register ( )
bulkRegister ( int parties)
arriveAndDeregister ( )
public int register ( ) {
return doRegister ( 1 ) ;
}
public int bulkRegister ( int parties) {
if ( parties < 0 )
throw new IllegalArgumentException ( ) ;
if ( parties == 0 )
return getPhase ( ) ;
return doRegister ( parties) ;
}
public int arriveAndDeregister ( ) {
return doArrive ( ONE_DEREGISTER ) ;
}
private static final int ONE_ARRIVAL = 1 ;
private static final int ONE_PARTY = 1 << PARTIES_SHIFT ;
private static final int ONE_DEREGISTER = ONE_ARRIVAL | ONE_PARTY ;
private static final int EMPTY = 1 ;
private static final int PARTIES_SHIFT = 16 ;
public Phaser ( Phaser parent, int parties) {
}
private final Phaser parent;
Phaser root = new Phaser ( 2 ) ;
Phaser c1 = new Phaser ( root, 3 ) ;
Phaser c2 = new Phaser ( root, 2 ) ;
Phaser c3 = new Phaser ( c1, 0 ) ;
public Phaser ( ) {
this ( null , 0 ) ;
}
public Phaser ( int parties) {
this ( null , parties) ;
}
public Phaser ( Phaser parent) {
this ( parent, 0 ) ;
}
public Phaser ( Phaser parent, int parties) {
if ( parties >>> PARTIES_SHIFT != 0 )
throw new IllegalArgumentException ( "Illegal number of parties" ) ;
int phase = 0 ;
this . parent = parent;
if ( parent != null ) {
final Phaser root = parent. root;
this . root = root;
this . evenQ = root. evenQ;
this . oddQ = root. oddQ;
if ( parties != 0 )
phase = parent. doRegister ( 1 ) ;
}
else {
this . root = this ;
this . evenQ = new AtomicReference < QNode > ( ) ;
this . oddQ = new AtomicReference < QNode > ( ) ;
}
this . state = ( parties == 0 ) ? ( long ) EMPTY :
( ( long ) phase << PHASE_SHIFT ) |
( ( long ) parties << PARTIES_SHIFT ) |
( ( long ) parties) ;
}
private volatile long state;
public final int getPhase ( ) {
return ( int ) ( root. state >>> PHASE_SHIFT ) ;
}
private final Phaser root;
private volatile long state;
private static final int PHASE_SHIFT = 32 ;
private static final int PARTIES_SHIFT = 16 ;
public boolean isTerminated ( ) {
return root. state < 0L ;
}
public int getRegisteredParties ( ) {
return partiesOf ( state) ;
}
private static final int PARTIES_SHIFT = 16 ;
private static int partiesOf ( long s) {
return ( int ) s >>> PARTIES_SHIFT ;
}
public int getUnarrivedParties ( ) {
return unarrivedOf ( reconcileState ( ) ) ;
}
private static final int EMPTY = 1 ;
private static final int UNARRIVED_MASK = 0xffff ;
private static int unarrivedOf ( long s) {
int counts = ( int ) s;
return ( counts == EMPTY ) ? 0 : ( counts & UNARRIVED_MASK ) ;
}
private long reconcileState ( ) {
final Phaser root = this . root;
long s = state;
if ( root != this ) {
int phase, p;
while ( ( phase = ( int ) ( root. state >>> PHASE_SHIFT ) ) !=
( int ) ( s >>> PHASE_SHIFT ) &&
! STATE . weakCompareAndSet
( this , s,
s = ( ( ( long ) phase << PHASE_SHIFT ) |
( ( phase < 0 ) ? ( s & COUNTS_MASK ) :
( ( ( p = ( int ) s >>> PARTIES_SHIFT ) == 0 ) ? EMPTY :
( ( s & PARTIES_MASK ) | p) ) ) ) ) )
s = state;
}
return s;
}
public Phaser ( Phaser parent, int parties) {
if ( parties >>> PARTIES_SHIFT != 0 )
throw new IllegalArgumentException ( "Illegal number of parties" ) ;
int phase = 0 ;
this . parent = parent;
if ( parent != null ) {
final Phaser root = parent. root;
this . root = root;
this . evenQ = root. evenQ;
this . oddQ = root. oddQ;
if ( parties != 0 )
phase = parent. doRegister ( 1 ) ;
}
else {
this . root = this ;
this . evenQ = new AtomicReference < QNode > ( ) ;
this . oddQ = new AtomicReference < QNode > ( ) ;
}
this . state = ( parties == 0 ) ? ( long ) EMPTY :
( ( long ) phase << PHASE_SHIFT ) |
( ( long ) parties << PARTIES_SHIFT ) |
( ( long ) parties) ;
}
private static final int PARTIES_SHIFT = 16 ;
private static final int PHASE_SHIFT = 32 ;
private static final int EMPTY = 1 ;
private final AtomicReference < QNode > ;
private final AtomicReference < QNode > ;
static final class QNode implements ForkJoinPool. ManagedBlocker {
final Phaser phaser;
final int phase;
final boolean interruptible;
final boolean timed;
boolean wasInterrupted;
long nanos;
final long deadline;
volatile Thread thread;
QNode next;
}
private void releaseWaiters ( int phase) {
QNode q;
Thread t;
AtomicReference < QNode > = ( phase & 1 ) == 0 ? evenQ : oddQ;
while ( ( q = head. get ( ) ) != null &&
q. phase != ( int ) ( root. state >>> PHASE_SHIFT ) ) {
if ( head. compareAndSet ( q, q. next) &&
( t = q. thread) != null ) {
q. thread = null ;
LockSupport . unpark ( t) ;
}
}
}
public int arrive ( ) {
return doArrive ( ONE_ARRIVAL ) ;
}
public int arriveAndDeregister ( ) {
return doArrive ( ONE_DEREGISTER ) ;
}
private int doArrive ( int adjust) {
final Phaser root = this . root;
for ( ; ; ) {
long s = ( root == this ) ? state : reconcileState ( ) ;
int phase = ( int ) ( s >>> PHASE_SHIFT ) ;
if ( phase < 0 )
return phase;
int counts = ( int ) s;
int unarrived = ( counts == EMPTY ) ? 0 : ( counts & UNARRIVED_MASK ) ;
if ( unarrived <= 0 )
throw new IllegalStateException ( badArrive ( s) ) ;
if ( STATE . compareAndSet ( this , s, s-= adjust) ) {
if ( unarrived == 1 ) {
long n = s & PARTIES_MASK ;
int nextUnarrived = ( int ) n >>> PARTIES_SHIFT ;
if ( root == this ) {
if ( onAdvance ( phase, nextUnarrived) )
n |= TERMINATION_BIT ;
else if ( nextUnarrived == 0 )
n |= EMPTY ;
else
n |= nextUnarrived;
int nextPhase = ( phase + 1 ) & MAX_PHASE ;
n |= ( long ) nextPhase << PHASE_SHIFT ;
STATE . compareAndSet ( this , s, n) ;
releaseWaiters ( phase) ;
}
else if ( nextUnarrived == 0 ) {
phase = parent. doArrive ( ONE_DEREGISTER ) ;
STATE . compareAndSet ( this , s, s | EMPTY ) ;
}
else
phase = parent. doArrive ( ONE_ARRIVAL ) ;
}
return phase;
}
}
}
private static final int ONE_ARRIVAL = 1 ;
private static final int ONE_PARTY = 1 << PARTIES_SHIFT ;
private static final int PARTIES_SHIFT = 16 ;
private void releaseWaiters ( int phase) {
QNode q;
Thread t;
AtomicReference < QNode > = ( phase & 1 ) == 0 ? evenQ : oddQ;
while ( ( q = head. get ( ) ) != null &&
q. phase != ( int ) ( root. state >>> PHASE_SHIFT ) ) {
if ( head. compareAndSet ( q, q. next) &&
( t = q. thread) != null ) {
q. thread = null ;
LockSupport . unpark ( t) ;
}
}
}
public int awaitAdvance ( int phase) {
