前言:
激活函数与loss的梯度
PyTorch 提供了Auto Grad 功能,这里系统讲解一下
torch.autograd.grad系统的工作原理,了解graph 结构
目录:
1: require_grad = False
2: require_grad =True
3: 多层bakcward 原理
4: index 的作用
5: 更复杂的例子
一 require_grad = False
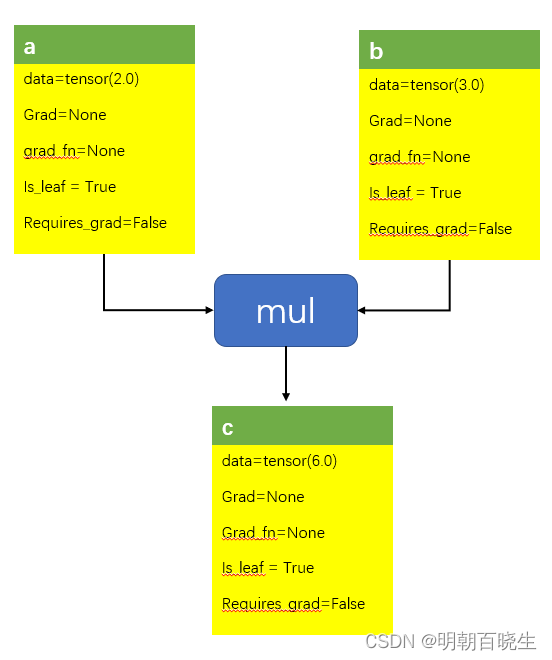
我们创建了两个tensor :a,b
c=a*b
tensor 会为Tensor a,b,c 内部自动分配一些属性
data: 当前的数据
grad: 保存当前的梯度,非leaf 不保存。retain_graid
grad_fn: 指向backward graph中的Node
is_leaf : 是否为graph 中的leaf
requires_grad: 为True 的时候才会创建backwards grad
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 1 17:34:37 2023
@author: chengxf2
"""
import torch
def autograd():
a = torch.tensor(2.0,requires_grad=False)
b = torch.tensor(3.0,requires_grad=False)
c =a*b
grad_a =torch.autograd.grad(c,[a])
print(a,grad_a)
autograd()
运行后回直接报错
因为 a 的require_grad 为 False,
所以没有对应的grad_fn 指向backwards graph
