4.1 谈谈MyBatis和JPA的区别
参考答案
ORM映射不同:
MyBatis是半自动的ORM框架,提供数据库与结果集的映射;
JPA(默认采用Hibernate实现)是全自动的ORM框架,提供对象与数据库的映射。
可移植性不同:
JPA通过它强大的映射结构和HQL语言,大大降低了对象与数据库的耦合性;
MyBatis由于需要写SQL,因此与数据库的耦合性直接取决于SQL的写法,如果SQL不具备通用性而用了很多数据库的特性SQL的话,移植性就会降低很多,移植时成本很高。
日志系统的完整性不同:
JPA日志系统非常健全、涉及广泛,包括:SQL记录、关系异常、优化警告、缓存提示、脏数据警告等;
MyBatis除了基本的记录功能外,日志功能薄弱很多。
SQL优化上的区别:
由于Mybatis的SQL都是写在XML里,因此优化SQL比Hibernate方便很多。
而Hibernate的SQL很多都是自动生成的,无法直接维护SQL。虽有HQL,但功能还是不及SQL强大,见到报表等复杂需求时HQL就无能为力,也就是说HQL是有局限的Hhibernate虽然也支持原生SQL,但开发模式上却与ORM不同,需要转换思维,因此使用上不是非常方便。总之写SQL的灵活度上Hibernate不及Mybatis。
4.2 MyBatis输入输出支持的类型有哪些?
参考答案
parameterType:
MyBatis支持多种输入输出类型,包括:
- 简单的类型,如整数、小数、字符串等;
- 集合类型,如Map等;
- 自定义的JavaBean。
其中,简单的类型,其数值直接映射到参数上。对于Map或JavaBean则将其属性按照名称映射到参数上。
4.3 MyBatis里如何实现一对多关联查询?
参考答案
一对多映射有两种配置方式,都是使用collection标签实现的。在此之前,为了能够存储一对多的数据,需要在主表对应的实体类中增加集合属性,用于封装子表对应的实体类。
嵌套查询:
- 通过select标签定义查询主表的SQL,返回结果通过reusltMap进行映射。
- 在resultMap中,除了映射主表属性,还要通过collection标签映射子表属性,该标签需包含如下内容:
-
- 通过property属性指定子表属性名;
- 通过javaType属性指定封装子表属性的集合类型;
- 通过ofType属性指定子表的实体类型;
- 通过select属性指定查询子表所依赖的SQL,这个SQL需单独定义,内部包含查询子表的语句。
嵌套结果:
- 通过select标签定义关联查询主表和子表的SQL,返回结果通过resultMap进行映射。
- 在resultMap中,除了映射主表属性,还要通过collection标签映射子表属性,该标签需包含如下内容:
-
- 通过property属性指定子表属性名;
- 通过ofType属性指定子表的实体类型;
- 通过result子标签定义子表字段和属性的映射关系。
4.4 MyBatis中的$和#有什么区别?
参考答案
使用#设置参数时,MyBatis会创建预编译的SQL语句,然后在执行SQL时MyBatis会为预编译SQL中的占位符(?)赋值。预编译的SQL语句执行效率高,并且可以防止注入攻击。
使用$设置参数时,MyBatis只是创建普通的SQL语句,然后在执行SQL语句时MyBatis将参数直接拼入到SQL里。这种方式在效率、安全性上均不如前者,但是可以解决一些特殊情况下的问题。例如,在一些动态表格(根据不同的条件产生不同的动态列)中,我们要传递SQL的列名,根据某些列进行排序,或者传递列名给SQL都是比较常见的场景,这就无法使用预编译的方式了。
4.5 既然 不安全,为什么还需要 不安全,为什么还需要 不安全,为什么还需要,什么时候会用到它?
