原文来自微信公众号“编程语言Lab”:数值程序分析
搜索关注“编程语言Lab”公众号(HW-PLLab)获取编程语言更多技术内容!
欢迎加入编程语言社区 SIG-程序分析,了解更多程序分析相关的技术内容。
加入方式:添加文末小助手微信,备注“加入 SIG-程序分析”。
作者 | 陈立前
整理 | 纪妙
作者简介
陈立前,国防科技大学计算机学院副教授,主要从事程序分析与验证、抽象解释相关研究。在 ACM/IEEE Transactions、POPL、FSE 等期刊会议上发表论文多篇,获 ACM SIGSOFT 杰出论文奖(FSE 2020),出版教材译著 3 部。研究成果获省部级科技进步一等奖 1 项、二等奖 1 项。部分成果已在航天、国防等领域重大工程中应用。
视频回顾
SIG-程序分析技术沙龙回顾|数值程序分析
# 研究背景 #
很多软件的代码里面都包含了大量的数值运算,如科学计算、金融、机器学习、物理模拟、统计分析等领域的软件。在嵌入式控制软件中,往往也会包含大量数值运算,而嵌入式控制软件在很多安全攸关的领域被大量使用,比如说在航天航空领域 GNC、姿轨控等相关的一些功能实现中都会用到数值运算。

这些软件数值运算中,用到的数值不像我们传统理解数学意义下的数,如实数和整数,而都是浮点数和机器整数。此外,在嵌入式软件设计中,往往会在事先设计时,把存储区域做一些划分,用来存一些数据,编写程序来操作这些存储区域时,会使用一些指针指向这些区域,然后使用指针算术访问数据。因此,这些软件中除了传统的数值运算,还涉及到一些指针算术的运算,当然我们可以把指针算术也看作是整数运算。
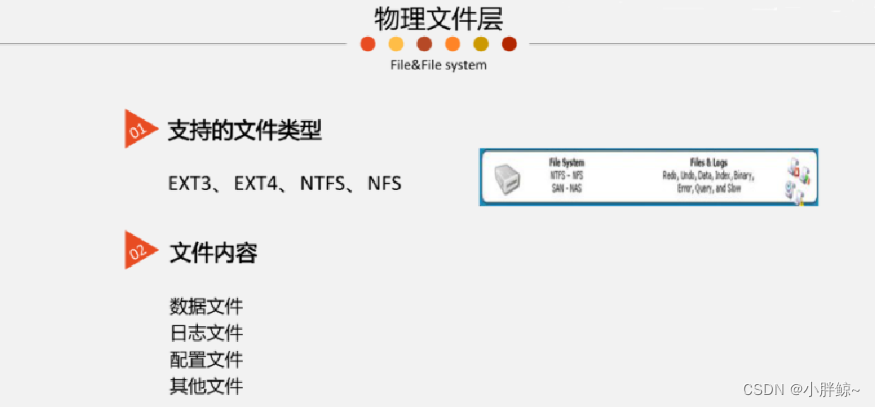
# 数值运算举例 - 求平均数
举一个简单的求两个数平均数的例子,可能大家第一印象会按照数学的模式去写,先做加法,然后再除以二,这样很容易就求得了两个数的平均数。这种在数学上大家肯定觉得没什么问题,但是如果在机器里面写成程序实现,这时候先做加法的话,x+y 很容易会出现浮点的上溢。而对于这种情况,如果把求平均数表达式稍微变一变,把参数先除以二,然后再做加法,你就会发现基本上就不会导致浮点上溢。

# 数值相关常见错误
正是因为这种数学上的运算,跟我们在机器里面的浮点数和整数的运算存在差异,有很多实数上的性质,对于浮点运算并不成立。那么,大家写程序的时候,可能很容易会导致一些数值相关的错误。有很多很常见的程序错误与此相关,比如说除零错、数组越界,浮点上溢、整数上溢等,还比如指针算术导致的非法指针访问。另外,程序中有大量的数值运算的话,还可能会导致一些计算精度的缺陷。
- 除零错、数组越界、浮点上溢、整数上溢等
- 指针算术导致的非法指针访问等
- 函数输入不在定义域内
- 计算精度缺陷
历史上出现的一些重大事件,比如像爱国者导弹防御系统拦截失败,阿丽亚娜 5 号火箭爆炸,openSSL 心脏滴血等,本质上都是跟数值相关的。有些是因为数值的溢出,有些是因为一些误差的累计,有些是因为缺少边界的检查,等等。

# 数值程序分析的思路
那么,我们应该如何检测这种错误呢?即通过 数值程序分析 来检测。
当程序写好了之后,我们可以通过程序分析的方法来检测这些错误。检测数值相关的错误的时候,最基础的一步是首先要生成不变式,有了不变式之后,我们再来分析这个程序里面的一些性质,检查一些性质是不是成立的,检测数值相关的缺陷,缺陷检测出来之后,我们还可以考虑缺陷修复。我们可以沿着这条途径来检测和修复数值相关的缺陷。

