Python re正则表达式模块用法详解
前面章节介绍了一些系统自带的工具函数,如 id()、max()。这些函数在 Python 启动时会自动加载进来,不需要我们做任何事情。但并不是所有的模块都是自动加载进来的,因为有些模块不常用,它们只是在完成某个特定任务时才被需要,此时才需要将其加载进来。
正则表达式又被称为规则表达式,英文名为 Regular Expression。正则表达式是计算机科学的一个概念,通常被用来检索、替换那些符合某个模式的文本。现代编程语言基本都内嵌了正则表达式的库,如 Perl、Python 也不例外。虽然各种语言和库定义的正则表达式的语法规则会有所不同,但基本内容是相同的。
Python 虽然自带正则表达式库 re,但是该库不是自动加载进内存的,需要使用下面的语句来引入:
import re
正则表达式的基础是匹配。匹配操作有两个输入,一个是规则,另一个是输入字符串。在匹配的基础上可以进行替换、检索等操作。
一个简单的例子便是检查用户输入的邮箱地址是否合法,合法的邮箱地址应该符合下面的形式:
用户名 @ 主机地址
这里假定用户名可以包含 26 个字母和 10 个数字;主机地址是用小数点( . )分割的分段,每个分段可以出现的字符和用户名中可以出现的字符相同。这里只是一个假设,实际格式要复杂得多。下面的代码演示了如何判断某个输入是否是合法的邮箱地址。
>>> import re # 引入正则表达式库
>>> def valid_email_address(addr): # 定义函数
... result = re.match(r"^[a-zA-Z0-9]+@[a-zA-Z0-9]+(\.[a-zA-Z0-9]+)*$",
addr)
... if result is not None: # 匹配成功
... print("[%s] is a valid email address" % addr)
... else: # 匹配失败
... print("[%s] is NOT a valid email address" % addr)
... # 函数定义结束
>>> valid_email_address("name") # 判断name是否为合法的邮箱地址
[name] is NOT a valid email address # 不是合法的邮箱地址
>>> valid_email_address("name@") # 判断name@是否为合法的邮箱地址
[name@] is NOT a valid email address # 不是合法的邮箱地址
# 判断name@126.com是否为合法的邮箱地址
>>> valid_email_address("name@126.com")
[name@126.com] is a valid email address # 是合法的邮箱地址
元字符和语法
在正则表达式中,定义了一些元字符。这些字符一般用来匹配一组字符,如希望匹配 0~9 这 10 个数字字符,那么便可以使用元字符 \d。元字符一般是以 \ 开头,后面再跟着一个字符。
另外有些语法是描述某个或者某组字符出现的频率的,例如,如果认为某个字段是可选的,则可以指定其出现的频率是 0 或者 1。
下面介绍一下 Python 中正则表达式的常用元字符和语法。
1) 任意字符
任意字符可以表示除换行之外的任意字符。
>>> input_str = "abcdefgh" # 搜索的字符串
>>> result = re.match("a.c", input_str) # 在input_str中查找符合a.c的字符串
>>> result is None # 如果没有找到会返回None
False # 找到了
>>> input_str[result.start():result.end()] # 显示匹配的字符串
'abc'
2) \(转义符)
假设要找到符合条件的字符串:以 a 开头,后面跟着 .. 再后面是任意字符,最后是 xxx。如果按照前面的方法来写如下:
a..xxx
. 表示任意字符,所以其表示的含义是以 a 开头,后面是任意两个字符,最后是 xxx。
这和我们期望的是不同的。为了解决该问题,需要使用转义符,转义符的作用就是使元字符无效,如 . 表示任意非换行字符,而 \. 就表示普通的小数点。下面的代码演示了所讨论的情况。
>>> input_str = "abcxxx" # 这个应该是不符合要求的
>>> result = re.match(r"a..xxx", input_str)
>>> result is None
False
>>> input_str[result.start():result.end()] # 显示匹配的字符串
'abcxxx'
# 修改匹配规则,使用\.表示小数点
>>> result = re.match(r"a\..xxx", input_str)
>>> result is None # 是否能找到匹配的字符串
True # 不能
\ 后面可以跟任何元字符,如表示任意字符的 .,表示转义的 \,即 \\ 表示普通的反斜杠 \。下面的例子演示了 \\ 的用法。
