- 获取pdf:密码7281
一:什么是生成模型
生成模型:在概率统计理论中,生成模型是指能够随机生成观测数据的模型,尤其是在给定某些隐含参数的条件下。为了训练一个生成模型我们首先要收集在特定领域下的大量数据(例如几百万张图片、语料等等),然后训练整个模型让其和这些数据十分相似
二:生成对抗网络(GAN)
(1)GAN概述
GAN(Generative Adversial Nets,生成式对抗网络):这是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型有两个模型:生成模型(Generative Model)和辨别模型(Discriminative Model)的互相博弈学习产生相当好的输出。实际使用时一般会选择DNN作为G和D
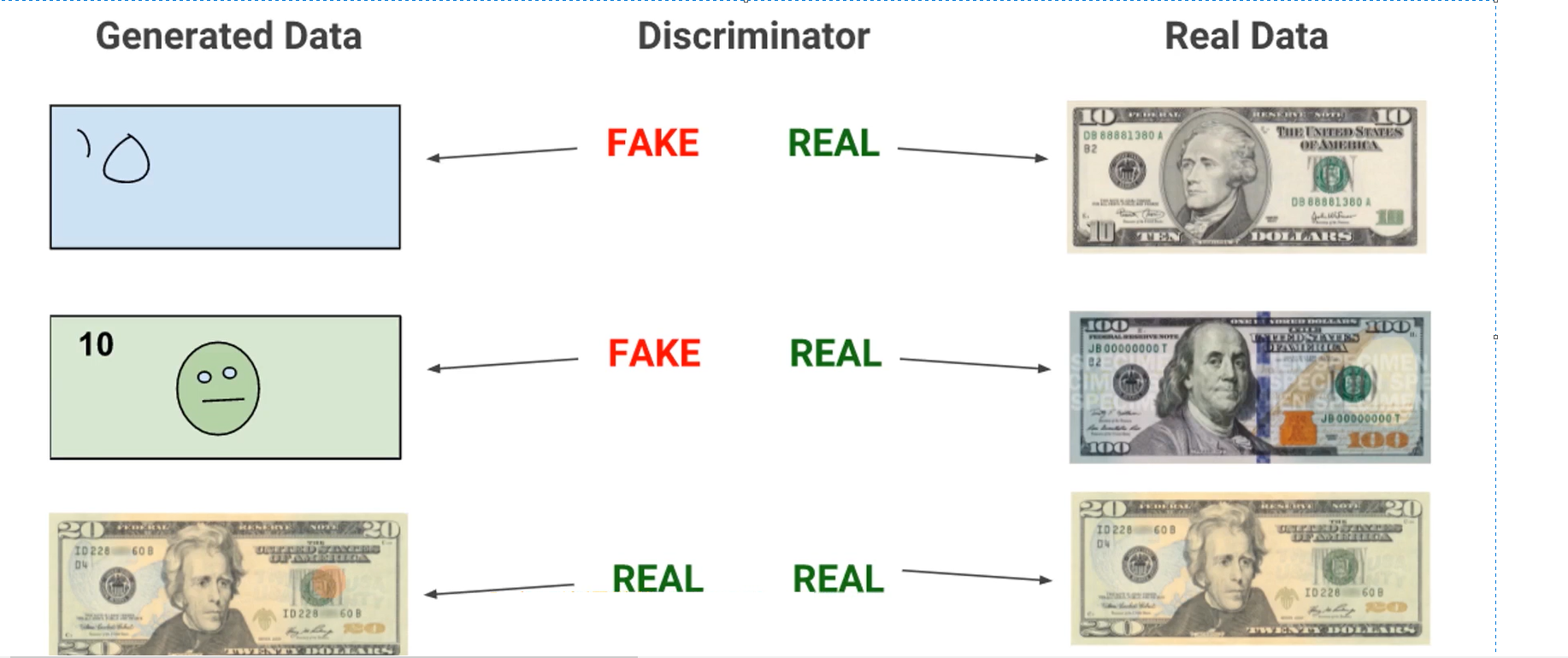
如下图,以论文中所述的制作假钞的例子为例进行说明
- 生成模型G的目的是尽量能够生成足以以假乱真的假钞去欺骗判别模型D,让它以为这是真钞
- 判别模型D的目的是尽量能够鉴别出生成模型G生成的假钞是假的
