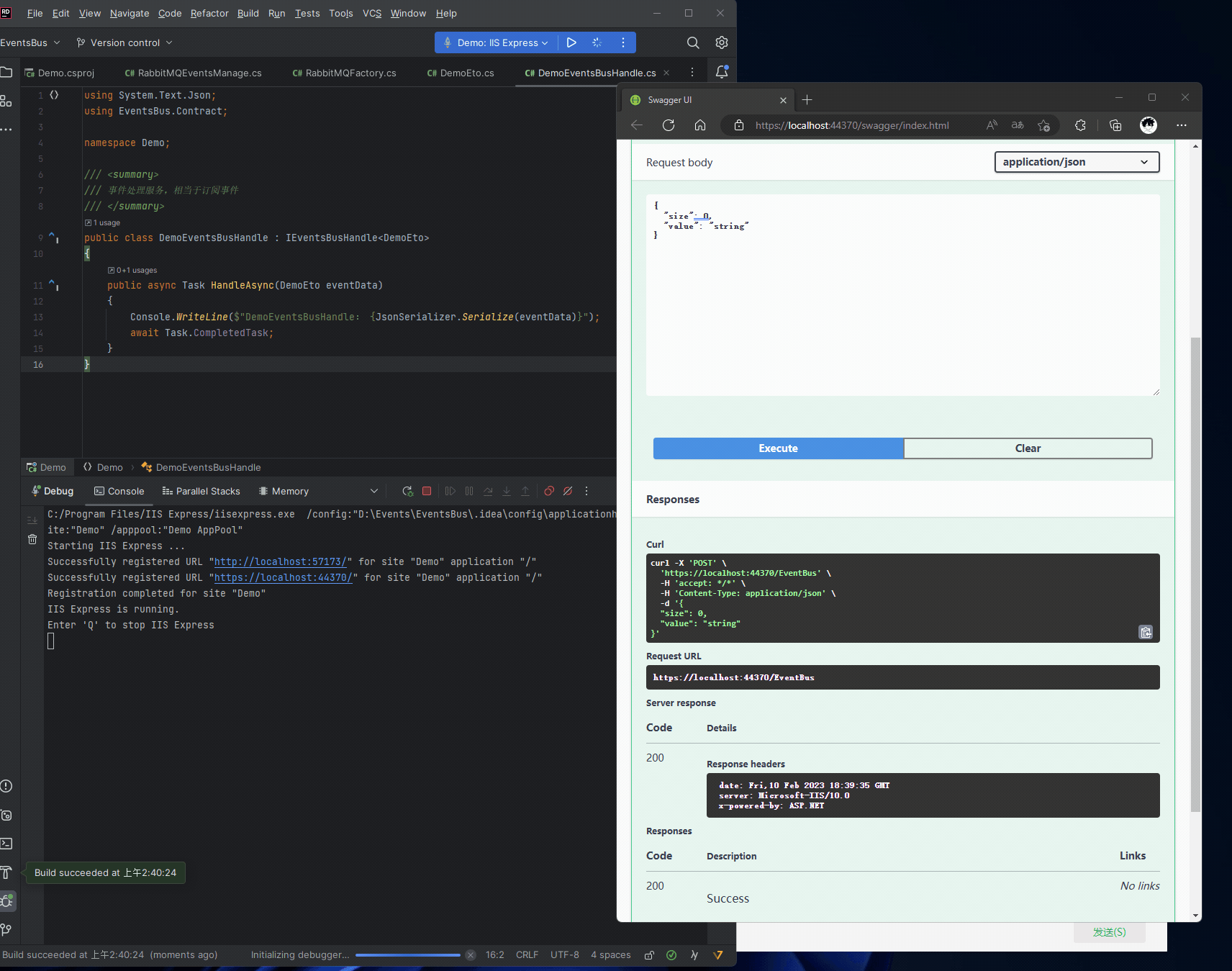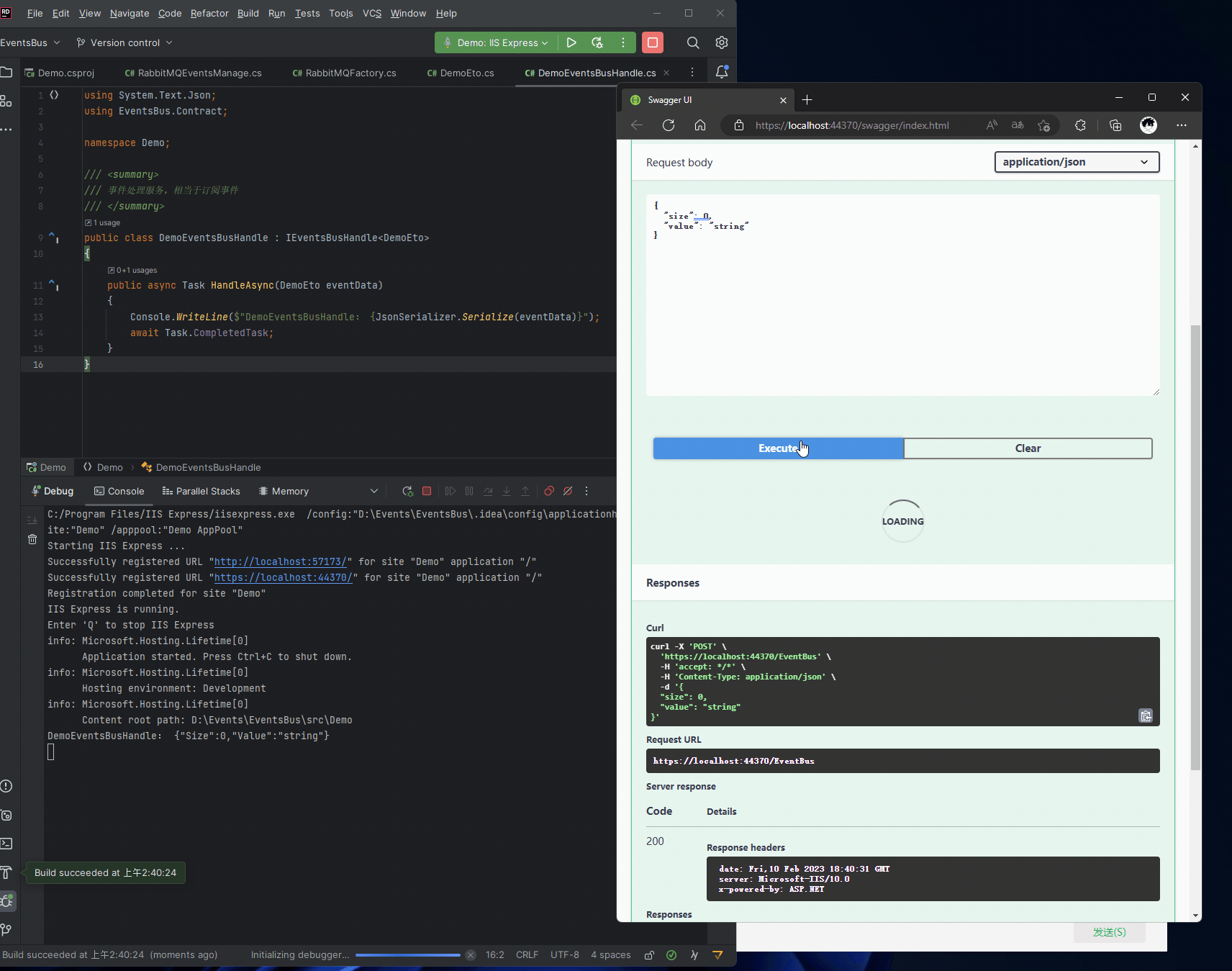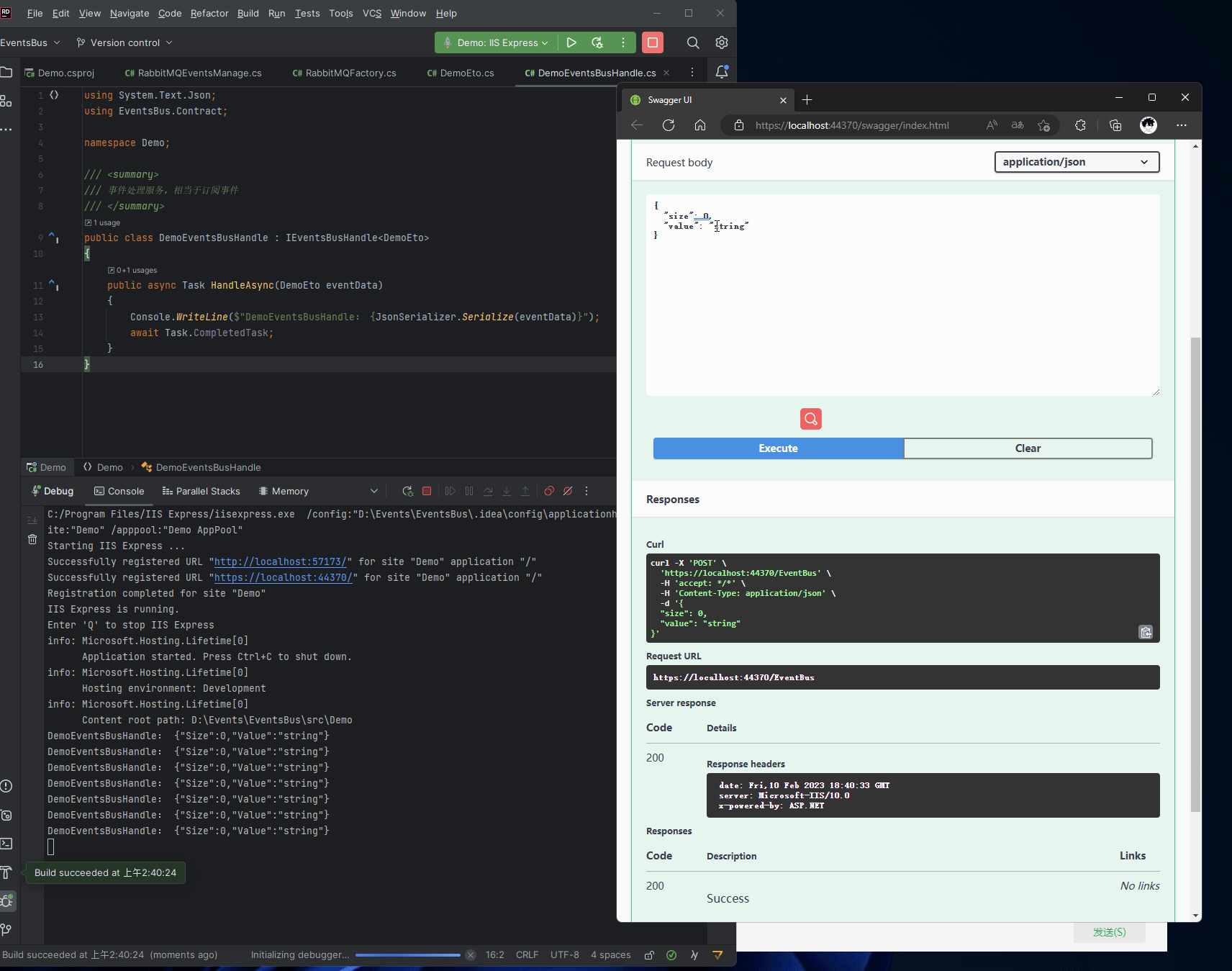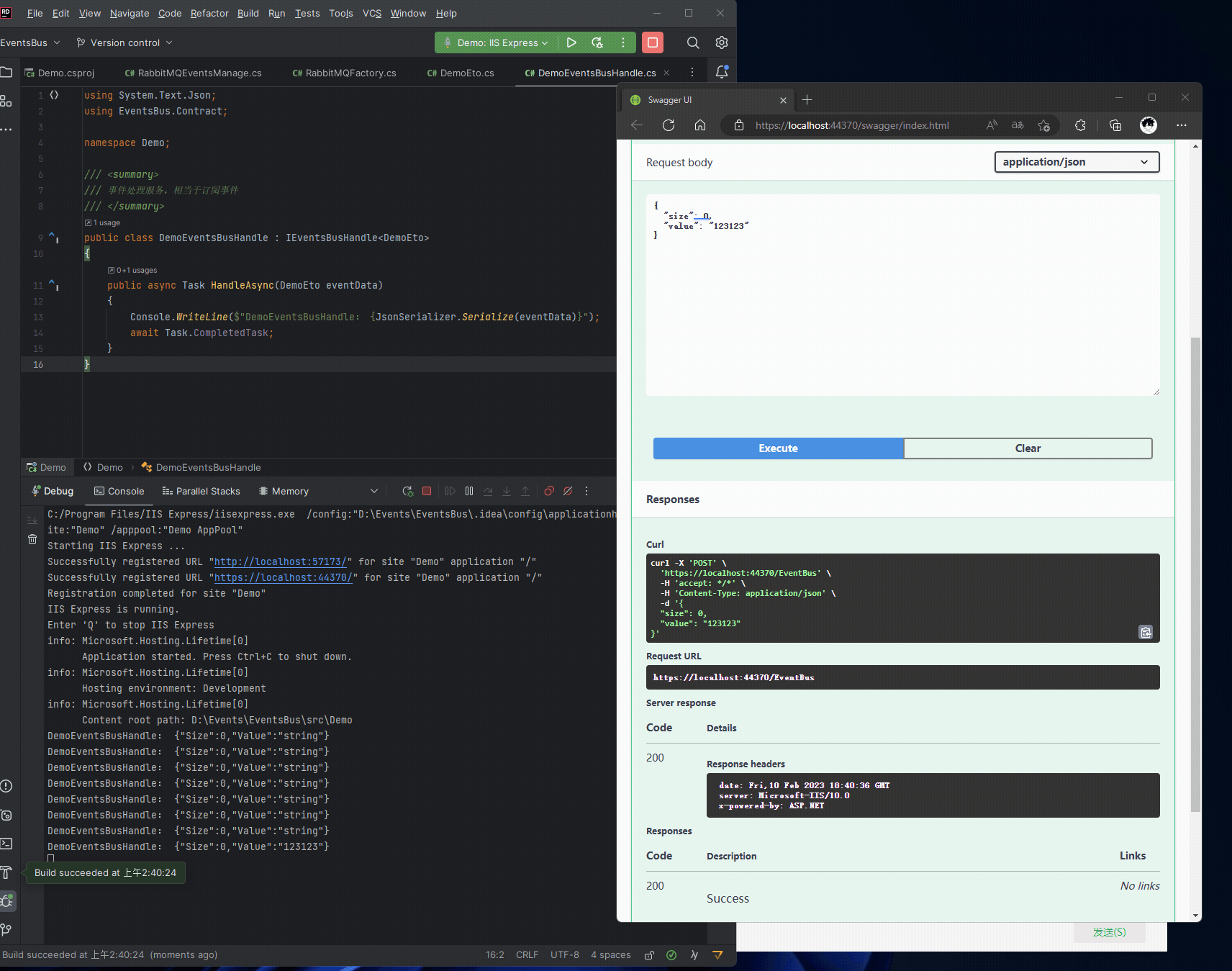
Pandas——groupby操作
文章目录
- Pandas——groupby操作
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
一、实验目的
熟练掌握pandas中的groupby操作
二、实验原理
groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False)
参数说明:
by是指分组依据(列表、字典、函数,元组,Series)
axis:是作用维度(0为行,1为列)
level:根据索引级别分组
sort:对groupby分组后新的dataframe中索引进行排序,sort=True为升序,
as_index:在groupby中使用的键是否成为新的dataframe中的索引,默认as_index=True
group_keys:在调用apply时,将group键添加到索引中以识别片段
squeeze :如果可能的话,减少返回类型的维数,否则返回一个一致的类型
grouping操作(split-apply-combine)
数据的分组&聚合 – 什么是groupby 技术?
在数据分析中,我们往往需要在将数据拆分,在每一个特定的组里进行运算。比如根据教育水平和年龄段计算某个城市的工作人口的平均收入。
pandas中的groupby提供了一个高效的数据的分组运算。
我们通过一个或者多个分类变量将数据拆分,然后分别在拆分以后的数据上进行需要的计算
我们可以把上述过程理解为三部:
1.拆分数据(split)
2.应用某个函数(apply)
3.汇总计算结果(aggregate)
下面这个演示图展示了“分拆-应用-汇总”的groupby思想
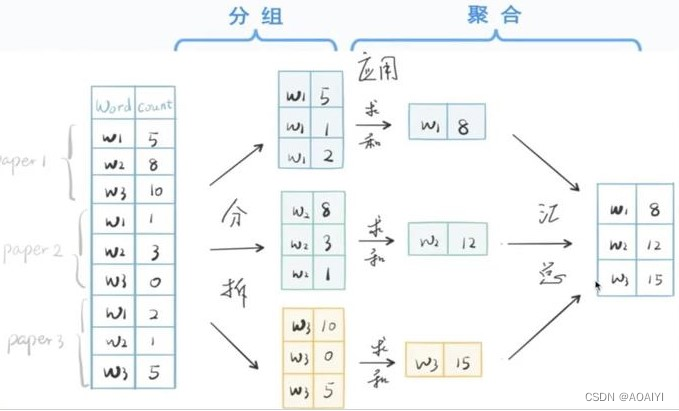
上图所示,分解步骤:
Step1 :数据分组—— groupby 方法
Step2 :数据聚合:
使用内置函数——sum / mean / max / min / count等
使用自定义函数—— agg ( aggregate ) 方法
自定义更丰富的分组运算—— apply 方法
三、实验环境
Python 3.6.1
Jupyter
四、实验内容
练习pandas中的groupby的操作案例
五、实验步骤
1.创建一个数据帧df。
import numpy as np
import pandas as pd
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
print(df)

