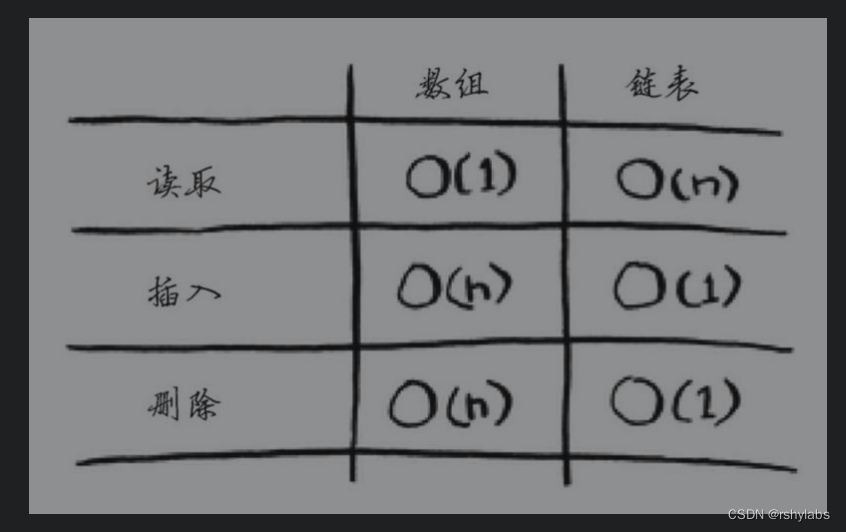
索引数据结构的考量
我们在考虑数据结构的时候,应该首先要知道数据存放在哪里?
而MYSQL的数据是持久化的,所以其数据(数据记录+索引)应该是保存在磁盘里面的。因此当我们要查询某条数据记录时,就会先从磁盘中读取索引到内存中,然后再通过内存索引数据找到该条记录在磁盘的某个位置上,最后将其读到内存中。所以查询过程中会发生多次磁盘I/O,而I/O越多耗时越长。
所以,我们索引数据结构应该要尽可能少的磁盘的 I/O 操作就能完成查询工作。
另外,MySQL 是支持范围查找的,所以索引的数据结构不仅要能高效地查询某一个记录,而且也要能高效地执行范围查找。
所以,一个适合 MySQL 索引的数据结构,至少满足以下要求:
1. 能在尽可能少的磁盘的 I/O 操作中完成查询工作
2. 要能高效地查询某一个记录,也要能高效地执行范围查找
索引数据结构的演变
二分查找
索引数据最好能按顺序排列,可以使用「二分查找法」高效定位数据。因为二分查找法每次都把查询的范围减半,这样时间复杂度就降到了 O(logn),但是每次查找都需要不断计算中间位置。
但是二分查找法线要求性表必须采用顺序存储结构(如数组),所以插入新数据时,性能很低。因为我们插入一个新数据,就要把该数据后面的所有数据后移一位,如果这样的操作发生在磁盘中,那么必然是不行的,因为磁盘的速度比内存慢几十万倍,所以不能使用一种线性结构在磁盘排序。
二叉查找树
由于二分查找存在两大缺点:
每次查找都需要不断计算中间位置
顺序存储结构
所以我们能不能解决这两个问题呢?设计一个非线性而且不需要计算中间位置的二分查找数据结构呢?