(2)GAN训练过程
GAN训练过程:GAN的训练过程就像一个博弈游戏,生成模型G和辨别模型D此消彼长,你强我弱,你弱我强,互相训练对方,最终使两个模型都变得十分优秀
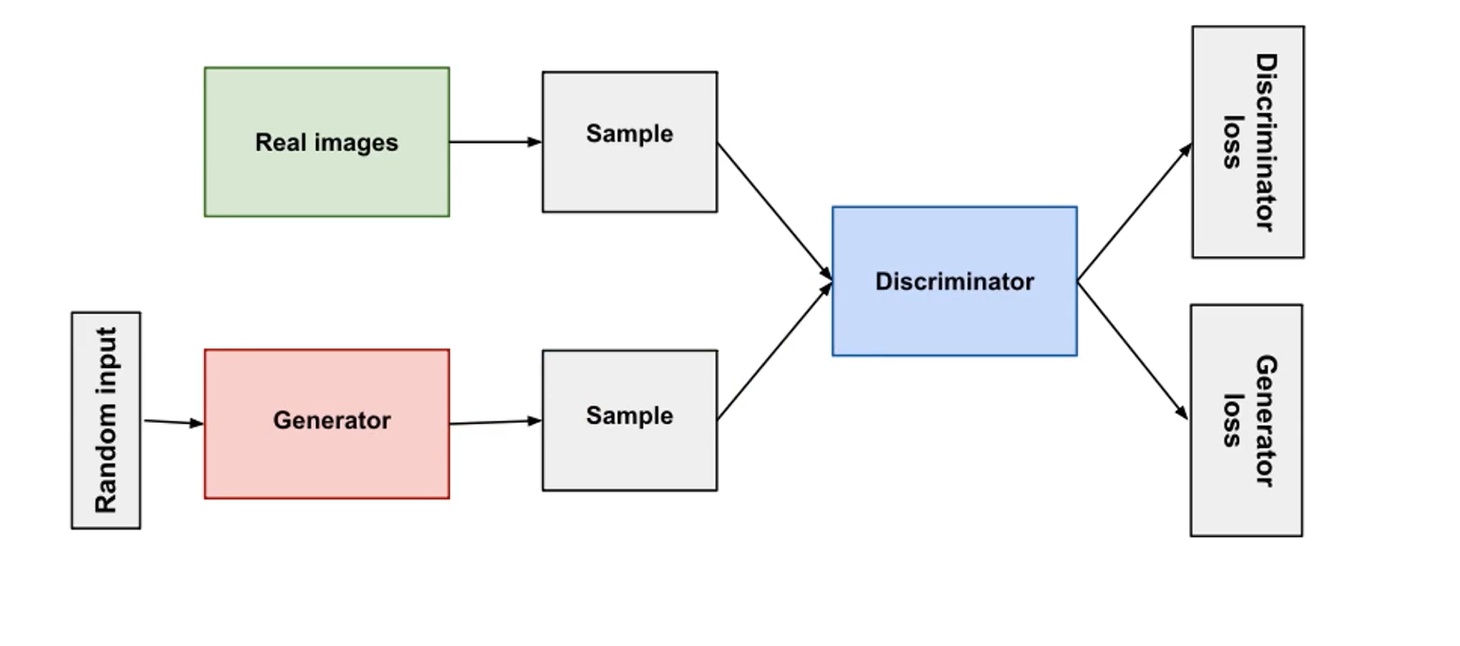
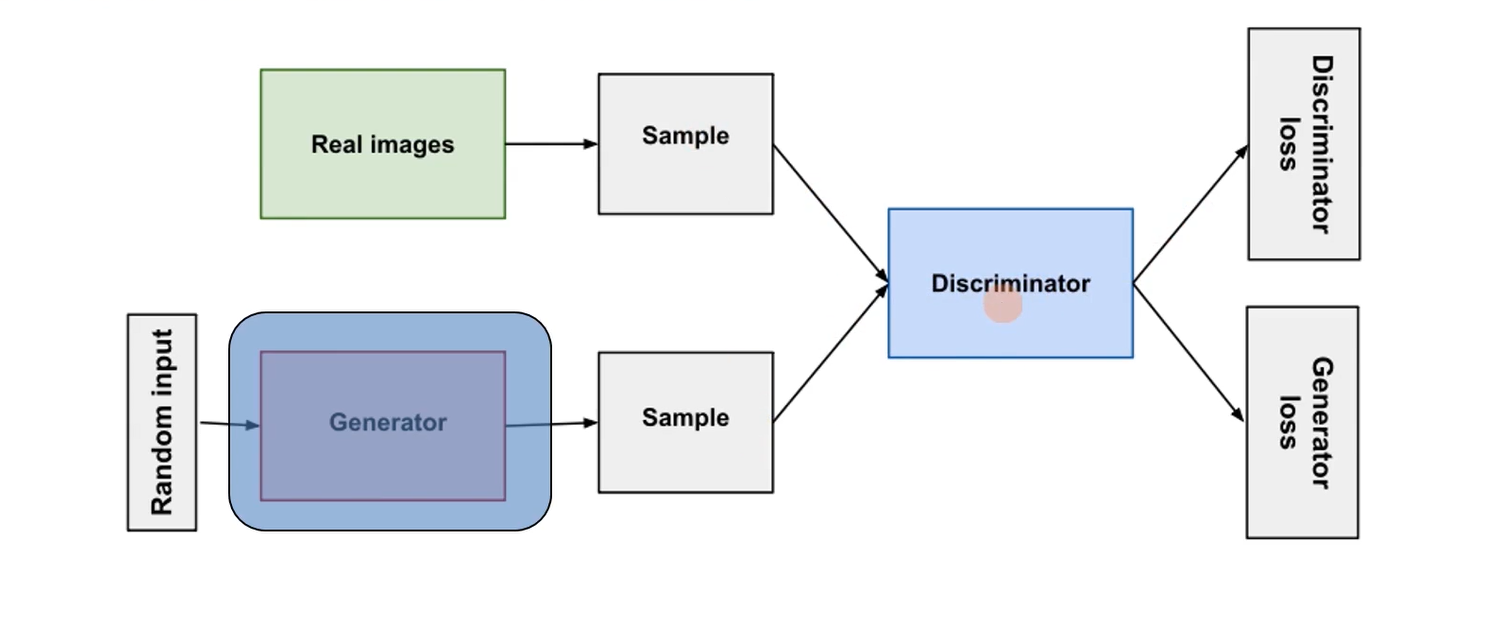
第一步:固定生成模型的参数,向生成模型G输入一些随机值或噪声(给定条件下),接着生成模型G会生成一些Sample;同时从收集来的大规模真实数据集中也取一些Sample;让这两个部分组成一个batch,送入辨别模型中以供鉴别,得到辨别模型的loss,进行反向求导,更新辨别模型D的参数并让其固定不变
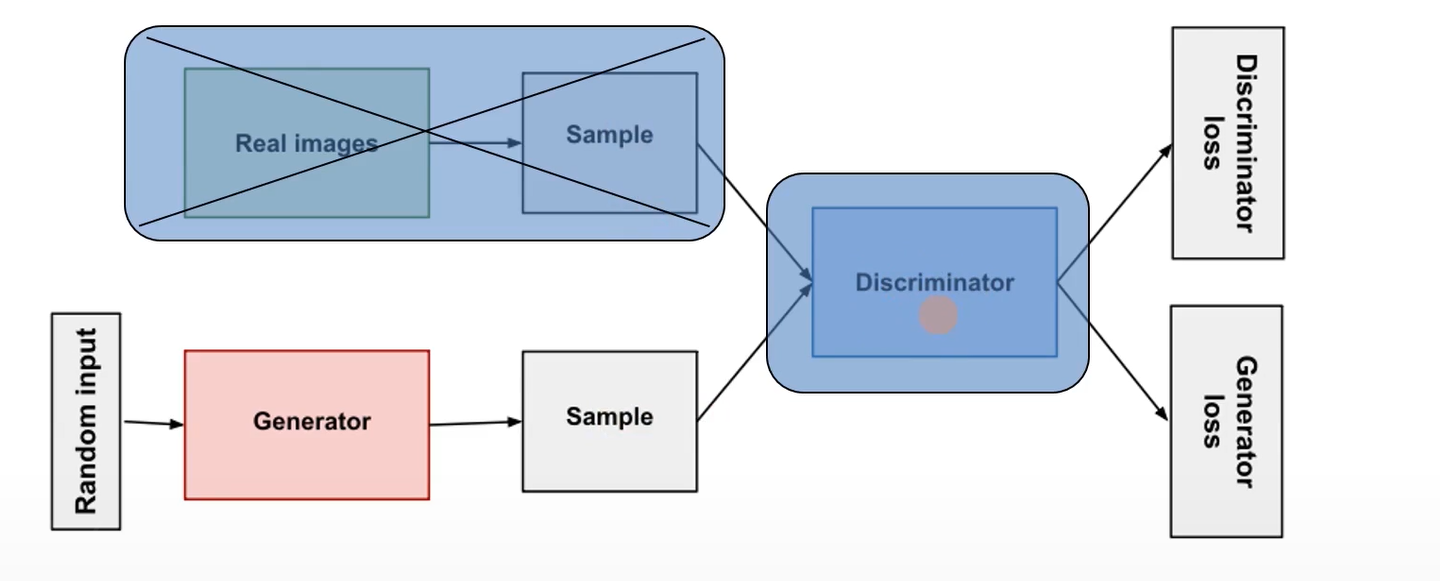
第二步:不需要从真实数据中取Sample,再向生成模型G输入噪声生成一些Sample,然后送入固定参数的辨别模型D让其进行区分,然后产生生成模型的loss,进行反向求导,更新生成模型G的参数,目的是让其生成的Sample与真实数据的Sample非常相似
