文章目录:
1.什么是原子变量类?
2.AtomicInteger(基本类型原子变量类)
3.AtomicIntegerArray(数组类型原子变量类)
4.AtomicMarkableReference(引用类型原子变量类)
5.AtomicIntegerFieldUpdater(对象Integer类型属性修改原子变量类)
6.AtomicReferenceFieldUpdater(对象引用类型属性修改原子变量类)
7.LongAdder、LongAccumulator(原子变量增强类)
8.浅谈LongAdder为什么这么快?
1.什么是原子变量类?
我们参照jdk的软件包,可以看到就是在 java.util.concurrent.atomic 包下。
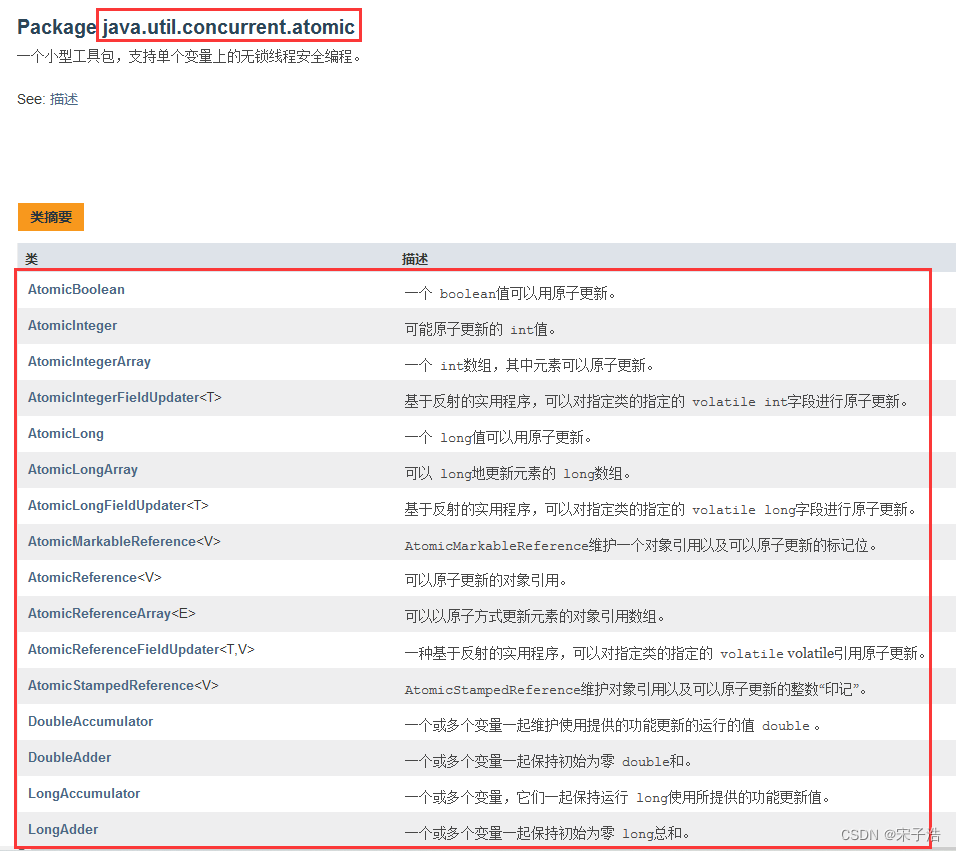
一共16个原子变量类,下面我来通过一些Demo简单介绍一下它们的用法。
2.AtomicInteger(基本类型原子变量类)
AtomicInteger 和 AtomicLong 以及 AtomicBoolean 都是一个类别的,都是操作单个数据,只是类型不一样(int、long、布尔)。
所以我就以AtomicInteger举例。
package com.juc.atomic;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
class MyNumber {
AtomicInteger atomicInteger = new AtomicInteger();
public void addPlusPlus() {
atomicInteger.getAndIncrement();
}
}
public class AtomicIntegerDemo {
public static final int SIZE = 50;
public static void main(String[] args) throws InterruptedException {
MyNumber number = new MyNumber();
CountDownLatch cdl = new CountDownLatch(SIZE); //计数器
for (int i = 0; i < SIZE; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 1000; j++) {
number.addPlusPlus(); //50个线程,每个线程执行1000次number++自增操作
}
} finally {
cdl.countDown(); //每执行完一个线程,计数器减一
}
}, String.valueOf(i)).start();
}
cdl.await(); //这里阻塞等待,直到50个线程全部执行完,计数器清零,程序才会继续向下执行
System.out.println(Thread.currentThread().getName() + " result: " + number.atomicInteger.get());
}
}
3.AtomicIntegerArray(数组类型原子变量类)
AtomicIntegerArray 和 AtomicLongArray 以及 AtomicReferenceArray 都是一个类别的,都是操作数组类型数据,只是数组的类型不一样(int、long、引用类型)。
所以我就以 AtomicIntegerArray 举例。
package com.juc.atomic;
import java.util.concurrent.atomic.AtomicIntegerArray;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
public class AtomicIntegerArrayDemo {
public static void main(String[] args) {
AtomicIntegerArray array = new AtomicIntegerArray(new int[5]); //0 0 0 0 0
// AtomicIntegerArray array = new AtomicIntegerArray(5); //0 0 0 0 0
// AtomicIntegerArray array = new AtomicIntegerArray(new int[]{1, 2, 3, 4, 5}); //1 2 3 4 5
for (int i = 0; i < array.length(); i++) {
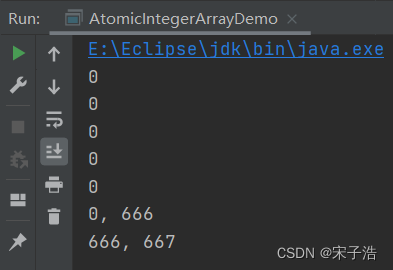
System.out.println(array.get(i)); //0 0 0 0 0
}
int ans = 0;
ans = array.getAndSet(0, 666); //先get,后set