# 不变式生成
不变式生成 是数值程序分析中最基础的关键技术之一。不变式生成实际上是一个非常经典的课题,关注如何在每一个程序点处自动生成变量之间的不变式。我们关注的是 数值不变式,如下图红色标注的注释,就是不变式。有了不变式后,我们就可以去分析这个程序会不会出现一些数值相关的缺陷。

打个比方,对于上图这个非常简单的就一个变量和一个循环的程序。假设我们现在关注程序点 3 处的加法操作,若 x 是整型变量,加 1 会不会出现整数上溢呢?
这个问题实际上是跟 x 的类型有关,如果 x 是 char 类型,也就是 8 位类型的话,我们知道前面的不变式是 [0,255],如果再加上 1,可能就会出现整数的上溢;当然如果 x 是 16 位的或者是 32 位的整型,那么这个加法操作就不会出现整数上溢问题。
因此,我们需要先拿到不变式,之后就可以检查程序语句是否满足数值的一些性质,或者说是否存在数值相关的一些缺陷。这是数值程序分析里面一个非常关键的技术。
业界有很多的方法来生成不变式,简单分为以下几类,比如最传统的 基于抽象解释 的,也可以用 基于约束求解 的方法来生成,最近几年也有用 机器学习 的方法来生成不变式,当然还有一些用动态的方法来生成一些 likely 不变式。
- 基于抽象解释
- 基于约束求解
- 基于学习
- 基于动态方法
今天这个报告,我主要介绍 基于抽象解释的不变式的生成,以及它在数值程序分析中的应用。
# 抽象解释 #
接下来,我先介绍一下抽象解释相关的理论。
# 抽象 & 近似
抽象解释是 1977 年提出来的 1,它最开始是用来对程序的语义进行 抽象(或近似) 的一种统一的框架。

这里的定义涉及到两个关键词,一个叫 抽象,一个叫 近似。我们应该怎么理解这两个词呢?接下来我会通过直观的例子来解释,希望能帮助大家理解。

首先,是对于 “近似” 的理解。比如说当我们用一个刻度尺去量一个物体的长度的时候,其实我们不能量出这个物体的精确的长度,但是我们人眼可以看到它大概是 3.4cm 左右,那么这个值实际上是一种近似。
接着,我们来看对 “抽象” (Abstraction) 的理解。比如说我们现在碰到这样一个问题,两个大数加起来之后再乘以一个大数的话,那么这个结果到底是正的还是负的呢?我们会首先想到先计算加法的结果,实际上这是一个比较大的值,然后再做乘法。如果用笔纸去算的话,那么需要费些时间才能把最终的值给算出来,并最后发现它是个正数。整个过程的计算代价还是比较大的。其实我们可以发现:如果两个数都是正数,那么两个正数相加的话,依然是个正数,然后再乘以另外一个正数,那么它的结果肯定也是个正数。这是一些简单的运算规则,但是根据这些规则计算的话,计算代价是非常低的。将每个数抽象为正负表示,这其实就是一种抽象的思想。通过抽象,我们把一些跟关注的问题本身无关的东西忽略掉。比如我们只关心这个结果是正的还是负的,而对它本身具体是什么值,我们并不关心,所以这个时候我们就可以把这个具体的值忽略掉,而只关心它的正负性,从而可以快速判定结果的正负。这就是抽象思想的体现。
抽象解释,为静态分析的设计提供了一个通用的框架,还可以用来自动生成程序的不变式。简单来讲,具体世界的状态比较多,它的取值的可能性也比较多,而中间的一些计算也比较繁琐或者代价比较大。那么我们就希望能通过一种抽象的方法,把它转到到一个抽象的空间里面来,使得在这个抽象的空间里面它的状态比较少,计算的代价也比较小,这样的话我们就能快速分析得到这个程序的一些性质。
# 伽罗瓦(Galois)连接
抽象解释里面最核心的一个概念叫做 伽罗瓦(Galois)连接:
( C , ≤ ) ⇌ α γ ( A , ⊑ ) (C, \leq) \xrightleftharpoons[\alpha]{\gamma} (A, \sqsubseteq) (C,≤)γ α(A,⊑)
定义如下:
对于给定的两个偏序集 ( C , ≤ ) (C, \leq) (C,≤) 和 ( A , ⊑ ) (A, \sqsubseteq) (A,⊑)( C C C 是 Concrete, A A A 是 Abstract),如果存在函数对 α : C → A \alpha:C \rightarrow A α:C→A 和 γ : A → C \gamma:A \rightarrow C γ:A→C 满足如下性质的话,那么我们认为这个函数对 ( α , γ ) (\alpha, \gamma) (α,γ) 是具体域 C C C 和抽象域 A A A 之间的 伽罗瓦连接。
∀ a ∈ A , c ∈ C : α ( c ) ⊑ a ⇔ c ≤ γ ( a ) \forall a \in A, c \in C : \alpha(c) \sqsubseteq a \Leftrightarrow c \leq \gamma(a) ∀a∈A,c∈C:α(c)⊑a⇔c≤γ(a)
该性质可以如此理解,假设把具体世界里的一个元素 c c c 抽象化之后得到 α ( c ) \alpha(c) α(c)。 α ( c ) \alpha(c) α(c) 比抽象域里另一元素 a a a 要小,当且仅当将抽象元素 a a a 映射回具体世界里面得到 γ ( a ) \gamma(a) γ(a) 时, c c c 应比 γ ( a ) \gamma(a) γ(a) 要小。这里所说的 “小”,对应的是一个序关系。
满足了这个性质后, α \alpha α 和 γ \gamma γ 就构成一个伽罗瓦连接。我们把 α \alpha α 叫作从具体世界到抽象世界的抽象化函数,把 γ \gamma γ 叫作从抽象世界到具体世界的具体化函数。我们把左边这个叫做具体域,右边叫做抽象域。

