文章目录
- 前言
- 从结构化文本文件中提取数据
- 针对Web的结构型数据
- 文字解谜好帮手
- 单词列表
- 标签列表
前言
当你在UNIX里对付文字处理作业时,必须谨记一个UNIX工具使用原则就是:想清楚这个问题该如何划分为更简单的工作,每个部分是不是已有现成的工具能解决,还是你可以写几行Shell程序或使用脚本语言就能解决。
从结构化文本文件中提取数据
在UNIX下的管理性文件,大部分都是无须使用任何特殊的文件专用工具,即可编辑、打印与阅读的简易文本文件。这些文件大部分放在标准目录:/etc下。最常见的例子就是密码与组文件(passwd and group)、文件系统加载表(fstab或vsftab)、主机文件(hosts),以及默认的Shell启动文件(profile),以及系统启动与关机的Shell脚本(存放在子目录树rc0.d、rc1.d···rc6.d之下,也有可能是其他目录)。
/etc/passwd相关的结构信息
| 1 | 用户名称 |
|---|---|
| 2 | 加密的密码,或指出密码存储于另一个文件中 |
| 3 | 用户ID数字 |
| 4 | 用户组ID数字 |
| 5 | 用户姓名,或其他相关数据(办公室号码、电话等) |
| 6 | 根目录 |
| 7 | 登录的Shell |
每个字段几乎对各种不同的UNIX程序都很重要,除第5个字段外。传统上,第5个字段用来置放用户相关的信息。其实原本叫做gecos子弹,这个名称有历史原因,它是在20世纪70年代在贝尔实验室时加入的,当初是为了我那个UNIX系统能与其他运行通用电子综合操作系统的计算机进行通信而产生的,后者需要UNIX用户相关的额外信息。今天,多数将它用来存放用户姓名,所以我们把这个字段简称为姓名字段。
范例,我们假定本地端点在姓名字段里存放其他信息:建筑物与办公室号码,以及电话号码,且这些数据与个人姓名以斜杠分隔。
#! /bin/bash
# 过滤/etc/passwd这类格式的输入流
# 并以此数据衍生出办公室名录
#
# 语法:
# passwd-to-directory </etc/passwd > office-directory-file
# ypcat passwd | passwd-to-directory > office-directory-file
# niscat passwd.org_dir | passwd-to-directory > office-directory-file
umask 077
PERSON=/tmp/pd.key.person.$$
OFFICE=/tmp/pd.key.office.$$
TELEPHONE=/tmp/pd.key.telephone.$$
USER=/tmp/pd.key.user.$$
trap "exit 1" HUP INT PIPE QUIT TERM
trap "rm -f $PERSON $OFFICE $TELEPHONE $USER" EXIT
awk -F: '{print $1 ":" $5}' > $USER
sed -e 's=/.*==' \
-e 's=^\([^:]*\):\(.*\) \([^ ]*\)=\1:\3, \2=' < $USER | sort > $PERSON
sed -e 's=^\([^:]*\):[^/]*/\([^/]*\)/.*$=\1:\2' < $USER | sort > $OFFICE
sed -e 's=^\([^:]*\):[^/]*/[^/]*/\([^/]*\)=\1:\2' < $USER | dort > $TELEPHONE
join -t: $PERSON $OFFICE |
join -t: - $TELEPHONE |
cut -d: -f 2- |
sort -t: -k1,1 -k2,2 -k3,3 |
awk -F: '{printf("%-39s\t%s\t%s\t%s\n", $1, $2,%3) }'
在此程序里,重要的假设是在每条数据记录的一个唯一键值。有了这个唯一键值,数据的各种不同视图可以用成对的key:value方式维护在文件中。这里的键值为UNIX的用户名称,但在较大型的例子中,键值很可能是书目编号、信用卡号码、员工编号、国家退休体系编号。产品序号、学号等。现在你终于知道我们身上有多少编号了吧!有时在处理这些数据时需要的不一定是号码:只是需要具有唯一值的文本字符串。
针对Web的结构型数据
由于World Wide Web(WWW)广为流行,所以在前一节中开发办公司名录的形式,可以稍作修改,让数据以较漂亮的形式呈现。
Web文件多半都是由Hyper Text Markup Language(HTML)语言写成;它是Standard Generalized Markup Language(SGML)家族语言之一,而SGML自1986年起,陆续被定义在数个ISO标准中。