final Phaser root = this . root;
long s = ( root == this ) ? state : reconcileState ( ) ;
int p = ( int ) ( s >>> PHASE_SHIFT ) ;
if ( phase < 0 )
return phase;
if ( p == phase)
return root. internalAwaitAdvance ( phase, null ) ;
return p;
}
private int internalAwaitAdvance ( int phase, QNode node) {
releaseWaiters ( phase- 1 ) ;
boolean queued = false ;
int lastUnarrived = 0 ;
int spins = SPINS_PER_ARRIVAL ;
long s;
int p;
while ( ( p = ( int ) ( ( s = state) >>> PHASE_SHIFT ) ) == phase) {
if ( node == null ) {
int unarrived = ( int ) s & UNARRIVED_MASK ;
if ( unarrived != lastUnarrived &&
( lastUnarrived = unarrived) < NCPU )
spins += SPINS_PER_ARRIVAL ;
boolean interrupted = Thread . interrupted ( ) ;
if ( interrupted || -- spins < 0 ) {
node = new QNode ( this , phase, false , false , 0L ) ;
node. wasInterrupted = interrupted;
}
else
Thread . onSpinWait ( ) ;
}
else if ( node. isReleasable ( ) )
break ;
else if ( ! queued) {
AtomicReference < QNode > = ( phase & 1 ) == 0 ? evenQ : oddQ;
QNode q = node. next = head. get ( ) ;
if ( ( q == null || q. phase == phase) &&
( int ) ( state >>> PHASE_SHIFT ) == phase)
queued = head. compareAndSet ( q, node) ;
}
else {
try {
ForkJoinPool . managedBlock ( node) ;
} catch ( InterruptedException cantHappen) {
node. wasInterrupted = true ;
}
}
}
if ( node != null ) {
if ( node. thread != null )
node. thread = null ;
if ( node. wasInterrupted && ! node. interruptible)
Thread . currentThread ( ) . interrupt ( ) ;
if ( p == phase && ( p = ( int ) ( state >>> PHASE_SHIFT ) ) == phase)
return abortWait ( phase) ;
}
releaseWaiters ( phase) ;
return p;
}
public class ForkJoinPool extends AbstractExecutorService {
public static interface ManagedBlocker {
boolean block ( ) throws InterruptedException ;
boolean isReleasable ( ) ;
}
}
static final class QNode implements ForkJoinPool. ManagedBlocker {
static final class QNode implements ForkJoinPool. ManagedBlocker {
final Phaser phaser;
final int phase;
final boolean interruptible;
final boolean timed;
boolean wasInterrupted;
long nanos;
final long deadline;
volatile Thread thread;
QNode next;
QNode ( Phaser phaser, int phase, boolean interruptible,
boolean timed, long nanos) {
this . phaser = phaser;
this . phase = phase;
this . interruptible = interruptible;
this . nanos = nanos;
this . timed = timed;
this . deadline = timed ? System . nanoTime ( ) + nanos : 0L ;
thread = Thread . currentThread ( ) ;
}
public boolean isReleasable ( ) {
if ( thread == null )
return true ;
if ( phaser. getPhase ( ) != phase) {
thread = null ;
return true ;
}
if ( Thread . interrupted ( ) )
wasInterrupted = true ;
if ( wasInterrupted && interruptible) {
thread = null ;
return true ;
}
if ( timed &&
( nanos <= 0L || ( nanos = deadline - System . nanoTime ( ) ) <= 0L ) ) {
thread = null ;
return true ;
}
return false ;
}
public boolean block ( ) {
while ( ! isReleasable ( ) ) {
if ( timed)
LockSupport . parkNanos ( this , nanos) ;
else
LockSupport . park ( this ) ;
}
return true ;
}
}
public class MyClass {
private int count = 0 ;
public void synchronized increment ( ) {
count++ ;
}
public void synchronized decrement ( ) {
count-- ;
}
}
public class MyClass {
private AtomicInteger count = new AtomicInteger ( 0 ) ;
public void add ( ) {
count. getAndIncrement ( ) ;
}
public long minus ( ) {
return count. getAndDecrement ( ) ;
}
}
package main5 ;
import java. util. concurrent. atomic. AtomicInteger ;
public class MyClass extends Thread {
private AtomicInteger count = new AtomicInteger ( 0 ) ;
int i = 0 ;
public void add ( ) {
i++ ;
count. getAndIncrement ( ) ;
}
public long minus ( ) {
i-- ;
return count. getAndDecrement ( ) ;
}
public static class add extends Thread {
MyClass m;
public add ( MyClass target) {
m = target;
}
@Override
public void run ( ) {
m. add ( ) ;
}
}
public static class add1 extends Thread {
MyClass m;
public add1 ( MyClass target) {
m = target;
}
@Override
public void run ( ) {
m. minus ( ) ;
}
}
public static void main ( String [ ] args) throws InterruptedException {
MyClass m = new MyClass ( ) ;
new add ( m) . start ( ) ;
new add1 ( m) . start ( ) ;
new add ( m) . start ( ) ;
new add1 ( m) . start ( ) ;
new add ( m) . start ( ) ;
new add1 ( m) . start ( ) ;
new add ( m) . start ( ) ;
new add1 ( m) . start ( ) ;
new add ( m) . start ( ) ;
new add1 ( m) . start ( ) ;
Thread . sleep ( 5000 ) ;
System . out. println ( m. i) ;
System . out. println ( m. count. get ( ) ) ;
}
}
public final int getAndIncrement ( ) {
return U . getAndAddInt ( this , VALUE , 1 ) ;
}
public final int getAndDecrement ( ) {
return U . getAndAddInt ( this , VALUE , - 1 ) ;
}
private static final jdk. internal. misc. UnsafeU = jdk. internal. misc. Unsafe. getUnsafe ( ) ;
private static final long VALUE = U . objectFieldOffset ( AtomicInteger . class , "value" ) ;
private volatile int value;
@HotSpotIntrinsicCandidate
public final int getAndAddInt ( Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile ( o, offset) ;
} while ( ! weakCompareAndSetInt ( o, offset, v, v + delta) ) ;
return v;
}
@HotSpotIntrinsicCandidate
public final boolean weakCompareAndSetInt ( Object o, long offset,
int expected,
int x) {
return compareAndSetInt ( o, offset, expected, x) ;
}
public final class Unsafe {
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt ( Object o, long offset,
int expected,
int x) ;
}
package java. lang. invoke ;
public abstract class VarHandle {
public final native
@MethodHandle.PolymorphicSignature
@HotSpotIntrinsicCandidate
boolean compareAndSet ( Object . . . args) ;
}
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt ( Object o, long offset,
int expected,
int x) ;
public final int getAndDecrement ( ) {
return U . getAndAddInt ( this , VALUE , - 1 ) ;
}
private static final long VALUE = U . objectFieldOffset ( AtomicInteger . class , "value" ) ;
private static final jdk. internal. misc. UnsafeU = jdk. internal. misc. Unsafe. getUnsafe ( ) ;
package jdk. internal. misc ;
import jdk. internal. HotSpotIntrinsicCandidate ;
import jdk. internal. vm. annotation. ForceInline ;
import java. lang. reflect. Field ;