举个栗子
接下来,我们通过一个简单且经典的抽象域 —— 区间抽象域,来给大家介绍抽象域的相关概念。
假设我们的具体域是一个整数集合 Z Z Z 上的幂集 P ( Z ) \mathcal{P}(\mathbb{Z}) P(Z),那么它对应的序关系就是集合包含关系。
( P ( Z ) , ⊆ ) ⇌ α γ ( I , ⊑ ) (\mathcal{P}(\mathbb{Z}), \subseteq) \xrightleftharpoons[\alpha]{\gamma} (I, \sqsubseteq) (P(Z),⊆)γ α(I,⊑)
我们会把这个幂集映射到区间抽象域上面的一个区间集合,这个抽象域的序关系是区间上的包含关系。即,如果区间较小的话,那么它的下界要大一点,上界要小一点。同时,我们对区间做了一些扩展,比如它的下界可以取到负无穷大,上界可以取到正无穷大。
I = def ( Z ∪ { − ∞ } ) × ( Z ∪ { + ∞ } ) I \stackrel{\text { def }}{=}(\mathbb{Z} \cup\{-\infty\}) \times(\mathbb{Z} \cup\{+\infty\}) I= def (Z∪{−∞})×(Z∪{+∞})
接下来我们来看 α \alpha α 和 γ \gamma γ 怎么定义。对于具体域上的一个元素,这个元素肯定是这个幂集里面的一个元素,即整数集合 Z \mathcal{Z} Z 的一个子集,我们把这个整数子集记作 X X X,那么 α ( X ) \alpha(X) α(X) 会把它映射成一个区间,取这个集合 X X X 里面最小的整数值作为区间的下界,最大的整数值作为区间的上界,这就是抽象化函数 α \alpha α 的定义。
α ( X ) = def [ min X , max X ] \alpha(X) \stackrel{\text { def }}{=}[\min X, \max X] α(X)= def [minX,maxX]
同样的反过来,如果给定一个抽象元素,比如说一个区间 [ a , b ] [a,b] [a,b],我们怎么把它映射回具体域的元素(即一个集合)呢? 这个整数集合会包含所有大于等于 a a a 且小于等于 b b b 的整数。
γ ( [ a , b ] ) = def { x ∈ Z ∣ a ≤ x ≤ b } \gamma([a, b]) \stackrel{\text { def }}{=}\{x \in \mathbb{Z} \mid a \leq x \leq b\} γ([a,b])= def {x∈Z∣a≤x≤b}
给一个整数的集合 { 0 , 1 , 2 , 5 } \{0,1,2,5\} {0,1,2,5},我们将其映射到区间抽象域,把它抽象化之后,按照定义,我们会得到区间 [ 0 , 5 ] [0,5] [0,5]。 [ 0 , 5 ] [0,5] [0,5] 这个区间实际上是整数集合 { 0 , 1 , 2 , 5 } \{0,1,2,5\} {0,1,2,5} 一个可靠的 上近似,并且是一个最佳的抽象,也就是说你找不到另外一个比 [ 0 , 5 ] [0,5] [0,5] 要小的,同时还包含 { 0 , 1 , 2 , 5 } \{0,1,2,5\} {0,1,2,5} 这个集合的区间。
a ( 0 , 1 , 2 , 5 ) = [ 0 , 5 ] [0,5]是0,1,2,5的可靠且最佳抽象 a({0,1,2,5})=[0,5] \qquad \text{[0,5]是{0,1,2,5}的可靠且最佳抽象} a(0,1,2,5)=[0,5][0,5]是0,1,2,5的可靠且最佳抽象