答案是肯定的,假如我们把所有的中间节点使用指针连接起来,如下图:
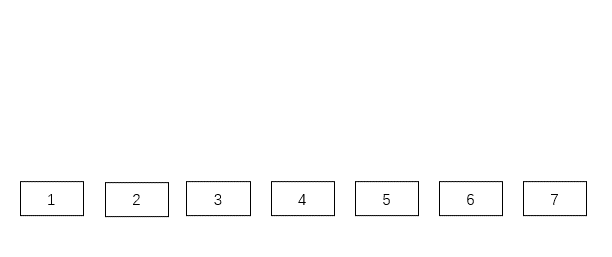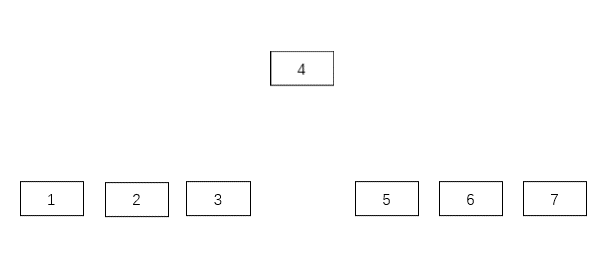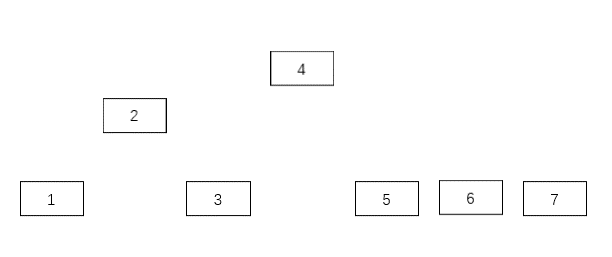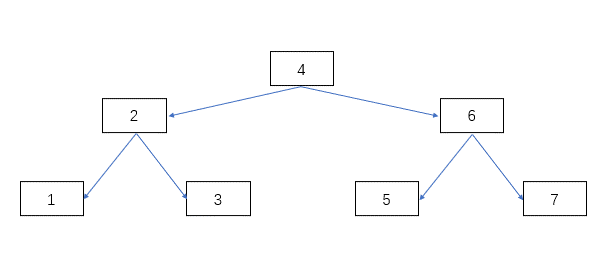
通过上面的动态图,我们可以知道最后就是一个二叉查找树。
二叉查找树的特点:
二叉查找树的特点是一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都大于这个节点
通过二叉查找树的特点,我们来看看二叉查找树的查询过程,如下图:
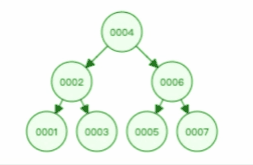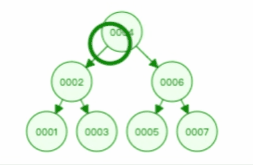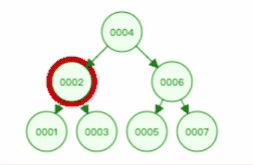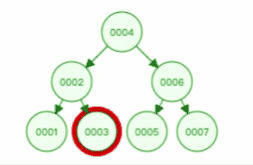
另外,二叉查找树的节点是通过指针连接起来的,所以二叉查找树是一个跳跃结构,不必连续排列,从而解决了二分查找法的插入新节点的问题。二叉查找树插入新节点过程如下:

但是,二叉查找树还是不能作为索引的数据结构,因为它有一种极端情况,如下图:

从图可以看出,每次插入的数据都大于二叉查找树的数据,从而退化成了一条链表,查找数据的时间复杂度变成了 O(n)。
由于索引是存放在磁盘中的,所以每访问一个节点就会发生一次I/O操作,也就是说树的高度就是查询数据时磁盘 IO 操作的次数。所以二叉查找树不适合作为数据库的索引结构原因如下:
1. 二叉查找树由于存在退化成链表的可能性,会使得查询操作的时间复杂度从 O(logn)降低为 O(n)
2. 随着插入的元素越多,树的高度也变高,意味着需要磁盘 IO 操作的次数就越多,这样导致查询性能严重下降,再加上不能范围查询
平衡二叉查找树(AVL 树)
为了解决二叉查找树会在极端情况下退化成链表的问题,引进了平衡二叉查找树(AVL 树)
平衡二叉查找树(AVL 树)的新增条件约束:
每个节点的左子树和右子树的高度差不能超过 1
