文章目录
- 1、实验环境
- 2、Prometheus介绍?
- 3、Prometheus特点
- 3.1 样本
- 4、Prometheus组件介绍
- 5、Prometheus和zabbix对比分析
- 6、Prometheus的几种部署模式
- 6.1 基本高可用模式
- 6.2 基本高可用+远程存储
- 6.3 基本HA + 远程存储 + 联邦集群方案
- 7、Prometheus的四种数据类型
- 7.1 Counter
- 7.2 Gauge
- 7.3 histogram
- 7.3.1 为什需要用histogram柱状图?
- 7.4 summary
- 8、Prometheus能监控什么?
- 9、Prometheus对kubernetes的监控
- 10、node-exporter组件安装和配置
- 10.1 node-exporter介绍
- 10.2 安装node-exporter
- 11、Prometheus server安装和配置
- 11.1 创建sa账号,对sa做rbac授权
- 11.2 创建prometheus数据存储目录
- 11.3 安装Prometheus server服务
- 11.3.1 创建一个configmap存储卷,用来存放prometheus配置信息
- 11.3.2 通过deployment部署prometheus
- 11.3.3 给prometheus pod创建一个service
- 11.3.4 Prometheus热加载
- 12、可视化UI界面Grafana的安装和配置
- 12.1 Grafana介绍
- 12.2 安装Grafana
- 12.3 Grafana界面接入Prometheus数据源
- 13、安装kube-state-metrics组件
1、实验环境
实验环境:Prometheus+grafana+alertmanager
k8s集群架构:master+node1+node2
实验文件:
链接:https://pan.baidu.com/s/1DGCNqgcKMKOzzLF_N6jFiQ?pwd=mw57
提取码:mw57
| 节点 | ip |
|---|---|
| master | 192.168.75.150 |
| node1 | 192.168.75.151 |
| node2 | 192.168.75.152 |
2、Prometheus介绍?
Prometheus是一个开源的系统监控和报警系统,现在已经加入到CNCF基金会,成为继k8s之后第二个在CNCF托管的项目,在kubernetes容器管理系统中,通常会搭配prometheus进行监控,同时也支持多种exporter采集数据,还支持pushgateway进行数据上报,Prometheus性能足够支撑上万台规模的集群。
Prometheus配置:
https://prometheus.io/docs/prometheus/latest/configuration/configuration/
Prometheus监控组件对应的exporter部署地址:
https://prometheus.io/docs/instrumenting/exporters/
Prometheus基于k8s服务发现参考:
https://github.com/prometheus/prometheus/blob/release-2.31/documentation/examples/prometheus-kubernetes.yml
3、Prometheus特点
(1)多维度数据模型
每一个时间序列数据都由metric度量指标名称和它的标签labels键值对集合唯一确定:
这个metric度量指标名称指定监控目标系统的测量特征(如:http_requests_total- 接收http请求的总计数)。labels开启了Prometheus的多维数据模型:对于相同的度量名称,通过不同标签列表的结合, 会形成特定的度量维度实例。(例如:所有包含度量名称为/api/tracks的http请求,打上method=POST的标签,则形成了具体的http请求)。这个查询语言在这些度量和标签列表的基础上进行过滤和聚合。改变任何度量上的任何标签值,则会形成新的时间序列图。
(2)灵活的查询语言(PromQL),可以对采集的metrics指标进行加法,乘法,连接等操作;
(3)可以直接在本地部署,不依赖其他分布式存储;
(4)通过基于HTTP的pull方式采集时序数据;
(5)可以通过中间网关pushgateway的方式把时间序列数据推送到prometheus server端;
(6)可通过服务发现或者静态配置来发现目标服务对象(targets)。
(7)有多种可视化图像界面,如Grafana等。
(8)高效的存储,每个采样数据占3.5 bytes左右,300万的时间序列,30s间隔,保留60天,消耗磁盘大概200G。
(9)做高可用,可以对数据做异地备份,联邦集群,部署多套prometheus,pushgateway上报数据
3.1 样本
在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
1、指标(metric):指标名称和描述当前样本特征的 labelsets;
2、时间戳(timestamp):一个精确到毫秒的时间戳;
3、样本值(value): 一个 folat64 的浮点型数据表示当前样本的值。
表示方式:
通过如下表达方式表示指定指标名称和指定标签集合的时间序列:
{
4、Prometheus组件介绍