import java. security. ProtectionDomain ;
public final class Unsafe {
}
public long objectFieldOffset ( Field f) {
if ( f == null ) {
throw new NullPointerException ( ) ;
}
return objectFieldOffset0 ( f) ;
}
public long objectFieldOffset ( Class < ? > , String name) {
if ( c == null || name == null ) {
throw new NullPointerException ( ) ;
}
return objectFieldOffset1 ( c, name) ;
}
private native long objectFieldOffset0 ( Field f) ;
private native long objectFieldOffset1 ( Class < ? > , String name) ;
private static final jdk. internal. misc. UnsafeU = jdk. internal. misc. Unsafe. getUnsafe ( ) ;
private static final long VALUE = U . objectFieldOffset ( AtomicInteger . class , "value" ) ;
private static final long serialVersionUID = 6214790243416807050L ;
private static final jdk. internal. misc. UnsafeU = jdk. internal. misc. Unsafe. getUnsafe ( ) ;
private static final long VALUE = U . objectFieldOffset ( AtomicInteger . class , "value" ) ;
private volatile int value;
if ( ! flag) {
flag = true ;
}
if ( flag == false ) {
flag = true ;
}
if ( compareAndSet ( false , true ) ) {
}
public class AtomicBoolean implements java. io. Serializable{
private static final VarHandle VALUE ;
public final boolean compareAndSet ( boolean expectedValue, boolean newValue) {
return VALUE . compareAndSet ( this ,
( expectedValue ? 1 : 0 ) ,
( newValue ? 1 : 0 ) ) ;
}
}
public class AtomicReference < V > implements java. io. Serializable{
private static final VarHandle VALUE ;
public final boolean compareAndSet ( V expectedValue, V newValue) {
return VALUE . compareAndSet ( this , expectedValue, newValue) ;
}
}
public final native
@MethodHandle.PolymorphicSignature
@HotSpotIntrinsicCandidate
boolean compareAndSet ( Object . . . args) ;
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt ( Object o, long offset,
int expected,
int x) ;
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetLong ( Object o, long offset,
long expected,
long x) ;
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetObject ( Object o, long offset,
Object expected,
Object x) ;
@ForceInline
public final boolean compareAndSetDouble ( Object o, long offset,
double expected,
double x) {
return compareAndSetLong ( o, offset,
Double . doubleToRawLongBits ( expected) ,
Double . doubleToRawLongBits ( x) ) ;
}
@ForceInline
public final boolean compareAndSetBoolean ( Object o, long offset,
boolean expected,
boolean x) {
return compareAndSetByte ( o, offset, bool2byte ( expected) , bool2byte ( x) ) ;
}
@HotSpotIntrinsicCandidate
public final boolean compareAndSetByte ( Object o, long offset,
byte expected,
byte x) {
return compareAndExchangeByte ( o, offset, expected, x) == expected;
}
@HotSpotIntrinsicCandidate
public final byte compareAndExchangeByte ( Object o, long offset,
byte expected,
byte x) {
long wordOffset = offset & ~ 3 ;
int shift = ( int ) ( offset & 3 ) << 3 ;
if ( BE ) {
shift = 24 - shift;
}
int mask = 0xFF << shift;
int maskedExpected = ( expected & 0xFF ) << shift;
int maskedX = ( x & 0xFF ) << shift;
int fullWord;
do {
fullWord = getIntVolatile ( o, wordOffset) ;
if ( ( fullWord & mask) != maskedExpected)
return ( byte ) ( ( fullWord & mask) >> shift) ;
} while ( ! weakCompareAndSetInt ( o, wordOffset,
fullWord, ( fullWord & ~ mask) | maskedX) ) ;
return expected;
}
@HotSpotIntrinsicCandidate
public final boolean weakCompareAndSetInt ( Object o, long offset,
int expected,
int x) {
return compareAndSetInt ( o, offset, expected, x) ;
}
public final boolean compareAndSet ( boolean expectedValue, boolean newValue) {
return VALUE . compareAndSet ( this ,
( expectedValue ? 1 : 0 ) ,
( newValue ? 1 : 0 ) ) ;
}
public final class Double extends Number implements Comparable < Double > {
@HotSpotIntrinsicCandidate
public static native long doubleToRawLongBits ( double value) ;
@HotSpotIntrinsicCandidate
public static native double longBitsToDouble ( long bits) ;
}
@ForceInline
public final boolean compareAndSetDouble ( Object o, long offset,
double expected,
double x) {
return compareAndSetLong ( o, offset,
Double . doubleToRawLongBits ( expected) ,
Double . doubleToRawLongBits ( x) ) ;
}
@ForceInline
public final boolean compareAndSetFloat ( Object o, long offset,
float expected,
float x) {
return compareAndSetInt ( o, offset,
Float . floatToRawIntBits ( expected) ,
Float . floatToRawIntBits ( x) ) ;
}
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetObject ( Object o, long offset,
Object expected,
Object x) ;
public boolean compareAndSet ( V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair < V > = pair;
return
expectedReference == current. reference &&
expectedStamp == current. stamp &&
( ( newReference == current. reference &&
newStamp == current. stamp) ||
casPair ( current, Pair . of ( newReference, newStamp) ) ) ;
}
private boolean casPair ( Pair < V > , Pair < V > ) {
return PAIR . compareAndSet ( this , cmp, val) ;
}
private static final VarHandle PAIR ;
public final native
@MethodHandle.PolymorphicSignature
@HotSpotIntrinsicCandidate
boolean compareAndSet ( Object . . . args) ;
public class AtomicStampedReference < V > {
private static class Pair < T > {
final T reference;
final int stamp;
private Pair ( T reference, int stamp) {
this . reference = reference;
this . stamp = stamp;
}
static < T > Pair < T > of ( T reference, int stamp) {
return new Pair < T > ( reference, stamp) ;
}
}
private static final VarHandle PAIR ;
static {
try {
MethodHandles. Lookup l = MethodHandles . lookup ( ) ;
PAIR = l. findVarHandle ( AtomicStampedReference . class , "pair" ,
Pair . class ) ;
} catch ( ReflectiveOperationException e) {
throw new ExceptionInInitializerError ( e) ;
}
}
private boolean casPair ( Pair < V > , Pair < V > ) {
return PAIR . compareAndSet ( this , cmp, val) ;
}
}
public AtomicStampedReference ( V initialRef, int initialStamp) {
pair = Pair . of ( initialRef, initialStamp) ;
}
public class AtomicMarkableReference < V > {
private static class Pair < T > {
final T reference;
final boolean mark;
private Pair ( T reference, boolean mark) {
this . reference = reference;
this . mark = mark;
}
static < T > Pair < T > of ( T reference, boolean mark) {
