文章目录
- Abstract
- Introduction
- Methodology
- Auxiliary Task selection
- SRL
- DP
- AMRization
- Tranform SRL to PseudoAMR
- Connectivity Formation
- Argument Reduction
- Reentrancy Restoration
- Dependency Guided Restoration
- Transform Dependency Structure to PseudoAMR
- Redundant Relation Removal
- Token Lemmatization
- Linearization
- Training Paradiagm Selection
- Multitask training
- Intermediate training
- Multitask & Intermediate training
- Experiments
- Dataset
- Evaluation metrics
- Experiment setups
- Model setting
- AMRization Setting
- Main Results
- 属于 AMR parsing 任务
- 文章链接
- 代码链接
- 关于 AMR 不懂的部分(前驱知识)可以去看我的博客的分析
Abstract
- 我们假设一些语义或者形式上相关的辅助任务与AMR parsing 任务共同进行训练可以获得更好的 AMR parsing 效果
- 采用了两个辅助任务:
- 语义角色标注(Semantic role labelling (SRL))
- 依赖解析(Dependency Parsing) DP 任务
- 由于 SRL 和 DP 任务的输出和 AMR 自身的结构存在较大差异,本文试图将 SRL 和 DP 任务的输出进行 AMR 化(AMRized),从而在 training 之前获得 伪-AMR(Pseudo-AMR)从而更加有助于 AMR parsing
- 与多任务学习相比,中间任务学习(intermediate task leaning ITL)是在AMR解析中引入辅助任务的较好方法
- 效果 state-of-the-art
- 代码开源:https://github.com/PKUnlp-icler/ATP
Introduction
-
AMR 可以用在很多下游任务,比如: 信息提取,文本摘要,问答,对话建模等
【information extraction (Rao et al., 2017; Wang et al., 2017; Zhang and Ji, 2021), text summarization, (Liao et al., 2018; Hardy and Vlachos, 2018) question answering (Mitra and Baral, 2016; Sachan and Xing, 2016) and dialogue modeling (Bonial et al., 2020)】 -
最近 AMR 的发展是基于 seq2seq 的网络的,取得了很大成功
-
seq2seq 模型不需要复杂的数据处理工作,并且天然地适合采用 辅助任务训练 以及 预训练的 encoder-decoder的方法
-
之前的工作 (Xu et al., 2020; Wu et al., 2021) 已经展示了 AMR parsing 任务可以用 co-training 和特定的辅助任务来提升
-
然而现在采用 辅助任务 来提高 AMR 解析的任务存在这么几个问题,尚未弄清楚:
- 如何选择 辅助的任务,目前尚未有一套标准,虽然很多工作取得了进展,但是对这一点还是避重就轻
- 如何弥补 / 解决 不同任务的 gap:比如机器翻译任务和 DP 以及 SRL 任务差异很大,如果将他们共同作为辅助任务,可能会导致不好的结果