(1)Prometheus Server: 用于收集和存储时间序列数据。
(2)Client Library: 客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
(3)Exporters: prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter
(4)Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack等。
(5)Grafana:监控仪表盘,可视化监控数据
(6)pushgateway: 各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
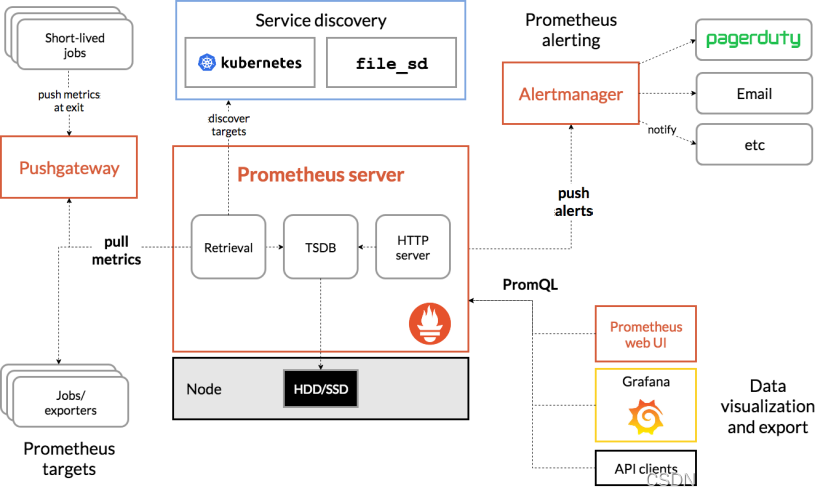
从上图可发现,Prometheus整个生态圈组成主要包括prometheus server,Exporter,pushgateway,alertmanager,grafana,Web ui界面,Prometheus server由三个部分组成,Retrieval,Storage,PromQL
1.Retrieval负责在活跃的target主机上抓取监控指标数据
2.Storage存储主要是把采集到的数据存储到磁盘中
3.PromQL是Prometheus提供的查询语言模块
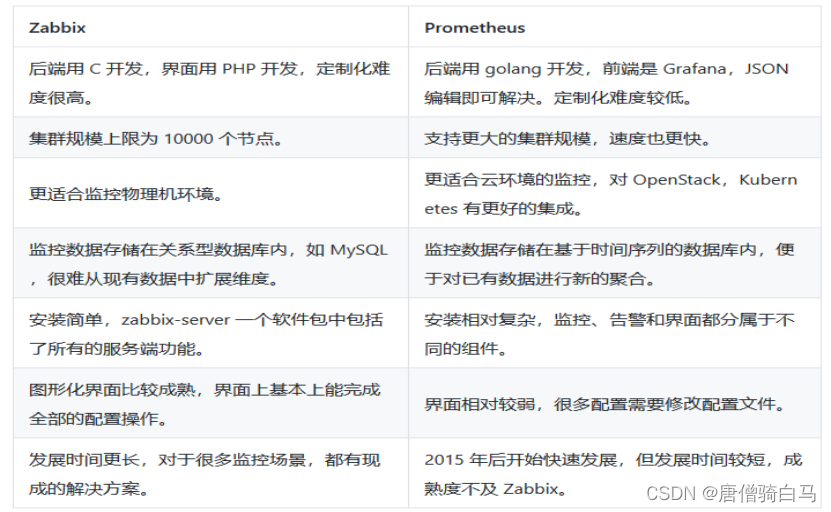
5、Prometheus和zabbix对比分析
6、Prometheus的几种部署模式
6.1 基本高可用模式
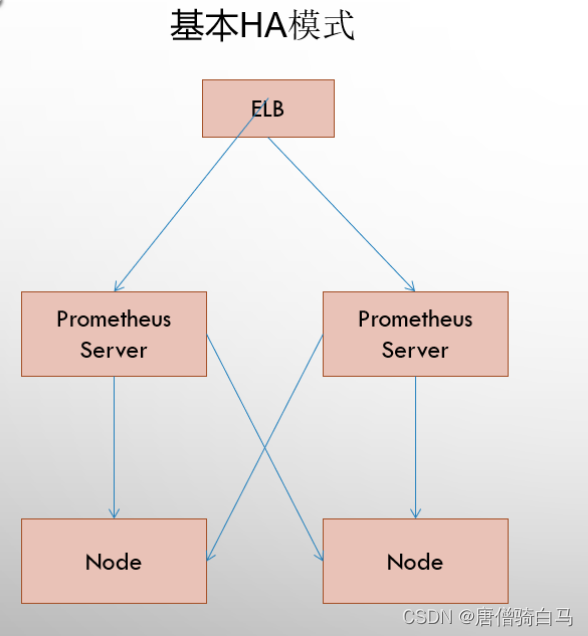
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
6.2 基本高可用+远程存储
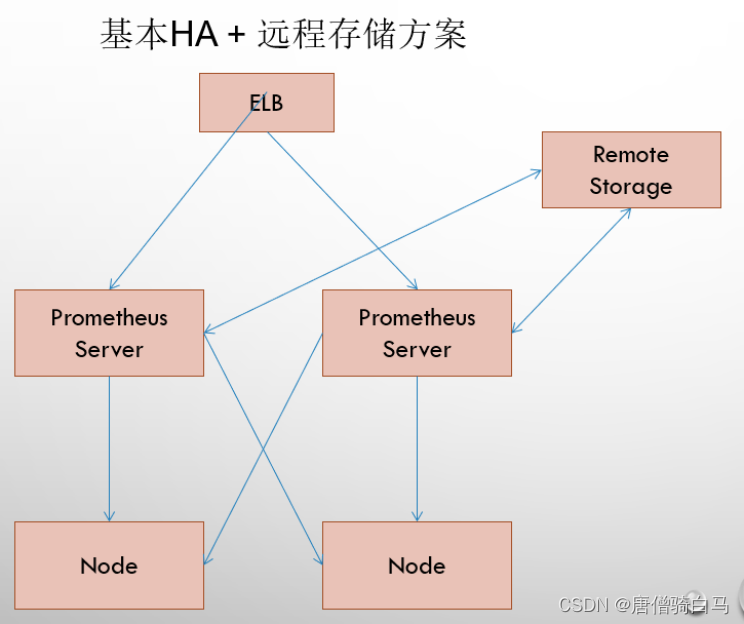
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
6.3 基本HA + 远程存储 + 联邦集群方案
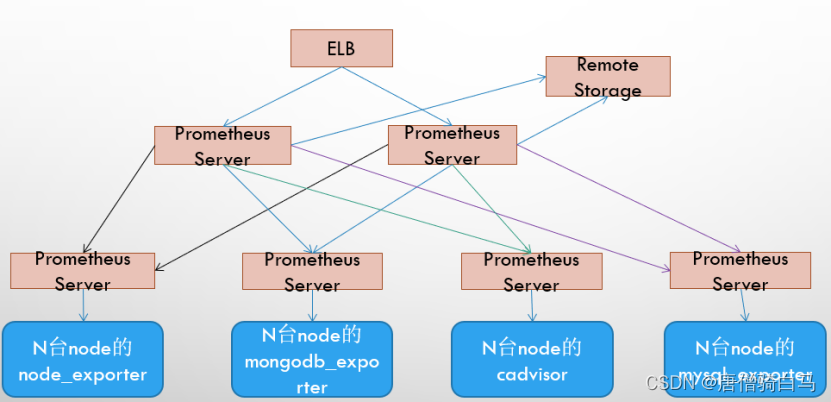
Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
7、Prometheus的四种数据类型
7.1 Counter
Counter是计数器类型:
1、Counter 用于累计值,例如记录请求次数、任务完成数、错误发生次数。
2、一直增加,不会减少。
3、重启进程后,会被重置。
例如:http_response_total{method=“GET”,endpoint=“/api/tracks”} 100
http_response_total{method=“GET”,endpoint=“/api/tracks”} 160
Counter 类型数据可以让用户方便的了解事件产生的速率的变化,在PromQL内置的相关操作函数可以提供相应的分析,比如以HTTP应用请求量来进行说明:
1、通过rate()函数获取HTTP请求量的增长率
rate(http_requests_total[5m])
2、查询当前系统中,访问量前10的HTTP地址
topk(10, http_requests_total)
7.2 Gauge
Gauge是测量器类型:
1、Gauge是常规数值,例如温度变化、内存使用变化。
2、可变大,可变小。
3、重启进程后,会被重置
例如:
memory_usage_bytes{host="master-01"} 100
memory_usage_bytes{host="master-01"} 30
memory_usage_bytes{host="master-01"} 50
memory_usage_bytes{host="master-01"} 80
对于 Gauge 类型的监控指标,通过 PromQL 内置函数 delta() 可以获取样本在一段时间内的变化情况,例如,计算 CPU 温度在两小时内的差异:
dalta(cpu_temp_celsius{host="zeus"}[2h])
你还可以通过PromQL 内置函数 predict_linear() 基于简单线性回归的方式,对样本数据的变化趋势做出预测。例如,基于 2 小时的样本数据,来预测主机可用磁盘空间在 4 个小时之后的剩余情况:
predict_linear(node_filesystem_free{job="node"}[2h], 4 * 3600) < 0
7.3 histogram
histogram是柱状图,在Prometheus系统的查询语言中,有三种作用:
1、在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中. 后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
2、对每个采样点值累计和(sum)
3、对采样点的次数累计和(count)
度量指标名称: [basename]_上面三类的作用度量指标名称
1、[basename]_bucket{le=“上边界”}, 这个值为小于等于上边界的所有采样点数量
2、[basename]_sum
3、[basename]_count
小结:如果定义一个度量类型为Histogram,则Prometheus会自动生成三个对应的指标
7.3.1 为什需要用histogram柱状图?