反过来,如果把抽象元素 [ 0 , 5 ] [0,5] [0,5] 映射到具体世界里面,我们需要定义一个 γ \gamma γ 函数。我们知道具体世界里对应的是一个整数集合,把 [ 0 , 5 ] [0,5] [0,5] 映射回来的话,只要在 [ a , b ] [a,b] [a,b] 中的整数都需要在这个集合中,那么结果就是 { 0 , 1 , 2 , 3 , 4 , 5 } \{0,1,2,3,4,5\} {0,1,2,3,4,5}。我们再与原来最开始的具体元素 { 0 , 1 , 2 , 5 } \{0,1,2,5\} {0,1,2,5} 进行比较,你会发现先做抽象,然后再映射回具体世界里,包含的元素会更多,比如说 { 3 , 4 } \{3,4\} {3,4} 包含进去了。
γ ( [ 0 , 5 ] ) = { 0 , 1 , 2 , 3 , 4 , 5 } 把0,1,2,5抽象成[0,5]存在精度损失 \gamma([0, 5]) = \{0,1,2,3,4,5\} \qquad \text{把{0,1,2,5}抽象成[0,5]存在精度损失} γ([0,5])={0,1,2,3,4,5}把0,1,2,5抽象成[0,5]存在精度损失
对应到这个程序分析场景,可以理解成这是一种精度的损失。为什么会存在这种情况呢? 因为在具体世界里面,我们知道 { 3 , 4 } \{3,4\} {3,4} 不在程序状态 { 0 , 1 , 2 , 5 } \{0,1,2,5\} {0,1,2,5} 里,但是做了抽象之后虽然能确定 { 6 } \{6\} {6} 不在程序状态中,但是不能排除 { 3 , 4 } \{3,4\} {3,4} 在程序状态中。
这个对应到程序分析里面对应的就是精度的损失。
# 抽象域设计
整个抽象解释框架,实际上自 1977 年提出来以后发展至今已经比较成熟了,在碰到特定应用场景时,我们需要在这个框架下设计一些新的抽象域。设计新的抽象域时主要考虑两个方面:
- 域元素:对 程序状态 进行抽象
表示方法: 约束形式等,e.g.,区间: a < = x < = b a<=x<=b a<=x<=b - 域操作:对程序 语义动作 进行抽象
- 交 (assume 语句)
- 控制流接合 (if-then-else-endif)
- 投影(非确定赋值,过程间分析)
- 迁移函数
- 赋值迁移语句 (赋值语句)
- 测试迁移语句 (if 语句)
- 加宽(循环)
一是我们要考虑应如何表示域里的元素。我们需要用域元素来对程序的状态进行描述。最经典的就是用一类约束来表示,比如刚才介绍的区间,我们用的就是变量的上下界的这种形式来对这个程序的状态进行描述。当然也有复杂点的描述方式,比如多面体抽象域用的是线性不等式约束。
另一方面,除了域元素的表示,我们还需要考虑如何处理程序中的语义动作,比如说赋值语句、if 语句等等。对于这些语句,我们需要在抽象域里面有对应的一个操作来对它进行处理。比如说,设计抽象域的时候,我们需要设计 meet 操作、join 操作。join 指集合或者控制流汇合。简单来讲,就是在 if-then-else-endif 这个地方,我们两个分支汇合处(即 endif 处)需要一个 join 操作来把程序状态合并起来。程序里面有赋值语句,所以我们对赋值语句需要设计一个抽象迁移函数。对于条件测试语句的话也是类似的。而对于程序里的循环,我们需要设计加宽的操作来保证程序分析过程中不动点迭代计算可终止。