- 如何将 辅助任务 更加高效地设计并完成:之前的操作都是结合多个 辅助任务 然后采用多模型学习策略 MTL(multi task leaning),但是我们认为 ITL 中间任务学习策略 才是更加高效的解决方案。我们的这个结论与 (Pruksachatkun et al., 2020; Poth et al., 2021) 是一致的
-
为了解决上面的三个问题,我们的 method 设计了三个部分:
- 辅助任务的选择:我们衡量不同的辅助任务与 AMR 任务的相似度(从语义和形式两个方面衡量相似度)最终选择了 SRL 和 DP 两个辅助任务
- AMR化: 虽然 SRL 和 DP 任务非常接近 AMR,但是仍然需要做一些额外的处理,AMR 化的目的是让 SRL 和 DP 的特征尽可能地接近 AMR 训练时候用的 特征
- 其中对待 SRL 我们采用 Reentrancy Restoration(重进入存储)的方法将 SRL 从树结构转换成 graph 结构,这样更加逼近 AMR 的结构
- 通过删除冗余关系(Redundant Relation Removal)我们在依赖树(dependency tree)中进行转换,并删除AMR图中远离语义关系的 relation,用这样的方法完成 DP 任务的 AMR 化。
- 训练范式的选择:选择 中间任务学习策略
-
本文贡献:
- 使用 SRL,DP 作为辅助任务来帮助 AMR 提升 parsing 效果
- 提出 AMR化的方法将 SRL 和 DP 的特征更加逼近 AMR
- 使用中间任务学习策略完成多个辅助任务的联合训练
-
结果非常好,在 AMR2.0 上达到了 85.2 的match 分数,在 AMR3.0上达到了 83.9,目前是 state-of-the-art
Methodology
- 我们将 Pseudo-amr 和 AMR 的任务都看做是 seq2seq 的生成任务,即给定一个句子
x
=
[
x
i
]
1
≤
i
≤
N
x=[x_i]_{1\leq i \leq N}
x=[xi]1≤i≤N,模型试图产生一个现行的 PseudoAMR或者 AMR graph
y
=
[
y
i
]
1
≤
i
≤
M
y=[y_i]_{1\leq i \leq M}
y=[yi]1≤i≤M,通过下面描述的条件概率:
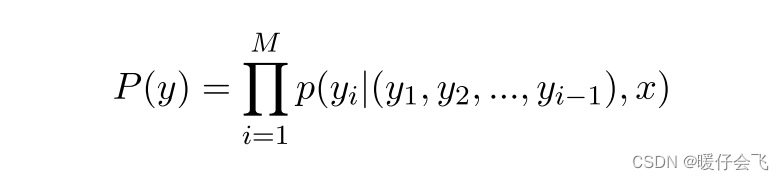
Auxiliary Task selection
- 从语义(semantically)和形式(formally)两个方面筛选,因此选择了 SRL 和 DP,也就是:我们的辅助训练任务 与 Translation 和 Summarization 作为辅助任务的情况进行了比较
SRL
- SRL 的目的是恢复一个句子中的 predicate-argument (述词论元结构),可以提高 AMR parsing 任务的精度,原因如下:
- AMR 的一个子任务就是恢复 predicate-argument,当然 AMR 包含的内容更加丰富一些,但是在恢复 predicate-argument 方面,这两个任务是重合的,所以通过训练 SRL 也可以促进 AMR 解析模型的训练效果。他们都针对一个中心的 predicate 来捕获与他相关的那些 arguments
- SRL 和 AMR 分别可以看做浅层和深层语义解析任务。从这个角度看,浅层任务做好了可以促进深层任务的理解和效果也是符合常理的
DP
- DP 的任务是把一个句子解析成 tree 的结构,从而代表不同的 token 之间的依赖关系(dependency relation)
- DP 的知识对于 AMR parsing 有意义因为:
- 从语言学上来说, DP 是 AMR 任务的前驱工作
- DP任务中关注的 依赖关系 同样也与 AMR 任务中的 semantic relation 这个概念是相关的
- DP 和 AMR 解析从 edge prediction 这个角度来看是很相似的任务,因为他们都需要捕一句话中不同 nodes(concepts / tokens) 之间的关系