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 CPU 的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 WEB 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在 0~10ms 之间的请求数有多少,而 10~20ms 之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram 和 Summary 都是为了能够解决这样问题的存在,通过 Histogram 和 Summary 类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram 类型的样本会提供三种指标(假设指标名称为 ):
样本的值分布在 bucket 中的数量,命名为 _bucket{le=“<上边界>”}。解释的更通俗易懂一点,这个值表示指标值小于等于上边界的所有样本数量。
1、http 请求响应时间 <=0.005 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path=“/”,method=“GET”,code=“200”,le=“0.005”,}
0.0
2、http 请求响应时间 <=0.01 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path=“/”,method=“GET”,code=“200”,le=“0.01”,} 0.0
3、http 请求响应时间 <=0.025 秒 的请求次数为0
io_namespace_http_requests_latency_seconds_histogram_bucket{path=“/”,method=“GET”,code=“200”,le=“0.025”,}
0.0
所有样本值的大小总和,命名为 _sum。
7.4 summary
与 Histogram 类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算。它也有三种作用:
1、对于每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
2、统计班上所有同学的总成绩(sum)
3、统计班上同学的考试总人数(count)
带有度量指标的[basename]的summary 在抓取时间序列数据有如命名。
1、观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]{分位数="[φ]"}
2、[basename]_sum, 是指所有观察值的总和
3、[basename]_count, 是指已观察到的事件计数值
样本值的分位数分布情况,命名为 <basename>{quantile="<φ>"}。
1、含义:这 12 次 http 请求中有 50% 的请求响应时间是 3.052404983s
io_namespace_http_requests_latency_seconds_summary{path=“/”,method=“GET”,code=“200”,quantile=“0.5”,} 3.052404983
2、含义: http 请求中有 90% 的请求响应时间是 8.003261666s
io_namespace_http_requests_latency_seconds_summary{path=“/”,method=“GET”,code=“200”,quantile=“0.9”,}
8.003261666
所有样本值的大小总和,命名为 _sum。
1、含义:http 请求的总响应时间为 51.029495508s
io_namespace_http_requests_latency_seconds_summary_sum{path=“/”,method=“GET”,code=“200”,}
51.029495508
样本总数,命名为 _count。
1、含义:当前一共发生了 12 次 http 请求
io_namespace_http_requests_latency_seconds_summary_count{path=“/”,method=“GET”,code=“200”,}
12.0
现在可以总结一下 Histogram 与 Summary 的异同:
它们都包含了 _sum 和 _count 指标
Histogram 需要通过 _bucket 来计算分位数,而 Summary 则直接存储了分位数的值。
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.5"} 0.012352463
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.9"} 0.014458005
prometheus_tsdb_wal_fsync_duration_seconds{quantile="0.99"} 0.017316173
prometheus_tsdb_wal_fsync_duration_seconds_sum 2.888716127000002
prometheus_tsdb_wal_fsync_duration_seconds_count 216
从上面的样本中可以得知当前Promtheus Server进行wal_fsync操作的总次数为216次,耗时2.888716127000002s。其中中位数(quantile=0.5)的耗时为0.012352463,9分位数(quantile=0.9)的耗时为0.014458005s。
8、Prometheus能监控什么?
- Databases
- Hardware related
- Messaging systems
- Storage
- HTTP
- APIs
- Logging
- Other monitoring systems
- Miscellaneous
- Software
- exposing Prometheus metrics
9、Prometheus对kubernetes的监控
对于Kubernetes而言,我们可以把当中所有的资源分为几类:
- 基础设施层(Node):集群节点,为整个集群和应用提供运行时资源
- 容器基础设施(Container):为应用提供运行时环境
- 用户应用(Pod):Pod中会包含一组容器,它们一起工作,并且对外提供一个(或者一组)功能
- 内部服务负载均衡(Service):在集群内,通过Service在集群暴露应用功能,集群内应用和应用之间访问时提供内部的负载均衡
- 外部访问入口(Ingress):通过Ingress提供集群外的访问入口,从而可以使外部客户端能够访问到部署在Kubernetes集群内的服务
因此,如果要构建一个完整的监控体系,我们应该考虑,以下5个方面:
- 集群节点状态监控:从集群中各节点的kubelet服务获取节点的基本运行状态;
- 集群节点资源用量监控:通过Daemonset的形式在集群中各个节点部署Node Exporter采集节点的资源使用情况;
- 节点中运行的容器监控:通过各个节点中kubelet内置的cAdvisor中获取个节点中所有容器的运行状态和资源使用情况;
- 如果在集群中部署的应用程序本身内置了对Prometheus的监控支持,那么我们还应该找到相- 应的Pod实例,并从该Pod实例中获取其内部运行状态的监控指标。
- 对k8s本身的组件做监控:apiserver、scheduler、controller-manager、kubelet、kube-proxy
10、node-exporter组件安装和配置
机器规划:
我的实验环境使用的k8s集群是一个master节点和两个node节点
master节点的机器ip是192.168.75.150,主机名是master
node1节点的机器ip是192.168.75.151,node2节点的机器ip是192.168.75.152
10.1 node-exporter介绍
node-exporter可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括CPU, 内存,磁盘,网络,文件数等信息。
10.2 安装node-exporter
创建namespace
[root@master ~]# kubectl create ns monitor-sa
namespace/monitor-sa created
node-exporter.tar.gz镜像压缩包上传到k8s的各个节点,手动解压:
[root@master ~]# docker load -i node-exporter.tar.gz
[root@node1~]# docker load -i node-exporter.tar.gz
[root@node2~]# docker load -i node-exporter.tar.gz
在master节点上新建node-export.yaml
[root@master ~]# cat node-export.yaml
apiVersion: apps/v1
kind: DaemonSet #可以保证k8s集群的每个节点都运行完全一样的pod
metadata:
name: node-exporter
namespace: monitor-sa
labels:
name: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
# hostNetwork、hostIPC、hostPID都为True时,表示这个Pod里的所有容器,会直接使用宿主机的网络,直接与宿主机进行IPC(进程间通信)通信,可以看到宿主机里正在运行的所有进程。
# 加入了hostNetwork:true会直接将我们的宿主机的9100端口映射出来,从而不需要创建service 在我们的宿主机上就会有一个9100的端口
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15 #这个容器运行至少需要0.15核cpu
securityContext:
privileged: true #开启特权模式
args:
- --path.procfs #配置挂载宿主机(node节点)的路径
- /host/proc
- --path.sysfs #配置挂载宿主机(node节点)的路径
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
#通过正则表达式忽略某些文件系统挂载点的信息收集
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
#将主机/dev、/proc、/sys这些目录挂在到容器中,这是因为我们采集的很多节点数据都是通过这些文件来获取系统信息的。
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
通过kubectl apply更新node-exporter.yaml文件
[root@master ~]# kubectl apply -f node-export.yaml
查看node-exporter是否部署成功,显示如下,看到pod的状态都是running,说明部署成功
[root@master ~]# kubectl get pods -n monitor-sa
NAME READY STATUS RESTARTS AGE
node-exporter-4ncrb 1/1 Running 0 18s
node-exporter-lplpx 1/1 Running 0 18s
node-exporter-ts2m7 1/1 Running 0 18s
通过node-exporter采集数据curl http://主机ip:9100/metrics
node-export默认的监听端口是9100,可以看到当前主机获取到的所有监控数据
curl http://192.168.75.150:9100/metrics | grep node_cpu_seconds
显示192.168.75.150主机cpu的使用情况
[root@master ~]# curl http://192.168.75.150:9100/metrics | grep node_cpu_seconds
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 66081 100 66081 0 0 750k 0 --:--:-- --:--:-- --:--:-- 759k
