工作中,遇到有两个不同的系统,两个系统中有相同的功能,维护一个主播的名称。现在准备将两个系统的主播合并到一起。因为主播名称可能由不同的人维护的,他们也不知道主播的真实姓名,比如一条小团团,可能维护成了亿条小团团,等等。
为了解决主播重复问题,现在想了一个办法,将要导入的一方,做一个列表,将原有系统所有与其相似的主播名称展示出来。大概就像这样。
| 一条小团团 | 一条小团团 |
| 亿条小团团 | |
| 一条晓团🍡 |
通过与大佬们的讨论、启发。现准备使用以下方案。
- 使用正则表达式,将昵称中的emoji剔除,只提取汉字和英文数字
- 使用中文分词法,将昵称字符串分成一个个的单词。并将词组个数为一的删去
- 两个系统的主播昵称进行同样的操作
- 之后遍历要导入的一方,与原有系统的拼音做对比,有重复的标记下来
- 最后导出文件,拿给运营同事人工比对
部分示例代码:
核心转换功能
import re
import jieba
import pypinyin
def get_words(name):
# 提取汉字和英文数字
name = re.sub('[^\u4e00-\u9fa5a-zA-Z0-9]', '', name)
seg_list = jieba.cut_for_search(name) # 搜索引擎模式
word_list = []
for j in seg_list:
print(j, end=',')
# 去除长度为一的词
if len(j) != 1:
# 将词转换成拼音,并连接成字符串
word_list.append(''.join(pypinyin.lazy_pinyin(j)))
return word_list
get_words("一条小团团")
> 一条,小,团团,
> ['yitiao', 'tuantuan']
原有系统制作哈希字典,方便查找
bigMap = {}
jeecg_data = db.execute_sql('select * from xxx', DB)[1]
for jeecg in jeecg_data:
words = get_words(jeecg.get('name'))
for word in words:
if bigMap.get(word) is None:
bigMap[word] = {
'name-id' = []
}
bigMap[word]['name-id'].append("%s#%s" % (jeecg.get('name'), jeecg.get('id')))