System.out.println(ans + ", " + array.get(0));
ans = array.getAndIncrement(0); //先get,后自增(i++)
System.out.println(ans + ", " + array.get(0));
}
}
4.AtomicMarkableReference(引用类型原子变量类)
AtomicReference:可以带泛型,更新引用类型。
AtomicStampedReference:携带版本号的引用类型原子类,解决修改过几次的问题,可以解决ABA问题。关于这个原子变量类的Demo可以参考我的这篇文章:CAS解决ABA问题
AtomicMarkableReference:类似于AtomicStampedReference,原子更新带有标记位的引用类型对象,只是不采用版本号记录,而是采用标记位true、false。
来看下面关于AtomicMarkableReference的Demo。
package com.juc.atomic;
import java.util.concurrent.atomic.AtomicMarkableReference;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
public class AtomicMarkableReferenceDemo {
static AtomicMarkableReference markableReference = new AtomicMarkableReference(100, false);
public static void main(String[] args) {
new Thread(() -> {
boolean marked = markableReference.isMarked(); //false
System.out.println(Thread.currentThread().getName() + " 默认标识:" + marked);
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
//1秒之后,t1线程读取值是100,和预期一样,首先将marked由false改为取反之后的值,也即true
markableReference.compareAndSet(100, 1000, marked, !marked);
}, "t1").start();
new Thread(() -> {
boolean marked = markableReference.isMarked(); //false
System.out.println(Thread.currentThread().getName() + " 默认标识:" + marked);
try {
Thread.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
//2秒之后,t2再次读取,值已经被改为了1000,marked也被改为了true,所以此次cas失败
boolean flag = markableReference.compareAndSet(100, 2000, marked, !marked);
System.out.println(Thread.currentThread().getName() + " cas-result:" + flag); //cas失败,所以是false
System.out.println(Thread.currentThread().getName() + " " + markableReference.isMarked()); //marked已被t1线程改为true
System.out.println(Thread.currentThread().getName() + " " + markableReference.getReference()); //变量值已被t1线程改为1000
}, "t2").start();
}
}

5.AtomicIntegerFieldUpdater(对象Integer类型属性修改原子变量类)
AtomicIntegerFieldUpdater:原子更新对象中Integer类型字段的值,该字段必须以 volatile int 修饰。
AtomicLongFieldUpdater:原子更新对象中Long类型字段的值,该字段必须以 volatile long 修饰。
AtomicReferenceFieldUpdater:原子更新引用类型字段的值,该字段必须以 volatile T 修饰。(T是引用类型的泛型值)
因为对象的属性修改类型原子类都是抽象类*,所以每次使用都必须使用静态方法
newUpdater()创建一个更新器*,并且需要设置想要更新的类和属性。