二 require_grad= True
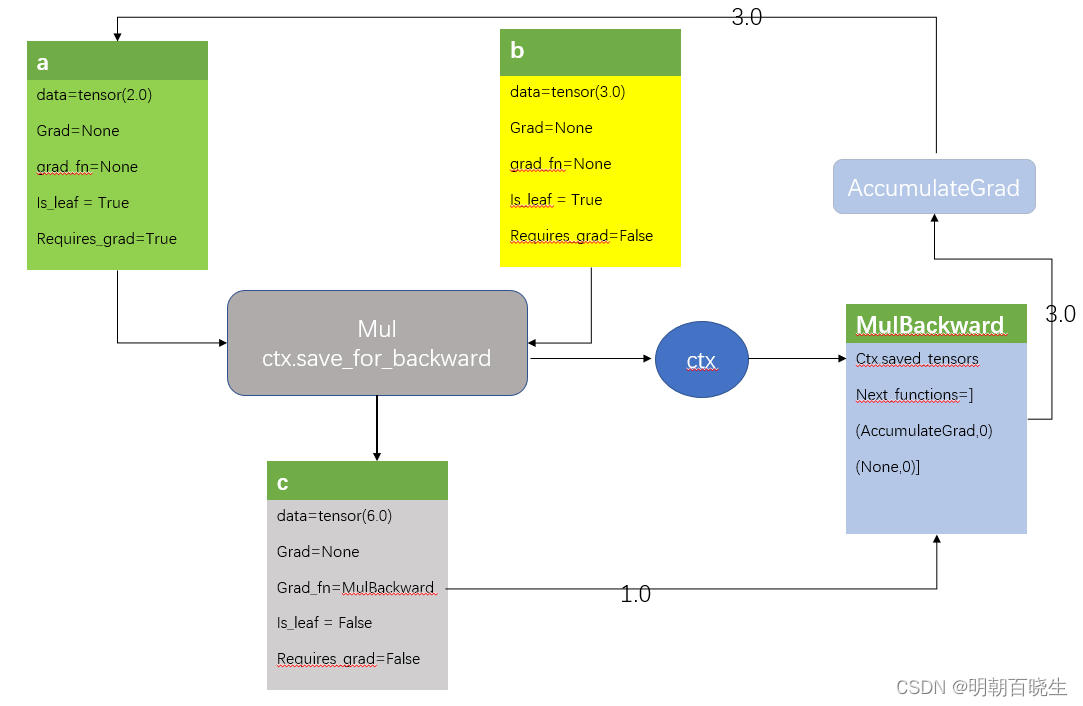
Mul 函数 会创建一个上下文保存当前输入的Tensor:a,b
当a require_grad属性 设置成True
Tensor C的三个属性发生了变化
grad_fn = MulBackward
is_leaf = False
require_grad = True
MulBackward 的input 是ctx中保存的tensor,跟输入的a,b分别关联
是tuple 组成的list
tuple的结构是[Function, index]
[Accumulated Grad,0] 跟 Tensor a 关联
[None ,0] 跟 Tensor b 关联
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 1 17:34:37 2023
@author: chengxf2
"""
import torch
def autograd():
a = torch.tensor(2.0,requires_grad=True)
b = torch.tensor(3.0,requires_grad=False)
c =a*b
grad_a =torch.autograd.grad(c,[a])
print(grad_a)
autograd()
三 多层bakcward 原理
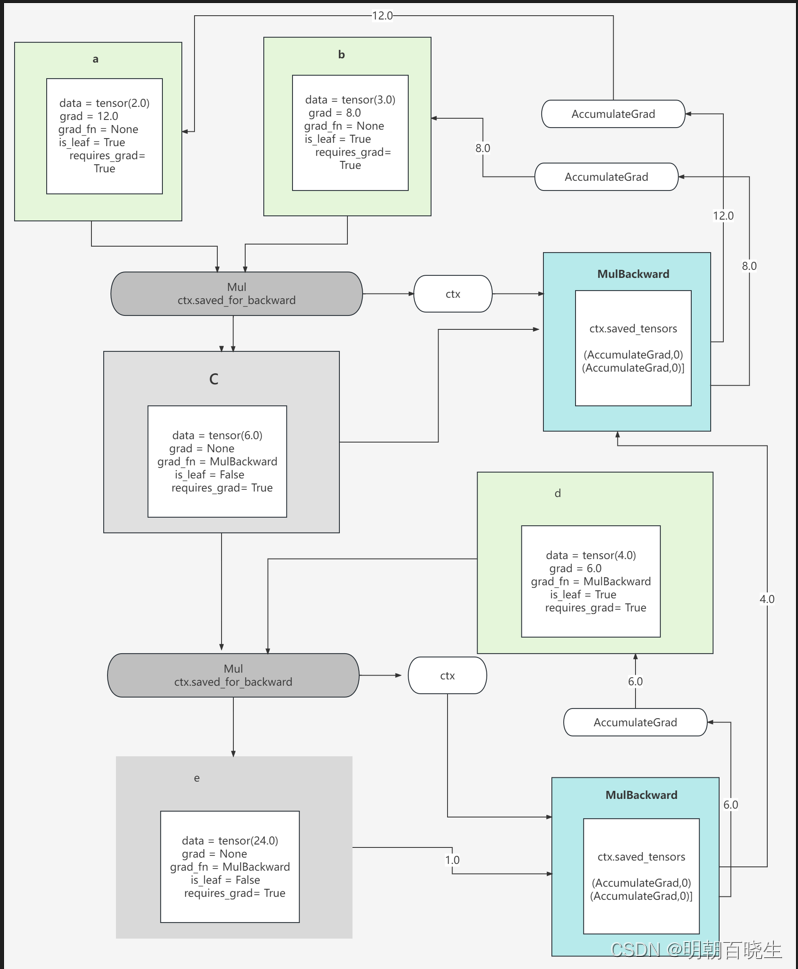
c=a*b
e=c*d
其中因为c 是intermediate node, 非leaf,当
backward时候,不保存grad,直接把梯度传递到 其内部的grad_fn(MulBackward)