input_str = r"c:\python2" >>> result = re.match(r"c:\\py", input_str) >>> result is None False >>> input_str[result.start():result.end()] 'c:\\py'
3) [候选字符列表]
[候选字符列表] 表示任意候选字符中的字符。如 [abc] 表示 abc 中的任意字符,所以可以匹配 a,也可以匹配 b,还可以匹配 c。但不能匹配 y,也不能匹配 A。
下面的例子演示了其用法。
>>> input_str = "abcdefgh" >>> result = re.match(r"[abc]bc", input_str) # 匹配以abc中的一个字符开头,跟着bc的字符串 >>> input_str[result.start():result.end()] 'abc' # 结果匹配了字符串abc >>> input_str = "bbcdefgh" # 匹配以abc中的一个字符开头,跟着bc的字符串 >>> result = re.match(r"[abc]bc", input_str) >>> input_str[result.start():result.end()] 'bbc' # 结果匹配了字符串bbc
另外一个用法是 [开始字符-结束字符],表示从开始字符到结束字符中的任意字符,包括开始字符和结束字符。如 [a-c] 可以匹配 a、b 或者 c。下面演示该用法。
>>> input_str = "abc" # 输入字符 >>> result = re.match(r"[a-x]bc", input_str) # 匹配以a-x中的一个字符开头,跟着bc的字符串 >>> result is None # 如果匹配不上,返回None False # 匹配上了 >>> input_str[result.start():result.end()] # 显示匹配的字符串 'abc' >>> input_str = "Abc" # 输入字符以大写的A开始 >>> result = re.match(r"[a-x]bc", input_str) # 匹配以a-x开头,跟着bc的字符串 >>> result is None # 如果匹配不上,返回None True # 没有匹配上
也可以使用 [^….] 来表示匹配不在 … 范围内定义的字符。如 [^a-b] 表示非 a~b 的任意字符。下面演示了这种用法。
>>> input_str = "Abc" >>> result = re.match(r"[^a-x]bc", input_str) >>> result is None # 匹配失败则返回None False >>> input_str[result.start():result.end()] # 显示匹配的字符串 'Abc'
4) \d(单个数字字符)
\d 等效于 [0-9]。
>>> input_str = "0123456789" # 输入字符串 >>> result = re.match(r"\d\d\d", input_str) # 匹配3个数字字符 >>> result is None # 匹配失败则返回None False >>> input_str[result.start():result.end()] # 显示匹配的字符串 '012'
5) \D(单个非数字字符)
\D 等效于除了 0~9 之外的任意字符,等效于 [^0-9]。
>>> input_str = "0123456789" >>> result = re.match(r"\D", input_str) >>> result is None True
6) \s(空白字符)
空白字符包含空格、回车 \r、换行 \n、制表 \t、垂直制表 \v、换页 \f。
>>> input_str = "01234\n56789" # 输入字符串 >>> re_obj = re.compile(r"4\s5") # 匹配的目标字符串格式 >>> result = re.search(re_obj, input_str) # 查找 >>> result.start() # 开始位置 4 >>> result.end() # 结束位置 7 >>> input_str[result.start():result.end()] # 匹配的字符串 '4\n5'
7) \S(非空白字符)
这里是大写的 S。下面的例子是查找单词,使用 \S+ 表示不包含空格字符的字符串。
>>> input_str = "abc def ijk" # 输入字符串 >>> re_obj = re.compile(r"\S+") # 查找模式 >>> result = re.search(re_obj, input_str) # 查找 >>> result.start() # 开始位置 0 >>> result.end() # 结束位置,该位置的字符不被包含 3 >>> input_str[result.start():result.end()] # 查看匹配的字符串 'abc'
8) \w(单词字符)
单词字符包括大小写字母、数字、下划线,不包括空格、$、# 等。