# 数值抽象域
数值抽象域是一类非常重要的抽象域,它的主要用途是来刻画程序变量之间的数值关系,即 数值不变式。有了这个数值不变式,我们就可以来检查数值相关的一些性质或者缺陷。目前已存在 40 种以上的抽象域。经典的抽象域可以简答划分成两类:
- 非关系型的抽象域:例如符号域。就像我们一开始介绍 “抽象” 这一概念的时候,我们只关心这个变量到底是正的还是负的。除此之外,还有刚才讲到的区间的抽象域,还有同余域
- 关系型抽象域:包括线性等式域、线性不等式抽象域(多面体域)、八边形域等。八边形域描述约束表示时,系数只能是 + 1,-1 或者是 0,且一条约束只能刻画两个变量之间的一个关系。

在我们使用抽象域来进行程序分析时,一般会采用 over-approximation(上近似),也就是说要把程序状态都包在里面,以防有所遗漏。我们来直观解释下,比如对于下面这个图,每一个蓝色的小十字叉代表了这个程序的一个具体状态,那用我们刚才列举的这些抽象域去包住程序状态时,在几何上就需要把这些蓝色的十字叉给包进来。如果我们用多面体抽象域,那么对应的二维形状就是一个多边形。我们用图中这个深绿色的多边形就可以把所有十字叉都包进来。假设图中外侧的红色的地方表示这个程序会出错,比如说会出现数组越界、除零、整数上溢等之类的错误。我们会发现这个程序的所有的状态都被这个多边形包住了,而且这个多边形跟这个红色的区域并没有相交,那也就是说,我们用多面体抽象域证明了在这个程序点处这个程序是不会出错的。

接下来,我们换成区间抽象域,区间抽象域对应地在平面上就是个矩形。这个时候,我们会发现绿色矩形和红色区域有交集。那么,程序分析时,我们拿到区间分析的结果就会报警,说这个程序状态在这个程序点处可能会有错误。然而,实际上我们会发现在这个相交的区域里面,并没有包括真正的具体程序状态,也就说蓝色的十字叉并没有出现在红绿相交区域里。换而言之,用区间分析得到的这个报警,是一个误报,是虚假报警,而实际上程序是不会出错的。因此,用(上近似)抽象解释做程序分析时,没有漏报,但是可能会存在误报。
已有数值抽象域,大部分采用约束的 conjunction(合取) 作为约束表示,都只能表达几何上凸的形态,存在凸性局限性(会导致误报),不能表达析取性质。但是程序中会有很多的析取的行为。比如,if 本身其实就是一个 disjunction,所以我们用已有的数值抽象域去分析程序的时候,会有很多因为凸性的局限性导致出现一些误报。
针对凸性局限性,我们设计并实现了一些 非凸 的数值抽象域,来提高抽象域对析取的表达能力。所谓非凸,如下图右侧所示,在把一个个表示具体状态的十字叉包住时,我们会发现非凸抽象域的区域比左侧用的多面体会小很多,至少我们可以知道原点没有出现在程序状态里。然后,我们用这个非凸抽象域去分析程序的时候,因为域元素包含的面积或体积更小了,分析就更加精确,误报更少。

这方面工作的主要技术思想是,我们把原来采用的传统线性不等式,变拓展成了带区间系数的线性不等式,或者把原来只关注 x x x, y y y 这些变量间关系拓展为关注 x x x、 ∣ x ∣ |x| ∣x∣、 y y y、 ∣ y ∣ |y| ∣y∣ 之间的关系,即我们利用这种绝对值函数来描述一些非凸的程序行为。
举个栗子
举个简单的例子来讲,传统八边形抽象域域元素采用的约束形式是 ± x ± y ≤ c \pm x \pm y \leq c ±x±y≤c,即它只能描述两个变量 x x x 和 y y y 之间的这种受限形式关系,其中变量系数只能是 + 1 +1 +1, − 1 -1 −1 或者 0 0 0。那么,我们可以对它简单做一些扩展,比如考虑允许其中一个变量带绝对值的情形,还可以进一步考虑允许两个变量都带绝对值的情形。按照这种方式扩展之后,就只会存在下面所列的这几种可能的约束表示:
- 八边形约束: ± x ± y ≤ a \pm x \pm y \le a ±x±y≤a
- 仅含一个变量的绝对值: − ∣ x ∣ ± y ≤ b , ± x − ∣ y ∣ ≤ c -|x|\pm y \le b,\pm x - |y| \le c −∣x∣±y≤b,±x−∣y∣≤c
- 含两变量的绝对值: − ∣ x ∣ − ∣ y ∣ ≤ d -|x|-|y|\le d −∣x∣−∣y∣≤d
按照这种思路,用扩展之后的约束形式去描述程序的行为,或者作为抽象域的一个域表示,就可以刻画一些非凸的性质了,而传统的八边形域能刻画的仅是凸的性质。

简单而言,在几何上,“凸” 意味着如果对于上图中一个图形绿色区域内的两个点,其连线上的点也都在这个区域里面,那么这个图形就是一个凸的,这是凸在几何上的性质。我们可以利用绝对值函数描述一个非凸的区域,比如 − ∣ x ∣ ≤ 1 -|x|\le 1 −∣x∣≤1,即 ∣ x ∣ ≥ 1 |x| \ge 1 ∣x∣≥1,所描述的程序状态集合,在几何上就是非凸的。直观上,抽象域元素对应的程序状态的面积越小,那么分析精度就会更高。
# 我们的工作
前面,我们通过一个简单例子来给大家介绍在设计数值抽象域时,如何面向我们需要解决的问题来设计一些新型的或者是适合这个问题的抽象域。其中,关键点是找一种合适的约束表示。
在选择了特定形式约束之后,接下来要考虑的就是,在这个约束形式上,如何设计比较高效的算法来操纵这种约束。比如说怎么实现 join,怎么实现 meet 等等。
我们课题组沿着这个思路,设计实现了一些抽象域,并融到了开源的数值抽象域库 Apron 的主分支里面。Apron 库应该是最早的且开源的数值抽象域库,里面包含了很多经典、常见数值抽象域的实现。我们在设计一些基于抽象解释的程序分析的时候,就可以在 Apron 数值抽象域库中,选择并调用对应的抽象域的接口,来实现自己的分析。
Apron:https://github.com/antoinemine/apron