return new Pair < T > ( reference, mark) ;
}
}
}
public abstract class AtomicIntegerFieldUpdater < T > {
protected AtomicIntegerFieldUpdater ( ) {
}
}
@CallerSensitive
public static < U > AtomicIntegerFieldUpdater < U > newUpdater ( Class < U > ,
String fieldName) {
return new AtomicIntegerFieldUpdaterImpl < U > ( tclass, fieldName, Reflection . getCallerClass ( ) ) ;
}
public int getAndIncrement ( T obj) {
int prev, next;
do {
prev = get ( obj) ;
next = prev + 1 ;
} while ( ! compareAndSet ( obj, prev, next) ) ;
return prev;
}
public final int getAndIncrement ( T obj) {
return getAndAdd ( obj, 1 ) ;
}
public final int getAndAdd ( T obj, int delta) {
accessCheck ( obj) ;
return U . getAndAddInt ( obj, offset, delta) ;
}
public abstract class AtomicIntegerFieldUpdater < T > {
private static final class AtomicIntegerFieldUpdaterImpl < T > extends AtomicIntegerFieldUpdater < T > {
private static final Unsafe U = Unsafe . getUnsafe ( ) ;
private final long offset;
private final Class < ? > ;
private final void accessCheck ( T obj) {
if ( ! cclass. isInstance ( obj) )
throwAccessCheckException ( obj) ;
}
public final boolean compareAndSet ( T obj, int expect, int update) {
accessCheck ( obj) ;
return U . compareAndSetInt ( obj, offset, expect, update) ;
}
}
}
AtomicIntegerFieldUpdaterImpl ( final Class < T > ,
final String fieldName,
final Class < ? > ) {
final Field field;
final int modifiers;
try {
field = AccessController . doPrivileged (
new PrivilegedExceptionAction < Field > ( ) {
public Field run ( ) throws NoSuchFieldException {
return tclass. getDeclaredField ( fieldName) ;
}
} ) ;
modifiers = field. getModifiers ( ) ;
sun. reflect. misc. ReflectUtil. ensureMemberAccess (
caller, tclass, null , modifiers) ;
ClassLoader cl = tclass. getClassLoader ( ) ;
ClassLoader ccl = caller. getClassLoader ( ) ;
if ( ( ccl != null ) && ( ccl != cl) &&
( ( cl == null ) || ! isAncestor ( cl, ccl) ) ) {
sun. reflect. misc. ReflectUtil. checkPackageAccess ( tclass) ;
}
} catch ( PrivilegedActionException pae) {
throw new RuntimeException ( pae. getException ( ) ) ;
} catch ( Exception ex) {
throw new RuntimeException ( ex) ;
}
if ( field. getType ( ) != int . class )
throw new IllegalArgumentException ( "Must be integer type" ) ;
if ( ! Modifier . isVolatile ( modifiers) )
throw new IllegalArgumentException ( "Must be volatile type" ) ;
this . cclass = ( Modifier . isProtected ( modifiers) &&
tclass. isAssignableFrom ( caller) &&
! isSamePackage ( tclass, caller) )
? caller : tclass;
this . tclass = tclass;
this . offset = U . objectFieldOffset ( field) ;
}
public final int getAndIncrement ( int i) {
return ( int ) AA . getAndAdd ( array, i, 1 ) ;
}
public class AtomicIntegerArray implements java. io. Serializable{
private static final VarHandle AA
= MethodHandles . arrayElementVarHandle ( int [ ] . class ) ;
private final int [ ] array;
}
public final int getAndDecrement ( int i) {
return ( int ) AA . getAndAdd ( array, i, - 1 ) ;
}
public final int getAndSet ( int i, int newValue) {
return ( int ) AA . getAndSet ( array, i, newValue) ;
}
public final boolean compareAndSet ( int i, int expectedValue, int newValue) {
return AA . compareAndSet ( array, i, expectedValue, newValue) ;
}
public final int getAndIncrement ( ) {
return U . getAndAddInt ( this , VALUE , 1 ) ;
}
public final int getAndDecrement ( ) {
return U . getAndAddInt ( this , VALUE , - 1 ) ;
}
public final boolean compareAndSet ( int expectedValue, int newValue) {
return U . compareAndSetInt ( this , VALUE , expectedValue, newValue) ;
}
public final native
@MethodHandle.PolymorphicSignature
@HotSpotIntrinsicCandidate
Object getAndAdd ( Object . . . args) ;
public final native
@MethodHandle.PolymorphicSignature
@HotSpotIntrinsicCandidate
boolean compareAndSet ( Object . . . args) ;
abstract class Striped64 extends Number {
}
public class LongAdder extends Striped64 implements Serializable {
}
public class LongAccumulator extends Striped64 implements Serializable {
}
public class DoubleAdder extends Striped64 implements Serializable {
}
public class DoubleAccumulator extends Striped64 implements Serializable {
}
public long sum ( ) {
Cell [ ] cs = cells;
long sum = base;
if ( cs != null ) {
for ( Cell c : cs)
if ( c != null )
sum += c. value;
}
return sum;
}
@jdk.internal.vm.annotation.Contended static final class Cell {
volatile long value;
}
abstract class Striped64 extends Number {
transient volatile Cell [ ] cells;
transient volatile long base;
@jdk.internal.vm.annotation.Contended static final class Cell {
volatile long value;
Cell ( long x) { value = x; }
}
Striped64 ( ) {
}
}
@jdk.internal.vm.annotation.Contended static final class Cell {
}
@jdk.internal.vm.annotation.Contended static final class Cell {
volatile long value;
Cell ( long x) { value = x; }
final boolean cas ( long cmp, long val) {
return VALUE . compareAndSet ( this , cmp, val) ;
}
final void reset ( ) {
VALUE . setVolatile ( this , 0L ) ;
}
final void reset ( long identity) {
VALUE . setVolatile ( this , identity) ;
}
final long getAndSet ( long val) {
return ( long ) VALUE . getAndSet ( this , val) ;
}
private static final VarHandle VALUE ;
static {
try {
MethodHandles. Lookup l = MethodHandles . lookup ( ) ;
VALUE = l. findVarHandle ( Cell . class , "value" , long . class ) ;
} catch ( ReflectiveOperationException e) {
throw new ExceptionInInitializerError ( e) ;
}
}
}
public void add ( long x) {
Cell [ ] cs; long b, v; int m; Cell c;
if ( ( cs = cells) != null || ! casBase ( b = base, b + x) ) {
boolean uncontended = true ;
if ( cs == null || ( m = cs. length - 1 ) < 0 ||
( c = cs[ getProbe ( ) & m] ) == null ||
! ( uncontended = c. cas ( v = c. value, v + x) ) )
longAccumulate ( x, null , uncontended) ;
}
}
public void increment ( ) {
add ( 1L ) ;
}
public void decrement ( ) {
add ( - 1L ) ;
}
final boolean casBase ( long cmp, long val) {
return BASE . compareAndSet ( this , cmp, val) ;
}
private static final VarHandle BASE ;
final boolean cas ( long cmp, long val) {
return VALUE . compareAndSet ( this , cmp, val) ;
}
private static final VarHandle VALUE ;