参考答案
它可以解决一些特殊情况下的问题。例如,在一些动态表格(根据不同的条件产生不同的动态列)中,我们要传递SQL的列名,根据某些列进行排序,或者传递列名给SQL都是比较常见的场景,这就无法使用预编译的方式了。
4.6 MyBatis的xml文件和Mapper接口是怎么绑定的?
参考答案
是通过xml文件中, 根标签的namespace属性进行绑定的,即namespace属性的值需要配置成接口的全限定名称,MyBatis内部就会通过这个值将这个接口与这个xml关联起来。
4.7 MyBatis分页和自己写的分页哪个效率高?
参考答案
自己写的分页效率高。
在MyBatis中,我们可以通过分页插件实现分页,也可以通过分页SQL自己实现分页。其中,分页插件的原理是,拦截查询SQL,在这个SQL基础上自动为其添加limit分页条件。它会大大的提高开发的效率,但是无法对分页语句做出有针对性的优化,比如分页偏移量很大的情况,而这些在自己写的分页SQL里却是可以灵活实现的。
4.8 了解MyBatis缓存机制吗?
参考答案
MyBatis的缓存分为一级缓存和二级缓存。
一级缓存:
一级缓存也叫本地缓存,它默认会启用,并且不能关闭。一级缓存存在于SqlSession的生命周期中,即它是SqlSession级别的缓存。在同一个 SqlSession 中查询时,MyBatis 会把执行的方法和参数通过算法生成缓存的键值,将键值和查询结果存入一个Map对象中。如果同一个SqlSession 中执行的方法和参数完全一致,那么通过算法会生成相同的键值,当Map 缓存对象中己经存在该键值时,则会返回缓存中的对象。
二级缓存:
二级缓存存在于SqlSessionFactory 的生命周期中,即它是SqlSessionFactory级别的缓存。若想使用二级缓存,需要在如下两处进行配置。
在MyBatis 的全局配置settings 中有一个参数cacheEnabled,这个参数是二级缓存的全局开关,默认值是true ,初始状态为启用状态。
MyBatis 的二级缓存是和命名空间绑定的,即二级缓存需要配置在Mapper.xml 映射文件中。在保证二级缓存的全局配置开启的情况下,给Mapper.xml 开启二级缓存只需要在Mapper. xml 中添加如下代码:
二级缓存具有如下效果:
- 映射语句文件中的所有SELECT 语句将会被缓存。
- 映射语句文件中的所有时INSERT 、UPDATE 、DELETE 语句会刷新缓存。
- 缓存会使用Least Rece ntly U sed ( LRU ,最近最少使用的)算法来收回。
- 根据时间表(如no Flush Int erv al ,没有刷新间隔),缓存不会以任何时间顺序来刷新。
- 缓存会存储集合或对象(无论查询方法返回什么类型的值)的1024 个引用。
- 缓存会被视为read/write(可读/可写)的,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
5.1 cookie和session的区别是什么?
参考答案
- 存储位置不同:cookie存放于客户端;session存放于服务端。
- 存储容量不同:单个cookie保存的数据<=4KB,一个站点最多保存20个cookie;而session并没有上限。
- 存储方式不同:cookie只能保存ASCII字符串,并需要通过编码当时存储为Unicode字符或者二进制数据;session中能够存储任何类型的数据,例如字符串、整数、集合等。
- 隐私策略不同:cookie对客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以它是不安全的;session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。
- 生命周期不同:可以通过设置cookie的属性,达到cookie长期有效的效果;session依赖于名为JSESSIONID的cookie,而该cookie的默认过期时间为-1,只需关闭窗口该session就会失效,因此session不能长期有效。
- 服务器压力不同:cookie保存在客户端,不占用服务器资源;session保管在服务器上,每个用户都会产生一个session,如果并发量大的话,则会消耗大量的服务器内存。
- 浏览器支持不同:cookie是需要浏览器支持的,如果客户端禁用了cookie,则会话跟踪就会失效;运用session就需要使用URL重写的方式,所有用到session的URL都要进行重写,否则session会话跟踪也会失效。
- 跨域支持不同:cookie支持跨域访问,session不支持跨域访问。
5.2 cookie和session各自适合的场景是什么?
参考答案
对于敏感数据,应存放在session里,因为cookie不安全。
对于普通数据,优先考虑存放在cookie里,这样会减少对服务器资源的占用。
5.3 请介绍session的工作原理
参考答案
session依赖于cookie。
当客户端首次访问服务器时,服务器会为其创建一个session对象,该对象具有一个唯一标识SESSIONID。并且在响应阶段,服务器会创建一个cookie,并将SESSIONID存入其中。
客户端通过响应的cookie而持有SESSIONID,所以当它再次访问服务器时,会通过cookie携带这个SESSIONID。服务器获取到SESSIONID后,就可以找到与之对应的session对象,进而从这个session中获取该客户端的状态。
5.4 get请求与post请求有什么区别?
