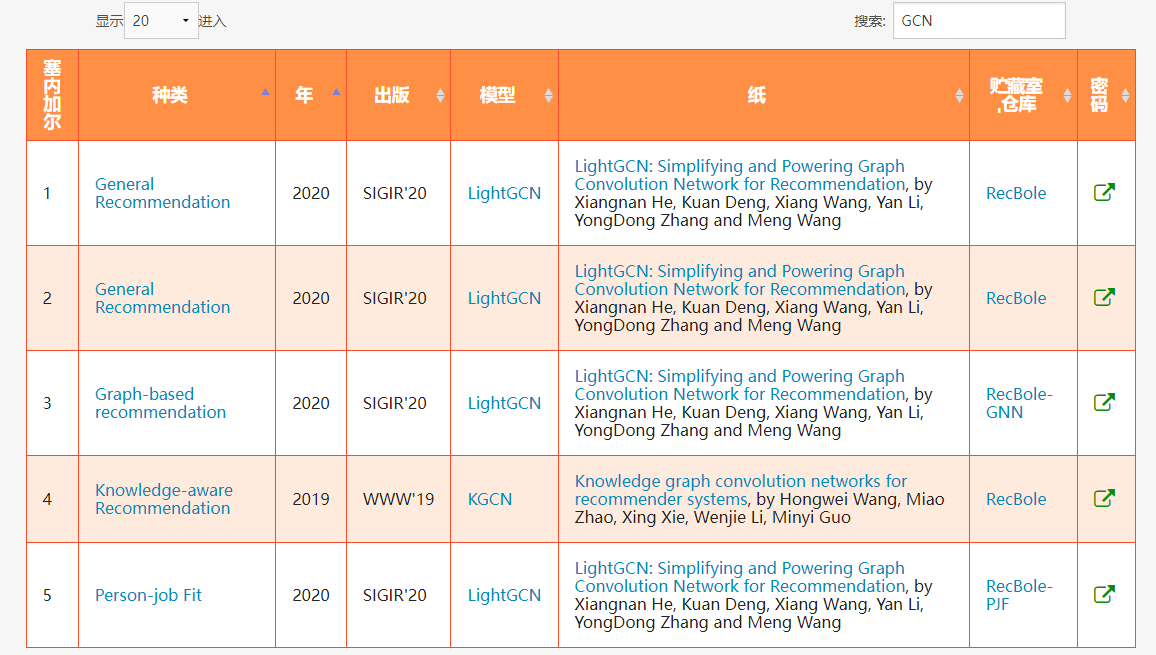
【LightGCN】
LightGCN RecBole教程
Model Hyper-Parameters:
embedding_size (int): The embedding size of users and items. Defaults to64.n_layers (int): The number of layers in LightGCN. Defaults to2.reg_weight (float): The L2 regularization weight. Defaults to1e-05.
A Running Example:
Write the following code to a python file, such as run.py
from recbole.quick_start import run_recbole
run_recbole(model='LightGCN', dataset='ml-100k')
And then:
python run.py
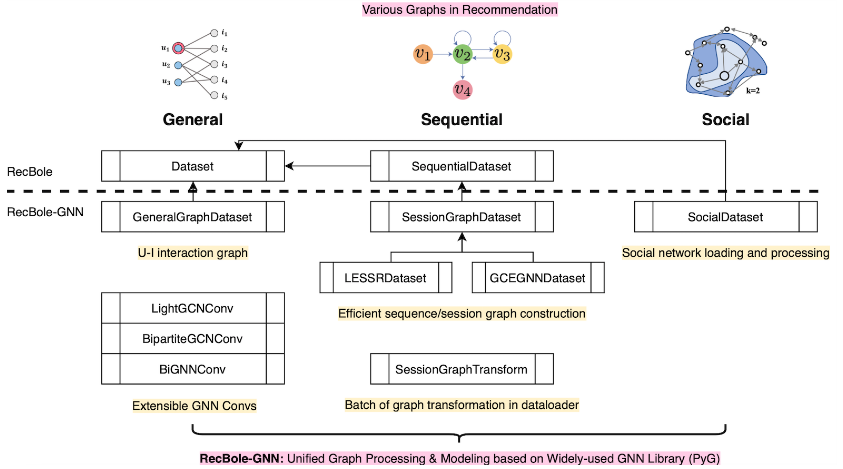
【GNN类】
需要使用RecBole-GNN这个新的工具包,但是得提前安装 recbole 包,简单使用工具包即运行 python run_recbole.py,同时 RecBole对应数据集参考 Social-Datasets。库包括涵盖三个主要类别的算法: 带有用户-项目交互图的一般推荐; 使用会话/序列图的顺序推荐; 社交网络的社交推荐。