文章目录
- 概念理解
- 名词解释
- 基本架构
- 工作流程
- Kafka的特性
概念理解
Kafka是分布式的基于发布-订阅消息队列。是一个分布式、支持分区的、多副本的,基于 Zookeeper 协调的分布式消息中间件系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景
名词解释
- 消息生产者(Producer ):向kafka broker发消息的客户端;
- 消息消费者(Consumer ):向kafka broker取消息的客户端;
- 消费者组(Consumer Group):由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。
- Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic;
- Topic :可以理解为一个队列,生产者和消费者面向的都是一个topic;
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
- leader: 每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader;
- follower: 每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时, Kafka通过Zookeeper管理集群配置选举leader,这样某个follower会成为新的leader。
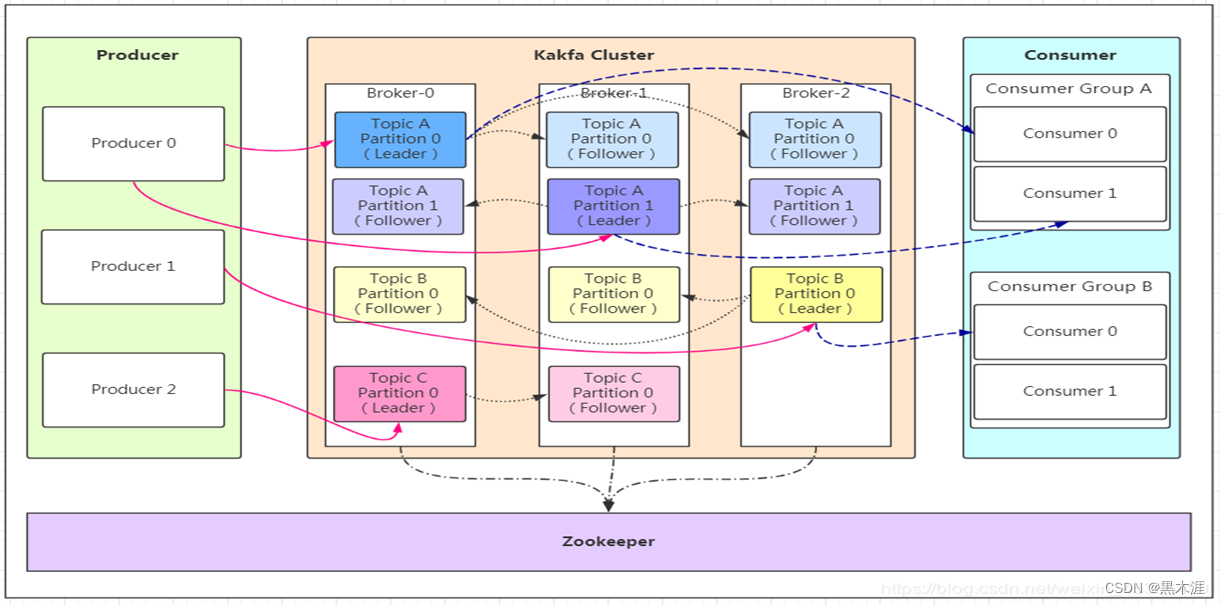
基本架构
工作流程
发送数据
在消息由生产者写入leader后,follower是主动的去leader进行同步的;producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!写入示意图如下:
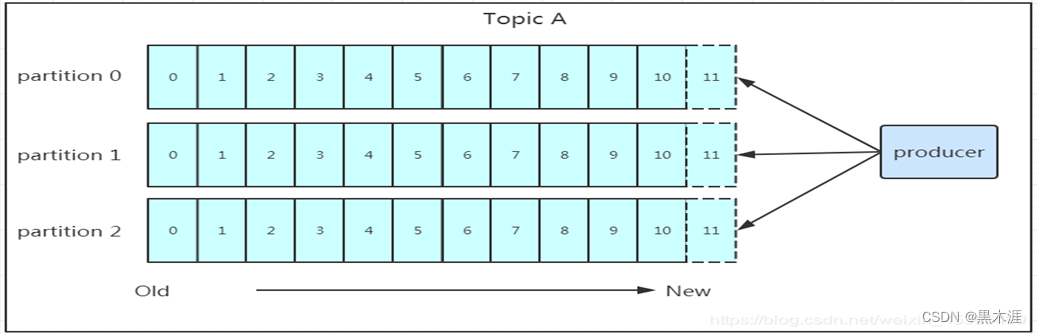
通过刚才的图片看到数据会写入到不同的分区,那kafka为什么要做分区呢?相信大家应该也能猜到,分区的主要目的是:
- 方便扩展
因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。 - 提高并发
以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。 - 保存数据
Producer将数据写入kafka后,集群就需要对数据进行保存了!kafka将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。前面说过了每个topic都可以分为一个或多个partition,Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。 - 消费数据
消息存储在log文件后,消费者就可以进行消费了。在消息队列中通信有两种模式,一种是点对点模式另一种是发布订阅模式。Kafka采用的是发布订阅模式,消费者主动的去kafka集群拉取消息,与生产者(producer)相同的是,消费者在拉取消息的时候也是找leader去拉取。多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据。
Kafka的特性
- 高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力; - 可扩展性、持久性、可靠性
kafka 集群支持热扩展;消息被持久化到本地磁盘,并且支持数据备份防止数据丢失; - 容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败); - 高并发,支持数千个客户端同时读写