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 1 17:34:37 2023
@author: chengxf2
"""
import torch
def autograd():
a = torch.tensor(2.0,requires_grad=True)
b = torch.tensor(3.0,requires_grad=True)
d = torch.tensor(4.0,requires_grad=True)
c =a*b
e =c*d
grad_a,grad_b,grad_d =torch.autograd.grad(e,[a,b,d])
print("grad_a: %d grad_b: %d grad_d: %d"%(grad_a,grad_b,grad_d))
autograd()

为了防止tensor 运行期间发生变化增加了 _version 保护

四 index 的作用
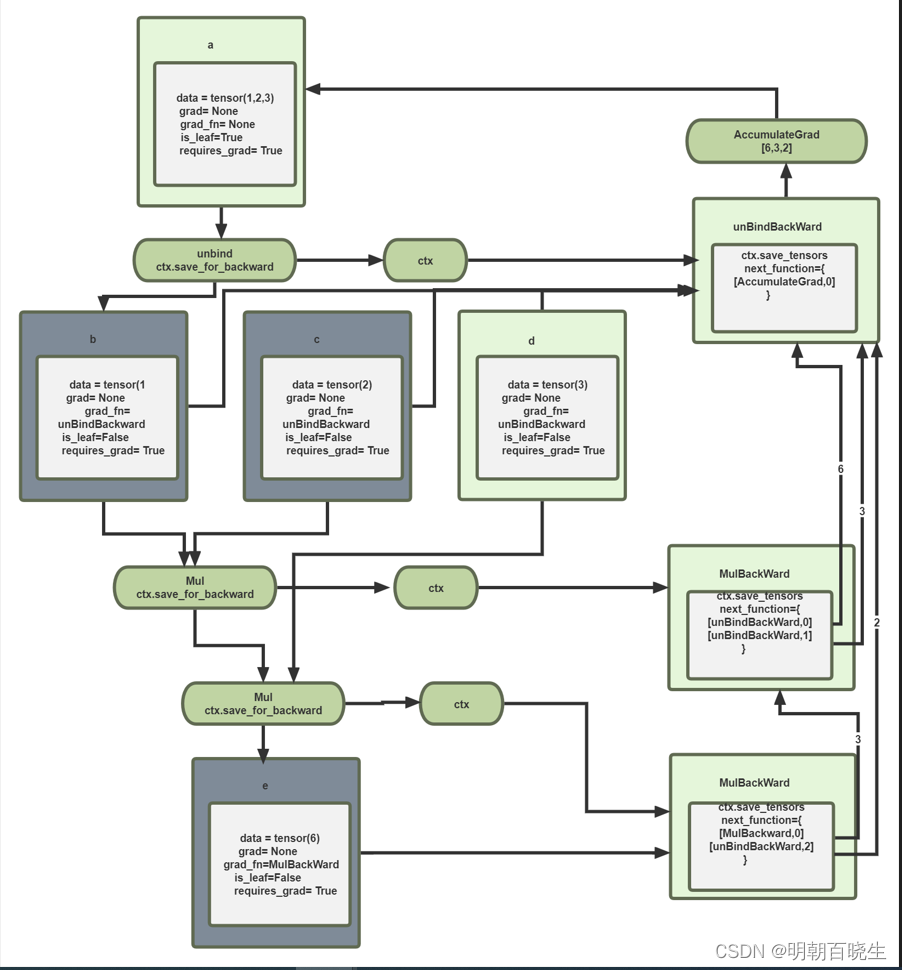
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 1 17:34:37 2023
@author: chengxf2
"""
import torch
def autograd():
a = torch.tensor([1.0,2.0,3.0],requires_grad=True)
b,c,d= a.unbind()
e =b*c*d
grad_a =torch.autograd.grad(e,[a])
print("grad_a: ",grad_a)
autograd()

index 主要用于指向对应的backward graph 中的input的tensor索引
五 更复杂的例子
c= a*b