AMRization
Tranform SRL to PseudoAMR
- SRL 和 AMR 之间的 gap 存在于:
- 连通性(Connectivity):AMR 是连通的 graph,SRL 是个 forest
- 短语-概念的差距(Span-Concept Gap):AMR 中的每个 node 都表示成一个 concept,而 SRL 中是以 token span 的形式存在的
- 重入性(Reentrancy):重入性是 AMR 一个很重要的性质,在图三中,AMR 中的
boy被引用了两次,但是 SRL 中没有任何的重用
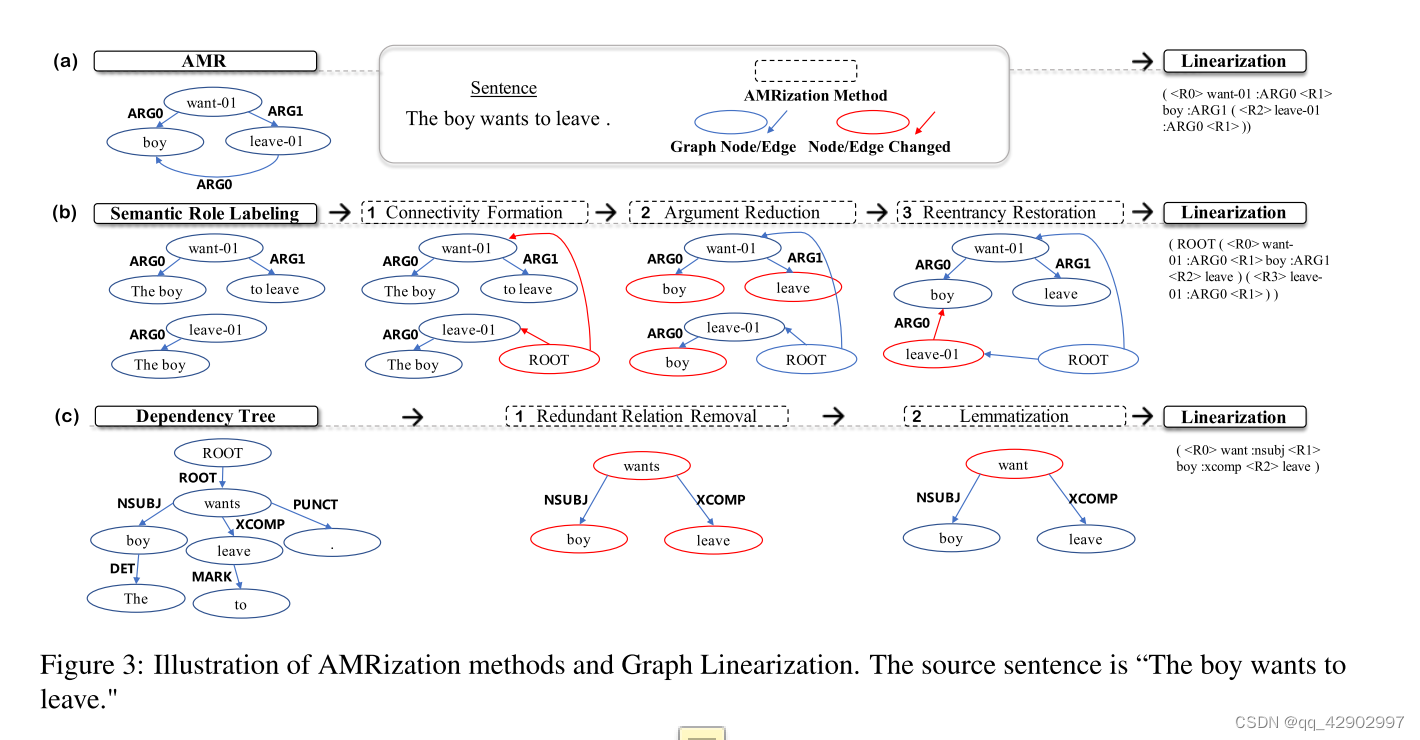
- 为了解决上述三点,采用了三个对应的解决方案:
Connectivity Formation
- 将 SRL tree 转化成一个 graph。这种改造并不能保证在语义层面是正确的(图三 b1),首先添加一个虚拟的 root 节点,然后基于 root 生成directed edge(有向边)到 SRL 原本树结构中的每个 root 节点,因此 SRL 就变成了一个 graph 结构
Argument Reduction
- 为了解决 SRL 中用 token span 而 AMR 中用concept 表示的差异,在图3 b2 中可以看到,如果对于一个核心的 predicate(图中的
leave和want,the boy,to leave)这个 predicate 如果是一个拥有多于一个 token 的 span,就将这个 span 用它的 head token 来代替,例如the boy -> boy; to leave -> leave这样更接近 AMR 中的 concept 的表示方法
Reentrancy Restoration
- 本文设计了一个启发式算法(基于 深度优先遍历 DFS)来保存 reentrancy。图三 b3 显示,这个做法的核心是:当这个基于 DFS 的启发式算法第一次遍历到某个 node 的时候就创建一个变量 variable,如果 DFS 再次遍历到这个 node ,那么当前这个 edge 的重点就直接变成第一次的变量 variable,这样就构造了多个 node 共同引用一个 node 的结构
- 举个例子来说,看图三中的 b-2,假设深度优先是从
want开始,那么遍历的顺序是want->boy->leave然后是leave-01->boy到这个 boy 的时候直接把这个边指向第一次的boy节点
Dependency Guided Restoration
-
在上述的处理中,只能保证像
boy这种词被重用,但是像leave和leave-01其实是一个东西,但是却出现了两次,没有进行重用,他们也应该被 merge 成一个 node -
但是这个操作不能简单的从 SRL 的 annotation 中继续进行,为了解决这个问题,我们又提出了一种新的方法,在图四中展示
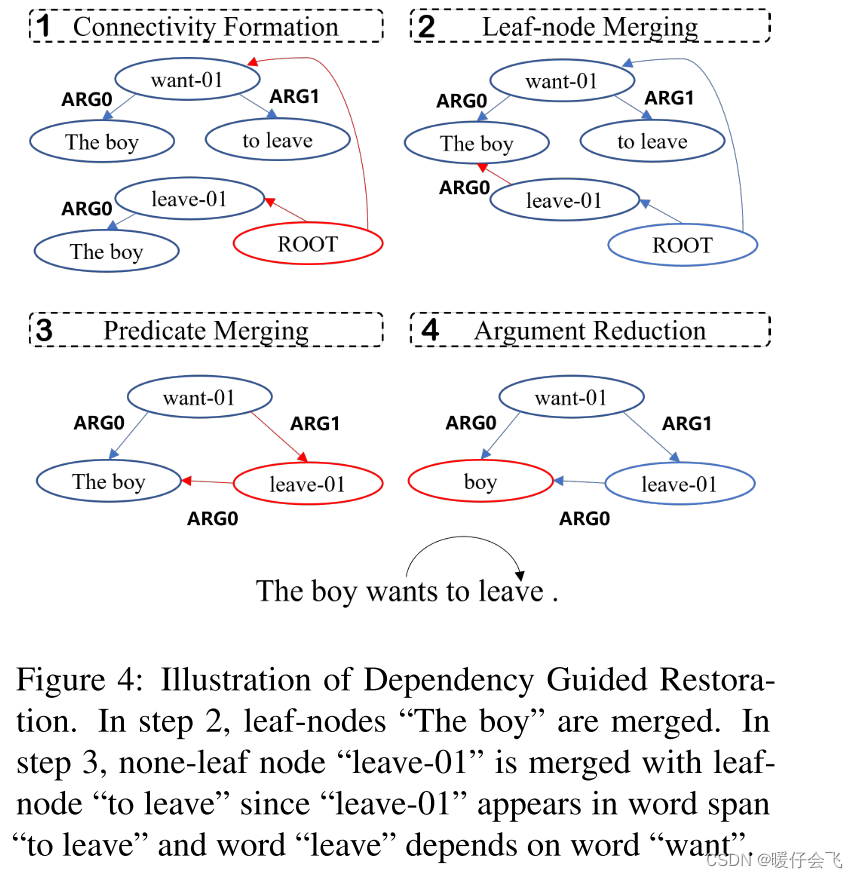
-
这个算法将之前的 Connectivity Formation 的结果作为输入,首先合并那些有相同 token 的叶子节点,这一步不会产生任何误差,因为 leaf-nodes 的合并不会产生误差,只是把相同的token 进行整合
-
第二步是将那些重要的 predicate(谓词 / 述词)进行和并,比如
want , leave,这一步会首先检查一个 predicate 是否在其他 span 的 argument 中出现过,并且是否这个 predicate 直接 depend on 其他 span 的 predicate,如果这两个条件都符合,那么算法将会将这个 predicate 和符合条件的那个 span 进行融合(图4 (3)中,因为 leave-01 出现在 to leave 这个 span 中,而且 leave 依赖于 the -