>>> input_str = "abc%def$ijk" # 输入字符,其中的%是不能匹配\w的 >>> re_obj = re.compile(r"\w+") >>> result = re.search(re_obj, input_str) >>> result.start() 0 >>> result.end() 3 >>> input_str[result.start():result.end()] 'abc'
9) \W(非单词字符)
\W 即非 \w 所包含的字符。
>>> input_str = "!@#$%^&*()_+abc" >>> re_obj = re.compile(r"\W+") >>> result = re.search(re_obj, input_str) >>> result.start() 0 >>> result.end() 10 >>> input_str[result.start():result.end()] '!@#$%^&*()'
10) *(任意多个)
* 表示 0 或者多个前面的字符。
>>> input_str = "aaaaaaaaabc" # 输入字符串 >>> re_obj = re.compile(r"a*bc") # 任意多个a后面跟着bc >>> result = re.search(re_obj, input_str) # 查找 >>> result.start() # 开始位置 0 >>> result.end() 11 >>> input_str[result.start():result.end()] # 查找的结果 'aaaaaaaaabc' >>> input_str = "bcdef" # 新的输入数据 >>> re_obj = re.compile(r"a*bc") # 查找模式没有发生变化 >>> result = re.search(re_obj, input_str) # 查找 >>> result.start() 0 >>> result.end() 2 >>> input_str[result.start():result.end()] # 查找结果 'bc'
11) +(一个或者多个)
+ 表示 1 个或者多个前面的字符。
>>> input_str = "aaaaaaaaabc" >>> re_obj = re.compile(r"a+bc") >>> result = re.search(re_obj, input_str) >>> result.start() 0 >>> result.end() 11 >>> input_str[result.start():result.end()] 'aaaaaaaaabc' >>> input_str = "bcdef" # 要求至少有一个a,但是输入字符串没有包括a >>> re_obj = re.compile(r"a+bc") # 匹配格式 >>> result = re.search(re_obj, input_str) # 进行查找 >>> result is None # 如果匹配失败,则返回None True # 匹配失败
12) ?(1个或者0个)
? 表示 0 个或者 1 个前面的字符。
>>> input_str = "aaaaaaaaabc" >>> re_obj = re.compile(r"a?bc") # 表示1个或者0个a,后面跟着bc >>> result = re.search(re_obj, input_str) # 查找 >>> result is None # 查找是否失败 False # 没有失败 >>> result.start() # 查找结果的开始位置 8 >>> result.end() # 查找结果的结束位置 11 >>> input_str[result.start():result.end()] # 查找的结果 'abc' >>> input_str = "bcdef" # 新的输入字符串 >>> re_obj = re.compile(r"a?bc") # 匹配模式没有变化 >>> result = re.search(re_obj, input_str) # 查找操作 >>> result is None # 匹配是否失败 False # 没有失败 >>> result.start() # 查找结果的开始位置 0 >>> result.end() # 查找结果的结束位置 2 >>> input_str[result.start():result.end()] # 查找的结果 'bc'
13) {m}(出现指定次数)
{m} 表示 m 个前面的字符。m 可以为 0,表示不出现该字符。
>>> input_str = "aaaaaaaaabc" # 输入字符串
>>> re_obj = re.compile(r"a{3}bc") # 表示3个a后面跟着bc
>>> result = re.search(re_obj, input_str) # 查找
>>> result is None # 匹配是否失败
False # 没有失败
>>> result.start() # 匹配开始的位置
6
>>> result.end() # 匹配结束的位置
11