2.通过A列对df进行分布操作。
df.groupby('A')

3.通过A、B列对df进行分组操作。
df.groupby(['A','B'])

4…使用自定义函数进行分组操作,自定义一个函数,使用groupby方法并使用自定义函数给定的条件,按列对df进行分组。
def get_letter_type(letter):
if letter.lower() in 'aeiou':
return 'vowel'
else:
return 'consonant'
grouped = df.groupby(get_letter_type, axis=1)
for group in grouped:
print(group)

5.创建一个Series名为s,使用groupby根据s的索引对s进行分组,返回分组后的新Series,对新Series进行first、last、sum操作。
lst = [1, 2, 3, 1, 2, 3]
s = pd.Series([1, 2, 3, 10, 20, 30], lst)
grouped = s.groupby(level=0)
#查看分组后的第一行数据
grouped.first()
#查看分组后的最后一行数据
grouped.last()
#对分组的各组进行求和
grouped.sum()

6.分组排序,使用groupby进行分组时,默认是按分组后索引进行升序排列,在groupby方法中加入sort=False参数,可以进行降序排列。
df2=pd.DataFrame({'X':['B','B','A','A'],'Y':[1,2,3,4]})
#按X列对df2进行分组,并求每组的和
df2.groupby(['X']).sum()
#按X列对df2进行分组,分组时不对键进行排序,并求每组的和
df2.groupby(['X'],sort=False).sum()