下面先看 AtomicIntegerFieldUpdater 的Demo。
package com.juc.atomic;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
class BankAccount {
public String bankName = "CCB";
public volatile int money = 0;
AtomicIntegerFieldUpdater<BankAccount> fieldUpdater =
AtomicIntegerFieldUpdater.newUpdater(BankAccount.class, "money");
public void addMoney(BankAccount bankAccount) {
fieldUpdater.getAndIncrement(bankAccount);
}
}
public class AtomicIntegerFieldUpdateDemo {
public static void main(String[] args) throws InterruptedException {
BankAccount bankAccount = new BankAccount();
CountDownLatch cdl = new CountDownLatch(10); //计数器
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 1000; j++) {
bankAccount.addMoney(bankAccount); //10个线程,每个线程对money执行1000次自增操作
}
} finally {
cdl.countDown(); //每执行完一个线程,计数器减一
}
}, String.valueOf(i)).start();
}
cdl.await(); //阻塞等待,直到10个线程全部执行完,计数器清零,程序继续向下执行
System.out.println(Thread.currentThread().getName() + " result: " + bankAccount.money);
}
}

6.AtomicReferenceFieldUpdater(对象引用类型属性修改原子变量类)
上面介绍了AtomicIntegerFieldUpdater针对Integer类型的属性进行修改。
下面来看 AtomicReferenceFieldUpdater 如何针对引用类型的属性进行修改。
package com.juc.atomic;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
class Resource {
public volatile Boolean isInit = Boolean.FALSE;
AtomicReferenceFieldUpdater<Resource, Boolean> fieldUpdater
= AtomicReferenceFieldUpdater.newUpdater(Resource.class, Boolean.class, "isInit");
public void init(Resource resource) {
//cas操作,同一时刻只会有一个线程cas成功,其他线程cas失败或者自旋等待
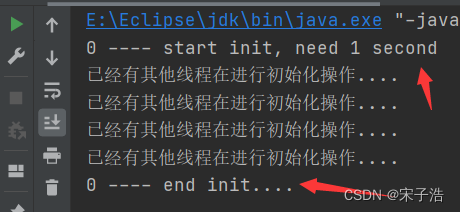
if (fieldUpdater.compareAndSet(resource, Boolean.FALSE, Boolean.TRUE)) {
System.out.println(Thread.currentThread().getName() + " ---- start init, need 1 second");
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " ---- end init....");
} else {
System.out.println("已经有其他线程在进行初始化操作....");
}
}
}
public class AtomicReferenceFieldUpdateDemo {
public static void main(String[] args) {
Resource resource = new Resource();
for (int i = 0; i < 5; i++) {
new Thread(() -> {
resource.init(resource); //5个线程并发去修改资源类中的引用类型属性
}, String.valueOf(i)).start();
}
}
}
由于以上两个案例都是针对某个类中的某个属性进行原子修改,而且这些属性都采用 volatile 修饰,小提一嘴:
面试官问你:你在哪里用了volatile?