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 14546.78
node_cpu_seconds_total{cpu="0",mode="iowait"} 11.98
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0
node_cpu_seconds_total{cpu="0",mode="softirq"} 17.92
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 158.94
node_cpu_seconds_total{cpu="0",mode="user"} 66.15
node_cpu_seconds_total{cpu="1",mode="idle"} 14519.68
node_cpu_seconds_total{cpu="1",mode="iowait"} 11.92
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0.05
#HELP:解释当前指标的含义,上面表示在每种模式下node节点的cpu花费的时间,以s为单位
#TYPE:说明当前指标的数据类型,上面是counter类型
node_cpu_seconds_total{cpu="0",mode="idle"} :
cpu0上idle进程占用CPU的总时间,CPU占用时间是一个只增不减的度量指标,从类型中也可以看出node_cpu的数据类型是counter(计数器)
counter计数器:只是采集递增的指标
curl http://192.168.75.150:9100/metrics | grep node_load
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 66190 100 66190 0 0 7358k 0 --:--:-- --:--:-- --:--:-- 8079k
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.32
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.19
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5 0.19
node_load1该指标反映了当前主机在最近一分钟以内的负载情况,系统的负载情况会随系统资源的使用而变化,因此node_load1反映的是当前状态,数据可能增加也可能减少,从注释中可以看出当前指标类型为gauge(标准尺寸)
gauge标准尺寸:统计的指标可增加可减少
11、Prometheus server安装和配置
11.1 创建sa账号,对sa做rbac授权
创建一个sa账号monitor
[root@master ~]# kubectl create serviceaccount monitor -n monitor-sa
serviceaccount/monitor created
把sa账号monitor通过clusterrolebing绑定到clusterrole上
[root@master ~]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created
11.2 创建prometheus数据存储目录
在k8s集群的node1和node2节点上创建数据存储目录
[root@node1~]# mkdir /data
[root@node1~]# chmod 777 /data/
[root@node2~]# mkdir /data
[root@node2~]# chmod 777 /data/
11.3 安装Prometheus server服务
11.3.1 创建一个configmap存储卷,用来存放prometheus配置信息
在master上创建prometheus-cfg.yaml文件,通过kubectl apply更新configmap
[root@xianchaomaster1 prometheus]# kubectl apply -f prometheus-cfg.yaml,prometheus-cfg.yaml文件内容如下:
---
kind: ConfigMap
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus-config
namespace: monitor-sa
data:
prometheus.yml: |
global:
scrape_interval: 15s #采集目标主机监控据的时间间隔
scrape_timeout: 10s # 数据采集超时时间,默认10s
evaluation_interval: 1m #触发告警检测的时间,默认是1m
#我们写了超过80%的告警,结果收到多条告警,但是真实超过80%的只有一个时间点。这是另外一个参数影响的
#evaluation_interval 这个是触发告警检测的时间,默认为1m。假如我们的指标是5m被拉取一次。
#检测根据evaluation_interval 1m一次,所以在值被更新前,我们一直用的旧值来进行多次判断,造成了1m一次,同一个指标被告警了4次。
scrape_configs:
#配置数据源,称为target,每个target用job_name命名。又分为静态配置和服务发现
- job_name: 'kubernetes-node'
kubernetes_sd_configs: #使用的是k8s的服务发现
- role: node # 使用node角色,它使用默认的kubelet提供的http端口来发现集群中每个node节点。
relabel_configs: #重新标记
- source_labels: [__address__] #配置的原始标签,匹配地址
regex: '(.*):10250' #匹配带有10250端口的url
replacement: '${1}:9100' #把匹配到的ip:10250的ip保留
