如果我们是在Linux下开发,那Makefile肯定要知道,不懂Makefile,面对较大的工程项目的时候就会比较麻烦,懂得利用开发工具将会大大提高我们的开发效率,也可以说Makefile是必须掌握的一项技能。
一、了解什么是 Makefile
一个大型工程中的源文件不计其数,各个功能或者模块分别放在不同的目录下,手动敲命令去编译就带来很大的麻烦,那么Makefile可以定义一系列的编译规则,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至进行更复杂的功能操作,Makefile带来的好处就是——“自动化编译 ”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高软件开发的效率。
make ** 是一个命令工具,是一个解释Makefile中指令的命令工具,一般来说,大多数的IDE都有这个命令,比如:Linux下GNU的make、Visual C++的nmake、Delphi的make。可见,Makefile都成为了一种在工程方面的编译方法。当然,不同产商的make各不相同,也有不同的语法,但其本质都是在 “文件依赖性” 上做文章** 。
二、明白编译链接过程
在编写Makefile之前,还是要先了解清楚程序编译链接过程,无论是c、c++,首先要把源文件编译成中间代码文件,在Windows下也就是 .obj 文件,Unix/Linux下是 .o 文件,即 Object File,这个动作叫做编译(compile)。然后再把大量的Object File合成执行文件,这个动作叫作链接(link)。
编译时,编译器需要的是语法的正确,函数与变量的声明的正确。对于后者,通常是你需要告诉编译器头文件的所在位置(头文件中应该只是声明,而定义应该放在C/C++文件中),只要所有的语法正确,编译器就可以编译出中间目标文件。一般来说,每个源文件都应该对应于一个中间目标文件(O文件或是OBJ文件)。
链接时,主要是链接函数和全局变量,所以,我们可以使用这些中间目标文件(O文件或是OBJ文件)来链接我们的应用程序。链接器并不管函数所在的源文件,只管函数的中间目标文件(Object File),在大多数时候,由于源文件太多,编译生成的中间目标文件太多,而在链接时需要明显地指出中间目标文件名,这对于编译很不方便,所以,我们要给中间目标文件打个包,在Windows下这种包叫“库文件”(Library File),也就是 .lib 文件,在Unix/Linux下是Archive File,也就是 .a 文件,也叫静态库文件。
总结一下,编译链接的过程如下:
源文件首先会生成中间目标文件,再由中间目标文件生成执行文件。
在编译时,编译器只检测程序语法,和函数、变量是否被声明。如果函数未被声明,编译器会给出一个警告,但可以生成Object File。
在链接程序时,链接器会在所有的Object File中找寻函数的实现,如果找不到,那就会报链接错误码(Linker Error),在VC下,这种错误一般是:Link 2001错误,意思是说,链接器未能找到函数的实现。你需要指定函数的Object File。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
三、编写一个简单的 Makefile
1. Makefile 的基本语法规则:
目标 ... : 依赖 ...
实现目标的具体表达式(命令)
...
...- 目标 (target):就是一个目标文件,可以是Object 文件,也可以是执行文件,还可以是一个标签(Label);
- 依赖 (prerequisites):就是要生成那个target所需要的文件或是目标;
- 命令 (command):Shell命令,也就是make工具需要执行的命令。
【 总结 】:通过依赖(prerequisites)中的一些文件生成目标(target)文件,目标文件要按照命令(command)中定义的规则来生成。
2. 来看一个简单的示例代码
简单写三个方法文件(openFile.c、readFile.c、writeFile.c)、一个头文件(operateFile.h)和一个主函数文件(main.c),代码如下:
// openFile.c
#include "operateFile.h"
void openFile()
{
printf("open file...........\n");
}
// readFile.c
#include "operateFile.h"
void readFile()
{
printf("read file...........\n");
}
// writeFile.c
#include "operateFile.h"
void writeFile()
{
printf("write file...........\n");
}
// operateFile.h
#ifndef __OPERATEFILE_H__
#define __OPERATEFILE_H__
#include <stdio.h>
void openFile(void);
void readFile(void);
void writeFile(void);
#endif
// main.c
#include <stdio.h>
#include "operateFile.h"
int main()
{
openFile();
readFile();
writeFile();
return 0;
}3. 根据上面的语法规则及编译链接过程编写一个Makefile文件
main:main.o openFile.o readFile.o writeFile.o # main生成所需要的.o文件
gcc -o main main.o openFile.o readFile.o writeFile.o # 生成main的规则
main.o:main.c # mian.o文件生成所需要的mian.c文件
gcc -c main.c
openFile.o:openFile.c
gcc -c openFile.c
readFile.o:readFile.c
gcc -c readFile.c
writeFile.o:writeFile.c
gcc -c writeFile.c
clean: # 需要手动调用
rm *.o main注意:Makefile的注释符号是 ‘#’。
4. 编写完成后,执行make命令,make会在当前目录下找到名字为Makefile或makefile的文件,程序就会自动运行,产生相应的中间文件和可执行文件
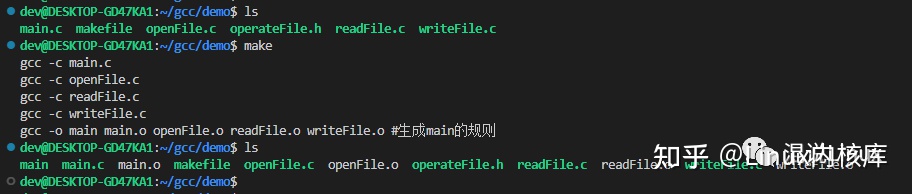
a. 如果执行make出现如下信息,那就是命令行(makefile中的gcc或者rm)前面没有用tab键缩进,不能用空格:

b. 如果执行make出现如下信息,那就是你的代码没有修改过,Makefile拒绝你的请求:

这里还会有一种情况就是如果只修改过其中一个文件,那么重新编译就可以看到只编译修改的那个文件,没有编译其他未修改的文件,避免了重复编译。这里可以想象在一个大型源码的工程或者一个内核源码,里面的源文件上千或上万个,如果只修改了一个小问题,就要全部重新编译,就会花费大量编译的过程,Makefile就可以避免这个问题,而且支持多线程并发操作,可以减少很多编译的时间,提高工作效率。
那么Makefile是如何判断文件是否有修改过呢?
Makefile是通过对比时间戳 ,当我们生成中间文件或可执行文件之后,他们的创建时间肯定要比 .c文件最后修改的时间晚,如果某个 .c文件有新修改过,它的时间戳肯定会比原来生成中间文件或可执行文件的时间戳晚,这样就判断这个 .c文件有被更新过,就会重新编译它。
5. 正常运行后,执行可执行文件输入 ./main 即可,就能看到代码执行的结果

6. 在makefile文件的最后可以看到有个clean,这个clean就是前面所说的标签,它不是一个文件,所以make无法生成它的依赖关系和决定它是否要执行,只能通过显示指定这个目标才可以 ,通过make clean的指令就可以执行clean下面的命令。

到这里,一个基础版的Makefile就完成了。
四、Makefile的优化
学会了编写基础版的Makefile后,就可以对刚刚写的Makefile进行优化。
优化1:省略命令
我们将上面写的基础版Makefile改成下面这样的省略版:
main:main.o openFile.o readFile.o writeFile.o
gcc -o main main.o openFile.o readFile.o writeFile.o
clean:
rm *.o main执行make后的结果:

可以看到,这些文件都在同一目录下的时候,省略版和基础版的结果是一样的,省略版的makefile中去掉了生成main.o、openFile.o、readFile.o和writeFile.o这些目标的依赖和生成命令,这就是make的隐含规则,make会试图去自动推导产生这些目标的依赖和生成命令,这个行为就是隐含规则的自动推导。
优化2:引入变量
这里引入变量的意思有点像使用宏替换,改成(变量名),是格式:
TARGET = main
OBJS = main.o openFile.o readFile.o writeFile.o
CC = gcc
$(TARGET):$(OBJS)
$(CC) -o $(TARGET) $(OBJS)
clean:
rm $(OBJS) $(TARGET)优化3:引入函数
格式:$(函数名 实参列表)
# 函数1
$(wildcard *.c) # 表示当前路径下的所有的 .c
# 函数2
$(patsubst %.c, %.o, 所有的.c文件) # 生成中间文件 .o
# 函数3
$(notdir xxx) # 去除xxx文件的绝对路径,只保留文件名引入函数后的Makefile版本可以改写成:
TARGET = main
SOURCE = $(wildcard *.c)
OBJS = $(patsubst %.c, %.o, $(SOURCE))
CC = gcc
$(TARGET):$(OBJS)
$(CC) -o $(TARGET) $(OBJS)
clean:
rm $(OBJS) $(TARGET)优化4:对文件进行分类管理
在一个实际工程项目中程序文件比较多,我们就会对文件按照文件类型进行分类,分为头文件、源文件、目标文件和可执行文件,分别放在不同的目录中,由Makefile统一管理这些文件,将生产的目标文件放在目标目录下,可执行文件放到可执行目录下,分类目录如下图:

- bin目录 :放可执行文件
- include目录 :放头文件
- obj目录 :放中间目标文件
- src目录 :放源文件
可见原来那些文件都不在同一目录下了,那么这时候如果还用之前的Makefile,make就没法处理了,自动推导也会无法进行,就需要改成如下:
INC_DIR = ./include
BIN_DIR = ./bin
SRC_DIR = ./src
OBJ_DIR = ./obj
SRC = $(wildcard $(SRC_DIR)/*.c) # /*/
OBJ = $(patsubst %.c, $(OBJ_DIR)/%.o, $(notdir $(SRC)))
TARGET = main
BIN_TARGET = $(BIN_DIR)/$(TARGET)
CC = gcc
$(BIN_TARGET):$(OBJ)
$(CC) $(OBJ) -o $@
$(OBJ_DIR)/%.o:$(SRC_DIR)/%.c
$(CC) -I$(INC_DIR) -c $< -o $@
clean:
find $(OBJ_DIR) -name *.o -exec rm -rf {} \; # 删除 .o 文件
rm $(BIN_TARGET) # 删除可执行文件main在Makefile中,最终要生成可执行文件main我们把它叫做终极目标,其它所有的 .o 文件本身也是一个目标,也需要编译生成,工程里面许多的 .c 就会生成许多的 .o,每一个 .c 都写一遍目标依赖命令显然是不可行的,于是就有了类似for循环的东西,把所有目标变成一个集合,但不是真正用for循环,而是使用一些抽象的符号表示,解释如下:
- %.o :所有 .o 结尾的文件
- %.c :所有 .c 结尾的文件
- $@ :表示目标文件
- $< :表示第一个依赖文件,也叫初级依赖
- $^ :表示所有的依赖文件,也叫终极依赖
当然,不止只有这些符号,只是列举了上面出现的或者常见的。
执行make后的结果:

make执行后bin目录里面已经生成了可执行文件main,obj目录里面已经生成了中间目标文件 main.o、openFile.o、readFile.o、writeFile.o,最后执行main后的结果也是和前面基础版的Makefile的结果是一样的。