# 数值程序分析 #
# 数值程序分析工具 Numpa
接下来给大家介绍一下,在抽象域设计好后,怎么实现一些程序分析。
我们课题组实现了一个数值程序分析工具 Numpa。下图是 Numpa 的框架示意,这同时也是一个典型的抽象解释工具的框架。很多抽象解释工具基本上也是采用这种框架。

步骤说明
如下所示,对于给定的一个某种语言编写的 待分析程序(目前我们的这个工具支持 C 程序):
- 先通过编译前端将它的表示 转化为一个中间表示,这个中间表示其实本质上是一个 图的描述,刻画的是一个迁移系统,同时也对应到了待分析程序的语义方程。
- 接下来是一个抽象解释里面的 不动点迭代求解器,它会不断 调用抽象域库(也就是 Apron)里面的抽象域的一些操作,比如遇到赋值语句,就调用抽象域里面赋值语句对应的赋值迁移函数,控制流汇合(control-flow join)语句,就调用抽象域里对应的 join 操作。
- 当分析过程迭代稳定之后,即达到不动点之后,工具就会输出数值不变式。
当然,为了处理指针,我们也设计了一个 指向抽象域,以得到每个指针变量的指向信息,包括其基地址信息,以及关于基地址的偏移量的信息。利用这些分析信息,我们可以检查程序缺陷并报警。
工具支持
我们的工具是面向 C 程序的,支持常见的数据类型和语法结构,如整型、浮点型及之间的类型转换,数组(一维/二维数组、指针数组)、静态指针及指针算术,结构体及结构体数组等。当然,也有一些我们目前暂不支持,如函数指针。
同时,我们还考虑了一些特定领域软件的特点,如嵌入式软件中常见的中断分析。
从工具的输出角度,Numpa 支持输出:
- 数值不变式,即数值变量间的约束关系,以及变量的取值范围
- 指针变量的指向信息:包括可能指向的基地址集合,以及相对于基地址的偏移量
- 报警类型:基于不变式信息,Numpa 可以检查一些常见的运行时错误,如未初始化、算术溢出、除零错、数组越界、空指针解引用、死代码、数学函数输入不在定义域内(如负数开平方根)等
举个栗子
如下代码示例,我们会在进入循环后的程序点 4 处,得出指针变量 p 的基地址是数组 A 的名字,其基地址的偏移量与 x 是两倍的关系,并分析得到 x 的值范围是 [0, 99]。
int A[198];
1 x := 0;
2 p := A;
3 while (x <= 99) do
4 *p := 0; // 数组越界!!!
5 x := x + 1;
6 p := p + 2;
7
done;
这是我们得到的不变式:
p ∈ A , 0 ≤ x ≤ 99 , offset_p = 2 x \begin{aligned} &p \in A, \\ &0 \le x \le 99, \text{offset\_p} = 2x \end{aligned} p∈A,0≤x≤99,offset_p=2x
在这个程序示例的点 4 处,Numpa 可分析得出 x 的值范围为 [0, 99],指针变量 p 关于其基地址(数组 A)的偏移量是 x 的两倍,即能取到 198。按照程序的语义,数组访问下标范围在 [0,197] 间才不会出错,而分析得出可能会访问到 198 的下标位置。因此,程序分析工具会报警,认为在程序点 4 处的赋值语句可能导致数组越界。
工具现状
目前,我们一直在维护这个数值程序分析工具,也在航天等领域中的一些实际程序上开展了实验。当然,工具本身还有很大的提升空间。
目前,这个工具面临的主要问题是:
- 误报相对较多。
- 且,如果我们用非关系型的抽象域,比如用区间,我们分析的规模能够满足要求,但是精度就会比较差,误报也会比较多;但是,当我们用关系型抽象域的时候,一旦变量过多,尤其采用精度较高的过程间分析方法时,工具的可扩展性就会比较差,因为关系型抽象域的可扩展性跟变量的维度紧密相关。
- 另外,当我们使用这个工具来分析一些实际的开源软件时,会遇到一些比较复杂的数据结构。比如,对于一些指针形态相关的操作,会增加了内存模型的复杂性,在分析过程中不易处理。
# 结合抽象域与 SMT 的程序分析
为了弥补 抽象解释分析精度不足 的问题,我们一个简单的想法是 利用 SMT 公式来提高分析精度,结合抽象域和 SMT 来开展分析。
抽象域 vs SMT
我们知道,SMT 公式的表达能力比较强,尤其是它能表达析取,当然它的计算代价也比较高。另外一个问题是,用 SMT 来分析程序的时候,如何处理循环?当然,一个简单策略时是循环展开,但是我们不知道循环应该展开多少次才能覆盖全程序行为。目前,在 SMT 上面没有特别合适的加宽算子,使得在抽象解释框架下在 SMT 公式表示的程序状态上开展不动点迭代,难以保证不动点迭代的终止性。
| 抽象域 | 可满足性模理论(SMT) | |
|---|---|---|
| 表达能力(精度) | 受限,尤其析取表达能力不足 | SMT 公式表达能力强(析取,量词等) |
| 计算代价 | 低 | 高 |
| 迭代收敛性(处理循环) | 加宽/变窄算子 | 尚无合适的加宽/变窄算子 |
具体方法
为了将 SMT 和抽象域结合起来开展程序分析,我们借鉴了软件模型检验中 程序分块编码技术,开展块级程序分析 2。
- 首先,我们对程序进行了分块。即,每个程序块作为一个单独的迁移函数;
- 在程序块内采用 SMT 来刻画公式(块内精度比较高);在程序块间或者遇到循环的时候,将 SMT 公式转化为抽象域表示(循环体会被看做一个程序块,采用 SMT 编码;在循环头处会将 SMT 转化为抽象域表示。从而,在循环头处,我们可以利用抽象域上的加宽操作,来保证不动点迭代的终止性)。