最终如果当前的结构在删除 root node 和 root-edges 之后依然连通的话,会删除 root node 和 root edges
Transform Dependency Structure to PseudoAMR
- 上面一个部分讲解的是如何将 SRL 的任务的输出适配成 AMR 的形式
- 这个部分是将如何将 DP 的任务的输出适配成 AMR 的形式
- DP 的主要问题是:
- Redundant Relation:一些 DP 任务中的关系更多地是语义层面(syntax)的表示,例如 “:PUNCT” 和 “:DET”,这些和 AMR 中表示的 relation 相去甚远
- Token-Concept GAP: 这个是指 DP 中使用的最基本单位是 token,但是在 AMR 中是 concept,concept 表示的意义更加的 syntax-independent(也就是 concept 与语义无关)
- 为了解决这两个部分的问题,本文采用了 redundant relation removal 和 token lemmatization 来处理
Redundant Relation Removal
- 首先移除那些与 AMR 的表示体系相差太大的 DP 中的元素,例如 “:PUNCT” 和 “:DET”。图3 c-1 中表示了这个操作,通过移除这些内容,解析的结果与原来的 DP tree 结构相比更加紧凑,迫使模型在进行 seq2seq 训练的时候忽略掉那些与语义不相关的 tokens
Token Lemmatization
- 在图 3c-2 中展示了这个操作,通过将 DP tree 进行词元化我们发现,单个词的词缀不会影响到它相关的 concept。结合 Bevilacqua 等人提出的 smart-initialization,通过将concept token 的 embedding 设置成子词的均值(average of the subword constituents),这个 want 的 embedding 向量更加接近于 concept(want-01) 的 embedding matrix,因此,需要模型在执行DP任务时捕捉更深层次的语义。
Linearization
- 经过对 SRL 和 DP 的 AMRization 的步骤,SRL 和 DP 的图结构已经形成,在进行 seq2seq 的训练以前,还需要进行线性化,按照 Bevilacqua 提出的线性化方式,通过 DFS 遍历的方式构建线性的 token 序列,通过 < R 0 > , < R 1 > , . . . . , < R k > <R0>, <R1>,....,<Rk> <R0>,<R1>,....,<Rk> 来表示不同的 variables,括号用来标记深度,这是最好的线性化方式。
Training Paradiagm Selection
- 我们探究了两种不同的训练范式:
- 多任务训练范式
- 中间任务训练范式
Multitask training
- 在序列对序列的多任务训练中使用经典模式,在输入句的开头添加特殊的任务标签,并同时训练所有任务
- 最佳模型的验证只在AMR解析子任务上进行
Intermediate training
- 首先 fine-tune 一个在 intermediate task 上预训练的模型(PseudoAMR parsing),然后在同样的参数条件下微调 target 的 AMR parsing 任务
- 也就是说,先用 SRL 和 DP 的任务做预训练模型,然后用这个预训练模型来微调 AMR parsing 任务的模型
Multitask & Intermediate training
- 首先先用 multitask training,然后再 AMR parsing 任务上进行微调,这里的预训练模型就不只是 PseudoAMR parsing 的任务了,而是 PseudoAMR + AMR paring 模型,然后微调 target 的 AMR parsing 任务