target_label: __address__ #新生成的url是${1}获取到的ip:9100
action: replace
- action: labelmap
#匹配到下面正则表达式的标签会被保留,如果不做regex正则的话,默认只是会显示instance标签
regex: __meta_kubernetes_node_label_(.+)
注意:Before relabeling表示匹配到的所有标签
- job_name: 'kubernetes-node-cadvisor'
# 抓取cAdvisor数据,是获取kubelet上/metrics/cadvisor接口数据来获取容器的资源使用情况
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap #把匹配到的标签保留
regex: __meta_kubernetes_node_label_(.+)
#保留匹配到的具有__meta_kubernetes_node_label的标签
- target_label: __address__
- #获取到的地址:__address__="192.168.75.150:10250"
replacement: kubernetes.default.svc:443
#把获取到的地址替换成新的地址kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
#把原始标签中__meta_kubernetes_node_name值匹配到
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
#把metrics替换成新的值api/v1/nodes/xianchaomaster1/proxy/metrics/cadvisor
#${1}是__meta_kubernetes_node_name获取到的值
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
#使用k8s中的endpoint服务发现,采集apiserver 6443端口获取到的数据
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
#endpoint这个对象的名称空间
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep #采集满足条件的实例,其他实例不采集
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
[root@master prometheus]# kubectl apply -f prometheus-cfg.yaml
11.3.2 通过deployment部署prometheus
将prometheus-2-2-1.tar.gz镜像上次到node1和node2并解压
[root@node1 ~]# docker load -i prometheus-2-2-1.tar.gz
[root@node2 ~]# docker load -i prometheus-2-2-1.tar.gz
在master节点上新建prometheus-deploy.yaml文件,通过kubectl apply更新prometheus,prometheus-deploy.yaml内容如下:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-server
namespace: monitor-sa
labels:
app: prometheus
spec:
replicas: 2
selector:
matchLabels:
app: prometheus
component: server
#matchExpressions:
#- {key: app, operator: In, values: [prometheus]}
#- {key: component, operator: In, values: [server]}
template:
metadata:
labels:
app: prometheus
component: server
annotations:
prometheus.io/scrape: 'false'
spec:
serviceAccountName: monitor
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
imagePullPolicy: IfNotPresent
command:
- prometheus
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention=720h
- --web.enable-lifecycle
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-config
- mountPath: /prometheus/
name: prometheus-storage-volume
securityContext:
runAsUser: 0
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
- name: prometheus-storage-volume
hostPath:
path: /data
type: Directory
[root@master prometheus]# kubectl apply -f prometheus-deploy.yaml
查看prometheus是否部署成功
[root@master prometheus]# kubectl get pods -n monitor-sa -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-4ncrb 1/1 Running 0 53m 192.168.75.152 node2 <none> <none>
node-exporter-lplpx 1/1 Running 0 53m 192.168.75.150 master <none> <none>