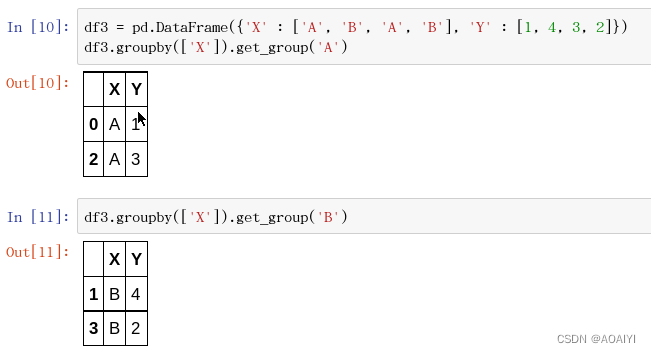
7.使用get_group方法得到分组后某组的值。
df3 = pd.DataFrame({'X' : ['A', 'B', 'A', 'B'], 'Y' : [1, 4, 3, 2]})
#按X列df3进行分组,并得到A组的df3值
df3.groupby(['X']).get_group('A')
#按X列df3进行分组,并得到B组的df3值
df3.groupby(['X']).get_group('B')
8.使用groups方法得到分组后所有组的值。
df.groupby('A').groups
df.groupby(['A','B']).groups

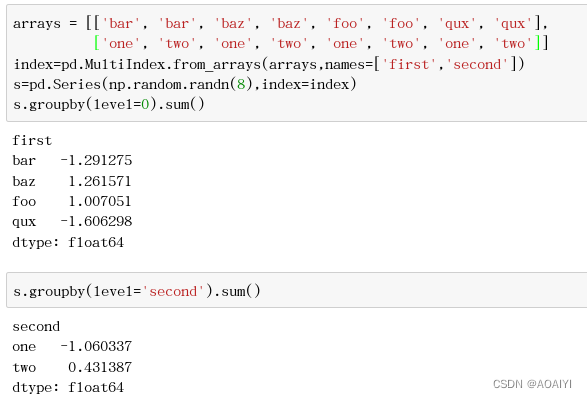
9.多级索引分组,创建一个有两级索引的Series,并使用两个方法对Series进行分组并求和。
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
index=pd.MultiIndex.from_arrays(arrays,names=['first','second'])
s=pd.Series(np.random.randn(8),index=index)
s.groupby(level=0).sum()
s.groupby(level='second').sum()
10.复合分组,对s按first、second进行分组并求和。
s.groupby(level=['first', 'second']).sum()

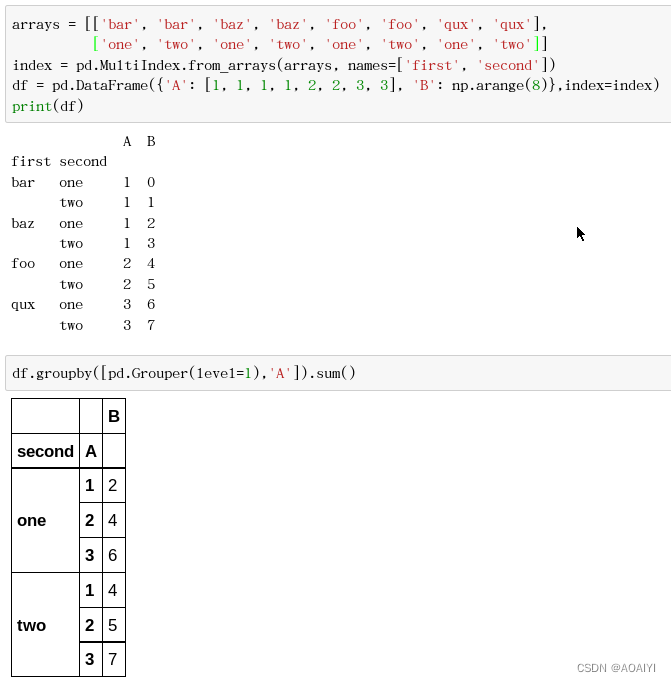
11.复合分组(按索引和列),创建数据帧df,使用索引级别和列对df进行分组。
arrays = [['bar', 'bar', 'baz', 'baz', 'foo', 'foo', 'qux', 'qux'],['one', 'two', 'one', 'two', 'one', 'two', 'one', 'two']]
index = pd.MultiIndex.from_arrays(arrays, names=['first', 'second'])
df = pd.DataFrame({'A': [1, 1, 1, 1, 2, 2, 3, 3], 'B': np.arange(8)},index=index)
print(df)
df.groupby([pd.Grouper(level=1),'A']).sum()
12.对df进行分组,将分组后C列的值赋值给grouped,统计grouped中每类的个数。
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B' : ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C' : np.random.randn(8),'D' : np.random.randn(8)})
grouped=df.groupby(['A'])
grouped_C=grouped['C']
print(grouped_C.count())

