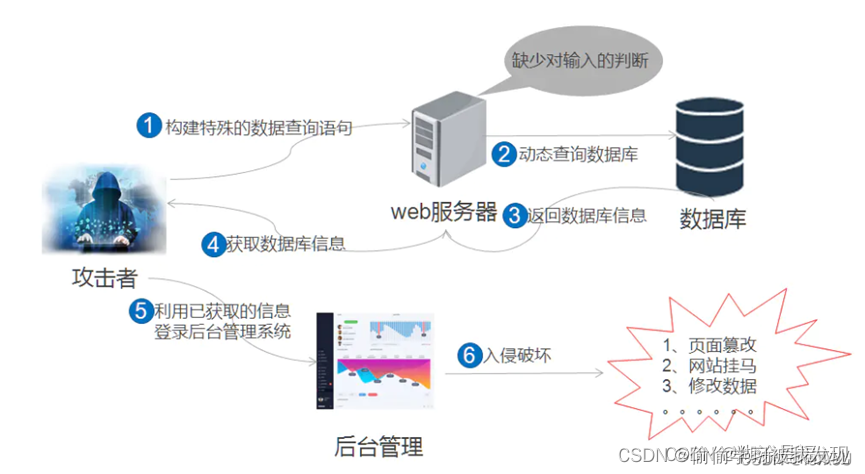
文章目录
- The arrival Process
- Queueing System
- The M/M/1 queue
- The M/M/1/N queue
- References
排队理论已被用于评估通信网络的性能很多年了。早在1917年,丹麦数学家 Erlang 就将该理论用于电话交换机的设计,并开创了现在著名的 Erlang-B 和 Erlang-C 公式,从那时起,这些公式就被用于许多应用中。自从引入分组交换后,排队论在通信网络的设计和分析中的重要性更加不言而喻。
The arrival Process
任何分组交换通信网络模型的第一个要求是对进入系统的数据包进行建模。最常见的方法是使用泊松过程。泊松过程对进入到网络的数据包的时间分布有很好的建模。
我们考虑一个时间间隔 Δ t \Delta t Δt, Δ t → 0 \Delta t \to 0 Δt→0。那么可以用以下三点来定义一个泊松到达过程:
- 在
Δ
t
\Delta t
Δt 中有包到达的可能性:
P
(
o
n
e
a
r
r
i
v
a
l
)
≜
λ
Δ
t
+
O
(
Δ
t
)
P({\rm one\ arrival}) \triangleq \lambda \Delta t+O(\Delta t)
P(one arrival)≜λΔt+O(Δt)
- 其中,
λ
Δ
t
≪
1
\lambda \Delta t \ll 1
λΔt≪1,
λ
\lambda
λ 是一个比例常数,
O
(
Δ
t
)
O(\Delta t)
O(Δt) 表示
Δ
t
\Delta t
Δt 中可忽略的高阶项。例如,如果
Δ
t
=
1
0
−
6
\Delta t=10^{-6}
Δt=10−6 s,那么
(
Δ
t
)
2
=
1
0
−
12
(\Delta t)^2=10^{-12}
(Δt)2=10−12 s 就是一个高阶项,和
Δ
t
\Delta t
Δt 比起来完全可以忽略。
- 其中,
λ
Δ
t
≪
1
\lambda \Delta t \ll 1
λΔt≪1,
λ
\lambda
λ 是一个比例常数,
O
(
Δ
t
)
O(\Delta t)
O(Δt) 表示
Δ
t
\Delta t
Δt 中可忽略的高阶项。例如,如果
Δ
t
=
1
0
−
6
\Delta t=10^{-6}
Δt=10−6 s,那么
(
Δ
t
)
2
=
1
0
−
12
(\Delta t)^2=10^{-12}
(Δt)2=10−12 s 就是一个高阶项,和
Δ
t
\Delta t
Δt 比起来完全可以忽略。
- 在
Δ
t
\Delta t
Δt 中无包到达的可能性:
P
(
n
o
a
r
r
i
v
a
l
)
=
1
−
λ
Δ
t
+
O
(
Δ
t
)
P({\rm no\ arrival}) = 1- \lambda \Delta t+O(\Delta t)
P(no arrival)=1−λΔt+O(Δt)
- 包的到达是无记忆性的(memoryless)。也就是说,在每个 Δ t \Delta t Δt 包的到达与否都是互相独立的。
如果我们不考虑高阶项,那么公式就简化为
P ( o n e a r r i v a l ) = λ Δ t P ( n o a r r i v a l ) = 1 − λ Δ t P({\rm one\ arrival}) = \lambda \Delta t \\ P({\rm no\ arrival}) = 1- \lambda \Delta t P(one arrival)=λΔtP(no arrival)=1−λΔt
现在我们有一个大的时间区间
T
T
T,将它再分成
n
n
n 个小区间,每个小区间为
Δ
t
=
T
/
n
\Delta t =T/n
Δt=T/n。然后我们可以用伯努利分布算出
T
T
T 时间内有
k
k
k 个到达的概率:
P
(
k
a
r
r
i
v
a
l
s
i
n
T
)
=
P
(
k
)
=
(
n
k
)
(
λ
Δ
t
)
k
(
1
−
λ
Δ
t
)
n
−
k
P({\rm k\ arrivals\ in\ T})=P(k)=\binom{n}{k}( \lambda \Delta t)^k(1- \lambda \Delta t)^{n-k}
P(k arrivals in T)=P(k)=(kn)(λΔt)k(1−λΔt)n−k
我们将 ( n k ) \binom{n}{k} (kn) 写开成 n ! ( n − k ) ! k ! \frac{n!}{(n-k)!k!} (n−k)!k!n!,且将 Δ t = T / n \Delta t =T/n Δt=T/n 代入得到