我们在这个小节,只需要小型的HTML子集,这部分我们将用一小段文字来介绍。如果你对HTML已熟悉,可以跳过这两页。
下面是我们写的一个遵循的小型HTML文件,是由我们其中一人所编写的一个好用工具所产生的Download
我没找到,有兴趣大家自己研究
使用方法
$ echo Hell, world. | html-pretty
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-13S68ek2-1669290014808)(file://C:\Users\g700382\AppData\Roaming\marktext\images\2022-11-22-11-32-08-image.png)]](https://img-blog.csdnimg.cn/41f64fdc46f145f6ac953b541c2fbec1.png)
(关于HTML的其他内容推荐大家上HTML 教程 | 菜鸟教程)
要将我们的办公司名录转换成正式的HTML,只需要再知道一件事:如何格式化表格,因为那才是真正的办公室名录,且我们不想使用打字机字体,强制每一行在浏览器显示时排列一致完全对齐。
因为我们选择保留办公室名录纯文本版里的特殊字段分割字符,所以有足够的信息可以识别每列中的单元格。而且,因为HTML文件里,空白多半不带特殊含义,我们就不需要特别主要标签是否完好排列。如果之后有需要,html-pretty还是可以做的很完美。我们转换过滤器有三个步骤:
-
输出前置的样板文件直到内文开始处。
-
将名录的每一行包括在表格标记里
-
输出结尾的样板文件
范例如下
#! /bin/bash
# 将制表符(Tab)所分割的文件,转换为遵循语法HTML
#
# 用法:
# tsv-to-html < infile > outfile
cat << EOFILE #开头的样本文件(boilerplate)
<!DOCTYPE HTML PUBLIC "-//IEIF // DTD HTML//EN//3.0" >
<HTML>
<HEAD>
<TITLE>
office directory
</TITLE>
<LINK REV="made" HREF="mailto:$USER@`hostname`">
</HEAD>
<BODY>
<TABLE>
EOFILE
sed -e 's=&=\& amp;=g '\ #将特殊字符转换为实体(阅读时忽略中间的空格例 &)
-e 's=<=\& lt;=g' \
-e 's=>=\& gt;=g' \
-e 's=\t=</TD><TD>=g' \ #提供表格标记
-e 's=^.*S= <TR><TD>&</TD></TR>='
cat << EOFILE #结尾的样板文件
</TABLE>
</BODY>
<HTML>
EOFILE
<<标记为嵌入文件。后面会详细解释,指的就是Shell读取所有行,直到接在<<之后的定界符为止(本例中是EOFILE)、在被包含的行上执行变量与命令替换,以及将结果当成标准输入给命令。
文字解谜好帮手
字谜游戏会给你一些单词的线索,但大部分时候我们还是被困住,例如:具有10个字母的单词,以a,b起始,且第七个不是x就是z。
用awk或grep进行正则表达式模式匹配是必须的,问题是:要查找什么文件呢?使用UNIX拼写字典是不错的选择,大部分系统的/usr/dict/words下都应该找得到它(还有像/usr/share/dict/words与/usr/share/lib/dict/words也是可能出现的地方)。这是一个简答的文本文件,每行一个单词,以字典顺序排列。我们可以轻松地从任何的文本文件集合建立另一个具相似外表的文件,如下所示:
cat file(s) | tr A-Z a-z | tr -c a-z\' '\n' | sort -u
第二个管道步骤是将大写字母转换为小写,第三个则是以换行字符取代非字母字符,最后为结果进行排序,并去除重复部分,让每行都为唯一值。在第三步里,视撇号(')为字母,因为他们在缩写里会用到。每个UNIX系统具有可以此方式处理的整租文字——例如格式化后的手册页在/usr/man/cat*/*与/usr/local/man/cat*/*内。我们的系统里就有一个提供了一百万行以上的文本,并且产生了44 000个左右的唯一单词。在internet上你也可以找到很多种语言的单词列表。
我们假设已经以此方式建立了单词列表的集合,并将它们存储在一个标准的地方,以便我们的脚本可以找到参考它。编写如下程序
#! /bin/bash
# 通过一堆单词列表,进行类似egrep的模式匹配
# word lists
#
# 语法
# puzzle-help egrep-pattern [word-list-files]
FILES="
/usr/dict/words
/usr/share/dict/words
/usr/share/lib/dict/words
/usr/local/share/dict/words.biology
/usr/local/share/dict/words.chemistry
/usr/local/share/dict/words.general
/usr/local/share/dict/words.knuth
/usr/local/share/dict/words.latin
/usr/local/share/dict/words.manpages
/usr/local/share/dict/words.mathematics
/usr/local/share/dict/words.physics
/usr/local/share/dict/words.roget
/usr/local/share/dict/words.sciences
/usr/local/share/dict/words.UNIX
/usr/local/share/dict/words.webster
"
pattern="$1"
egrep -h -i "$pattern" $FILES 2> /dev/null |sort -u -f | fmt
FILES变量保存了单词列表文件的内建列表,可供各个本地站点定制。grep的-h选项指示最后结果不要显示出文件名,-i选项为忽略字母大小写,我们还用了 2> /dev/null丢弃标准错误信息的输出,这是单词列表文件不存在或是在他们缺乏必须的读取权限的情况。最后的sort步骤则可以简化最后的结果,让列表没有重复单词,并忽略字母大小写,fmt重新编排输出,方便阅读
测试如下,检查以b开头第七位为x或z的10位字母