通过上述这种方法,我们可以提高程序分析的精度,但其中用到了一个关键技术:SMT-opt。我们将 SMT 公式转化为抽象域表示时,SMT 公式里面是带析取的,但是抽象域表示中是没有析取的,所以我们需要 符号化抽象技术,将 SMT 公式转换为抽象域表示。
我们可以用类似线性规划的 SMT 规划技术(或者叫 SMT 最优化技术),将一个 SMT 公式转化为一个带模板的抽象域的表示。
如下图示,我们目前用的是 SMT 求解器 Z3 中的 vZ 模块,它可以支持 SMT 规划。但这个方法的计算代价还是挺大的,会影响到程序分析效率。

这一方面最新的研究进展,是姚培森博士等人发表在 OOPSLA 2021 上的工作 3,提出了一种更高效的符号化抽象技术。
# 数值程序分析应用 #
基于数值程序分析技术,除了利用数值程序分析技术来检查运行时错误,我们还可以做一些应用分析。
# 软件资源使用情况分析
关注的问题
比如分析 程序中资源使用量的上界。程序在运行过程中,会使用到很多类型的软件资源(堆内存、文件句柄、网络套接字、用户自定义资源等)。

资源消耗量上界分析的结果,有助于在资源受限的条件下(如在嵌入式系统中),帮助指导软件的设计、部署、配置;同时,我们也可以利用资源消耗量上界分析技术来检测,未受控资源消耗缺陷等资源使用相关缺陷。实际上,有不少 CWE 跟资源使用相关:
– CWE-400: Uncontrolled Resource Consumption
– CWE-769: File Descriptor Exhaustion
– CWE-774: Allocation of File Descriptors or Handles Without Limits or Throttling
– CWE-775: Missing Release of File Descriptor or Handle after Effective Lifetime
技术途径
我们分析资源消耗量上界的主要思路是 4,把资源使用量上界分析问题转化成数值程序分析问题,如下图所示:

简单来讲,对于给定的待分析程序,
STEP 1:首先,对源程序进行 插桩转换,通过引入一些辅助整型变量来建模资源的消耗情况;
STEP 2:接下来,因为我们关注的其实就是新引入的这些辅助变量的值范围,而程序中有很多代码跟资源使用无关,因此我们可以拿着这些变量去 对程序切片;
STEP 3:最后,基于抽象解释技术来分析 被提取出来的数值程序,可以得到一些描述资源使用量的辅助变量间的数值关系,从而获得资源使用量上界的估计。

# 神经网络架构中的数值缺陷检测
关注的问题
现在也有不少工作用抽象解释来做神经网络的验证,我下面介绍的这个工作其实不是来做神经网络模型层面验证的,而是依然属于程序层面的。
我们用深度学习框架(如 Tensorflow)写的程序中会包含大量数值运算,其中可能存在数值缺陷,从而需要相应的检测技术。