13.对上面创建的df的C列,按A列值进行分组并求和。
df['C'].groupby(df['A']).sum()

14.遍历分组结果,通过A,B两列对df进行分组,分组结果的组名为元组。
for name, group in df.groupby(['A', 'B']):
print(name)
print(group)

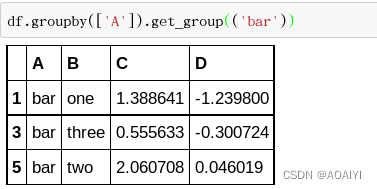
15.通过A列对df进行分组,并查看分组对象的bar列。
df.groupby(['A']).get_group(('bar'))
16.按A,B两列对df进行分组,并查看分组对象中bar、one都存在的部分。
df.groupby(['A','B']).get_group(('bar','one'))

注意:当分组按两列来分时,查看分组对象也应该包含每列的一部分。
17.聚合操作,按A列对df进行分组,使用聚合函数aggregate求每组的和。
grouped=df.groupby(['A'])
grouped.aggregate(np.sum)

按A、B两列对df进行分组,并使用聚合函数aggregate对每组求和。
grouped=df.groupby(['A','B'])
grouped.aggregate(np.sum)
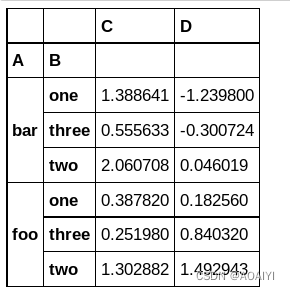
注意:通过上面的结果可以看到。聚合完成后每组都有一个组名作为新的索引,使用as_index=False可以忽略组名。
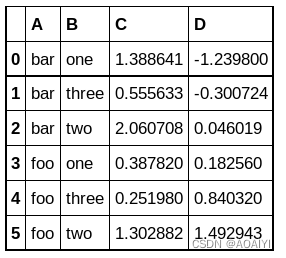
18.当as_index=True时,在groupby中使用的键将成为新的dataframe中的索引。按A、B两列对df进行分组,这是使参数as_index=False,再使用聚合函数aggregate求每组的和.
grouped=df.groupby(['A','B'],as_index=False)
grouped.aggregate(np.sum)
19.聚合操作,按A、B列对df进行分组,使用size方法,求每组的大小。返回一个Series,索引是组名,值是每组的大小。
grouped=df.groupby(['A','B'])
grouped.size()

20.聚合操作,对分组grouped进行统计描述。
grouped.describe()
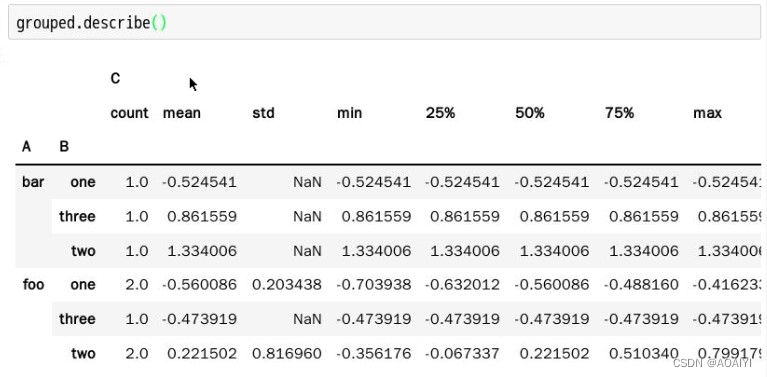
注意:聚合函数可以减少数据帧的维度,常用的聚合函数有:mean、sum、size、count、std、var、sem 、describe、first、last、nth、min、max。
执行多个函数在一个分组结果上:在分组返回的Series中我们可以通过一个聚合函数的列表或一个字典去操作series,返回一个DataFrame。