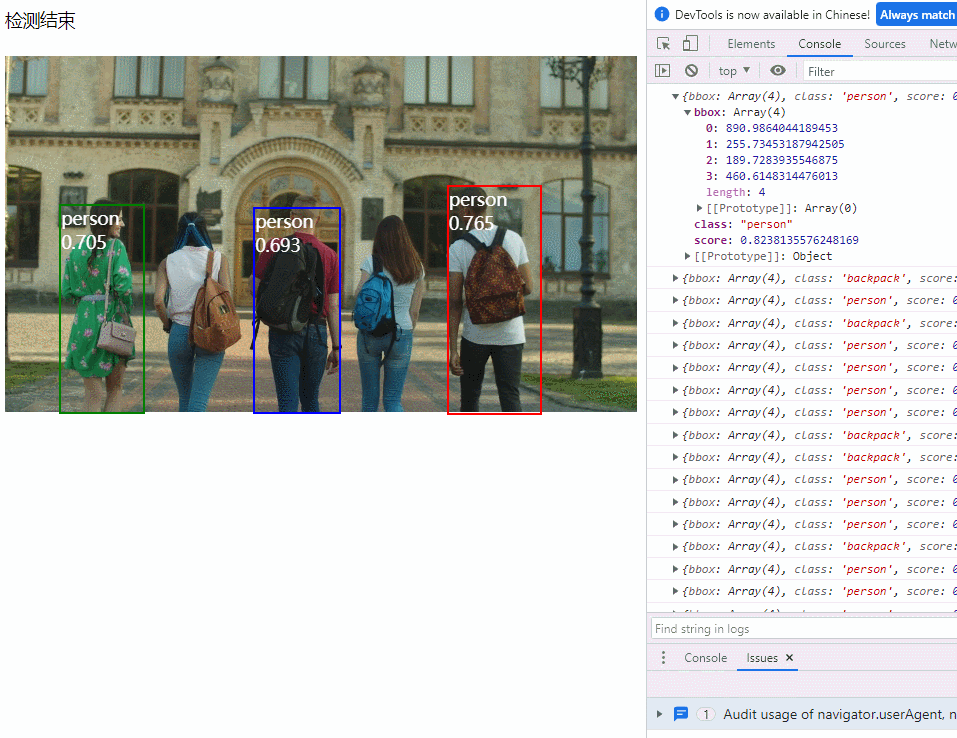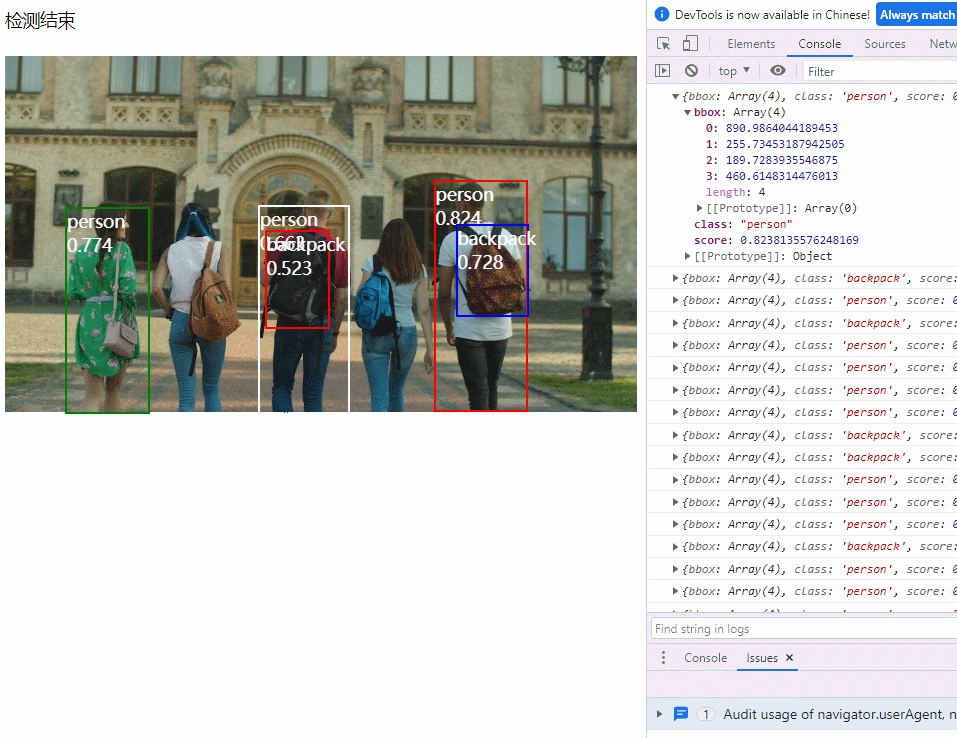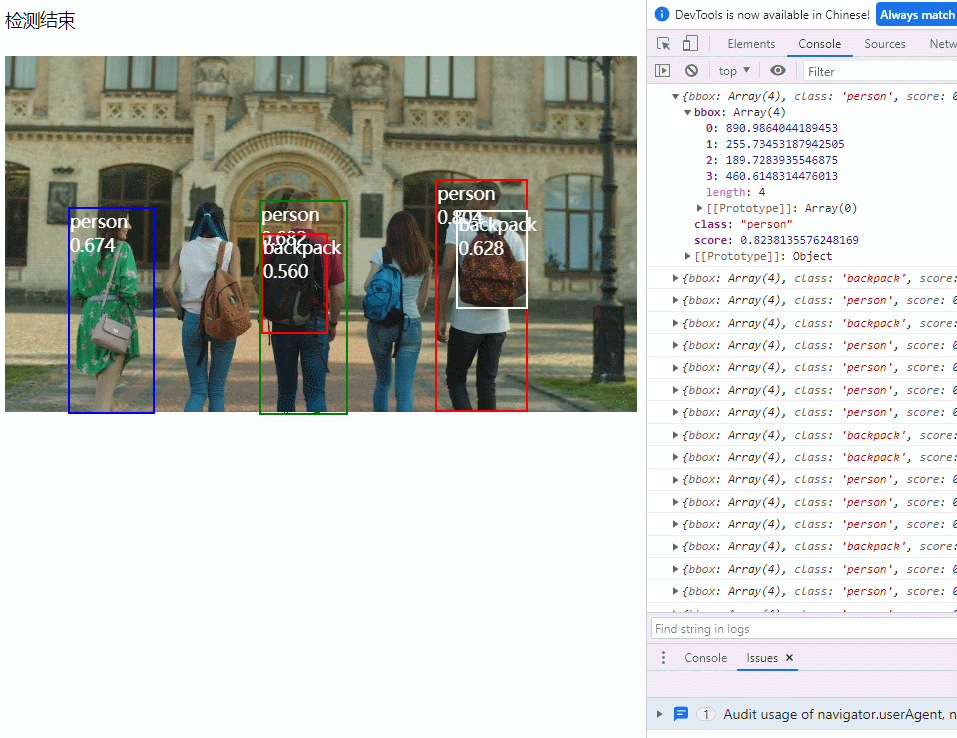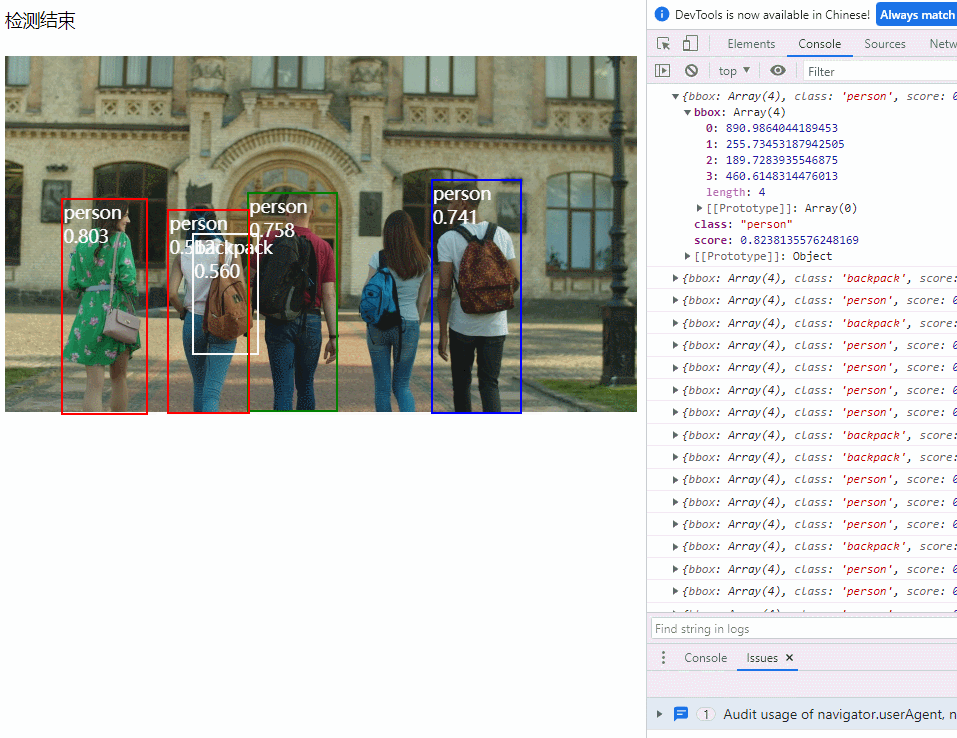
随着软件和云技术的普及,越来越多的企业开始采用微服务架构、容器化、多云部署和持续部署模式,这增加了因系统失败而给运维/ SRE / DevOps 团队带来的压力,从而增加了开发团队和他们之间的摩擦,因为开发团队总是想尽快部署新功能,并启动新的 A/B 测试。
在云时代,CI/CD 模式发展迅速,它能帮助研发团队快速改进、修复系统缺陷,把新功能推向生产,极大提高开发效率。CI/CD 能实现这一点,因为它拥有功能强大的工具,能够生成信息,也能实时或几乎实时地从运行的应用程序中收集信息,这些信息反映了应用程序的健康状况、性能和可靠性。用户可以观察和分析异常信号,捕捉行为不端的应用程序,决定是否需要修补或禁用它们。CI/CD 模式可以帮助开发者快速检测异常,防止重大故障和安全漏洞的出现,从而改善用户使用体验。
过去用于记录错误和异常的信号传输方法发展到现在,已经演变成了最新的 OpenTelemetry 标准。
本文将探索 Jina 3.12 中引入的最新跟踪和监控功能,并使用 Sentry 跟踪索引或搜索时系统内部的工作情况。
监控和跟踪可以解决什么问题?