技术途径
下面介绍的是我和北大的熊英飞老师、谢涛老师和他们的团队,还有港科大的张成志老师一起合作的一项工作:张量抽象 & 数值抽象 5。
用 Tensorflow 写的程序,会要拿很多的数据来进行训练,而在训练的过程中也执行很多数值运算,其中也会调用很多数值函数。那么,数值运算过程中可能会出现一些如 “NAN” 或 “INF” 值,这些值往后传播可能导致程序缺陷。

我们这项工作大体的思路还是用 抽象解释 来做分析。因为这类程序里面有很多数值运算,所以我们可以做 数值抽象,进而获得程序中变量的值范围。但,因为这类程序里面涉及很多的张量(张量可以简单理解为传统程序里面的数组,或者说高维的数组),我们就需要对这些数组或者张量做一些特殊分析和处理。
我们用的方法是 基于张量划分的张量抽象技术。数值抽象用的是比较简单的抽象域,我们用了区间域和线性等式域,这两个数值抽象域都是经典的抽象域,相对来说也是比较轻量级的数值抽象域,从而得到变量值的范围:
- 张量抽象(张量划分)
- 数值抽象(结合区间抽象与线性等式抽象)

我们的方法将张量抽象和数值抽象结合起来,比如,可以得到张量划分后的每一部分的取值范围。

# 总结 #
今天,一方面给大家介绍了用抽象解释怎么来生成数值不变式。因为抽象解释框架本身比较成熟了,其中最重要的就是设计比较适合目标问题的数值抽象域。我们用抽象域来进行程序分析的时候,可能会碰到一些问题,比如说误报比较多。那么怎么来提高分析的精度呢?结合例子,我给大家简单介绍了下我们结合 SMT 和抽象域来提高分析精度的思路。
另一方面,基于数值程序分析,我们可以开展一些应用分析。除了缺陷检测,我们可以基于数值程序分析来分析程序资源的使用量上界(类似于 WCET 分析)。此外,除了传统的程序(如 C 程序),深度学习相关程序代码也包含大量的数值运算,也可能出现一些数值缺陷,那么怎么用抽象解释来检测这一类程序的缺陷呢?除了数值不变式,这类程序还涉及到一些新的结构,如张量,这就需要一些新的抽象技术。
- 基于抽象解释的数值不变式生成
- 数值抽象域的设计
- 数值程序分析
- 结合数值抽象域与SMT的块级程序分析
- 软件中资源使用量上界分析
- 神经网络架构中的数值缺陷检测
相关论文推荐
数值程序分析:
- Tengbin Wang, Liqian Chen, Taoqing Chen, Guangsheng Fan, Ji Wang. Making Rigorous Linear Programming Practical for Program Analysis. In CP 2021.
- Banghu Yin, Liqian Chen, Jiangchao Liu, Ji Wang. Hierarchical Analysis of Loops With Relaxed Abstract Transformers. IEEE Transactions on Reliability. 2020.
数值程序验证:
- Pengfei Yang, Jianlin Li, Jiangchao Liu, Cheng-Chao Huang, Renjue Li, Liqian Chen, Xiaowei Huang, Lijun Zhang. Enhancing Robustness Verification for Deep Neural Networks via Symbolic Propagation. Formal Aspects of Computing, 2021.
- Banghu Yin, Liqian Chen, Jiangchao Liu, Ji Wang, Patrick Cousot. Verifying Numerical Programs via Iterative Abstract Testing. In SAS 2019.
- Jiangchao Liu, Liqian Chen and Xavier Rival. Automatic Verification of Embedded System Code Manipulating Dynamic Structures Stored in Contiguous Regions. IEEE TCAD, 2018.
参考
P. Cousot and R. Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Conference Record of the Fourth Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, pages 238–252, Los Angeles, California, 1977. ACM Press, New York, NY. ↩︎
Jiahong Jiang, Liqian Chen, Xueguang Wu and Ji Wang.Block-wise abstract interpretation by combining abstract domains with SMT. In VMCAI 2017. ↩︎
Program Analysis via Efficient Symbolic Abstraction. Peisen Yao, Qingkai Shi, Heqing Huang, and Charles Zhang. The 36th ACM SIGPLAN Conference on Objected Oriented Programming, Systems, Languages, and Applications, OOPSLA 2021. ↩︎
Guangsheng Fan, Taoqing Chen, Banghu Yin, Liqian Chen, Tengbin Wang, Ji Wang. Static Bound Analysis of Dynamically Allocated Resources for C Programs. In ISSRE 2021. ↩︎
Yuhao Zhang, Luyao Ren, Liqian Chen, Yingfei Xiong, Shing-Chi Cheung, Tao Xie. Detecting Numerical Bugs in Neural Network Architectures. In FSE 2020. (ACM SIGSOFT Distinguished Paper Award). ↩︎




![[python入门㊷] - python存储数据](https://img-blog.csdnimg.cn/333cef0e1ba041e08fa1105a1df15922.png)