(3)GAN损失函数
GAN损失函数如下图,其中各参数分别表示
- x x x:真实的数据样本
- z z z:噪声,从随机分布采集的样本
- G G G:生成模型
- D D D:判别模型
- G ( z ) G(z) G(z):输入噪声生成一条样本
- D ( x ) D(x) D(x):判别真实样本是否来自真实数据(如果是则为1,如果不是则为0)
- D ( G ( z ) ) D(G(z)) D(G(z)):判别生成样本是否来自真实数据(如果是则为1,如果不是则为0)

该损失函数整体分为两个部分
第一部分:给定 G G G找到使 V V V最大化的 D D D,因为使 V V V最大化的 D D D会使判别器效果最好
- 对于①:判别器的输入为真实数据 x x x, E x ∼ p d a t a [ l o g D ( x ) ] E_{x}\sim p_{data}[logD(x)] Ex∼pdata[logD(x)]值越大表示判别器认为输入 x x x为真实数据的概率越大,也即表示判别器的能力越强,所以这一项输出越大对判别器越有利
- 对于②:判别器的输入伪造数据 G ( z ) G(z) G(z),此时 D ( G ( z ) ) D(G(z)) D(G(z))越小那么就表示判别器将此伪造数据鉴别为真实数据的概率也越小,也即表示判别器的能力越强。注意此时第二项是 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))的期望 E x ∼ p d a t a [ l o g ( 1 − D ( G ( z ) ) ) ] E_{x}\sim p_{data}[log(1-D(G(z)))] Ex∼pdata[log(1−D(G(z)))]。所以当判别器能力越强时, D ( G ( z ) ) D(G(z)) D(G(z))越小同时 E x ∼ p d a t a [ l o g ( 1 − D ( G ( z ) ) ) ] E_{x}\sim p_{data}[log(1-D(G(z)))] Ex∼pdata[log(1−D(G(z)))]也就越大
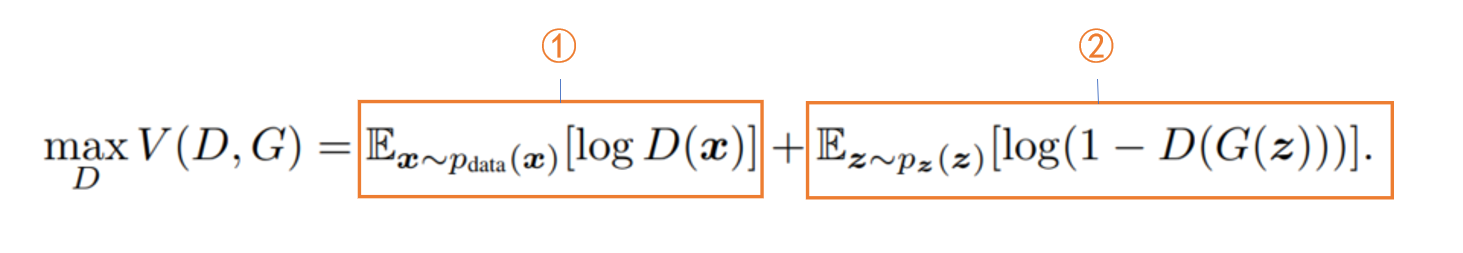