嘿,一起来认识我们的小伙伴小博吧!他创建了一个可以在线购物的电商网站叫 J 多多,我们一起来看看这个网站是如何发展的吧,同时也可以了解一下他的监控和跟踪功能哦!
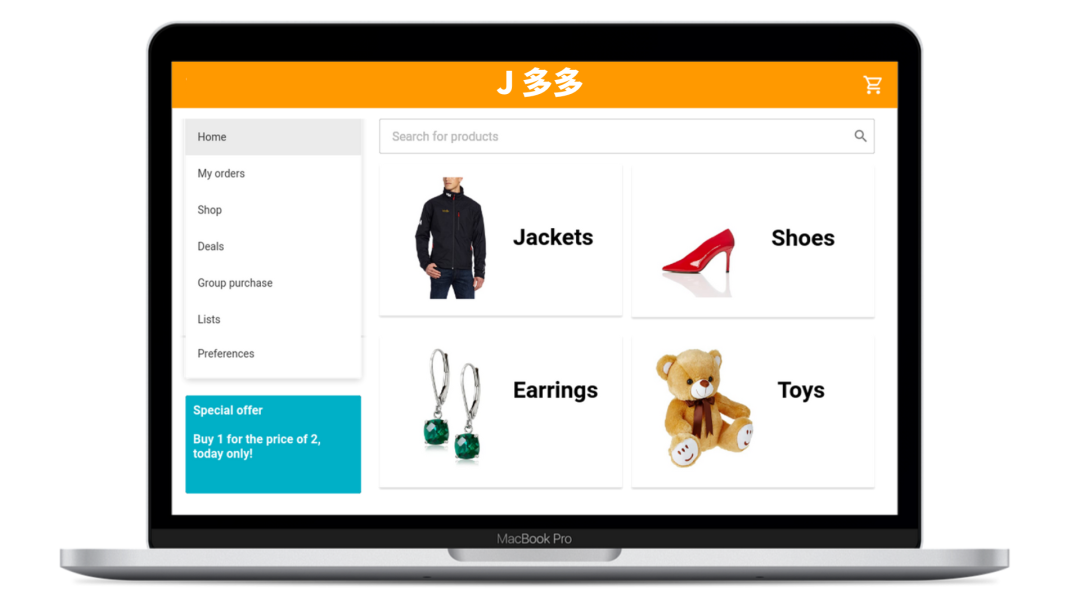
J 多多 1.0:日志作为 stdout
一开始,为了提高 J 多多网站可靠性,小博采用了一个简单的系统,用来监控生成、捕获和分析信号:
应用程序日志存储在本地机器上,定期旋转避免磁盘空间耗尽。如果需要延长日志的保留期限,可以将它们导出。
如果客户或测试人员发现搜索引擎出现异常(例如经常超时等),可以创建投诉工单来获得解决方案。
接着通过检查程序日志,将客户遇到的错误与时间进行匹配。
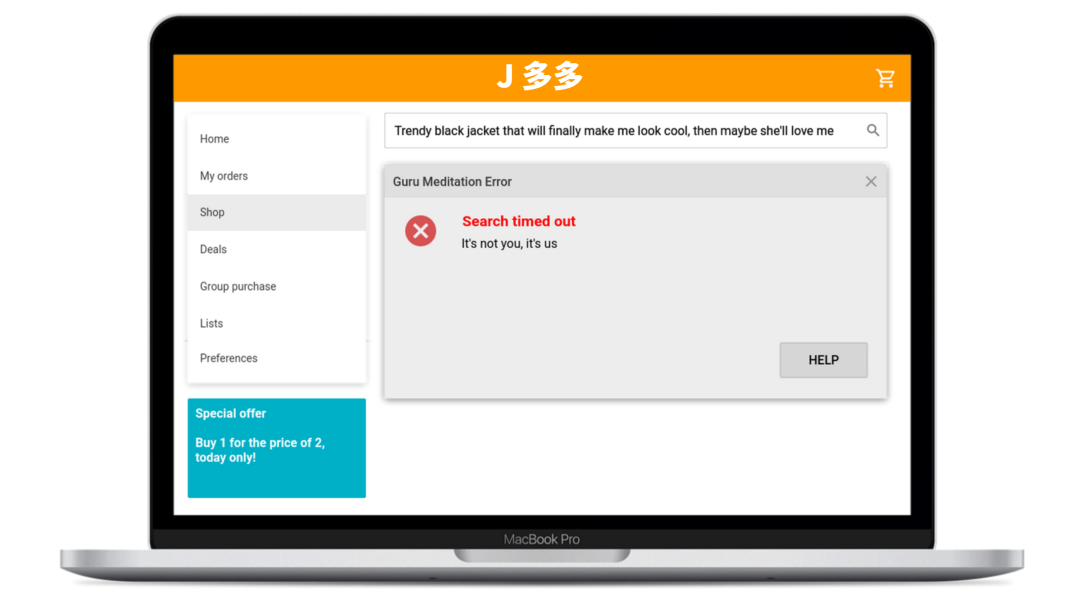
小博认识到,这个过程的繁琐是由于该系统未能改善客户的实际体验所造成的,因此他迫切尽快优化该系统。
J 多多 2.0 :结构化和持久化的日志
随着程序日志的发展迅速,小博很快就优化了日志格式,引入了结构化日志(JSON),改善了故障的报错消息以及提供了更加便捷的工具。有些工具甚至可以将代码度量集成到正在运行的应用程序中,以实时测量应用程序栈各层(网络、磁盘、CPU)的代码性能。此外,小博可以捕获、可视化并长时间存储这些信号。大数据处理框架可以让小博从不同的应用领域(语言、架构、设备平台)和部署环境中聚合、分析数据。
J 多多 3.0:使用日志跟踪故障
J 多多逐渐走向成熟, 它开始支持云/混合部署环境,处理全球数百万用户的不同设备类型。这意味着 J 多多需要更细致的跟踪监控方法:
生成有价值的信号。
找出问题最可能的根本原因。
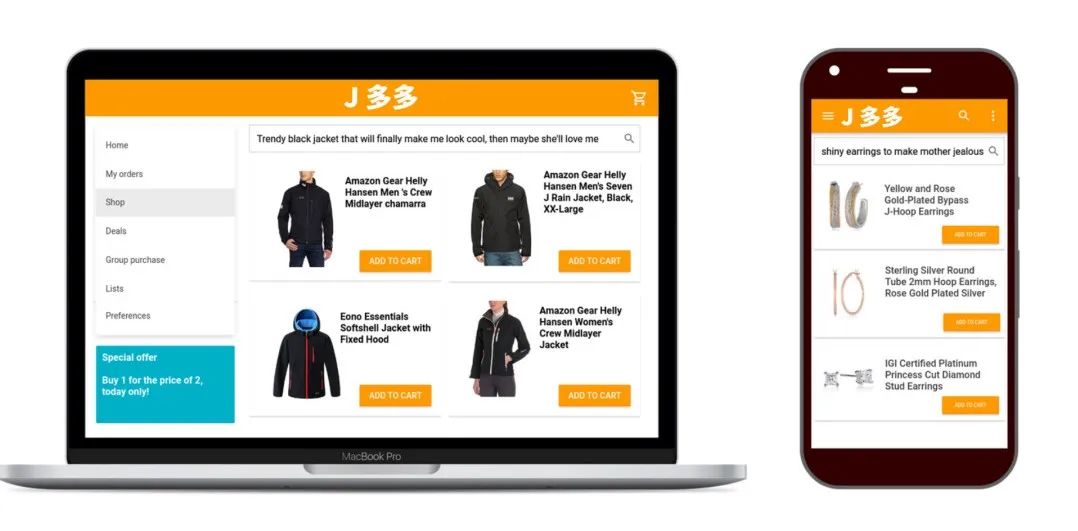
以用户小美和小智为例:
小美在 J 多多 Android 应用上购买奢侈耳环,她使用的是美国的数据连接。
小智在 Ubuntu PC 端,从智利研究基地购买黑色夹克。