- 在AtomicReferenceFieldUpdater中,因为是规定好的必须由volatile修饰的。
- 单例模式的DCL写法中,采用volatile保证单例在多线程之间的可见性。
7.LongAdder、LongAccumulator(原子变量增强类)
首先,我们来看在阿里巴巴Java开发手册中有这样一个参考内容。他说的是 LongAdder 要比传统的 AtomicLong 的性能更好,同时也会减少乐观锁的重试次数(这个很关键,因为我们都知道原子变量类的底层实现都是CAS,而CAS就是基于乐观锁机制做的)。

下面我们先看一下简单的案例。
package com.juc.atomic;
import java.util.concurrent.atomic.LongAccumulator;
import java.util.concurrent.atomic.LongAdder;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
public class LongAdderDemo {
public static void main(String[] args) {
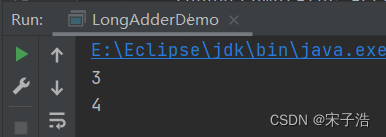
LongAdder longAdder = new LongAdder(); //0
longAdder.increment();
longAdder.increment();
longAdder.increment(); //3
System.out.println(longAdder.sum());
LongAccumulator longAccumulator = new LongAccumulator((x, y) -> x + y, 0);
longAccumulator.accumulate(1); //此时x=0,y=1,求和结果是1
longAccumulator.accumulate(3); //此时x=1,y=3,求和结果是4
System.out.println(longAccumulator.get()); //4
}
}
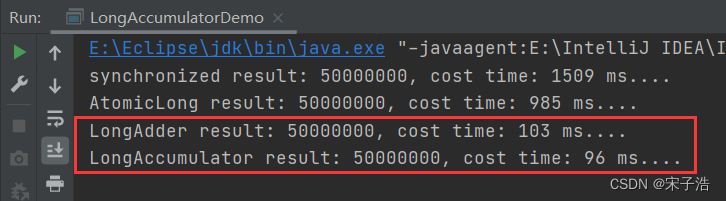
上面的案例就不多说了,主要来看一下下面关于 synchronized、AtomicLong、LongAdder、LongAccumulator 在多线程并发情况下的性能对比(一目了然)。
模拟的是一个点赞器功能,50个线程,每个线程点赞100万次,最终数据一定是五千万。
package com.juc.atomic;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAccumulator;
import java.util.concurrent.atomic.LongAdder;
/**
* @author: SongZiHao
* @date: 2023/2/11
*/
class ClickNumber {
int number = 0;
public synchronized void addBySynchronized() {
number++;
}
AtomicLong atomicLong = new AtomicLong(0);
public void addByAtomicLong() {
atomicLong.getAndIncrement();
}
LongAdder longAdder = new LongAdder();
public void addByLongAdder() {
longAdder.increment();
}
LongAccumulator longAccumulator = new LongAccumulator((x, y) -> x + y, 0);
public void addByLongAccumulator() {
longAccumulator.accumulate(1);
}
}
public class LongAccumulatorDemo {
public static final int CLICK_NUMBER = 1000000;
public static final int THREAD_NUMBER = 50;
public static void main(String[] args) throws InterruptedException {
ClickNumber clickNumber = new ClickNumber();
long startTime;
long endTime;
CountDownLatch cdl1 = new CountDownLatch(THREAD_NUMBER);
CountDownLatch cdl2 = new CountDownLatch(THREAD_NUMBER);
CountDownLatch cdl3 = new CountDownLatch(THREAD_NUMBER);
CountDownLatch cdl4 = new CountDownLatch(THREAD_NUMBER);
//synchronized
startTime = System.currentTimeMillis();
for (int i = 0; i < THREAD_NUMBER; i++) {
new Thread(() -> {
try {