P ( k ) = ( λ T ) k k ! ( 1 − λ T n ) n n ( n − 1 ) . . . ( n − k + 1 ) n k ( 1 − λ T n ) − k P(k) = \frac{(\lambda T)^k}{k!}\left(1-\frac{\lambda T}{n}\right)^n \frac{n(n-1)...(n-k+1)}{n^k}\left(1-\frac{\lambda T}{n}\right)^{-k} P(k)=k!(λT)k(1−nλT)nnkn(n−1)...(n−k+1)(1−nλT)−k
令 n → ∞ n\to \infty n→∞,那么
( 1 − λ T n ) n → e − λ T \left(1-\frac{\lambda T}{n}\right)^n \to e^{-\lambda T} (1−nλT)n→e−λT
n ( n − 1 ) . . . ( n − k + 1 ) n k → 1 \frac{n(n-1)...(n-k+1)}{n^k} \to 1 nkn(n−1)...(n−k+1)→1
( 1 − λ T n ) − k → 1 \left(1-\frac{\lambda T}{n}\right)^{-k} \to 1 (1−nλT)−k→1
因此公式简化为
P ( k ) = ( λ T ) k k ! e − λ T , k = 0 , 1 , 2 , … , ∞ P(k)=\frac{(\lambda T)^k}{k!}e^{-\lambda T},\quad k=0, 1, 2,\dots, \infty P(k)=k!(λT)ke−λT,k=0,1,2,…,∞
这不就是泊松分布嘛!
泊松分布的均值大家应该也知道,所以 T T T 时间内包平均到达的数量即为 λ T \lambda T λT。
Queueing System
-
一个排队系统通常可以用肯德尔记号(Kendall’s notation)来描述。肯德尔记号的形式形如 a/b/c/d/e 共五个字段,它们分别代表
- a: arrival process
- b: service process
- c: number of servers
- d: system capacity
- e: maximum number of potential customers
-
a 的描述符有:
-
- M:代表 memoryless,每个到达的间隔时间是指数分布的,例如我们上面讨论的泊松过程
-
- D:代表 deterministic,每个到达的间隔时间是常数
-
- G:代表 general,包含所有的 arrival process
-
- Geo:代表 geometric,离散的指数间隔时间分布
第二个字段,b,可以用第一个字段中使用的任何描述符来代替,只是这些描述符现在描述的是 service process 而不是 arrival process。
第三个字段,显而易见,用正整数来表示。第四个和第五个字段也是使用正整数。如果这些字段中的某个忽略不写,那么会默认为无穷。
例如 M/M/1 表示:泊松过程、指数服务时间、单个服务器、无穷客户数量、潜在的无穷客户数量。
Geo/D/1//N 表示:geometric 分布的到达时间、确定的服务时间(固定大小的包)、单个服务器、无穷客户数量、最大的潜在客户数量 N
The M/M/1 queue
对于 M/M/1 队列,我们假设到达速率为 λ \lambda λ,服务速率为 μ \mu μ,队列的状态为队列中等候服务的“客户”(包)数量。我们可以画出描述这个队列的状态转移图:

当处于状态 0 时,队列是空的,一个到达可能以 λ Δ t \lambda \Delta t λΔt 的概率发生。
在状态 1 中,队列中有一个客户,这个客户可以以 μ Δ t \mu \Delta t μΔt 的概率得到服务,在这种情况下,队列返回状态 0。或者这时有一个到达,队列会进入状态 2。
根据上面的分析,状态 k 和状态 k+1 之间的关系为
λ P ( k ) = μ P ( k + 1 ) , k ≥ 0 \lambda P(k) = \mu P(k+1),\quad k \ge 0 λP(k)=μP(k+1),k≥0
我们将 λ / μ \lambda/\mu λ/μ 写为 ρ \rho ρ,所以有
P ( k + 1 ) = ρ P ( k ) , k ≥ 0 P(k+1) = \rho P(k),\quad k \ge 0 P(k+1)=ρP(k),k≥0
我们从 k = 0 k=0 k=0 开始代入,会发现如下规律:
P ( k ) = ρ k P ( 0 ) , k ≥ 0 P(k) = \rho^kP(0),\quad k \ge 0 P(k)=ρkP(0),k≥0
将此式代入 ∑ k = 0 ∞ P ( k ) = 1 \sum_{k=0}^\infty P(k)=1 ∑k=0∞P(k)=1 中,有
P ( 0 ) ∑ k = 0 ∞ ρ k = 1 P(0)\sum_{k=0}^\infty \rho^k=1 P(0)k=0∑∞ρk=1
式中的无穷等比数列由公式很容易算出,因此我们可以计算出 P ( 0 ) = 1 − ρ P(0)=1-\rho P(0)=1−ρ.