对于他俩来说,用户体验都不太满意。为了服务全球各地不同设备、不同语言的本地化搜索,系统需要采用更精准的方式生成信号,以找出导致问题的根本原因。此外,越来越多的用户和设备类型意味着也会带来更多的错误方式和问题原因。总之,J 多多需要进一步优化。
什么是 OpenTelemetry
OpenTelemetry[1] 是 CNCF[2] 的孵化项目,它支持分布式跟踪和度量。小博要求在 Jina Flow 中实现 Telemetry。在开始之前,我们需要了解几个概念:
Telemetry (遥测) 是一种远程数据采集技术,用于监控系统性能和故障,它可以自动收集数据并将其发送至接收设备进行监控。简而言之,原始观察值或日志消息在请求期间可以用作度量。
Instrumentation(仪表仪器)是使用仪器记录和收集原始观察值,并将其转换为信号进行传输来实现监控的过程。
Tracing(跟踪)则是指根据应用程序的日志记录,来监视它的运行情况。
如何在 Jina 中使用 OpenTelemetry?
Jina >=3.12 已经集成了 OpenTelemetry,本文将介绍如何使用它构建文本到图像搜索系统。
DocArray 负责处理数据并与存储后端交互。
Jina Executor 实现微服务。
Jina Flow 用于加载、编码和存储编排微服务。
OpenTelemetry Collector Contrib 收集微服务跟踪信息,可以实时监视微服务。
Sentry 可视化微服务报告操作,帮助用户及时发现和解决问题。
请注意,本文仅涉及后端,如果您想要构建 无代码并且前后端兼具的神经搜索解决方案,请查看 Jina AI Cloud 的 APPs。
地址:cloud.jina.ai
1 准备数据
我们利用 Finetuner 对 deepfashion 数据集进行预处理,并通过提取和格式化 Finetuner 生成的图像标签来产生每个产品的 text 属性。

数据库:paperswithcode.com/dataset/deepfashion
注:Jina ≥ 3.12.0 才支持 OpenTelemetry 功能,一定要记得升级!