final void longAccumulate ( long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ( ( h = getProbe ( ) ) == 0 ) {
ThreadLocalRandom . current ( ) ;
h = getProbe ( ) ;
wasUncontended = true ;
}
boolean collide = false ;
done: for ( ; ; ) {
Cell [ ] cs; Cell c; int n; long v;
if ( ( cs = cells) != null && ( n = cs. length) > 0 ) {
if ( ( c = cs[ ( n - 1 ) & h] ) == null ) {
if ( cellsBusy == 0 ) {
Cell r = new Cell ( x) ;
if ( cellsBusy == 0 && casCellsBusy ( ) ) {
try {
Cell [ ] rs; int m, j;
if ( ( rs = cells) != null &&
( m = rs. length) > 0 &&
rs[ j = ( m - 1 ) & h] == null ) {
rs[ j] = r;
break done;
}
} finally {
cellsBusy = 0 ;
}
continue ;
}
}
collide = false ;
}
else if ( ! wasUncontended)
wasUncontended = true ;
else if ( c. cas ( v = c. value,
( fn == null ) ? v + x : fn. applyAsLong ( v, x) ) )
break ;
else if ( n >= NCPU || cells != cs)
collide = false ;
else if ( ! collide)
collide = true ;
else if ( cellsBusy == 0 && casCellsBusy ( ) ) {
try {
if ( cells == cs)
cells = Arrays . copyOf ( cs, n << 1 ) ;
} finally {
cellsBusy = 0 ;
}
collide = false ;
continue ;
}
h = advanceProbe ( h) ;
}
else if ( cellsBusy == 0 && cells == cs && casCellsBusy ( ) ) {
try {
if ( cells == cs) {
Cell [ ] rs = new Cell [ 2 ] ;
rs[ h & 1 ] = new Cell ( x) ;
cells = rs;
break done;
}
} finally {
cellsBusy = 0 ;
}
}
else if ( casBase ( v = base,
( fn == null ) ? v + x : fn. applyAsLong ( v, x) ) )
break done;
}
}
public LongAccumulator ( LongBinaryOperator accumulatorFunction,
long identity) {
this . function = accumulatorFunction;
base = this . identity = identity;
}
@FunctionalInterface
public interface LongBinaryOperator {
long applyAsLong ( long left, long right) ;
}
public void accumulate ( long x) {
Cell [ ] cs; long b, v, r; int m; Cell c;
if ( ( cs = cells) != null
|| ( ( r = function. applyAsLong ( b = base, x) ) != b
&& ! casBase ( b, r) ) ) {
boolean uncontended = true ;
if ( cs == null
|| ( m = cs. length - 1 ) < 0
|| ( c = cs[ getProbe ( ) & m] ) == null
|| ! ( uncontended =
( r = function. applyAsLong ( v = c. value, x) ) == v
|| c. cas ( v, r) ) )
longAccumulate ( x, function, uncontended) ;
}
}
public void add ( double x) {
Cell [ ] cs; long b, v; int m; Cell c;
if ( ( cs = cells) != null ||
! casBase ( b = base,
Double . doubleToRawLongBits
( Double . longBitsToDouble ( b) + x) ) ) {
boolean uncontended = true ;
if ( cs == null || ( m = cs. length - 1 ) < 0 ||
( c = cs[ getProbe ( ) & m] ) == null ||
! ( uncontended = c. cas ( v = c. value,
Double . doubleToRawLongBits
( Double . longBitsToDouble ( v) + x) ) ) )
doubleAccumulate ( x, null , uncontended) ;
}
}
public void synchronized method1 ( ) {
method2 ( ) ;
}
public void synchronized method2 ( ) {
}
public interface Lock {
void lock ( ) ;
void lockInterruptibly ( ) throws InterruptedException ;
boolean tryLock ( ) ;
boolean tryLock ( long time, TimeUnit unit) throws InterruptedException ;
void unlock ( ) ;
Condition newCondition ( ) ;
}
public class ReentrantLock implements Lock , java. io. Serializable{
private final Sync sync;
public void lock ( ) {
sync. acquire ( 1 ) ;
}
public void unlock ( ) {
sync. release ( 1 ) ;
}
}
public ReentrantLock ( ) {
sync = new NonfairSync ( ) ;
}
public ReentrantLock ( boolean fair) {
sync = fair ? new FairSync ( ) : new NonfairSync ( ) ;
}
public abstract class AbstractOwnableSynchronizer implements java. io. Serializable{
private transient Thread exclusiveOwnerThread;
}
public abstract class AbstractQueuedSynchronizer extends
AbstractOwnableSynchronizer implements java. io. Serializable{
private volatile int state;
}
public native void unpark ( Object thread) ;
public native void park ( boolean isAbsolute, long time) ;
public class LockSupport {
private static final Unsafe U = Unsafe . getUnsafe ( ) ;
public static void park ( ) {
U . park ( false , 0L ) ;
}
public static void unpark ( Thread thread) {
if ( thread != null )
U . unpark ( thread) ;
}
}
我们也能够进行使用他 ,一般的,可以直接操作并且是原子的或者最终会操作原语的主要调用,我们称为原语操作类,即可以操作原语的类,一般synchronized代码块主要是靠monitorenter和monitorexit这两个原语来实现同步的,但是我们也知道synchronized的原语有中间操作,因为他操作JVM阻塞(前面有过说明),但是最终还是操作系统阻塞,而CAS直接操作系统阻塞,所以通常CAS效率比synchronized高,那么换言之lock效率比synchronized高,这是因为中间操作需要时间,所以synchronized比较慢点,其中这个中间操作也是原语的,就算不是原语,由于被原语包括,那么我们也称为原语操作,那么很明显,CAS也就是类似于原语的一种,因为底层也是使用原语来完成的(native),我们可以看一下上面的代码,可以发现,对应的park和unpark都是一个native方法,具体如何操作原语那就不是java该做的了,具体可以学习C/C++或者汇编(自己去学习吧)或者其他可以操作原语的语言(虽然基本没有)public abstract class AbstractQueuedSynchronizer {
static final class Node {
volatile Thread thread;
volatile Node prev;
volatile Node next;
}
private transient volatile Node head;
private transient volatile Node tail;
}
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L ;
protected final boolean tryAcquire ( int acquires) {
return nonfairTryAcquire ( acquires) ;
}
}
@ReservedStackAccess
final boolean nonfairTryAcquire ( int acquires) {
final Thread current = Thread . currentThread ( ) ;
int c = getState ( ) ;
if ( c == 0 ) {
if ( compareAndSetState ( 0 , acquires) ) {
setExclusiveOwnerThread ( current) ;
return true ;
}
}
else if ( current == getExclusiveOwnerThread ( ) ) {
int nextc = c + acquires;
if ( nextc < 0 )
throw new Error ( "Maximum lock count exceeded" ) ;
setState ( nextc) ;
return true ;
}
return false ;
}
@ReservedStackAccess
protected final boolean tryAcquire ( int acquires) {
final Thread current = Thread . currentThread ( ) ;
int c = getState ( ) ;
if ( c == 0 ) {
if ( ! hasQueuedPredecessors ( ) &&
compareAndSetState ( 0 , acquires) ) {
setExclusiveOwnerThread ( current) ;
return true ;
}
}
else if ( current == getExclusiveOwnerThread ( ) ) {
int nextc = c + acquires;
if ( nextc < 0 )
throw new Error ( "Maximum lock count exceeded" ) ;
setState ( nextc) ;
return true ;
}
return false ;
}
}
public void lock ( ) {
sync. acquire ( 1 ) ;
}
public final void acquire ( int arg) {
if ( ! tryAcquire ( arg) &&
acquireQueued ( addWaiter ( Node . EXCLUSIVE ) , arg) )
selfInterrupt ( ) ;
}
private Node addWaiter ( Node mode) {
Node node = new Node ( mode) ;
for ( ; ; ) {
Node oldTail = tail;
if ( oldTail != null ) {
node. setPrevRelaxed ( oldTail) ;
if ( compareAndSetTail ( oldTail, node) ) {