所以最终得出
P ( k ) = ρ k ( 1 − ρ ) , k ≥ 0 P(k) = \rho^k(1-\rho),\quad k \ge 0 P(k)=ρk(1−ρ),k≥0
平均吞吐量(Mean Throughput):平均吞吐量被定义为单位时间内通过系统的平均客户数量。
因为我们的服务速率为
μ
\mu
μ,所以平均吞吐量为
S
=
μ
∑
k
=
1
∞
P
(
k
)
=
λ
S = \mu \sum_{k=1}^\infty P(k) = \lambda
S=μk=1∑∞P(k)=λ
平均系统延迟(mean system delay):平均系统延迟被定义为一个客户从进入系统到服务完毕离开系统的时间。我们通常通过 Little’s result 间接计算平均系统延迟。
Little’s result 表明,系统的平均客户数量等于到达速率和平均系统延迟的乘积:
L
=
λ
W
L=\lambda W
L=λW
而平均客户数量的计算如下:
L
=
∑
k
=
0
∞
k
P
(
k
)
=
ρ
(
1
−
ρ
)
∑
k
=
1
∞
k
ρ
k
−
1
L = \sum_{k=0}^\infty kP(k)=\rho(1-\rho)\sum_{k=1}^\infty k\rho^{k-1}
L=k=0∑∞kP(k)=ρ(1−ρ)k=1∑∞kρk−1
假设
ρ
<
1
\rho < 1
ρ<1,也就是说服务速率大于到达速率,那么以上公式可以简化为
L
=
ρ
1
−
ρ
L = \frac{\rho}{1-\rho}
L=1−ρρ
所以平均系统延迟可以相应被表示为
W
=
L
λ
=
1
μ
−
λ
W=\frac{L}{\lambda}=\frac{1}{\mu-\lambda}
W=λL=μ−λ1
补充:
∑
n
=
0
∞
x
n
=
1
1
−
x
\sum_{n=0}^\infty x^n=\frac{1}{1-x}
n=0∑∞xn=1−x1
∑ n = 1 ∞ n x n = x ( 1 − x ) 2 \sum_{n=1}^\infty nx^n=\frac{x}{(1-x)^2} n=1∑∞nxn=(1−x)2x
The M/M/1/N queue
M/M/1/N 队列与 M/M/1 队列相同,只是它的客户容量为有限值 N,因此状态转移图必须被修改为只有 0 到 N 共 N+1 个状态。

M/M/1/N queue 的公式推导与 M/M/1 基本一致,我们直接给出如下结果:
P
(
k
)
=
{
ρ
k
1
−
ρ
1
−
ρ
N
+
1
,
ρ
≠
1
ρ
k
N
+
1
,
ρ
=
1
P(k)=\left\{ \begin{aligned} \rho^k\frac{1-\rho}{1-\rho^{N+1}},\quad \rho \neq 1 \\ \frac{\rho^k}{N+1}, \quad \rho=1 \end{aligned} \right.
P(k)=⎩⎪⎪⎨⎪⎪⎧ρk1−ρN+11−ρ,ρ=1N+1ρk,ρ=1
因缓存满而丢包的概率:
P
L
=
P
(
N
)
=
{
ρ
N
(
1
−
ρ
)
1
−
ρ
N
+
1
,
ρ
≠
1
1
N
+
1
,
ρ
=
1
P_L=P(N)=\left\{ \begin{aligned} \frac{\rho^N(1-\rho)}{1-\rho^{N+1}},\quad \rho \neq 1 \\ \frac{1}{N+1}, \quad \rho=1 \end{aligned} \right.
PL=P(N)=⎩⎪⎪⎨⎪⎪⎧1−ρN+1ρN(1−ρ),ρ=1N+11,ρ=1
平均吞吐量:
S
=
λ
(
1
−
P
L
)
S=\lambda(1-P_L)
S=λ(1−PL)
平均系统延迟:
W
=
L
S
=
1
S
∑
k
=
0
N
k
P
(
k
)
W=\frac{L}{S}=\frac{1}{S}\sum_{k=0}^NkP(k)
W=SL=S1k=0∑NkP(k)
References
Digital Communications, by Ian Glover, Dr Peter Grant. Chapter 19.




![[附源码]计算机毕业设计JAVA某城市参军和退役军人信息管理系统](https://img-blog.csdnimg.cn/415fd09bd51b4090943704fd9d1ba0f7.png)





![[附源码]java毕业设计医疗预约系统](https://img-blog.csdnimg.cn/eb6d2c0baa4249049b763bc872188fef.png)