从的条件约束,我们知道平衡二叉查找树(AVL 树)的查找数据的时间复杂度一直是O(logn)。下图是平衡二叉查找树(AVL 树)平衡的过程:
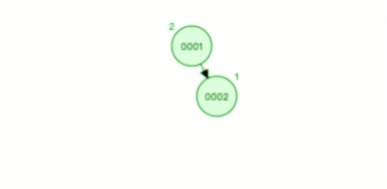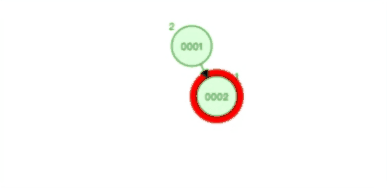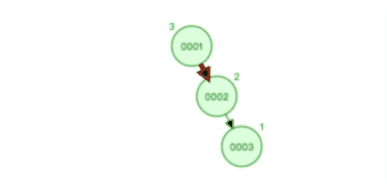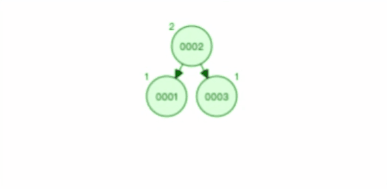
当然了自平衡的二叉树,除了平衡二叉查找树(AVL 树)外,还有很多,比如红黑树。只是各自条件约束不同,要了解更多可以自己查询相关的数据结构书籍。但话又说回来,不管平衡二叉查找树还是红黑树,都会随着插入的元素增多,而导致树的高度变高,这就意味着磁盘 I/O 操作次数多,会影响整体数据查询的效率。
但是,不过是什么样的二叉树都有一个根本问题,那就是它们都是二叉树,只能有两个子节点。所以它们无法解决树的高度问题。那么就会有人会说,那么把二叉树变为M(M>2)叉树不就好了。这样,当树的节点越多的时候,并且树的分叉数 M 越大的时候,M 叉树的高度会远小于二叉树的高度。
B树
为了解决树的高度问题,引进了B 树。即不再像二叉树那样限制每个节点只能有2个子节点,它允许有M(M>2)个子节点,来解决树的高度问题,同时M就是B 树的阶。
M(M>2)阶的 B 树的特点:
1. 每个节点最多有 M-1个数据
2. 最多有 M个子节点
一旦超出了M(M>2)阶的 B 树的特点要求,就会产生分裂节点,如下 3 阶的 B 树分裂过程:

说了那么 多B 树,那么 B 树是怎么查找数据的呢?如下:
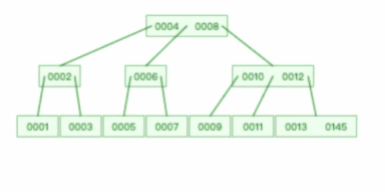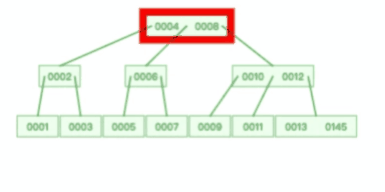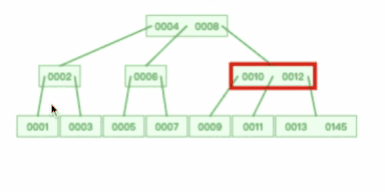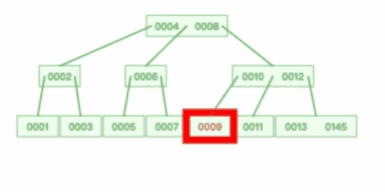
从上图可以看出,一棵 3 阶的 B 树在查询叶子节点中的数据时,由于树的高度是 3 ,所以在查询过程中会发生 3 次磁盘 I/O 操作。如果相同的节点数据放到平衡二叉树下,那么树的高度就会很高,意味着磁盘 I/O 操作会更多。