Jina Flow 可以作为连接微服务(也就是 Executors)的流水线。由于我们只是为了让大家了解 OpenTelemetry 功能,所以不会深究代码,只是给出概括性的介绍。毕竟 Telemetry 才是重点。
在 Python 中定义以下内容:
from jina import Flow, DocumentArray, Document
flow = (
Flow(
host='localhost',
port=8080,
tracing=True,
traces_exporter_host='localhost',
traces_exporter_port=4317,
)
.add(
name='clip_encoder', # encode images/text into vectors
host='localhost',
port=51000,
timeout_ready=3000000,
uses_with={'name': 'ViT-B-32::openai'},
external=True,
tls=False,
)
.add(
name='qdrant_indexer',
uses='jinahub+docker://QdrantIndexer', # store vectors and metadata on disk
uses_with={
'collection_name': 'collection_name',
'distance': 'cosine',
'n_dim': 512,
},
)
)
with flow:
flow.block()为了节省时间,Flow 使用的是 Jina Executor Hub 中预先构建的 Executors。
📎 https://cloud.jina.ai/executors

Flow 由以下部分组成:
Gateway[3],管理流向底层微服务的请求,向 Flow 提供跟踪参数,使得每个部署的微服务都能使用 OpenTelemetry 跟踪功能。
CLIP-as-service[4] Executor,使用默认的基于 cpu 运行的
ViT-L-14-336::openai模型,编码文本和图像。clip_encoder服务基于独立 Flow 运行,Flow 中包含跟踪参数。QdrantIndexer[5] ,基于 Docarray 的后端存储和搜索数据。如果数据库不是在本地默认端口运行的,则需要提供适当的 Qdrant
host和port参数,uses_with是指定向量维度的参数。
2 索引和搜索
现在我们已经把所有组件都准备好了,把数据加进数据库,然后就可以使用文本搜索技术搜索商品了。
下面这段代码可以让我们轻松地索引商品图片:
from jina import DocumentArray, Client
da = DocumentArray.pull('deepfashion-text-preprocessed', show_progress=True)
# connect to the Flow
client = Client(host="grpc://0.0.0.0:8080")
# use only 100 Documents for demo
for docs in da[:100].batch(batch_size=10):
client.post(on="/index", inputs=docs)示例:发送一个搜索请求
from jina import Client, DocumentArray, Document
client = Client(host='grpc://0.0.0.0:8080')
results = client.post('/search', DocumentArray(Document(text='jacket mens')))接下来,我们一起来分解一下上面的索引和搜索流程:
clip_encoder为产品的text属性生成嵌入向量。Flow(...).add(...).add(...)默认创建顺序拓扑。请求首先会通过 clip_encoder 服务,然后结果流向qdrant_indexer服务。qdrant_indexer实现了用于索引操作的/index端和用于搜索操作的/search端。操作都是基于嵌入向量的,不关注产品属性。
3 启动 Executors 跟踪
现在,开始解释 OpenTelemetry 的一些概念:
Tracing 是指记录程序执行信息的特定日志记录程序。
Trace 表示构成最终结果的一系列(或者并行,或者组合)操作。。
每个 trace 都由一个或多个跨度组成。跨度表示跟踪中的操作,如
process_docs、sanitize_text、或embed_text。
Hub Executors (cloud.jina.ai/executors) 默认集成了检测工具。以下是一个简单的示例,基于有用的标签 /index 为操作提供了跨度:下面的代码来自 QdrantIndexer,创建了两个跨度:
Jina 会自动为
@requests装饰器创建 /index 跨度,这是 Jina 自动检测功能之一,开箱即用。你可以跟踪更细粒度的操作,如
qdrant_index跨度,它记录了 Qdrant 的索引请求中接收的文档数量。可疑的快速索引操作可能是由于空请求导致的,非常慢的请求则可能是由于大型文档导致的。你可以向跨度标签添加更多信息,例如目标 Qdrant Collection[6] 和与部署相关的信息。
@requests(on='/index')
def index(self, docs: DocumentArray, tracing_context, **kwargs):
"""Index new documents
:param docs: the Documents to index
"""
with self.tracer.start_as_current_span(
'qdrant_index', context=tracing_context
) as span:
span.set_attribute('len_docs', len(docs))
self._index.extend(docs)注意,在存储 Document 时,不同的 Flow 可能需要使用同一 Qdrant 集群,这时,service.name 属性会为你提供帮助。
4 收集并分析 trace
现在,Jina 支持通过基于 OpenTelemetry Collector Contrib 的统一组件,将 Telemetry 信号收集并导出至转换数据用于可视化和分析的增强组件。收集器仅作为收集和导出数据的统一中介,具有基本的设置。
为此,我们使用自托管的 Sentry 应用程序环境来设置实际的 APM 或 SPM,本文只探索了 Sentry 支持的一小部分功能。有关更多信息,请参阅 文档。
💡 Application Performance Monitoring(APM)或 System Performance Monitoring(SPM)是监控应用性能和可用性的技术。服务级别指标(SLI)通过检测和诊断复杂的应用性能问题,维护预期的服务级目标(SLO)。
如何使用 Sentry 可视化并分析收集的数据?