for (int j = 0; j < CLICK_NUMBER; j++) {
clickNumber.addBySynchronized();
}
} finally {
cdl1.countDown();
}
}, String.valueOf(i)).start();
}
cdl1.await();
endTime = System.currentTimeMillis();
System.out.println("synchronized result: " + clickNumber.number + ", cost time: " + (endTime - startTime) + " ms....");
//AtomicLong
startTime = System.currentTimeMillis();
for (int i = 0; i < THREAD_NUMBER; i++) {
new Thread(() -> {
try {
for (int j = 0; j < CLICK_NUMBER; j++) {
clickNumber.addByAtomicLong();
}
} finally {
cdl2.countDown();
}
}, String.valueOf(i)).start();
}
cdl2.await();
endTime = System.currentTimeMillis();
System.out.println("AtomicLong result: " + clickNumber.atomicLong.get() + ", cost time: " + (endTime - startTime) + " ms....");
//LongAdder
startTime = System.currentTimeMillis();
for (int i = 0; i < THREAD_NUMBER; i++) {
new Thread(() -> {
try {
for (int j = 0; j < CLICK_NUMBER; j++) {
clickNumber.addByLongAdder();
}
} finally {
cdl3.countDown();
}
}, String.valueOf(i)).start();
}
cdl3.await();
endTime = System.currentTimeMillis();
System.out.println("LongAdder result: " + clickNumber.longAdder.sum() + ", cost time: " + (endTime - startTime) + " ms....");
//LongAccumulator
startTime = System.currentTimeMillis();
for (int i = 0; i < THREAD_NUMBER; i++) {
new Thread(() -> {
try {
for (int j = 0; j < CLICK_NUMBER; j++) {
clickNumber.addByLongAccumulator();
}
} finally {
cdl4.countDown();
}
}, String.valueOf(i)).start();
}
cdl4.await();
endTime = System.currentTimeMillis();
System.out.println("LongAccumulator result: " + clickNumber.longAccumulator.get() + ", cost time: " + (endTime - startTime) + " ms....");
}
}
从结果中可以看到, 内部锁synchronized是最耗时的,因为它的锁粒度比较粗,不再多说了。AtomicLong基于CAS乐观锁,性能要好一些。而两个原子变量增强类的性能可以说在AtomicLong基础上提升了将近10倍,这如果是在高并发的场景下就很恐怖了。。。
8.浅谈LongAdder为什么这么快?
我们浅谈一下LongAdder在大并发的情况下,性能为什么这么快?
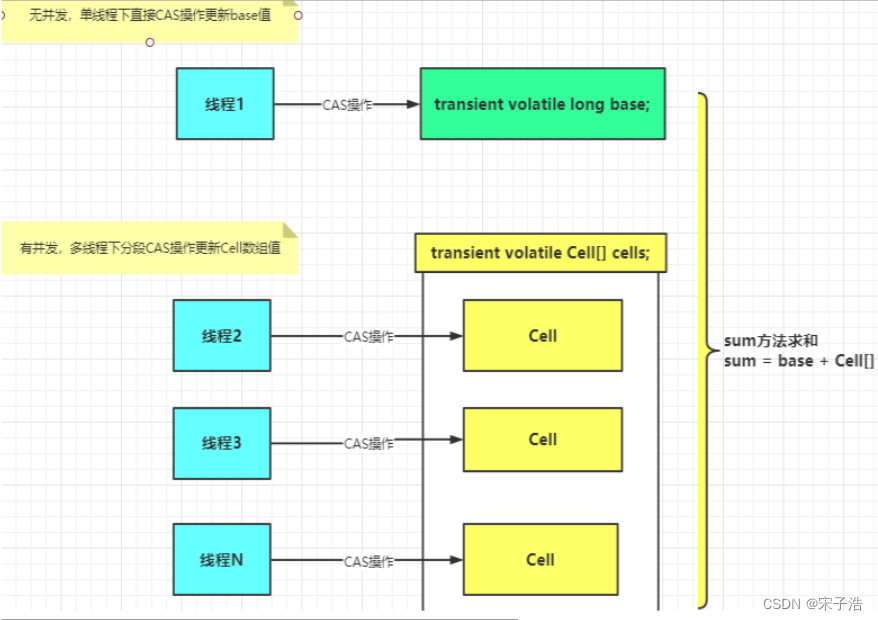
其实在小并发下情况差不多;但在高并发情况下,在AtomicLong中,等待的线程会不停的自旋,导致效率比较低;而LongAdder用cell[]分了几个块出来,最后统计总的结果值(base+所有的cell值),分散热点。
- 内部有一个base变量,一个Cell[]数组。
- base变量:非竞态条件下,直接累加到该变量上。
- Cell[]数组:竞态条件下,累加各个线程自己的槽Cell[i]中。
举个形象的例子,火车站买火车票,AtomicLong 只要一个窗口,其他人都在排队;而LongAdder 利用cell开了多个卖票窗口,所以效率高了很多。

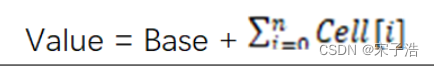
LongAdder的基本思路就是分散热点 ,将value值分散到一个Cell数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
sum()会将所有Cell数组中的value和base累加作为返回值,核心的思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点 。