那么就会有人会说,那就用B 树做索引了。但是B 树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,这就需要花费更多的磁盘 I/O 操作次数来读到有用的索引数据。从而读取了很多无用的记录数据,而且为了读到有用的索引数据,要增加磁盘 I/O 操作次数。
另外,如果使用 B 树来做范围查询的话,需要使用中序遍历,这会涉及多个节点的磁盘 I/O 问题,从而导致整体速度下降。
B+树
B+树是对B树的优化,下面通过图简单说明:
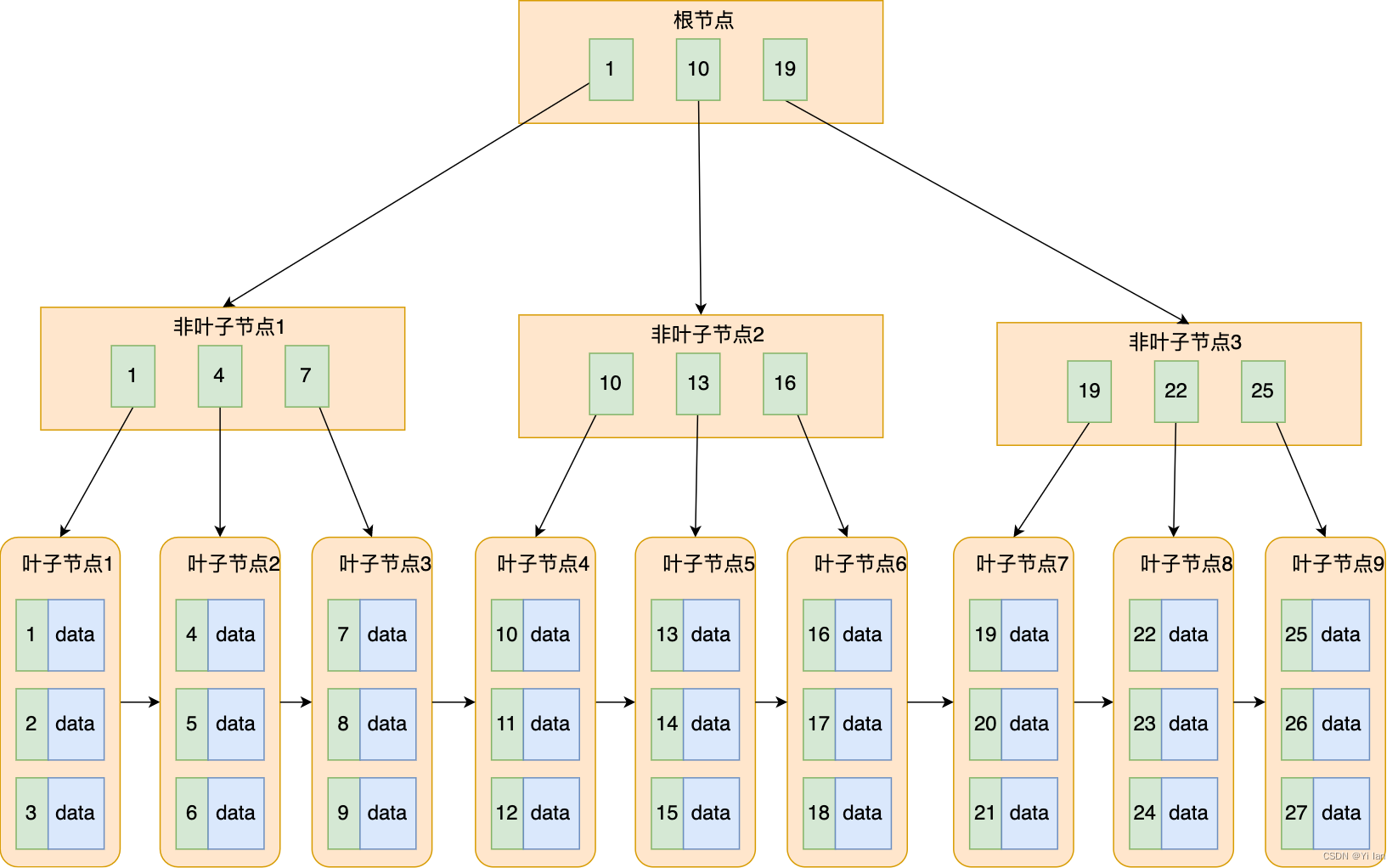
B+ 树的数据存储的特点:
1. 聚簇索引的叶子节点才会存放实际数据(索引+记录),非叶子节点只会存放索引
2. 非聚簇索引的叶子节点只会存放索引 + 主键值
3. 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表
4. 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)
5. 非叶子节点中有多少个子节点,就有多少个索引
B+ 和 B 树的比较主要通过这三方面:单点查询, 范围查询, 插入和删除效率
单点查询
从单个索引查询来看的话, B 树的平均用时要比B+ 树快一些。但是 B 树的波动比较大,因为B 树每个节点都存放索引+ 记录,所以有时候在非叶子节点找到索引,有时候要到叶子节点才能找到索引。
而B+ 树不同,它的非叶子节点只会存放索引,所以相同数量的情况下,要比即存索引又存记录的B 树来说,B+ 树非叶子节点能存放更多的索引,所以B+ 树要比B 树更矮胖,查询时磁盘I/O也会更少
范围查询
B 树和 B+ 树等值查询原理基本一致的,都是从根节点进行范围比较,然后递归进入子节点查询。但是,B+ 树的所有叶子节点有一个链表连接起来,这对范围查询非常有帮助。比如我们要找5和15的数据记录,我们可以先找5所在的子叶节点,然后使用链表找到15数据记录就可以了,不需要再从根节点查找15的数据记录,从而也会减少查询时间。
但是B 树是没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
插入和删除效率