Sentry 提供了很多功能和定义,可以帮助开发者将 Telemetry 信号转换为业务术语。我们只关注性能[7]、摘要[8]、追踪[9] 以及 Dashboard 视图,基于这些信息,我们可以监控 Flow 和 Executor。
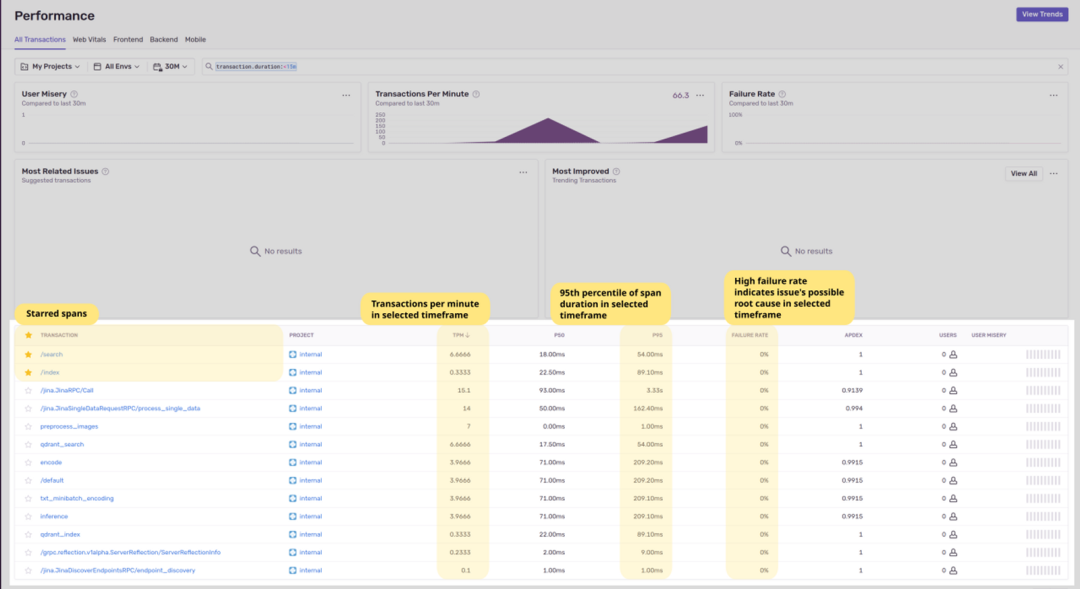
1. Performance view
Performance view (性能视图)给出了 Sentry 接收的指标信号的整体视图:
2. Summary view
您可以单击跨度,查看 Summary view (事务摘要)页面。在我们的例子中,点击 /index 跨度,弹出了 index 摘要:
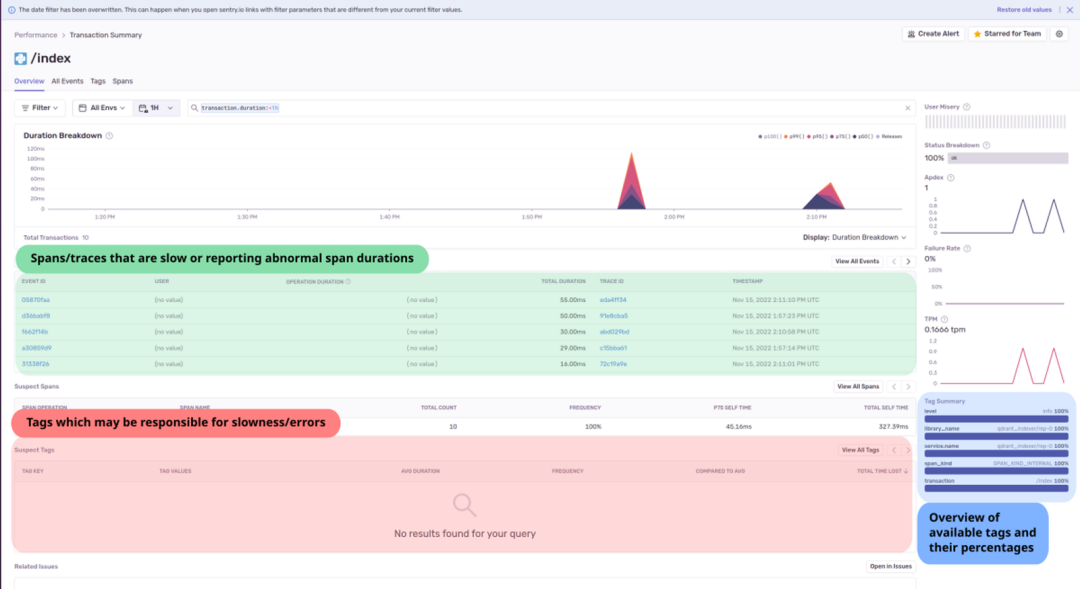
在上面的屏幕截图中:
TRACE ID 显示了跨度的父追踪。
绿色部分列出了可能很慢的跨度,点击 trace ID 可以查看操作的完整跟踪。
红色部分可以帮助开发者识别并了解操作期间产生的异常、错误或问题的根本原因,跨度的持续时间和状态还可用来检测可疑对象,并显示属于可疑跨度的标签。通过向跨度属性添加有用的标签,可以更容易地检测出可疑的跨度和标签。
蓝色部分显示所选时间段内的顶级标签,提供更概括的视图,帮助开发者快速了解不同属性,并深入了解异常的根源。
3. Trace view
在 summary view 中点击跨度的 event ID,就能看到 Trace view(跟踪视图)。让我们一起来看单个 /search 操作的 跟踪视图:
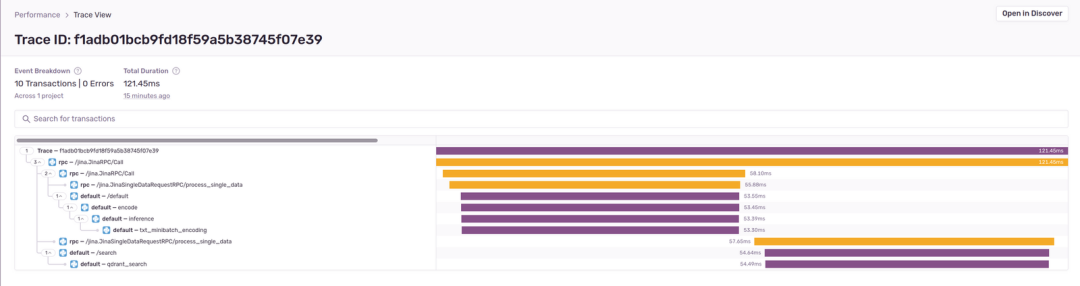
在上图中,trace f1adb01bcb9fd18f59a5b38745f07e39 显示了生成响应跨度的端到端请求流,跨度名称以 rpc 或 default 标签为前缀,前缀由 Sentry 根据跨度标签属性确定。在这张截图中,Jina 自动创建了 rpc 跨度,它表示内部请求流。 rpc 跨度有助于填补空白,并基于用户添加的 encode, inference, txt_minibatch_encoding, /search 和 qdrant_search 跨度,提供完整的视图。