>>> input_str[result.start():result.end()] # 匹配的字符串
'aaabc'
>>> input_str = "aaaaaaaaabc" # 输入字符串没有改变
>>> re_obj = re.compile(r"a{4}bc") # 表示4个a后面跟着bc
>>> result = re.search(re_obj, input_str)
>>> result is None
False
>>> result.start()
5
>>> result.end()
11
>>> input_str[result.start():result.end()] # 匹配的字符串
'aaaabc'
>>> input_str = "aaaaaaaaabc" # 输入没有改变
>>> re_obj = re.compile(r"a{0}bc") # m=0的情况
>>> result = re.search(re_obj, input_str) # 查找
>>> result is None
False
>>> result.start()
9
>>> result.end()
11
>>> input_str[result.start():result.end()] # 匹配的结果
'bc'
14) {m,n}(指定出现次数的范围)
{m,n} 表示 m 到 n 个前面的字符。如 1{1,2} 可以匹配 1 和 11 两个字符串。IPv4 中定义的 IP 地址格式比较统一,是由 4 段数字组成,段与段之间用 . 分割,段的长度在 1~3 之间。
下面的例子演示了如何定义 IPv4 的 IP 地址:
>>> input_str = "127.0.0.1" # 合法的IPv4的IP地址
>>> result = re.match(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", input_str)
>>> result is None
False
>>> input_str[result.start():result.end()] # 匹配的结果
'127.0.0.1'
>>> input_str = "127.0.0" # 不合法的地址,少了一段
>>> result = re.match(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", input_str)
>>> result is None # 匹配是否失败
True # 匹配失败
>>> input_str = "127.0.0.1000" # 新输入
>>> result = re.match(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", input_str)
>>> result is None
False
>>> input_str[result.start():result.end()] # 显示匹配内容
'127.0.0.100' # 可以看到最后一个字符0没有被匹配上
>>> input_str = "1270.0.0.100" # 新输入
>>> result = re.match(r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}", input_str)
>>> result is None # 没有匹配成功
True
15) ^(开头)
^ 字符表示的是输入的第一个字符,如 ^ab 可以匹配上 ab,但不能匹配上 mab。因为 mab 的第一字符是 m 而不是 a。
>>> re_obj = re.compile(r"^abc") # 匹配以abc开头的字符串 >>> input_str = "aaaaaaaaabc" # 输入字符串 >>> result = re.search(re_obj, input_str) # 查找 >>> result is None # 匹配是否失败 True # 匹配失败 >>> input_str = "abcd" # 新的输入字符串 >>> result = re.search(re_obj, input_str) # 查找 >>> result is None # 匹配是否失败 False # 没有失败 >>> result.start() 0 >>> result.end() 3 >>> input_str[result.start():result.end()] # 匹配的内容 'abc'
16) $(结尾)
$ 表示输入字符串的结尾字符,如 abc$ 可以匹配成功 abc,但不能匹配上 abcd,因为 abcd 的最后一个字符是 d,而不是 c。
>>> re_obj = re.compile(r"abc$") # 匹配规则,以abc结尾的字符串 >>> input_str = "-----abcd" # 输入字符串 >>> result = re.search(re_obj, input_str) # 查找 >>> result is None # 匹配是否失败 True # 匹配失败 >>> input_str = "-----abc" # 新的输入字符串 >>> result = re.search(re_obj, input_str) # 查找 >>> result is None # 匹配是否失败 False # 没有失败 >>> result.start() 5 >>> result.end() 8 >>> input_str[result.start():result.end()] # 匹配的字符串 'abc'