Experiments
Dataset
-
在 AMR2.0 的数据集上和 AMR3.0 的数据集上进行实验
- AMR2.0 包含 36521 training, 1368 validation, 1371 testing
- AMR3.0 包含 55635 training, 1722 validation,1898 testing
-
我们还在一些其他的分布不同的数据中进行了实验(BIO, TLP, News3),这些数据集的数据量都很小
Evaluation metrics
- 首选 Smatch score,然后采用 break down score
- 为了探究辅助任务到底帮助 AMR 进行了何种提升,我们将 fine-grained score 分成了两个大类:
- concept-related:包括 Concept, NER和 Negation score,这些指标更加关注于 concept 为主的预测结果
- topology-related:包括 Unlabeled, Reentrancy 和 SRL score,这些更注重 relation 的预测结果
- NoWSD和Wikification被列为独立评测的分数,因为NoWSD与Smatch分数高度相关,Wikification依赖于外部实体链接系统
Experiment setups
Model setting
- 采用 SPRING model(seq2seq 训练 AMR parsing 的 state-of-the-art)作为 baseline
- 将 BART-LARGE 模型作为预训练模型
- 我们采用 (Bevilac- qua et al., 2021) 这篇文章中所有的 postprocessing 方法来获得 token sequence
AMRization Setting
-
对于SRL, 我们使用了四种不同的 AMRization setting 方式:
- Trivial——对于 SRL tree,我们用 concept
:multi-sentence和 relation:snt来表示虚拟的root和edges - With argument reduction. 使用斯坦福大学提供的 CoreNLP toolkit 中的 dependency parser来做 argument reduction
- With reentrancy Restoration
- ALL techniques
- Trivial——对于 SRL tree,我们用 concept
-
对于 DP, 采取 4 种不同的 AMRization settings:
- Trivial:讲 DP tree 中的额外的 relation 都加入到 BART 的 vocabulary 中
- With lemmatization:使用 NLTK 来执行 token 的 lemmatization
- With Redundant Relation Removal:将 PUNCT, DET, MARK 和 ROOT relation 都删掉
- 结合所有的技术(all techniques)
Main Results
- 当采用 ITL 训练范式 + 所有的 AMRization 方法之后,达到了最好的结果。
- 与 SPRINT(之前最好的结果,采用了200k 的额外训练数据)相比,我们采用的extra data 要少很多,只用了 40k 的额外数据就超过了他们的结果
- 结果表明,我们的集成模型以更少的额外数据击败了对手,达到了更高的性能
- 即使不采用集成模型,我们的模型依然表现的比那些 集成模型好,并且使用 Dependency guided restoration 的方法达到了比 trivial 更好的精度表现,体现了方法的有效性




![[附源码]java毕业设计疫情防控下高校教职工健康信息管理系统](https://img-blog.csdnimg.cn/df6cd9eb1dc04a31bb722ce435b61ed9.png)