在深入研究用户创建的跨度之前,我们先了解一下 Trace view。Trace view 是一个有向无环图,从请求开始连接到到结束(从左到右跟踪条形图)。从自上而下渲染的彩色条可以看出,所有操作都是顺序的。每个操作的持续时间都会显示,在有并行操作或慢速跨度的情况下,跟踪视图的作用会更明显。左侧是一个树形表示,代表高级跨度和每个操作嵌套的跨度(自上而下)。因为 Flow 生成的拓扑结构,存在三个顶级跨度。
客户端请求到达网关之后,网关会调用
clip_encoderExecutor。接着,Executor 会创建搜索文本的嵌入向量,并将其转发到
qdrant_indexer的搜索端。最后,搜索端会根据文本查询检索商品。
如果你想要了解 Sentry 的详细信息和功能(例如,显示错误的跨度),可以查看文档。
用户可以通过点击跨度获取更多信息,我们可以单击 clipencoder 的 inference 跨度,inference 跨度会为生成请求中 Document 的 text 属性生成嵌入向量:
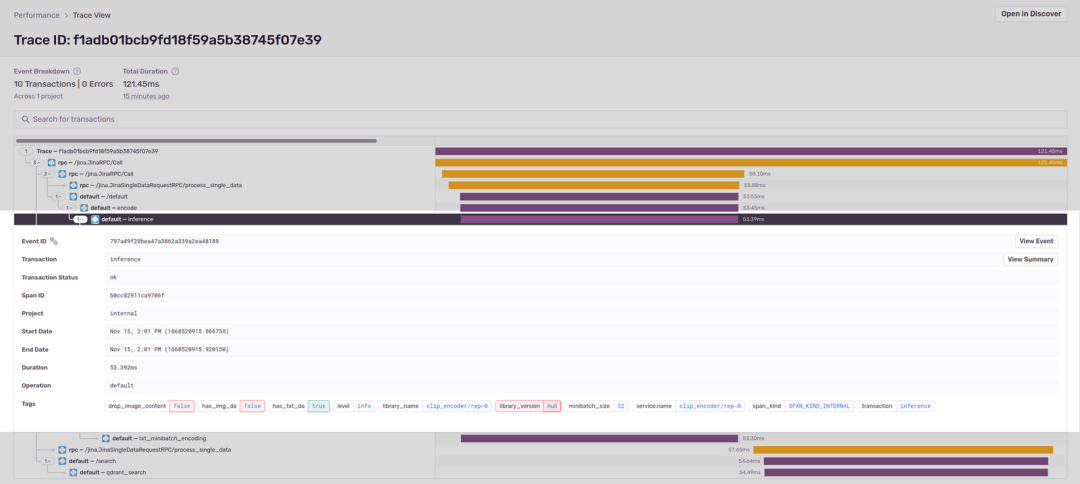
has_img_da和has_txt_da属性显示了文档中是否包含图像和/或文本数据。minibatch_size显示了线程池生成嵌入向量的批量大小。
由于演示数据集只提供文本数据,所以将 has_txt_da 设置为 True ,下一个跨度仅包含 txt_minibatch_encoding 跨度,其中文本嵌入实际上是线程池生成的。
定制 Sentry dashboard
最后,让我们一起来研究示例 Flow 的性能监控仪表盘。通过综合多种 Telemetry 信号,我们为开发者提供全面的指标概览,以便他们根据这些指标来辨别系统的差异或异常行为。
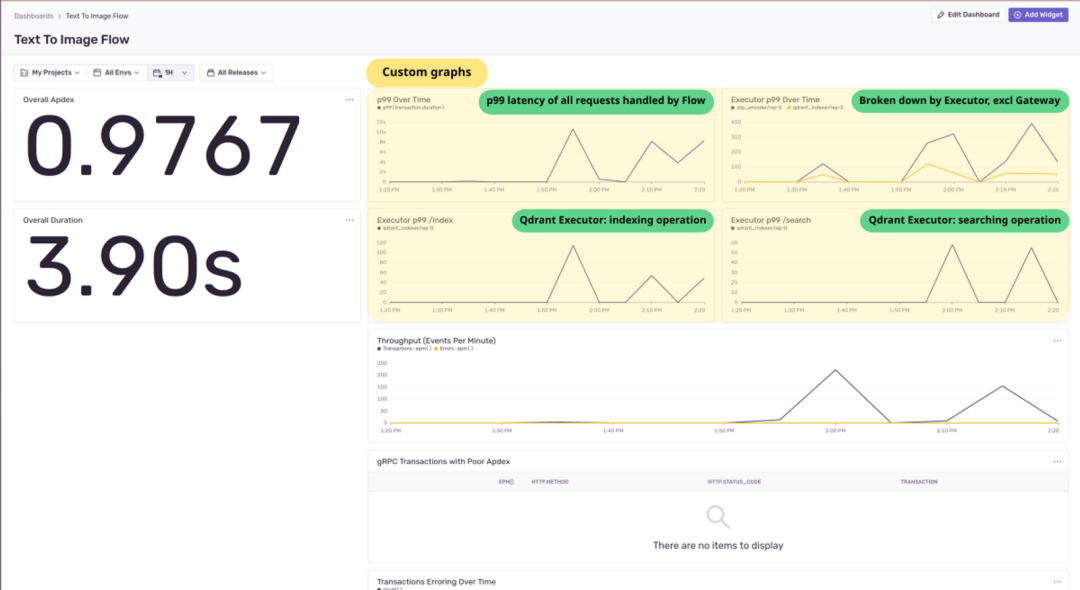
💡 关于自定义 dashboard 和 Sentry 提供的错误分析图的详细信息,请参阅文档。https://docs.sentry.io/product/dashboards/
总结
基于 OpenTelemetry,我们为小博提供了可靠的产品搜索系统。这使得在错误发生时可以获得及时报告,从而更容易追踪系统问题,加快响应时间,缩短问题修复的时间。小博可以专注于改进网站,以增加购物网站的商品数量或添加新的搜索功能,从而提高客户满意度、提升业务量并增加利润。
如果您有兴趣了解 OpenTelemetry,想要复现小博的成功,可以利用 OpenTelemetry 提高系统的可观察性和可靠性,请参阅我们的 文档[10]。