C风格接口函数
这类接口直接使用函数,而不用创建正则表达式对象,或者说正则表示式用字符串表示。其主要包括匹配、查找、替换等接口函数。
1) search():查找
search() 接口函数在整个字符串内查找能够匹配上的子字符串。如果找到匹配的字符串,返回一个 re.Match 对象;如果未找到,返回 None。
如果给定一个输入 abc1234ef876,想得到第一个子数字串 1234,那么可以使用该函数来实现。
>>> input_str = "abc1234ef876" # 输入字符串 >>> result = re.search(r"\d+", input_str) # 使用\d+进行配置 >>> result is None # 匹配是否失败 False >>> input_str[result.start():result.end()] # 显示匹配的字符串 '1234'
从上面的例子也可以看出,如果有多个符合条件可以成功匹配的子字符串,search() 仅返回第一个符合条件的子字符串。如上例中其实可以找到两个符合条件的子字符串,即 1234 和 876,但是 search() 仅返回第一个,即 1234。
2) match():匹配
match() 从输入字符串头部开始匹配,如果匹配不成功,返回 None;如果匹配成功,返回 re.Match 对象。
3) sub():替换
sub() 接口函数接受匹配模式,输入字符串和替换字符串,它在输入字符串中查找符合匹配模式的子字符串,并用替换字符串来替换匹配的字符串,得到一个新的字符串。其最常用的格式如下:
re.sub(匹配模式,替换字符串,输入字符串)
如输入字符串是 abc123kjl,匹配模式是 \d+,则可以匹配的子字符串是 123,替换字符串是 ===,那么得到的返回值是字符串 abv===kjl。
下面是该例子的演示效果:
>>> re.sub(r"\d+", "===", "abc123kjl") # 替换 'abc===kjl'
如果匹配不成功,则返回值为输入字符串。如下面的例子,要求匹配 8 个连续数字字符,但输入字符串中没有 8 个连续的数字字符,即找不到可以进行替换的子字符串,那么返回值就是输入字符串。
>>> re.sub(r"\d{8}", "===", "abc123kjl") # 没有匹配的情况
'abc123kjl'
默认情况下,该接口对所有符合条件的子字符串进行替换操作。如下面的例子,对所有的 a 用 A 进行替换,
>>> re.sub(r"a", "A", "abc123abcABC") 'Abc123AbcABC'
如果不希望替换所有符合条件的子字符串,则可以使用参数 count,该参数表示最多替换的次数。下面的例子演示了这种用法,其仅替换一个匹配的,即第一个匹配的字符串,其他的匹配不被替换。
>>> re.sub(r"a", "A", "abc123abcABC", count=1) 'Abc123abcABC'
面向风格接口函数
面向风格接口函数的用法是首先产生一个正则表达式对象,然后调用该对象的接口函数来完成匹配、查找及替换等功能。
可以用字符串来生成正则表达式对象,使用的是 re.compile() 函数。下面的例子演示了该函数的使用。
>>> re_obj = re.compile(r'\d\d\d') # 得到正则表达式对象
>>> re_obj
re.compile('\\d\\d\\d')
>>> type(re_obj)
<class 're.Pattern'>
re.Match对象
re.Match 对象在前面已经使用过了,该对象表示匹配结果。前文也使用该对象的 start() 和 end() 接口函数来得到匹配的开始和结束位置,但该类型对象还有一些其他属性和方法需要进一步了解。
1) start():匹配开始位置
start() 用于匹配开始位置。对于 match() 函数返回的 Match 对象,该值永远为 0,因为 match() 函数是从输入字符串的头部开始匹配的,如果第一个字符不能被匹配上,则匹配失败。
>>> match_obj = re.match(r"a+", "Aabc") # 第一个字符不匹配,所以失败 >>> match_obj is not None # 匹配成功 False
如果匹配成功,start() 一定是 0,因为是从字符串的头部开始匹配的。
>>> match_obj = re.match(r"a+", "aaaabc") # 可以匹配上开头的aaaa >>> match_obj is not None # 匹配是否成功 True >>> match_obj.start() # 匹配子字符串在输入字符串中的开始位置 0
而对于 search() 则不同,其匹配上的子字符串可以在输入字符串的中间或者结尾。