oldTail. next = node;
return node;
}
} else {
initializeSyncQueue ( ) ;
}
}
}
private final void initializeSyncQueue ( ) {
Node h;
if ( HEAD . compareAndSet ( this , null , ( h = new Node ( ) ) ) )
tail = h;
}
final boolean acquireQueued ( final Node node, int arg) {
boolean interrupted = false ;
try {
for ( ; ; ) {
final Node p = node. predecessor ( ) ;
if ( p == head && tryAcquire ( arg) ) {
setHead ( node) ;
p. next = null ;
return interrupted;
}
if ( shouldParkAfterFailedAcquire ( p, node) )
interrupted |= parkAndCheckInterrupt ( ) ;
}
} catch ( Throwable t) {
cancelAcquire ( node) ;
if ( interrupted)
selfInterrupt ( ) ;
throw t;
}
}
static void selfInterrupt ( ) {
Thread . currentThread ( ) . interrupt ( ) ;
}
private final boolean parkAndCheckInterrupt ( ) {
LockSupport . park ( this ) ;
return Thread . interrupted ( ) ;
}
public final void acquire ( int arg) {
if ( ! tryAcquire ( arg) &&
acquireQueued ( addWaiter ( Node . EXCLUSIVE ) , arg) )
selfInterrupt ( ) ;
}
public void unlock ( ) {
sync. release ( 1 ) ;
}
public final boolean release ( int arg) {
if ( tryRelease ( arg) ) {
Node h = head;
if ( h != null && h. waitStatus != 0 )
unparkSuccessor ( h) ;
return true ;
}
return false ;
}
@ReservedStackAccess
protected final boolean tryRelease ( int releases) {
int c = getState ( ) - releases;
if ( Thread . currentThread ( ) != getExclusiveOwnerThread ( ) )
throw new IllegalMonitorStateException ( ) ;
boolean free = false ;
if ( c == 0 ) {
free = true ;
setExclusiveOwnerThread ( null ) ;
}
setState ( c) ;
return free;
}
private void unparkSuccessor ( Node node) {
int ws = node. waitStatus;
if ( ws < 0 )
node. compareAndSetWaitStatus ( ws, 0 ) ;
Node s = node. next;
if ( s == null || s. waitStatus > 0 ) {
s = null ;
for ( Node p = tail; p != node && p != null ; p = p. prev)
if ( p. waitStatus <= 0 )
s = p;
}
if ( s != null )
LockSupport . unpark ( s. thread) ;
}
public void lockInterruptibly ( ) throws InterruptedException {
sync. acquireInterruptibly ( 1 ) ;
}
public final void acquireInterruptibly ( int arg)
throws InterruptedException {
if ( Thread . interrupted ( ) )
throw new InterruptedException ( ) ;
if ( ! tryAcquire ( arg) )
doAcquireInterruptibly ( arg) ;
}
private void doAcquireInterruptibly ( int arg)
throws InterruptedException {
final Node node = addWaiter ( Node . EXCLUSIVE ) ;
try {
for ( ; ; ) {
final Node p = node. predecessor ( ) ;
if ( p == head && tryAcquire ( arg) ) {
setHead ( node) ;
p. next = null ;
return ;
}
if ( shouldParkAfterFailedAcquire ( p, node) &&
parkAndCheckInterrupt ( ) )
throw new InterruptedException ( ) ;
}
} catch ( Throwable t) {
cancelAcquire ( node) ;
throw t;
}
}
public boolean tryLock ( ) {
return sync. nonfairTryAcquire ( 1 ) ;
}
public interface ReadWriteLock {
Lock readLock ( ) ;
Lock writeLock ( ) ;
}
ReadWriteLock readWriteLock = new ReentrantReadWriteLock ( ) ;
Lock readLock = readWriteLock. readLock ( ) ;
readLock. lock ( ) ;
readLock. unlock ( ) ;
Lock writeLock = readWriteLock. writeLock ( ) ;
writeLock. lock ( ) ;
writeLock. unlock ( ) ;
public ReentrantReadWriteLock ( ) {
this ( false ) ;
}
public ReentrantReadWriteLock ( boolean fair) {
sync = fair ? new FairSync ( ) : new NonfairSync ( ) ;
readerLock = new ReadLock ( this ) ;
writerLock = new WriteLock ( this ) ;
}
abstract static class Sync extends AbstractQueuedSynchronizer {
static final int SHARED_SHIFT = 16 ;
static final int SHARED_UNIT = ( 1 << SHARED_SHIFT ) ;
static final int MAX_COUNT = ( 1 << SHARED_SHIFT ) - 1 ;
static final int EXCLUSIVE_MASK = ( 1 << SHARED_SHIFT ) - 1 ;
static int sharedCount ( int c) { return c >>> SHARED_SHIFT ; }
static int exclusiveCount ( int c) { return c & EXCLUSIVE_MASK ; }
}
public static class ReadLock implements Lock , java. io. Serializable{
public void lock ( ) {
sync. acquireShared ( 1 ) ;
}
public void unlock ( ) {
sync. releaseShared ( 1 ) ;
}
}
public static class WriteLock implements Lock , java. io. Serializable{
public void lock ( ) {
sync. acquire ( 1 ) ;
}
public void unlock ( ) {
sync. release ( 1 ) ;
}
}
public void lock ( ) {
sync. acquire ( 1 ) ;
}
public final void acquire ( int arg) {
if ( ! tryAcquire ( arg) &&
acquireQueued ( addWaiter ( Node . EXCLUSIVE ) , arg) )
selfInterrupt ( ) ;
}
public void unlock ( ) {
sync. release ( 1 ) ;
}
public final boolean release ( int arg) {
if ( tryRelease ( arg) ) {
Node h = head;
if ( h != null && h. waitStatus != 0 )
unparkSuccessor ( h) ;
return true ;
}
return false ;
}
public void lock ( ) {
sync. acquireShared ( 1 ) ;
}
public final void acquireShared ( int arg) {
if ( tryAcquireShared ( arg) < 0 )
doAcquireShared ( arg) ;
}
public void unlock ( ) {
sync. releaseShared ( 1 ) ;
}
public final boolean releaseShared ( int arg) {
if ( tryReleaseShared ( arg) ) {
doReleaseShared ( ) ;
return true ;
}
return false ;
}
static final class NonfairSync extends Sync {
private static final long serialVersionUID = - 8159625535654395037L ;
final boolean writerShouldBlock ( ) {
return false ;
}
final boolean readerShouldBlock ( ) {
return apparentlyFirstQueuedIsExclusive ( ) ;
}
}
static final class FairSync extends Sync {
private static final long serialVersionUID = - 2274990926593161451L ;
final boolean writerShouldBlock ( ) {
return hasQueuedPredecessors ( ) ;
}
final boolean readerShouldBlock ( ) {
return hasQueuedPredecessors ( ) ;
}
}
public boolean tryLock ( ) {
return sync. tryWriteLock ( ) ;
}
@ReservedStackAccess
final boolean tryWriteLock ( ) {
Thread current = Thread . currentThread ( ) ;
int c = getState ( ) ;
if ( c != 0 ) {
int w = exclusiveCount ( c) ;
if ( w == 0 || current != getExclusiveOwnerThread ( ) )
return false ;
if ( w == MAX_COUNT )
throw new Error ( "Maximum lock count exceeded" ) ;
}
if ( ! compareAndSetState ( c, c + 1 ) )
return false ;
setExclusiveOwnerThread ( current) ;
return true ;
}
public void lock ( ) {
sync. acquire ( 1 ) ;
}
public final void acquire ( int arg) {
if ( ! tryAcquire ( arg) &&
acquireQueued ( addWaiter ( Node . EXCLUSIVE ) , arg) )
selfInterrupt ( ) ;
}
public void unlock ( ) {
sync. release ( 1 ) ;
}