📎 https://docs.jina.ai/cloud-nativeness/opentelemetry/
作者简介
Girish Chandrashekar, Senior Cloud Architect at Jina AI
Alex C-G, Open-source Evangelist at Jina AI译者简介
吴书凝,Jina AI 社区贡献者
原文链接
https://jina.ai/news/guide-using-opentelemetry-jina-monitoring-tracing-applications/
参考资料
[1]
OpenTelemetry: https://opentelemetry.io/
[2]CNCF: https://www.cncf.io/
[3]Gateway: https://docs.jina.ai/fundamentals/gateway/#gateway/
[4]CLIP-as-service: https://github.com/jina-ai/clip-as-service/
[5]QdrantIndexer: https://cloud.jina.ai/executor/j3u4uwje?random=4939/
[6]Qdrant Collection: https://qdrant.tech/documentation/collections/
[7]性能: https://docs.sentry.io/product/performance/
[8]摘要: https://docs.sentry.io/product/performance/transaction-summary/
[9]追踪: https://docs.sentry.io/product/sentry-basics/tracing/trace-view/
[10]文档: https://docs.jina.ai/cloud-nativeness/opentelemetry/
更多技术文章
⚖️ 模型微调,低预算,高期望!
🌪 开箱即用的云原生多模态系统解决方案
📖 Jina AI 创始人肖涵博士解读多模态AI的范式变革
🎨 语音生成图像任务|🚀 模型微调神器 Finetuner
👬 在 Jina AI 社区连接、分享、共创

点击“阅读原文”,即刻阅读原文