文章目录
- 1 urllib库的使用
- 1.1 urllib.request
- 发送请求获得响应数据
- 一个类型六个方法
- 内容下载
- 定制请求对象
- 1.2 urllib.parse
- get请求编码
- post请求编码
- 1.3 ajax的get请求示例
- 1.4 ajax的post请求示例
- 1.5 Handler处理器
- 1.6 代理服务器
- 2 解析
- 2.1 xpath
- 2.2 JsonPath
- 2.3 BeautifulSoup
1 urllib库的使用
urllib.request.urlopen() 模拟浏览器向服务器发送请求
response 服务器返回的数据
response的数据类型是HttpResponse
字节‐‐>字符串
解码decode
字符串‐‐>字节
编码encode
read() 字节形式读取二进制 扩展:rede(5)返回前几个字节
readline() 读取一行
readlines() 一行一行读取 直至结束
getcode() 获取状态码
geturl() 获取url
getheaders() 获取headers
urllib.request.urlretrieve()
请求网页
请求图片
请求视频
1.1 urllib.request
import urllib.request as req
发送请求获得响应数据
urlopen
import urllib.request as req
#要请求的url地址
url='https://blog.csdn.net/m0_58730471/article/details/128872792?spm=1001.2014.3001.5501'
#发送请求
res=req.urlopen(url)
#read是读取字节,这里设置其解码方式
contet=res.read().decode('utf-8')
print(contet)
一个类型六个方法
请求响应的类型HTTPResponse
方法:
read 按字节读取
readline 读取一行
readlines 按行读取所有
getcode 获取状态码 200/500/404…
geturl 获取当前的请求url地址
getheards 获取响应头内容
内容下载
urlretrieve
# urlretrieve(url,'名称.格式')
#下载一张图片,url为下载地址
url='https://img1.baidu.com/it/u=1605341541,1182642759&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750'
req.urlretrieve(url,'1.jpg')
定制请求对象
Request封装一下请求头的信息,包装成request类型
url='https://www.baidu.com/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
#定制请求头对象
request=req.Request(url=url,headers=headers)
#里面放的就不是直接的url,而是包装后的request
res=req.urlopen(request)
contet=res.read().decode('utf-8')
print(contet)
1.2 urllib.parse
get请求编码
单个参数编码(Unicode编码)
quote
import urllib.parse
name=urllib.parse.quote("张三")
print(name) #%E5%BC%A0%E4%B8%89
多个参数编码拼接
urlencode
url='https://www.baidu.com/'
data={
'wd':'周杰伦',
'age':18,
'sex':'男'
}
url+=urllib.parse.urlencode(data)
print(url)
#https://www.baidu.com/wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&age=18&sex=%E7%94%B7
post请求编码
urllib.parse.urlencode(data).encode(‘utf‐8’)
eg:百度翻译
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'user‐agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
keyword = input('请输入您要查询的单词')
data = {
'kw':keyword
}
data = urllib.parse.urlencode(data).encode('utf‐8')
request = urllib.request.Request(url=url,headers=headers,data=data)
response = urllib.request.urlopen(request)
print(response.read().decode('utf‐8'))
总结:post和get区别?
1:get请求方式的参数必须编码,参数是拼接到url后面,编码之后不需要调用encode方法
2:post请求方式的参数必须编码,参数是放在请求对象定制的方法中,编码之后需要调用encode方法
1.3 ajax的get请求示例
# 爬取豆瓣电影前10页数据
# https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&start=0&limit=20
# 页码规律 (start变化(page-1)*20)
# 1 2 3 4
# 0 20 40 60
import urllib.request
import urllib.parse
# 下载前10页数据
# 下载的步骤:1.请求对象的定制 2.获取响应的数据 3.下载
# 每执行一次返回一个request对象
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=20&interval_id=100%3A90&action=&'
headers = {
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
data={
# 1 2 3 4
# 0 20 40 60
'start':(page‐1)*20,
'limit':20
}
# data编码
data = urllib.parse.urlencode(data)
url = base_url + data
request = urllib.request.Request(url=url,headers=headers)
return request
# 获取网页源码
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf‐8')
return content
def down_load(page,content):
# with open(文件的名字,模式,编码)as fp:
# fp.write(内容)
with open('douban_'+str(page)+'.json','w',encoding='utf‐8')as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_content(request)
down_load(page,content)
1.4 ajax的post请求示例
KFC官网
简介:1.HTTPError类是URLError类的子类
2.导入的包urllib.error.HTTPError urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出
了问题。
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try‐
except进行捕获异常,异常有两类,URLError\HTTPError
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/ityard/article/details/102646738'
# url = 'http://www.goudan11111.com'
headers = {
'Cookie': '...',
'User‐Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, likeGecko) Chrome/77.0.3865.120 Safari/537.36',
}
try:
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf‐8')
print(content)
except urllib.error.HTTPError:
print(1111)
except urllib.error.URLError:
print(2222)
1.5 Handler处理器
为什么要学习handler?