public final boolean release ( int arg) {
if ( tryRelease ( arg) ) {
Node h = head;
if ( h != null && h. waitStatus != 0 )
unparkSuccessor ( h) ;
return true ;
}
return false ;
}
public boolean tryLock ( ) {
return sync. tryReadLock ( ) ;
}
@ReservedStackAccess
final boolean tryReadLock ( ) {
Thread current = Thread . currentThread ( ) ;
for ( ; ; ) {
int c = getState ( ) ;
if ( exclusiveCount ( c) != 0 &&
getExclusiveOwnerThread ( ) != current)
return false ;
int r = sharedCount ( c) ;
if ( r == MAX_COUNT )
throw new Error ( "Maximum lock count exceeded" ) ;
if ( compareAndSetState ( c, c + SHARED_UNIT ) ) {
if ( r == 0 ) {
firstReader = current;
firstReaderHoldCount = 1 ;
} else if ( firstReader == current) {
firstReaderHoldCount++ ;
} else {
HoldCounter rh = cachedHoldCounter;
if ( rh == null ||
rh. tid != LockSupport . getThreadId ( current) )
cachedHoldCounter = rh = readHolds. get ( ) ;
else if ( rh. count == 0 )
readHolds. set ( rh) ;
rh. count++ ;
}
return true ;
}
}
}
public void lock ( ) {
sync. acquireShared ( 1 ) ;
}
public final void acquireShared ( int arg) {
if ( tryAcquireShared ( arg) < 0 )
doAcquireShared ( arg) ;
}
public void unlock ( ) {
sync. releaseShared ( 1 ) ;
}
public final boolean releaseShared ( int arg) {
if ( tryReleaseShared ( arg) ) {
doReleaseShared ( ) ;
return true ;
}
return false ;
}
@ReservedStackAccess
protected final boolean tryReleaseShared ( int unused) {
Thread current = Thread . currentThread ( ) ;
for ( ; ; ) {
int c = getState ( ) ;
int nextc = c - SHARED_UNIT ;
if ( compareAndSetState ( c, nextc) )
return nextc == 0 ;
}
}
public interface Condition {
void await ( ) throws InterruptedException ;
boolean await ( long time, TimeUnit unit) throws InterruptedException ;
long awaitNanos ( long nanosTimeout) throws InterruptedException ;
void awaitUninterruptibly ( ) ;
boolean awaitUntil ( Date deadline) throws InterruptedException ;
void signal ( ) ;
void signalAll ( ) ;
}
public interface Lock {
void lock ( ) ;
void lockInterruptibly ( ) throws InterruptedException ;
Condition newCondition ( ) ;
boolean tryLock ( ) ;
boolean tryLock ( long time, TimeUnit unit) throws InterruptedException ;
void unlock ( ) ;
}
public class ArrayBlockingQueue < E > extends AbstractQueue < E > implements BlockingQueue < E > , java. io. Serializable{
final Object [ ] items;
int takeIndex;
int putIndex;
int count;
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
public ArrayBlockingQueue ( int capacity, boolean fair) {
if ( capacity <= 0 )
throw new IllegalArgumentException ( ) ;
this . items = new Object [ capacity] ;
lock = new ReentrantLock ( fair) ;
notEmpty = lock. newCondition ( ) ;
notFull = lock. newCondition ( ) ;
}
public void put ( E e) throws InterruptedException {
Objects . requireNonNull ( e) ;
final ReentrantLock lock = this . lock;
lock. lockInterruptibly ( ) ;
try {
while ( count == items. length)
notFull. await ( ) ;
enqueue ( e) ;
} finally {
lock. unlock ( ) ;
}
}
private void enqueue ( E e) {
final Object [ ] items = this . items;
items[ putIndex] = e;
if ( ++ putIndex == items. length) putIndex = 0 ;
count++ ;
notEmpty. signal ( ) ;
}
public E take ( ) throws InterruptedException {
final ReentrantLock lock = this . lock;
lock. lockInterruptibly ( ) ;
try {
while ( count == 0 )
notEmpty. await ( ) ;
return dequeue ( ) ;
} finally {
lock. unlock ( ) ;
}
}
private E dequeue ( ) {
final Object [ ] items = this . items;
@SuppressWarnings ( "unchecked" )
E e = ( E ) items[ takeIndex] ;
items[ takeIndex] = null ;
if ( ++ takeIndex == items. length) takeIndex = 0 ;
count-- ;
if ( itrs != null )
itrs. elementDequeued ( ) ;
notFull. signal ( ) ;
return e;
}
}
public class ReentrantLock implements Lock , java. io. Serializable{
public Condition newCondition ( ) {
return sync. newCondition ( ) ;
}
}
public class ReentrantReadWriteLock
implements ReadWriteLock , java. io. Serializable{
private final ReentrantReadWriteLock. ReadLock readerLock;
private final ReentrantReadWriteLock. WriteLock writerLock;
public static class ReadLock implements Lock , java. io. Serializable{
public Condition newCondition ( ) {
throw new UnsupportedOperationException ( ) ;
}
}
public static class WriteLock implements Lock , java. io. Serializable{
public Condition newCondition ( ) {
return sync. newCondition ( ) ;
}
}
}
public abstract class AbstractQueuedSynchronizer extends
AbstractOwnableSynchronizer
implements java. io. Serializable{
public class ConditionObject implements Condition , java. io. Serializable{
}
}
abstract static class Sync extends AbstractQueuedSynchronizer {
final ConditionObject newCondition ( ) {
return new ConditionObject ( ) ;
}
}
public class ConditionObject implements Condition , java. io. Serializable{
private transient Node firstWaiter;
private transient Node lastWaiter;
}
static final class Node {
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node nextWaiter;
}
public final void await ( ) throws InterruptedException {
if ( Thread . interrupted ( ) )
throw new InterruptedException ( ) ;
Node node = addConditionWaiter ( ) ;
int savedState = fullyRelease ( node) ;
int interruptMode = 0 ;
while ( ! isOnSyncQueue ( node) ) {
LockSupport . park ( this ) ;
if ( ( interruptMode = checkInterruptWhileWaiting ( node) ) != 0 )
break ;
}
if ( acquireQueued ( node, savedState) && interruptMode != THROW_IE )
interruptMode = REINTERRUPT ;
if ( node. nextWaiter != null )
unlinkCancelledWaiters ( ) ;
if ( interruptMode != 0 )
reportInterruptAfterWait ( interruptMode) ;
}
private Node addConditionWaiter ( ) {
if ( ! isHeldExclusively ( ) )
throw new IllegalMonitorStateException ( ) ;
Node t = lastWaiter;
if ( t != null && t. waitStatus != Node . CONDITION ) {
unlinkCancelledWaiters ( ) ;
t = lastWaiter;
}
Node node = new Node ( Node . CONDITION ) ;
if ( t == null )
firstWaiter = node;
else
t. nextWaiter = node;
lastWaiter = node;
return node;
}
public final void awaitUninterruptibly ( ) {
Node node = addConditionWaiter ( ) ;
int savedState = fullyRelease ( node) ;
boolean interrupted = false ;
while ( ! isOnSyncQueue ( node) ) {
LockSupport . park ( this ) ;
if ( Thread . interrupted ( ) )