c.require_grad= True
e = c*d
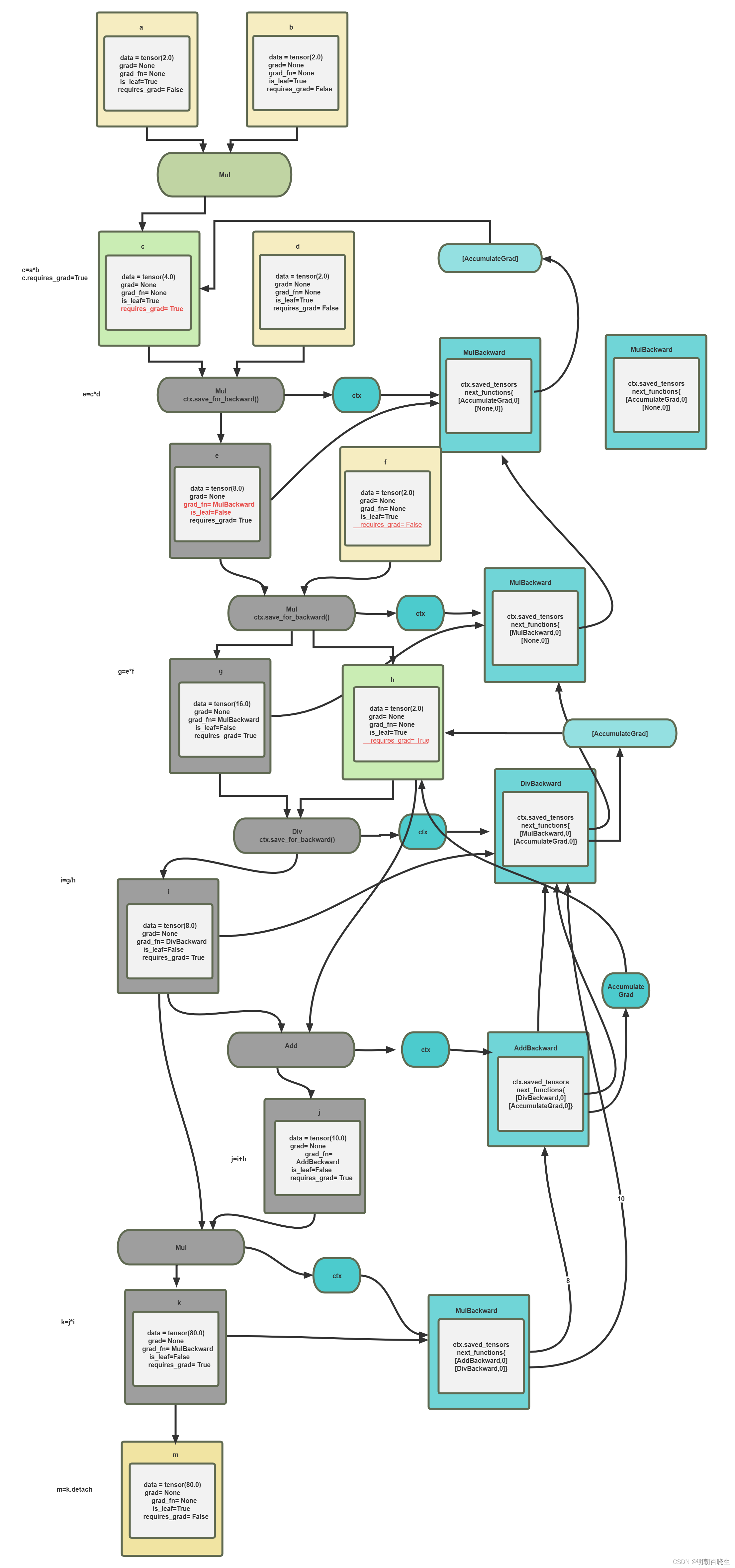
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 1 17:34:37 2023
@author: chengxf2
"""
import torch
def Forward():
a = torch.tensor(2.0,requires_grad=False)
b = torch.tensor(2.0, requires_grad=False)
d = torch.tensor(2.0, requires_grad=False)
f = torch.tensor(2.0, requires_grad=False)
h = torch.tensor(2.0, requires_grad=True)
c= a*b
print("\n c:",c)
c.requires_grad=True
e= c*d
print("\n e ",e)
g= e*f
print("\n g ",g)
i =g/h
print("\n i ",i)
j = i+h
k=j*i
print("\n j ",j)
print("\n k ",k)
grad_c = torch.autograd.grad(k,[c])
print("\n grad_c ",grad_c)
m=k.detach()
print("m ",m)
Forward()
输出:

i.reatin_graid(): 保证当前的梯度












![[Linux]-Ansible](https://img-blog.csdnimg.cn/0e79673580104bad8d3ac0e160008d9a.png#pic_center)