>>> match_obj = re.search(r"a+", "Aabc") # 查找 >>> match_obj is not None # 查找是否成功 True >>> match_obj.start() # 找到的字符串的开始位置 1
2) end():匹配结束位置
end() 用于匹配结束位置。
>>> match_obj = re.search(r"a+", "Aaabc") >>> match_obj is not None # 是否找到符合要求的子字符串 True >>> match_obj.end() # 结束位置是3 3
需要注意的是,input_string[end] 不是匹配的最后一个字符,而是最后一个匹配字符的后一个字符,最后一个字符是 input_string[end-1]。
>>> input_string = "AaabcKL" # 输入字符串 # 查找,可以匹配上aabc >>> match_obj = re.search(r"[a-z]+", input_string) # end()表示结束位置,不是最后一个匹配的字符 >>> input_string[match_obj.end()] 'K' # 该位置的字符是K,而不是c >>> input_string[match_obj.end()-1] # end()-1才是最后一个匹配字符的位置 'c'
3) span():匹配的字符串的跨度
span() 接口函数返回一个包含两个元素的元组,第一个元素表示匹配开始的位置,第二个元素表示匹配结束的位置,即该接口同时返回了 start() 和 end() 的值。
>>> input_str = "abc123ABC" # 输入字符串 >>> match_obj = re.search(r"\d+", input_str) # 查找连续数字字符 >>> match_obj is not None # 匹配成功? True >>> match_obj.start() # start(),得到匹配开始的位置 3 >>> match_obj.end() # end(),得到匹配结束的位置 6 >>> match_obj.span() # span(),同时得到开始和结束的位置 (3, 6)
4) groups()
groups() 得到所有的分组信息,返回值是一个列表。前面匹配过邮箱地址,该地址由两部分组成,第一部分是用户名,第二部分是主机名。如果想同时得到用户名和主机名,那么就可以使用分组的方式。方法就是在模式中将某一部分用 () 包裹起来,便可以得到一个组。
>>> def pass_email_addr(addr): # 返回邮箱地址中的用户名和主机名
... match_obj = re.match(r"([a-zA-Z0-9]+)@([a-zA-Z0-9]+(\.[a-zA-
Z0-9]+)*)",
... addr)
... if match_obj is not None:
... return match_obj.groups()[0], match_obj.groups()[1]
... else: # 非法邮箱地址
... return None # 返回None
... # 函数定义结束
>>> pass_email_addr("hello@python.cn") # 分析邮箱地址
('hello', 'python.cn') # 得到用户名和主机名
接下来举几个用re模块实现网页爬虫获取数据的例子:
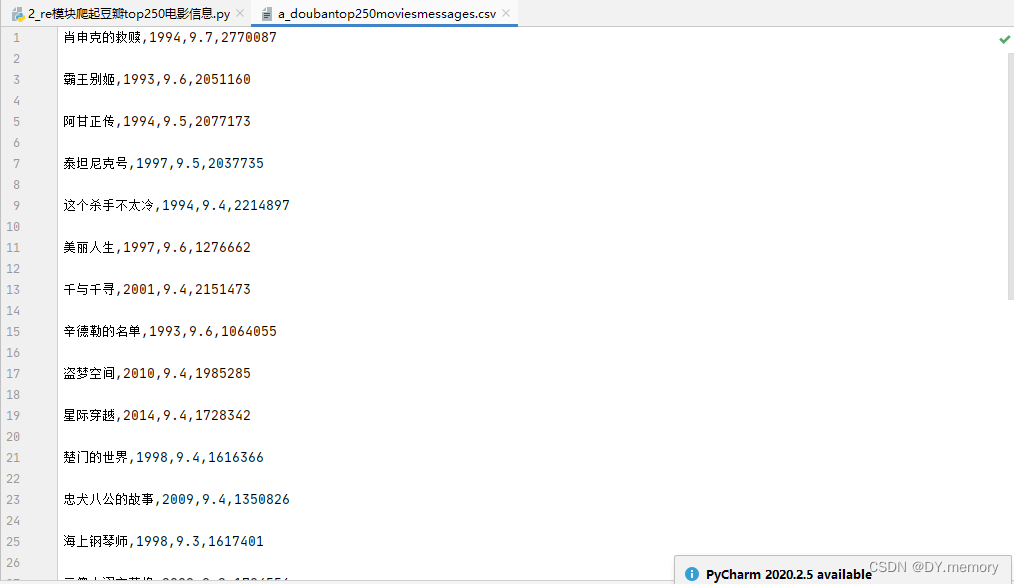
1: 获取豆瓣榜电影信息
import requests
import re
import csv
url="https://movie.douban.com/top250"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36"
}
response=requests.get(url,headers=headers)
page_contect=response.text
# 正则解析数据
obj=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<num>.*?)人评价</span>',re.S)
# 开始匹配
f=open("a_doubantop250moviesmessages.csv",mode="w",encoding="utf-8")
csvwriter=csv.writer(f)
result=obj.finditer(page_contect)
for iter in result:
print(iter.group("name"))
print(iter.group("score"))
print(iter.group("num"))
print(iter.group("year").strip())
dict=iter.groupdict()
dict["year"]=dict["year"].strip()
csvwriter.writerow(dict.values())
print("everything is over!!!")
f.close()