单词列表
这里有个故事大家有兴趣可以阅读

总之就是让你将一个文件中所用的单词频率列出来,针对这种问题使用UNIX工具来处理会比直接编程要简单的多。
接原文:
将复杂的问题切分成数个较简单的部分,简单到你已经知道这个部分该怎么处理。为解决单词出现频率问题,Mcllroy将纯文本文件转换为单词列表,一行一个字(由tr来完成此工作)、将单词对应到单一的字母大小写(一样还是使用tr)、单词列表的排序(用sort)、从单词列表以计数的数字由大到小排序,最后,显示单词列表的前几项(这里使用sed,不过head也可以)。
最后形成的程序应该值得给他一个名称wf(word frequency,单词出现的频率之意),然后附上注释标题,打包成Shell脚本。我们也扩充了Macllroy原本的sed命令,让输出列表长度参数可选,并现代化sort选项
#! /bin/bash
# 从标准输入读取文本流,再输出出现频率最高的前n(默认值:25)个单词的列表
# 附上出现频率的计数,按照这个计数由大到小排列
# 输出到标准输出
#
# 语法:
# wf [n]
tr -cs A-Za-z\' '\n' | #将非字母字符置换成换行符号
tr A-Z a-z | #所有大写字母转换成小写
sort | # 由小到大进行排序单词
uniq -c | # 去除重复,并显示计数
sort -k1,1nr -k2 | #计数由大到小排序后,再按照单词由小到大排序
sed ${1:-25}q #显示前n行,默认25
测试:默认25
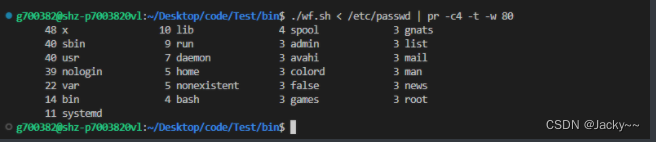
pr用于重新格式化输出结果,以每行4列显示。(这里不对该问题的复杂度进行分析,有兴趣的可自己研究)。
测试,前10行

测试前1000
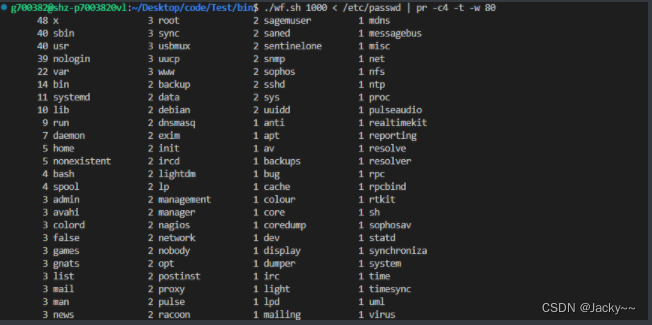
还可以通过tail显示后面不常用的,grep -c '^ *1.'只出现1次的单词大家自己尝试
出现任意次次的也可以使用awk来实现
./wf.sh 1000 < /etc/passwd | awk '$1 >=5' | wc -l

标签列表
tr命令可用于取得单词列表,但其更常见的用法是:将一组字符集转换成另一组。这也导致了一个问题:如何确保整篇5万行左右的原稿文件具有一致的标记(markup)呢?例如,当我们在正文中提到一条命令时,可将命令标记为<command>tr</command>,但是在其他地方,我们可能举例说明你输入的内容,便会使用<literal>tr</literal>这样的标记。还有一种是提及手册参考时,标记形式为<emphasis>tr</emphasis>。
后面范例缩写的程序就是这类问题的解决方案。该程序找出写在同一行里开始/结束的一对标签(tag),然后再输出一个排序列表,该列表将标签的使用与输入文件相关联。此外,对于多次的方式标记相同单词的地方,给出一个箭头标志。下列片段即为应用该程序后的输出