node-exporter-ts2m7 1/1 Running 0 53m 192.168.75.151 node1 <none> <none>
prometheus-server-6bbcdc84d8-gtkmt 1/1 Running 0 8m9s 10.244.166.135 node1 <none> <none>
prometheus-server-6bbcdc84d8-zv24s 1/1 Running 0 8m9s 10.244.104.7 node2 <none> <none>
11.3.3 给prometheus pod创建一个service
在master上新建prometheus-svc.yaml文件,内容如下:
[root@master prometheus]# cat prometheus-svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitor-sa
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
selector:
app: prometheus
component: server
通过kubectl apply 更新service,查看service在物理机映射的端口
[root@master prometheus]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@master prometheus]# kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.110.113.224 <none> 9090:31793/TCP 8s
通过上面可以看到service在宿主机上映射的端口是31793,这样我们访问k8s集群的master节点的ip:31793,就可以访问到prometheus的web ui界面了
访问prometheus web ui界面http://192.168.75.150:31793/graph,可看到如下页面:
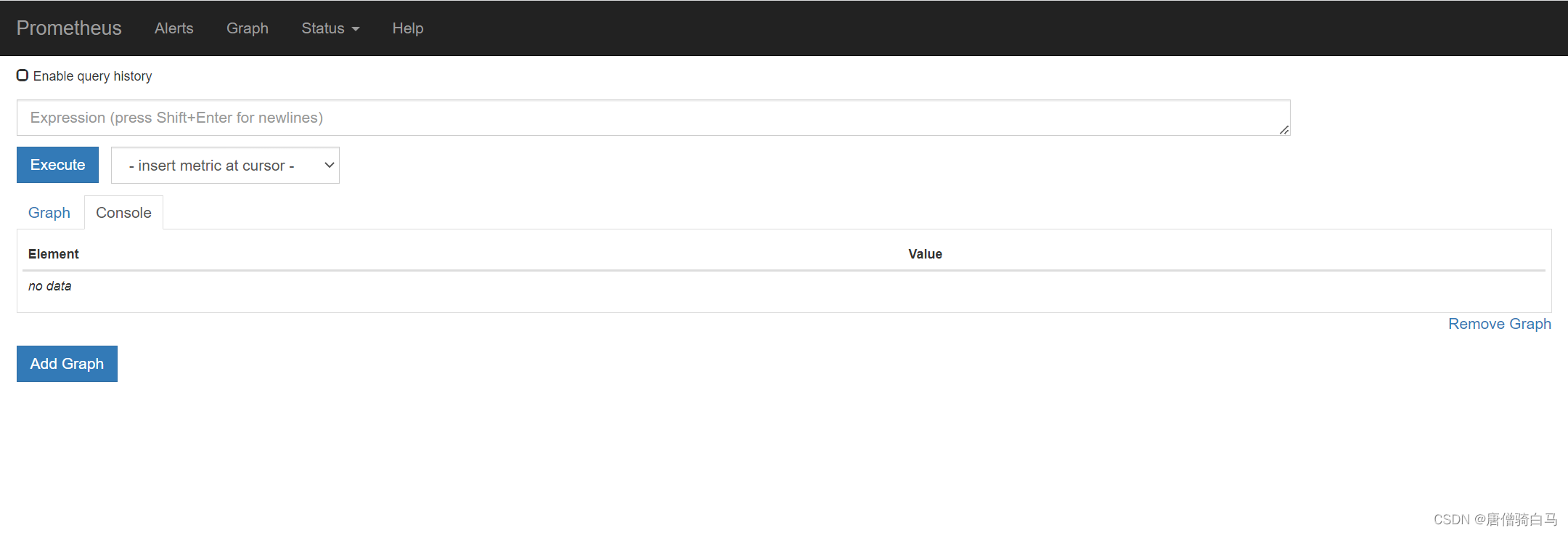
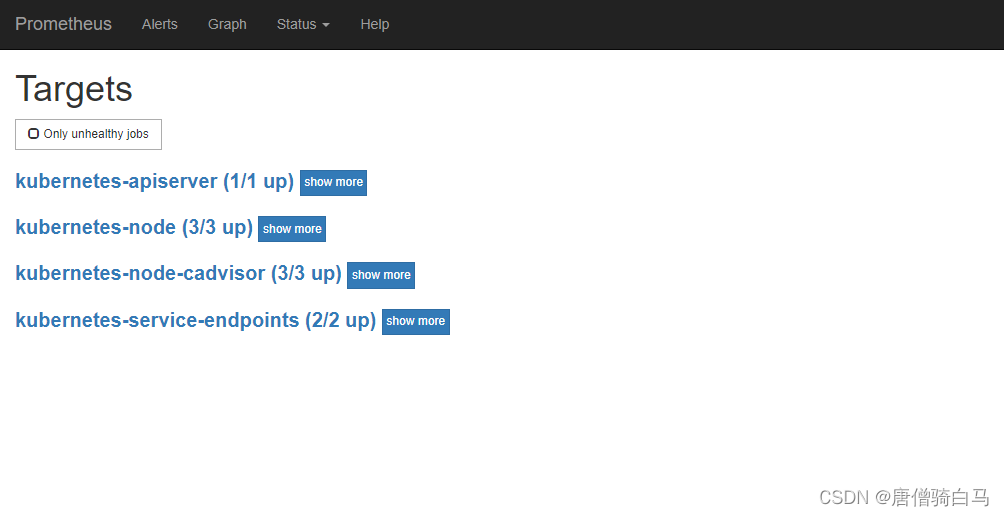
点击页面的Status->Targets,可看到如下,说明我们配置的服务发现可以正常采集数据
11.3.4 Prometheus热加载
为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效,想要使配置生效可用如下热加载命令:
[root@master prometheus]# kubectl get pods -n monitor-sa -o wide -l app=prometheus

想要使配置生效可用如下命令热加载:
[root@master prometheus]# curl -X POST http://10.244.166.135:9090/-/reload
热加载速度比较慢,可以暴力重启prometheus,如修改上面的prometheus-cfg.yaml文件之后,可执行如下强制删除:
kubectl delete -f prometheus-cfg.yaml
kubectl delete -f prometheus-deploy.yaml
然后再通过apply更新:
kubectl apply -f prometheus-cfg.yaml
kubectl apply -f prometheus-deploy.yaml
注意:线上最好热加载,暴力删除可能造成监控数据的丢失
12、可视化UI界面Grafana的安装和配置
12.1 Grafana介绍
Grafana是一个跨平台的开源的度量分析和可视化工具,可以将采集的数据可视化的展示,并及时通知给告警接收方。它主要有以下六大特点:
1、展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
2、数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB等;
3、通知提醒:以可视方式定义最重要指标的警报规则,Grafana将不断计算并发送通知,在数据达到阈值时通过Slack、PagerDuty等获得通知;
4、混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
5、注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记。
12.2 安装Grafana
将Grafana需要的镜像传到k8s的node1和node2节点并解压
root@node1 ~]# docker load -i heapster-grafana-amd64_v5_0_4.tar.gz
在master节点新建grafana.yaml文件,并使用apply更新文件
[root@master prometheus]# cat grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
更新文件
[root@master prometheus]# kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
查看grafana是否创建成功:
[root@master prometheus]# kubectl get pods -n kube-system -l task=monitoring
NAME READY STATUS RESTARTS AGE
monitoring-grafana-7948df75d9-dg5w2 1/1 Running 0 23s
monitoring-grafana-7948df75d9-wczdk 1/1 Running 0 23s
12.3 Grafana界面接入Prometheus数据源
查看grafana前端的service
[root@master prometheus]# kubectl get svc -n kube-system | grep grafana
monitoring-grafana NodePort 10.101.75.37 <none> 80:31985/TCP 2m3s