需导入的主播
result_list = []
jane_data = db.execute_sql("select * from xxx", DB)[1]
for jane in jane_data:
words = get_words(jane.get('name'))
res = {
'id': jane.get('id'),
'head': jane.get('head'),
'name': jane.get('name'),
'name-id': []
}
for word in words:
if bigMap.get(word):
res['name-id'].extend(bigMap.get(word).get('name-id'))
# 去重(可能一个昵称存在多个单词相同)
res['name-id'] = list(set(res['name-id']))
result_list.append(res)
导出文件
for i in result_list:
with open("foo.txt", "a+") as f:
for j in i.get('name-id'):
f.write(i.get('name'))
f.write('\t')
f.write(i.get('id'))
f.write('\t')
f.write(j)
f.write('\t')
f.write('\n')
用到的库:jieba, pypinyin
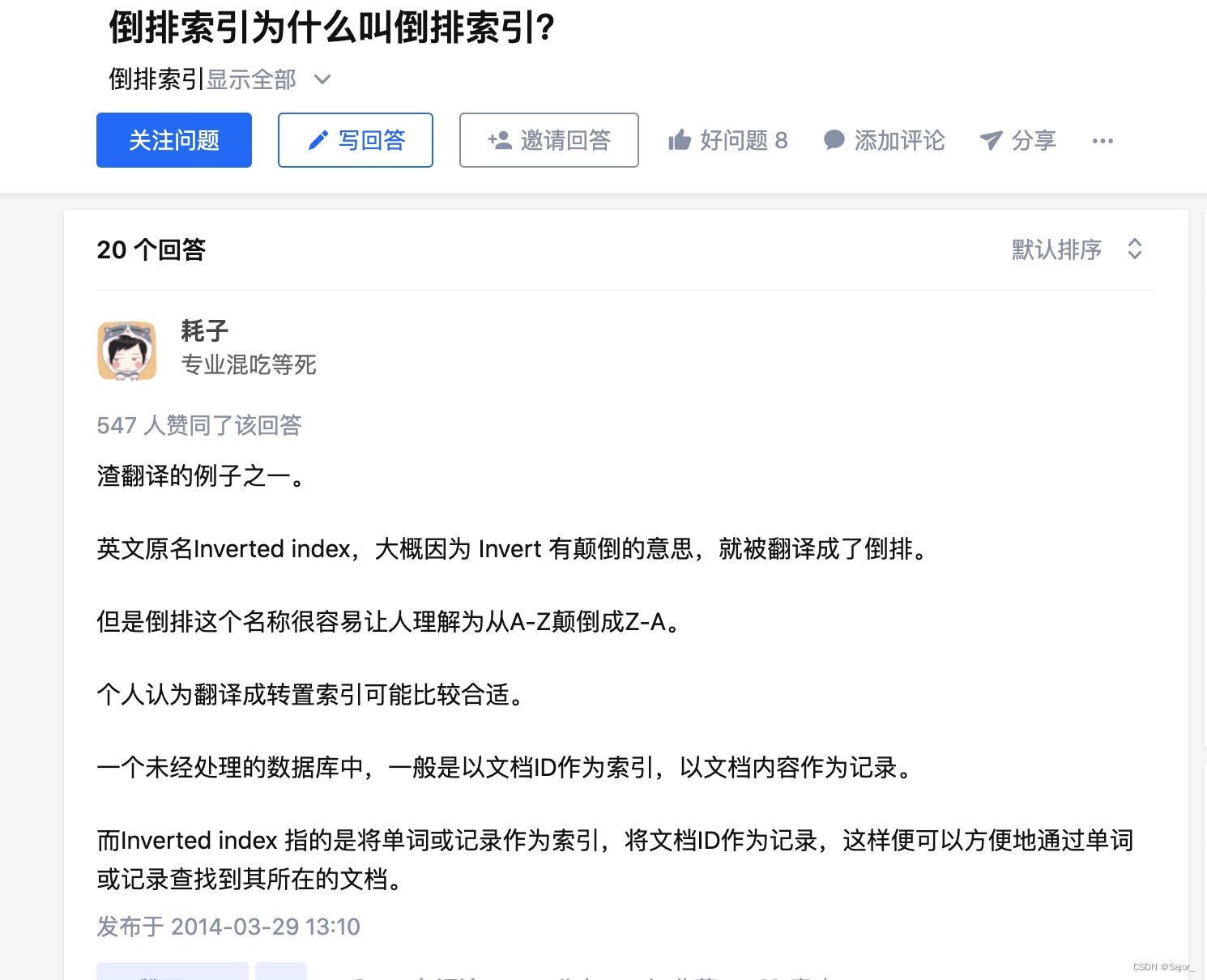
倒排索引
之后才知道,原来我代码中构建的bigMap其实是一个倒排索引,马上补习了关于倒排索引的知识。
顾名思义,有倒排就有正排。正排索引-forward index;倒排索引-inverted index。正排索引都知道,就是MySQL的索引,按id给数据排索引。
拓展
这个功能其实也可以用到录入时的重复联想功能里面。这里大概讲一下我能想到的思路。
我们可以用一颗 Trie 树来存储经过分词并转拼音后的主播名称。数据可以直接直接存到缓存中,便于快速读取。
前端在输入新主播名称时有两种做法:
- 先分词后,再转拼音直接从 Trie 树上查找有没有匹配到主播。这个消耗时间主要分词的效率。
- 也可以不分词,直接转拼音之后从 Trie 上查找,但是需要循环每个字作为开始。这就依赖匹配的效率了。这里可以将 Tire 魔改成基于字的AC自动机,在构建失配指针的时候要基于一个字,这样可以优化循环;