列出标签的任务想当然是很复杂的,如果你以最传统的程序语言来做也有点困难,即使拥有很大规模的类库。但是你使用UNIX管道,搭配你已熟悉的几个工具,只要9个步骤就能完成。
单词出现频率计算程序无法处理多个命名的文件:它假设仅有单一流。不过这也不是太严重的限制,因为我们可以很简单地通过cat将多个输入文件喂给它。不过在这里,我们需要有文件名,因为知道出问题但不晓得问题出在哪里,这对我们是没有好处的。所以,文件名成了程序的单个参数,在脚本中可通过$number来取得。
- 通过
cat将输入文件给管道。当然,也可以省掉这个步骤,只需从$1中重定向下一步的输入,不过我们觉得在一个复杂的管道里”将数据生成“与”数据处理“分开,会比较有条例,而这么做在程序日后需要在另一个步骤插入新的管道时,也会容易些。cat "$1" | ... - 通过
sed简化Web URL所需的另一种复杂标记“ ...|sed -e 's#systemitem *role="#URL#g"' -e 's#systemitem#/URL#'| ...这是将标签,如<systemitem role="URL">与</systemitem>分别转换成较简单的<URL>与</URL>标签。- 下一个步骤使用
tr将空白与成对的定界符转换为换行符:...|tr '(){}' '\n\n\n\n\n\n\n' | ... - 至此,输入数据包括一行一个单词。这里所指的单词,不是真正的文本就是SGML/XML标签。所以我们下一步骤我们使用
egrep,选定由标签括起来的单词...|egrep '>[^<>]+</' | ...这个正则表达式会匹配由标签括起来的单词:右尖括号,接着至少一个非尖括号字符,跟着一个左尖括号,再接上一个斜杠(也就是结束标签)。 - 至此,输入数据包括了带有标签的行,第一个
awk步骤使用尖括号作为分割字符,所以当输入为<literal>tr</literal>,即切分为4栏,依次是:一个空字段、literal、tr,最后为/literal。文件名通过命令行传给awk,其中-v选项把awk变量FIEL设置为此文件名。该变量之后会应用到print语句上,以输出单词、标签与文件名:...|awk -F '[<>]' -v FILE="$1" '{printf ("%-31s\t%-15s\t%s\n", $3, $2,FILE)}' | ... sort步骤是以单词顺序排列每一行:...| sort |...uniq命令提供初始化的计数字段。输出为记录列表,其中字段一次为计数,单词,标签,文件:...|uniq -c |...- 第二个
sort是将输出结果以单词及标签的顺序排列(第二,三字段)...|sort -k2,2 -k3,3 | ... - 最后步骤是使用小小的
awk程序,过滤掉连续的行,加上结尾的箭头符号,当出现与上一行相同单词时使用。然后,此箭头符号可清楚地指出那个字使用了不同的标记,也就是作者、编辑或出版社相关人员应特别检查的地方:...|awk '{print ($2 == Last) ? ($0 "<-----"):$0 Last = $2}'
完整的程序如下
#! /bin/bash
# 读取命令行上给定的HTML/SGML/XML文件
# 找出包含像<tag>word</tag>这样的标记,在输出到标准输出
# 该标准输出将以制表符(tab)分割字符,依次为
#
# 计数 单词 标签 文件名
# 按照单词与标签由小至大排序。
#
# 语法:
# taglist xml-file
cat "$1" |
sed -e 's#systemitem *role="url"#URL#g' -e 's#/systemitem#/URL#' |
tr ' (){}[]' '\n\n\n\n\n\n\n' |
egrep '>[^<>]+</' |
awk -F '[<>]' -v FILE='$1' \
'{printf("%-31s\t%-15s\t%s\n", $3, $2, FILE)}' |
sort |
uniq -c |
sort -k2,2 -k3,3 |
awk '{
print ($2 == Last) ? ($0 " <----"): $0
Last = $2
}'
后面会分析如何将标签列表应用到多文件的情况上。





![[附源码]计算机毕业设计JAVA龙虎时代健身房管理系统](https://img-blog.csdnimg.cn/d9bf27ede9ee4c9d99abf10cf414b028.png)