参考答案
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST没有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中。
5.5 get请求的参数能放到body里面吗?
参考答案
GET请求是可以将参数放到BODY里面的,官方并没有明确禁止,但给出的建议是这样不符合规范,无法保证所有的实现都支持。这就意味着,如果你试图这样做,可能出现各种未知的问题,所以应该当避免。
5.6 post不幂等是为什么?
参考答案
HTTP方法的幂等性是指一次和多次请求某一个资源应该具有同样的副作用。幂等性属于语义范畴,正如编译器只能帮助检查语法错误一样,HTTP规范也没有办法通过消息格式等语法手段来定义它。
POST所对应的URI并非创建的资源本身,而是资源的接收者。比如:POST http://www.forum.com/articles的语义是在http://www.forum.com/articles下创建一篇帖子,HTTP响应中应包含帖子的创建状态以及帖子的URI。两次相同的POST请求会在服务器端创建两份资源,它们具有不同的URI。所以,POST方法不具备幂等性。
5.7 页面报400错误是什么意思?
参考答案
400状态码标识请求的语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。通常情况下,是本次请求中包含有错误的参数,此时应该排查前端传递的参数。
5.8 请求数据出现乱码该怎么处理?
参考答案
服务端出现请求乱码的原因是,客户端编码与服务器解码方案不一致,可以有如下几种解决办法:
- 将获得的数据按照客户端编码转成BYTE,再将BYTE按服务端编码转成字符串,这种方案对各种请求方式均有效,但是十分的麻烦。
- 在接受请求数据之前,显示声明实体内容的编码与服务器一致,这种方式只对POST请求有效。
- 修改服务器的配置文件,显示声明请求路径的编码与服务器一致,这种方式只对GET请求有效。
5.9 如何在SpringBoot框架下实现一个定时任务?
参考答案
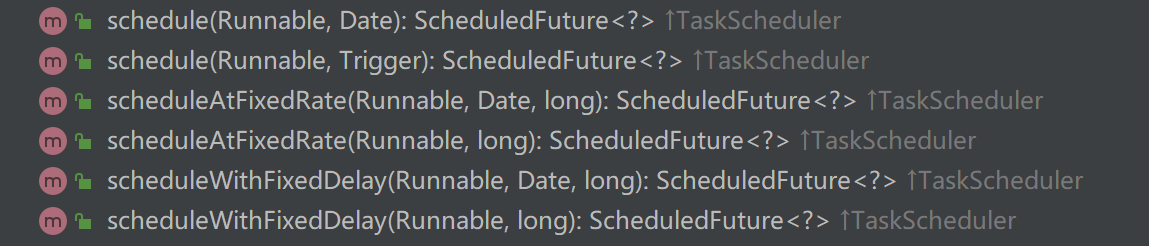
Spring给我们提供了可执行定时任务的线程池ThreadPoolTaskScheduler,该线程池提供了多个可以与执行定时任务的方法,如下图。在Spring Boot中,只需要在配置类中启用线程池注解,就可以直接使用这个线程池了。
5.10 调用接口时要记录日志,该怎么设计?
参考答案
可以定义一个记录日志的组件,并通过AOP将其织入到这个接口的调用中。这种方式对接口无需做任何改造,业务代码中也无需增加任何调用的逻辑,完美地消除了记录日志和业务代码的耦合度。
5.11 了解Spring Boot JPA吗?
参考答案
JPA即Java Persistence API,它是一个基于O/R映射的标准规范。也就是说它指定以了标准规则,不提供实现,软件提供商可以按照标准规范来实现,而使用者只需按照规范中定义的方式来使用,不用和软件提供商打交道。JPA主要实现有Hibernate、EclipseLink、OpenJPA等,我们使用JPA来开发,无论是采用哪一种实现方式都一样。









![[Linux]-Ansible](https://img-blog.csdnimg.cn/0e79673580104bad8d3ac0e160008d9a.png#pic_center)