interrupted = true ;
}
if ( acquireQueued ( node, savedState) || interrupted)
selfInterrupt ( ) ;
}
public final void signal ( ) {
if ( ! isHeldExclusively ( ) )
throw new IllegalMonitorStateException ( ) ;
Node first = firstWaiter;
if ( first != null )
doSignal ( first) ;
}
private void doSignal ( Node first) {
do {
if ( ( firstWaiter = first. nextWaiter) == null )
lastWaiter = null ;
first. nextWaiter = null ;
} while ( ! transferForSignal ( first) &&
( first = firstWaiter) != null ) ;
}
final boolean transferForSignal ( Node node) {
if ( ! node. compareAndSetWaitStatus ( Node . CONDITION , 0 ) )
return false ;
Node p = enq ( node) ;
int ws = p. waitStatus;
if ( ws > 0 || ! p. compareAndSetWaitStatus ( ws, Node . SIGNAL ) )
LockSupport . unpark ( node. thread) ;
return true ;
}
package main5 ;
import java. util. concurrent. locks. StampedLock ;
public class Point {
private double x, y;
private final StampedLock sl = new StampedLock ( ) ;
void move ( double deltaX, double deltaY) {
long stamp = sl. writeLock ( ) ;
try {
x += deltaX;
y += deltaY;
} finally {
sl. unlockWrite ( stamp) ;
}
}
double distenceFromOrigin ( ) {
long stamp = sl. tryOptimisticRead ( ) ;
double currentX = x, currentY = y;
if ( ! sl. validate ( stamp) ) {
stamp = sl. readLock ( ) ;
try {
currentX = x;
currentY = y;
} finally {
sl. unlockRead ( stamp) ;
}
}
return Math . sqrt ( currentX * currentX + currentY * currentY) ;
}
}
long stamp = sl. tryOptimisticRead ( ) ;
double currentX = x, currentY = y;
if ( ! sl. validate ( stamp) ) {
}
public boolean validate ( long stamp) {
VarHandle . acquireFence ( ) ;
return ( stamp & SBITS ) == ( state & SBITS ) ;
}
public class StampedLock implements java. io. Serializable{
private static final int LG_READERS = 7 ;
private static final long RUNIT = 1L ;
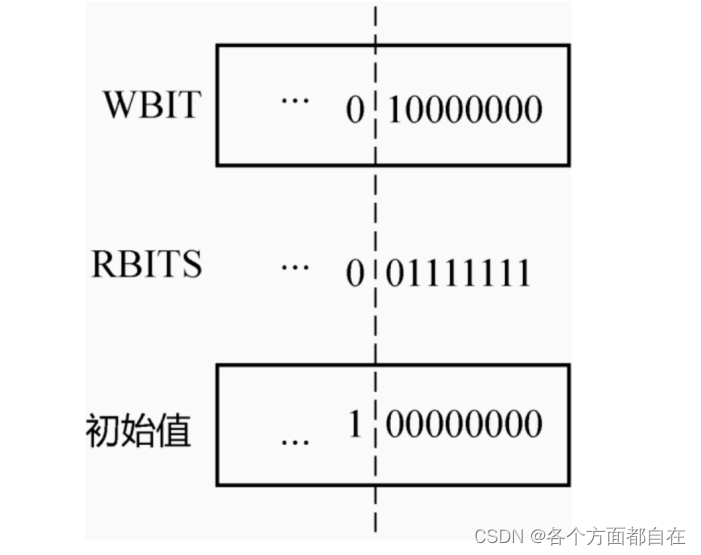
private static final long WBIT = 1L << LG_READERS ;
private static final long RBITS = WBIT - 1L ;
private static final long RFULL = RBITS - 1L ;
private static final long ABITS = RBITS | WBIT ;
private static final long SBITS = ~ RBITS ;
private static final long ORIGIN = WBIT << 1 ;
private transient volatile long state;
}
public StampedLock ( ) {
state = ORIGIN ;
}
public long tryOptimisticRead ( ) {
long s;
return ( ( ( s = state) & WBIT ) == 0L ) ? ( s & SBITS ) : 0L ;
}
public boolean validate ( long stamp) {
VarHandle . acquireFence ( ) ;
return ( stamp & SBITS ) == ( state & SBITS ) ;
}
public class StampedLock implements java. io. Serializable{
static final class WNode {
volatile WNode prev;
volatile WNode next;
volatile WNode cowait;
volatile Thread thread;
volatile int status;
final int mode;
WNode ( int m, WNode p) {
mode = m;
prev = p;
}
}
private transient volatile WNode whead;
private transient volatile WNode wtail;
}
private static final int NCPU = Runtime . getRuntime ( ) . availableProcessors ( ) ;
private static final int SPINS = ( NCPU > 1 ) ? 1 << 6 : 0 ;
public long writeLock ( ) {
long next;
return ( ( next = tryWriteLock ( ) ) != 0L ) ? next : acquireWrite ( false , 0L ) ;
}
public long tryWriteLock ( ) {
long s;
return ( ( ( s = state) & ABITS ) == 0L ) ? tryWriteLock ( s) : 0L ;
}
private long acquireWrite ( boolean interruptible, long deadline) {
WNode node = null , p;
for ( int spins = - 1 ; ; ) {
long m, s, ns;
if ( ( m = ( s = state) & ABITS ) == 0L ) {
if ( ( ns = tryWriteLock ( s) ) != 0L )
return ns;
}
else if ( spins < 0 )
spins = ( m == WBIT && wtail == whead) ? SPINS : 0 ;
else if ( spins > 0 ) {
-- spins;
Thread . onSpinWait ( ) ;
}
else if ( ( p = wtail) == null ) {
WNode hd = new WNode ( WMODE , null ) ;
if ( WHEAD . weakCompareAndSet ( this , null , hd) )
wtail = hd;
}
else if ( node == null )
node = new WNode ( WMODE , p) ;
else if ( node. prev != p)
node. prev = p;
else if ( WTAIL . weakCompareAndSet ( this , p, node) ) {
p. next = node;
break ;
}
}
boolean wasInterrupted = false ;
for ( int spins = - 1 ; ; ) {
WNode h, np, pp; int ps;
if ( ( h = whead) == p) {
if ( spins < 0 )
spins = HEAD_SPINS ;
else if ( spins < MAX_HEAD_SPINS )
spins <<= 1 ;
for ( int k = spins; k > 0 ; -- k) {
long s, ns;
if ( ( ( s = state) & ABITS ) == 0L ) {
if ( ( ns = tryWriteLock ( s) ) != 0L ) {
whead = node;
node. prev = null ;
if ( wasInterrupted)
Thread . currentThread ( ) . interrupt ( ) ;
return ns;
}
}
else
Thread . onSpinWait ( ) ;
}
}
else if ( h != null ) {
WNode c; Thread w;
while ( ( c = h. cowait) != null ) {
if ( WCOWAIT . weakCompareAndSet ( h, c, c. cowait) &&
( w = c. thread) != null )
LockSupport . unpark ( w) ;
}
}
if ( whead == h) {
if ( ( np = node. prev) != p) {
if ( np != null )
( p = np) . next = node;
}
else if ( ( ps = p. status) == 0 )
WSTATUS . compareAndSet ( p, 0 , WAITING ) ;
else if ( ps == CANCELLED ) {
if ( ( pp = p. prev) != null ) {
node. prev = pp;
pp. next = node;
}
}
else {
long time;
if ( deadline == 0L )
time = 0L ;
else if ( ( time = deadline - System . nanoTime ( ) ) <= 0L )
return cancelWaiter ( node, node, false ) ;
Thread wt = Thread . currentThread ( ) ;
node. thread = wt;
if ( p. status < 0 && ( p != h || ( state & ABITS ) != 0L ) &&
whead == h && node. prev == p) {
if ( time == 0L )
LockSupport . park ( this ) ;
else
LockSupport . parkNanos ( this , time) ;
}
node. thread = null ;
if ( Thread . interrupted ( ) ) {
if ( interruptible)
return cancelWaiter ( node, node, true ) ;
wasInterrupted = true ;
}
}
}
}
}
@ReservedStackAccess
public void unlockWrite ( long stamp) {
if ( state != stamp || ( stamp & WBIT ) == 0L )
throw new IllegalMonitorStateException ( ) ;
unlockWriteInternal ( stamp) ;
}
private long unlockWriteInternal ( long s) {
long next; WNode h;
STATE . setVolatile ( this , next = unlockWriteState ( s) ) ;
if ( ( h = whead) != null && h. status != 0 )
release ( h) ;
return next;
}
private void release ( WNode h) {
if ( h != null ) {
WNode q; Thread w;
WSTATUS . compareAndSet ( h, WAITING , 0 ) ;
if ( ( q = h. next) == null || q. status == CANCELLED ) {
for ( WNode t = wtail; t != null && t != h; t = t. prev)
if ( t. status <= 0 )
q = t;
}
if ( q != null && ( w = q. thread) != null )
LockSupport . unpark ( w) ;
}
}