urllib.request.urlopen(url)
不能定制请求头
urllib.request.Request(url,headers,data)
可以定制请求头
Handler
定制更高级的请求头(随着业务逻辑的复杂 请求对象的定制已经满足不了我们的需求(动态cookie和代理
不能使用请求对象的定制)
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML,likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
request = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.HTTPHandler()
opener = urllib.request.build_opener(handler)
response = opener.open(request)
print(response.read().decode('utf‐8'))
1.6 代理服务器
1.代理的常用功能?
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务
器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3.提高访问速度
扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲
区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
4.隐藏真实IP
扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。2.代码配置代理
创建Reuqest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User ‐ Agent': 'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML,likeGecko) Chrome / 74.0.3729.169Safari / 537.36'
}
request = urllib.request.Request(url=url,headers=headers)
proxies = {'http':'117.141.155.244:53281'}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf‐8')
with open('daili.html','w',encoding='utf‐8')as fp:
fp.write(content)
2 解析
2.1 xpath
xpath使用:
注意:提前安装xpath插件
(1)打开chrome浏览器
(2)点击右上角小圆点
(3)更多工具
(4)扩展程序
(5)拖拽xpath插件到扩展程序中
(6)如果crx文件失效,需要将后缀修改zip
(7)再次拖拽
(8)关闭浏览器重新打开
(9)ctrl + shift + x
(10)出现小黑框1.安装lxml库
pip install lxml ‐i https://pypi.douban.com/simple
2.导入lxml.etree
from lxml import etree
3.etree.parse() 解析本地文件
html_tree = etree.parse(‘XX.html’)
4.etree.HTML() 服务器响应文件
html_tree = etree.HTML(response.read().decode(‘utf‐8’)
html_tree.xpath(xpath路径)
xpath基本语法:
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点2.谓词查询
//div[@id]
//div[@id=“maincontent”]3.属性查询
//@class
4.模糊查询
//div[contains(@id, “he”)]
//div[starts‐with(@id, “he”)]5.内容查询
//div/h1/text()
6.逻辑运算
//div[@id=“head” and @class=“s_down”]
//title | //price
小练:
站长素材图片抓取并且下载http://sc.chinaz.com/tupian/shuaigetupian.html
2.2 JsonPath
转载:https://goessner.net/articles/JsonPath/
JSONPath - 是xpath在json的应用。
如果使用xpath来解析json:
1,可以在客户端上以交互方式找到数据并从JSON结构中提取数据,而无需编写特殊脚本
2,客户端请求的JSON数据可以减少到服务器上的相关部分,从而最大限度地减少服务器响应的带宽使用。
由于JSON是C系列编程语言数据的自然表示,因此,特定语言具有访问JSON结构的原生语法元素的可能性很高。
在Javascript、Python和PHP中,具有保持JSON结构的变量x。在这里我们观察到,特定语言通常已经内置了一个基本的XPath特性。(就是可以解析)
JOSNPath 表达式
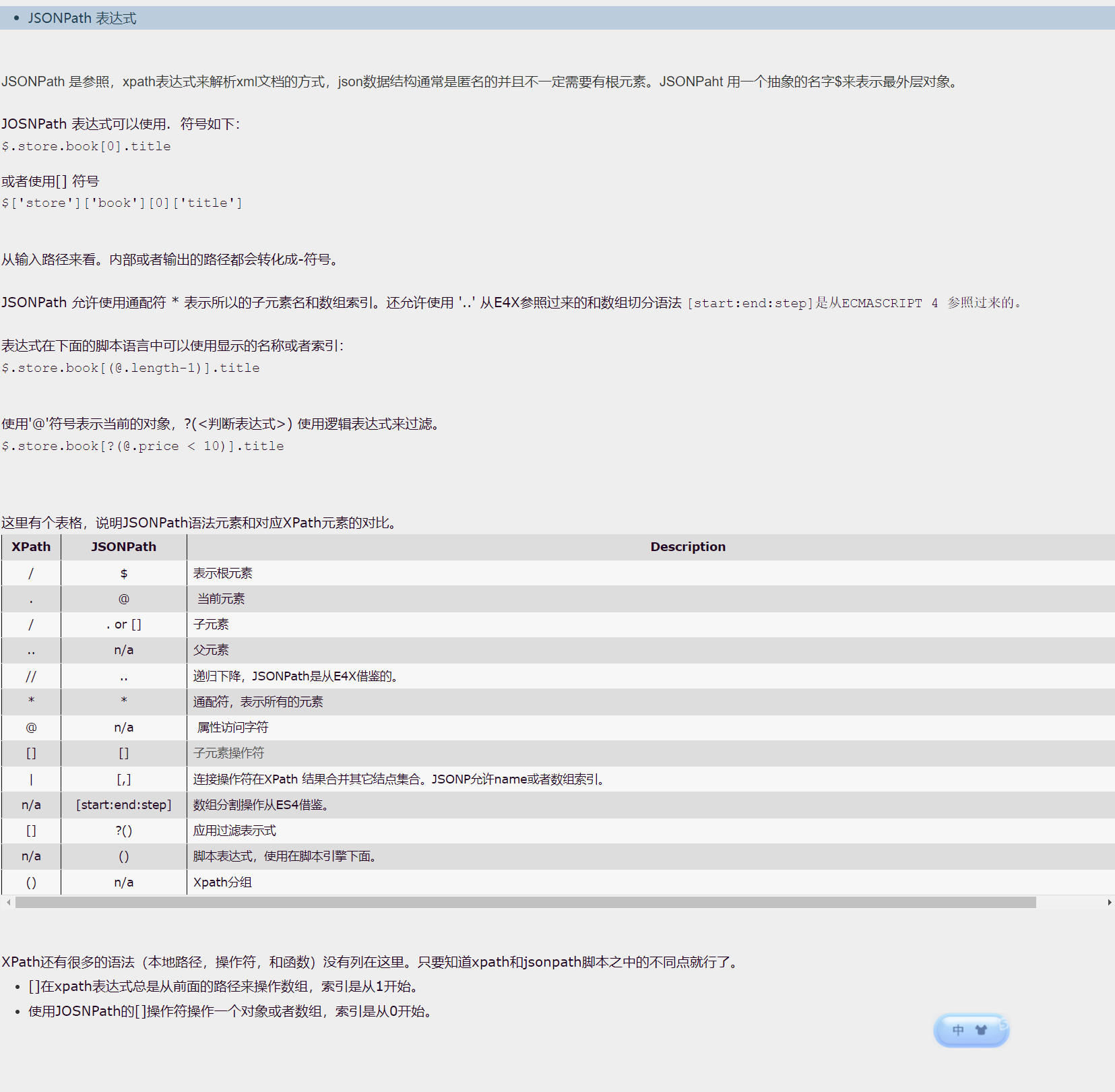
举例:
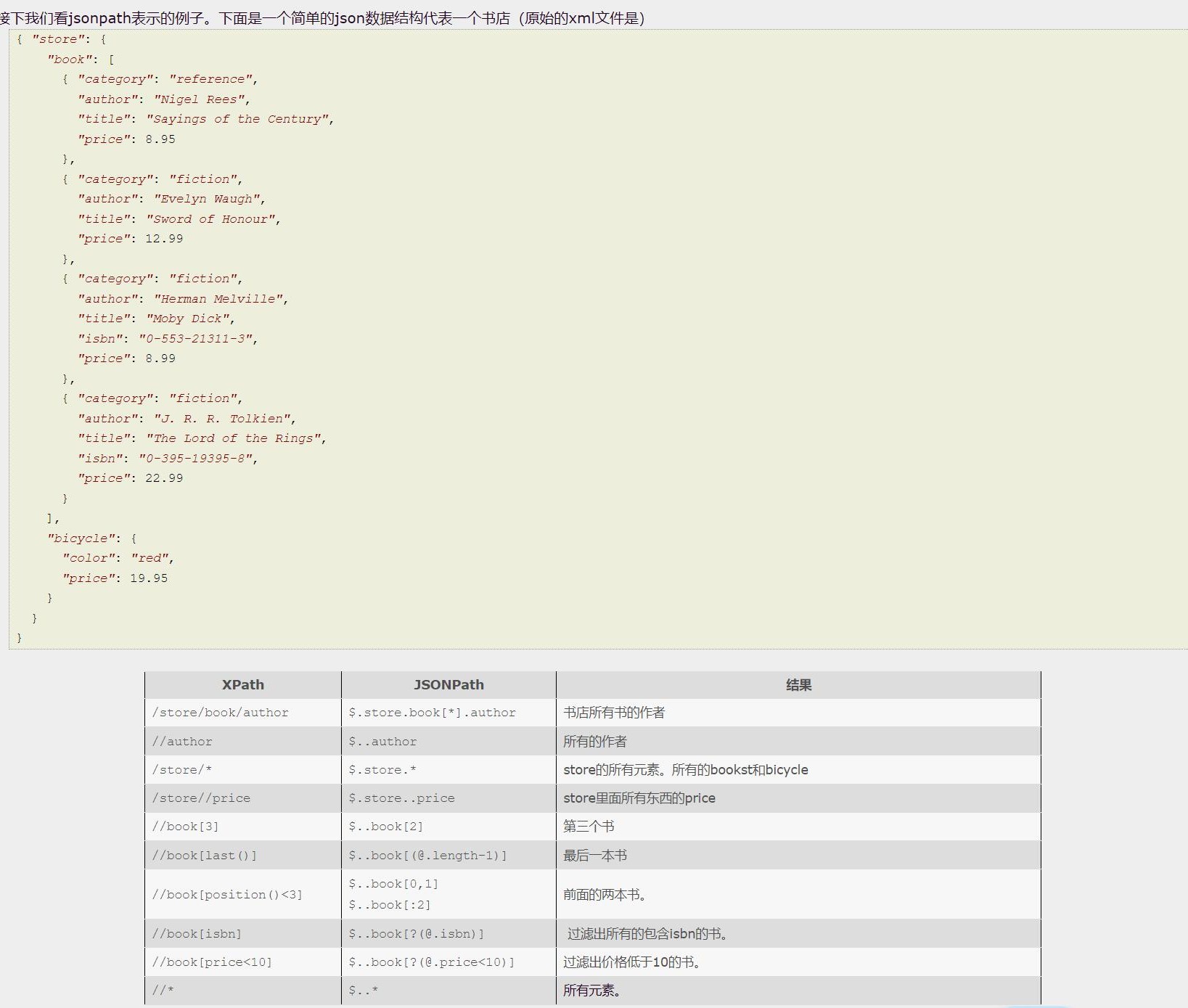
jsonpath的安装及使用方式:
pip安装:
pip install jsonpath
jsonpath的使用:
obj = json.load(open(‘json文件’, ‘r’, encoding=‘utf‐8’))
ret = jsonpath.jsonpath(obj, ‘jsonpath语法’)
2.3 BeautifulSoup
1.基本简介
1.BeautifulSoup简称:
bs4
2.什么是BeatifulSoup?
BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点?
缺点:效率没有lxml的效率高
优点:接口设计人性化,使用方便
2.安装以及创建
1.安装
pip install bs4
2.导入
from bs4 import BeautifulSoup
3.创建对象
服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(), ‘lxml’)
本地文件生成对象
soup = BeautifulSoup(open(‘1.html’), ‘lxml’)
注意:默认打开文件的编码格式gbk所以需要指定打开编码格式
3.节点定位
1.根据标签名查找节点
soup.a 【注】只能找到第一个a
soup.a.name
soup.a.attrs
2.函数
(1).find(返回一个对象)
find('a'):只找到第一个a标签
find('a', title='名字')
find('a', class_='名字')
(2).find_all(返回一个列表)
find_all('a') 查找到所有的a
find_all(['a', 'span']) 返回所有的a和span
find_all('a', limit=2) 只找前两个a
(3).select(根据选择器得到节点对象)【推荐】
1.element
eg:p
2..class
eg:.firstname
3.#id
eg:#firstname
4.属性选择器
[attribute]
eg:li = soup.select('li[class]')
[attribute=value]
eg:li = soup.select('li[class="hengheng1"]')
5.层级选择器
element element
div p
element>element
div>p
element,element
div,p
eg:soup = soup.select('a,span')
4.节点信息
(1).获取节点内容:适用于标签中嵌套标签的结构
obj.string
obj.get_text()【推荐】
(2).节点的属性
tag.name 获取标签名
eg:tag = find('li)
print(tag.name)
tag.attrs将属性值作为一个字典返回
(3).获取节点属性
obj.attrs.get('title')【常用】
obj.get('title')
obj['title']