第二部分:给定 D D D找到使 V V V最小化的 G G G,因为使 V V V最小化的 G G G会使生成器效果最好
- 对于①:由于固定了 D D D,而这一部分只和 D D D有关,因此这一部分是常量,所以可以舍去
- 对于②:判别器的输入伪造数据 G ( z ) G(z) G(z),与上面不同的是,我们期望生成器的效果要好,尽可能骗过辨别器,所以 D ( G ( z ) ) D(G(z)) D(G(z))要尽可能大( D ( G ( z ) ) D(G(z)) D(G(z))越大表示辨别器鉴定此数据为真实数据的概率越大), E x ∼ p d a t a [ l o g ( 1 − D ( G ( z ) ) ) ] E_{x}\sim p_{data}[log(1-D(G(z)))] Ex∼pdata[log(1−D(G(z)))]也就越小
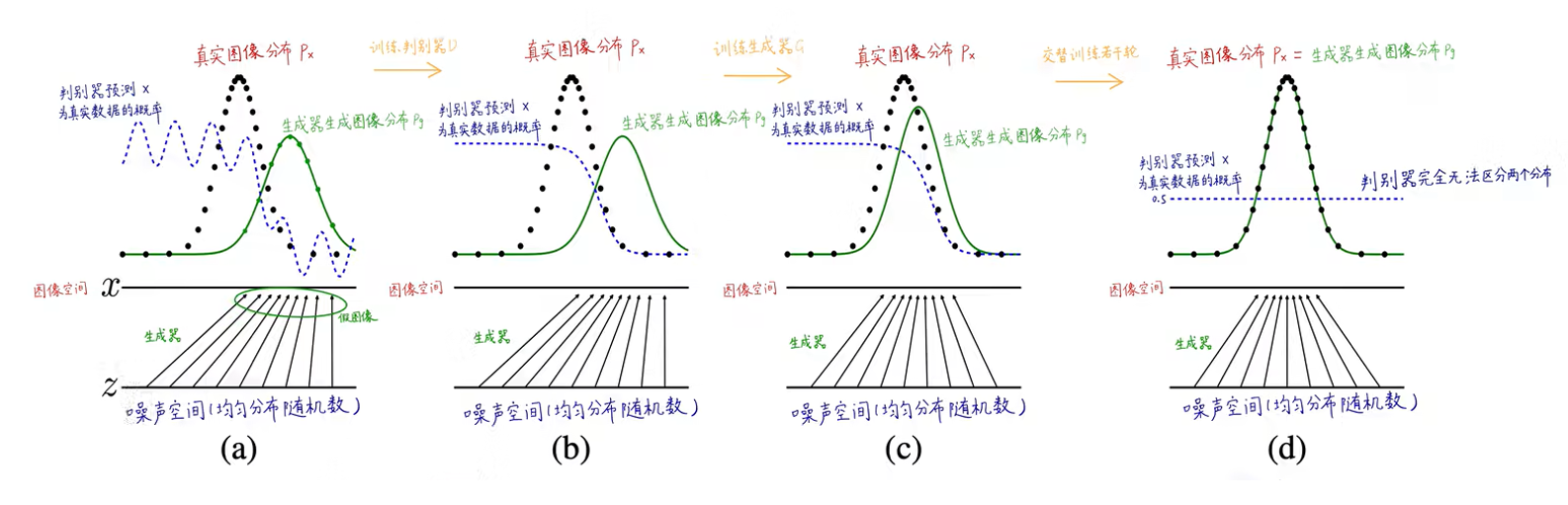
下面是一个图例,用来解释GAN过程
(4)GAN算法流程
GAN算法流程如下:在一次训练过程中,我们是训练k次(k可以取1)判别器,然后训练一次生成器