(1)登陆grafana,在浏览器访问http://192.168.75.150:31985,可看到如下界面:
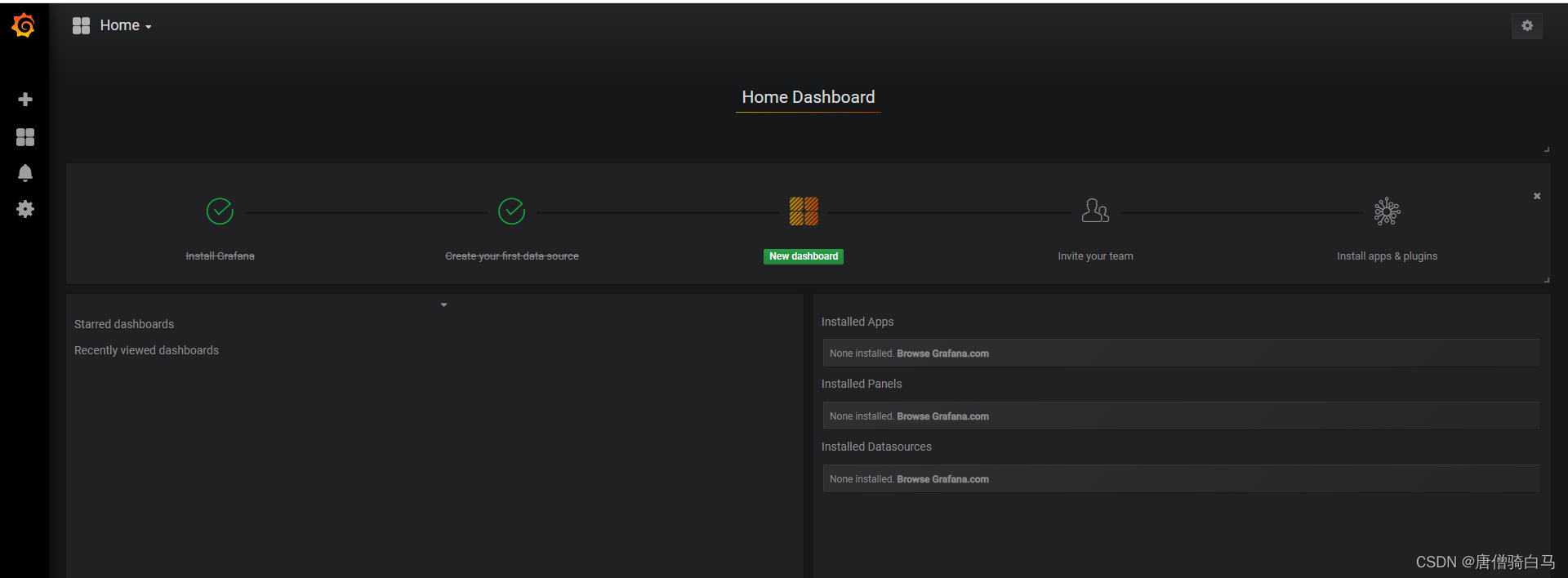
(2)配置grafana界面,开始配置grafana的web界面,选择Create your first data source
填写prometheus配置信息
Name: Prometheus
Type: Prometheus
HTTP 处的URL写 如下:
http://prometheus.monitor-sa.svc:9090,配置好的整体页面如下:
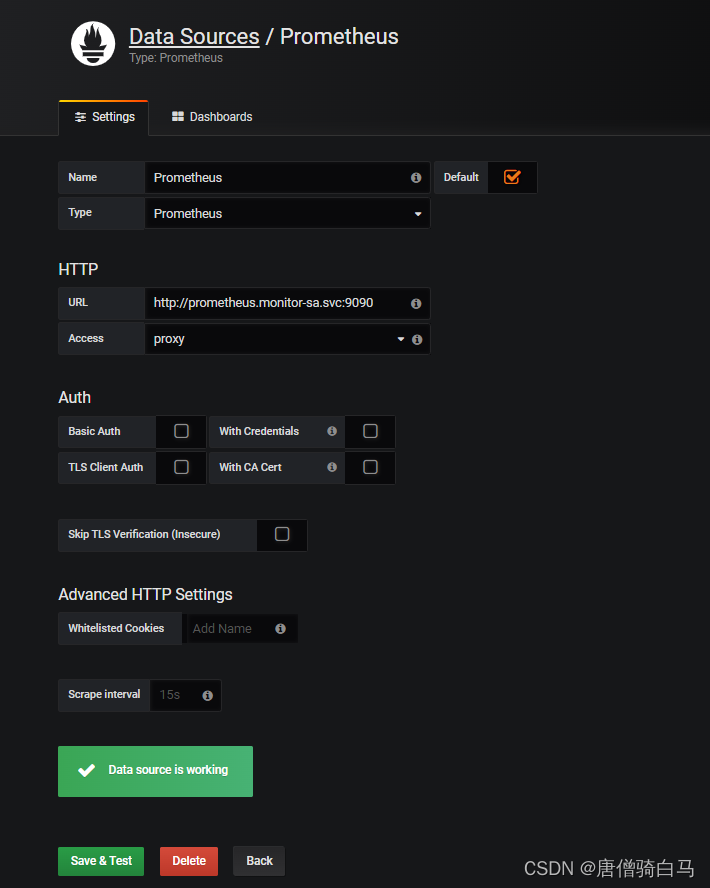
点击左下角Save & Test,出现如下Data source is working,说明prometheus数据源成功的被grafana接入了
导入的监控模板,可在如下链接搜索https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
可直接导入node_exporter.json监控模板,上面Save & Test测试没问题之后,就可以返回Grafana主页面,点击左侧+号下面的Import,出现如下界面
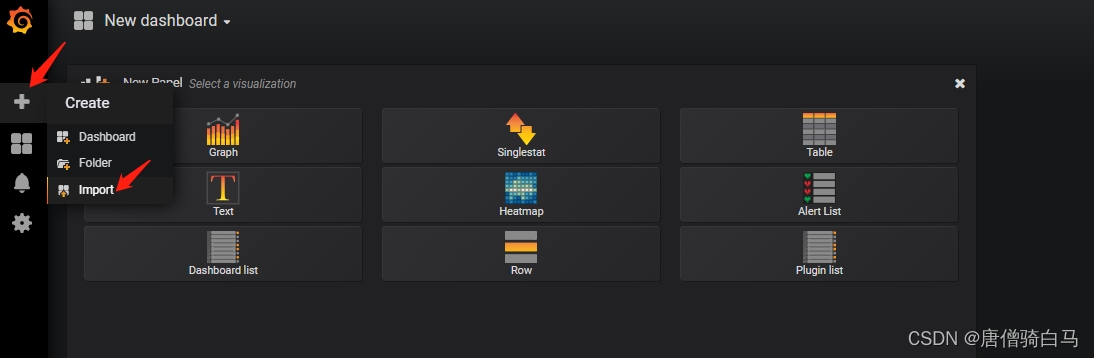
选择Upload json file,将需要 json文件导入即可
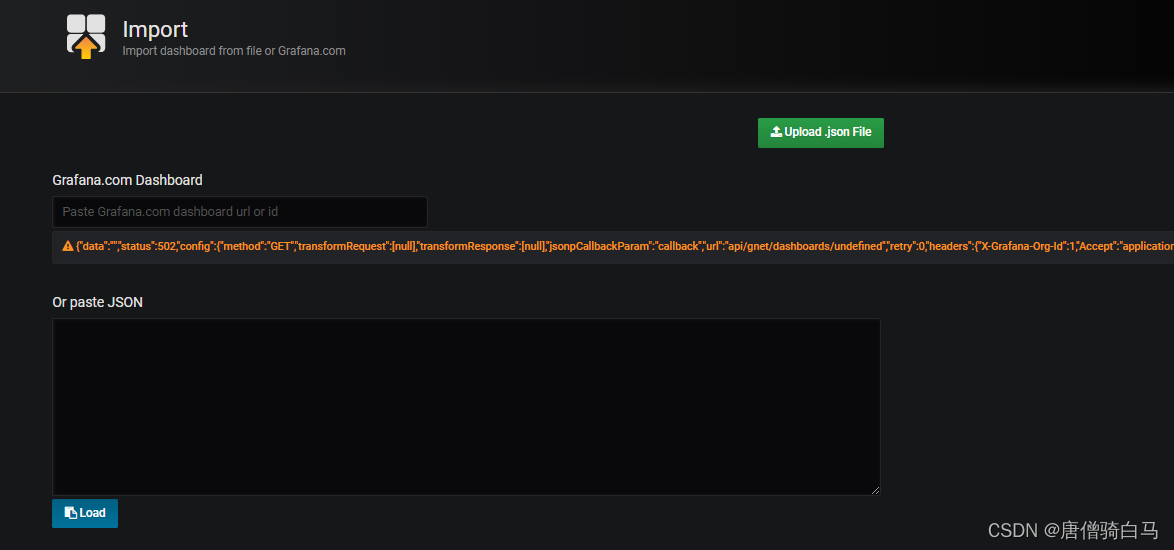
**扩展:**如果Grafana导入Prometheusz之后,发现仪表盘没有数据,如何排查?
1、打开grafana界面,找到仪表盘对应无数据的图标
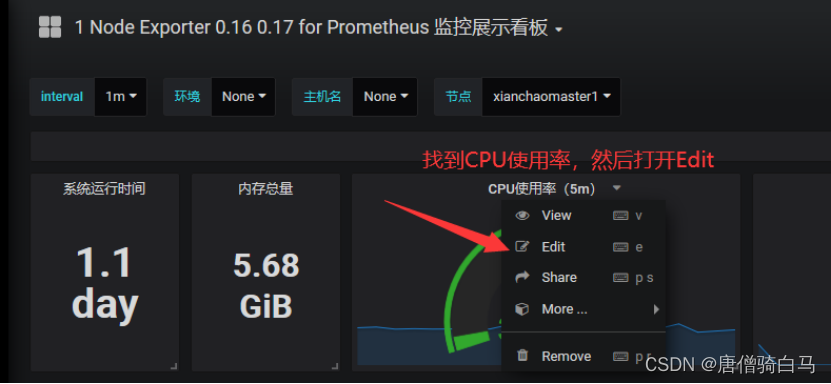
Edit之后出现如下:
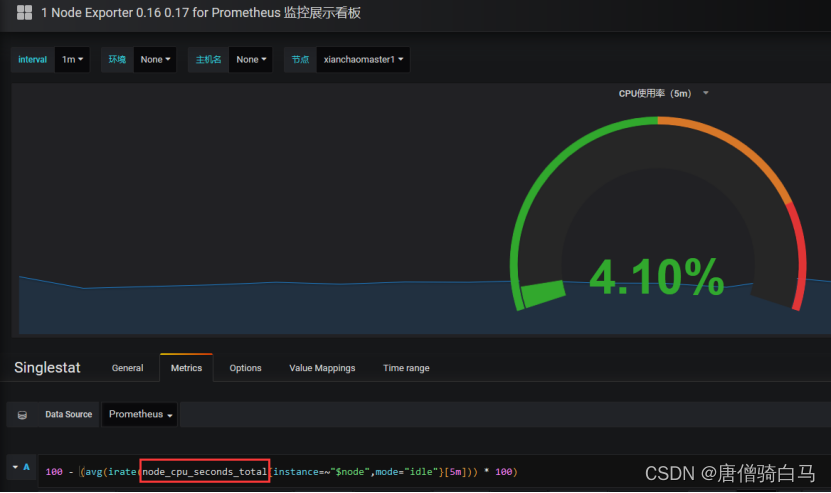
node_cpu_seconds_total 就是grafana上采集的cpu的时间,需要到prometheus ui界面看看采集的指标是否是node_cpu_seconds_total
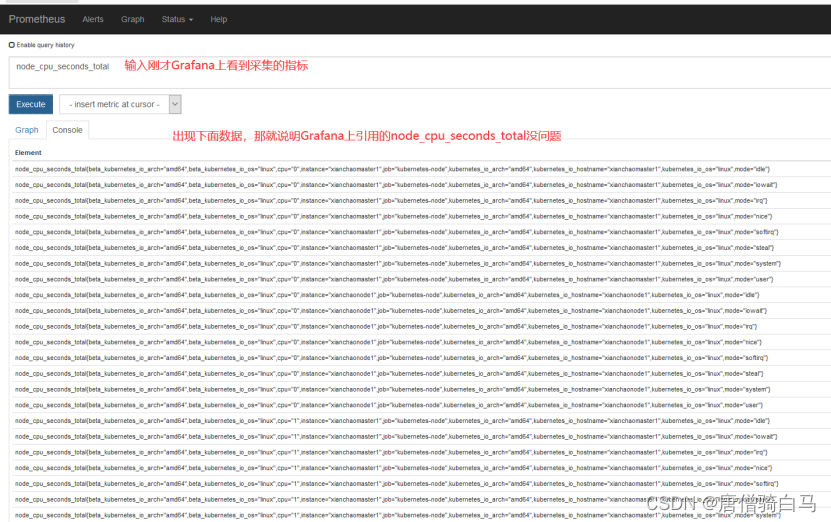
如果在prometheus ui界面输入node_cpu_seconds_total没有数据,那就看看是不是prometheus采集的数据是node_cpu_seconds_totals,怎么看呢?
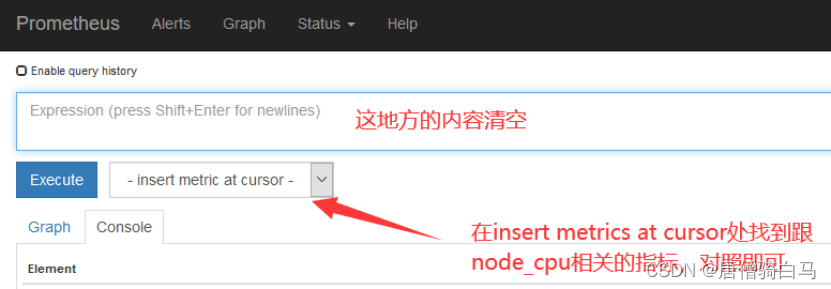
13、安装kube-state-metrics组件
kube-state-metrics是什么?
kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Pod副本状态等;调度了多少个replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?我有多少job在运行中。
安装kube-state-metrics组件
(1)创建sa,并对sa授权
在k8s master节点新建一个kube-state-metrics-rbac.yaml文件,内容如下
[root@master prometheus]# cat kube-state-metrics-rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
[root@master prometheus]# kubectl apply -f kube-state-metrics-rbac.yaml
(2)安装kube-state-metrics组件
在master上新建kube-state-metrics-deploy.yaml文件,内容如下:
[root@master prometheus]# cat kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
查看kube-state-metrics是否部署成功
[root@master prometheus]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-state-metrics-57794dcf65-9zjrg 1/1 Running 0 12s
kube-state-metrics-57794dcf65-jhh9w 1/1 Running 0 12s
(3)创建service
在k8s的控制节点生成一个kube-state-metrics-svc.yaml文件:
[root@master prometheus]# cat kube-state-metrics-svc.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
查看service是否创建成功
[root@master prometheus]# kubectl apply -f kube-state-metrics-svc.yaml
service/kube-state-metrics created
[root@master prometheus]# kubectl get svc -n kube-system | grep kube-state-metrics
kube-state-metrics ClusterIP 10.102.119.195 <none> 8080/TCP 23s
在grafana web界面导入Kubernetes Cluster (Prometheus)-1577674936972.json和Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json
导入Kubernetes Cluster (Prometheus)-1577674936972.json文件
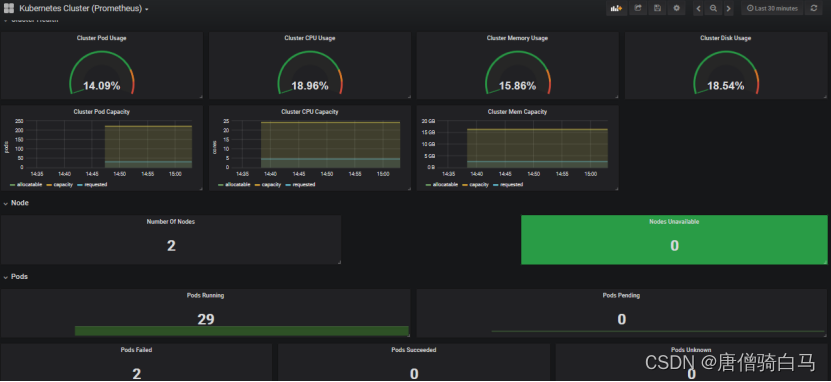
导入之后出现如下页面
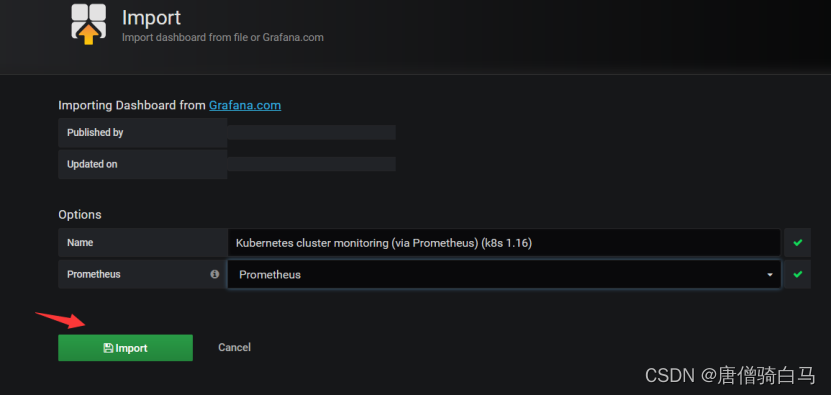
在grafana web界面导入Kubernetes cluster monitoring (via Prometheus) (k8s 1.16)-1577691996738.json
导入之后出现如下页面