B+ 树有大量的冗余节点,这样使得删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点,这样删除非常快,
比如下面这个动图是删除 B+ 树某个叶子节点节点的过程:
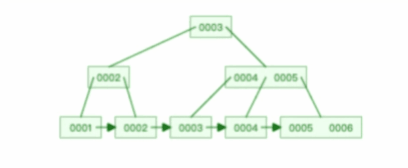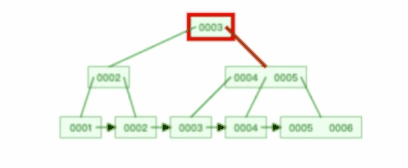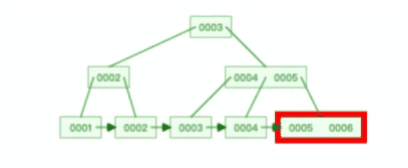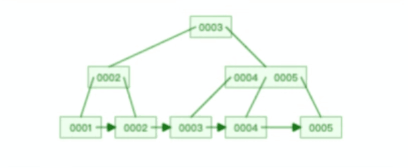
注意,:B+ 树对于非叶子节点的子节点和索引的个数,定义方式可能会有不同,有的是说非叶子节点的子节点的个数为 M 阶,而索引的个数为 M-1(这个是维基百科里的定义),因此我本文关于 B+ 树的动图都是基于这个。但是我在前面介绍 B+ 树与 B+ 树的差异时,说的是「非叶子节点中有多少个子节点,就有多少个索引」,主要是 MySQL 用到的 B+ 树就是这个特性。
甚至,B+ 树在删除根节点的时候,由于存在冗余的节点,所以不会发生复杂的树的变形,比如下面这个动图是删除 B+ 树根节点的过程:
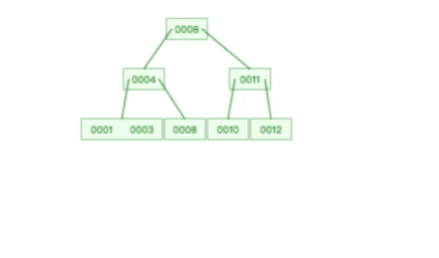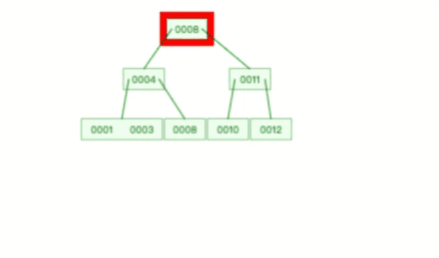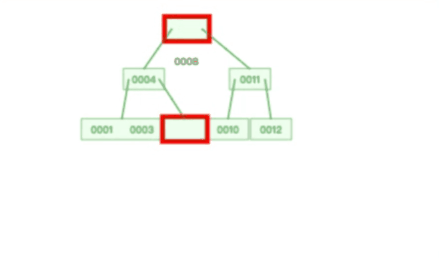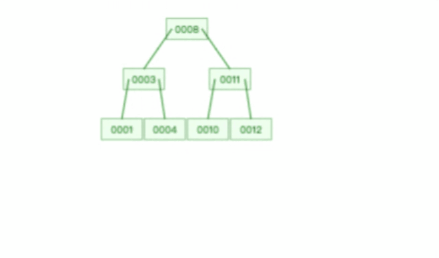
B 树则不同,B 树没有冗余节点,删除节点的时候非常复杂,比如删除根节点中的数据,可能涉及复杂的树的变形,比如下面这个动图是删除 B 树根节点的过程:
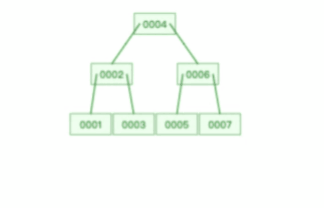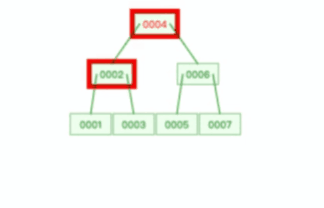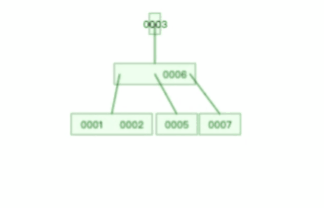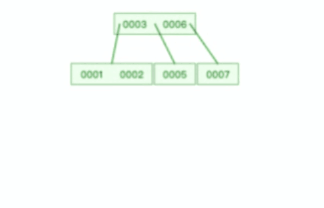
B+ 树的插入也是一样,有冗余节点,插入可能存在节点的分裂(如果节点饱和),但是最多只涉及树的一条路径。而且 B+ 树会自动平衡,不需要像更多复杂的算法,类似红黑树的旋转操作等。
因此,B+ 树的插入和删除效率更高
总结:存在大量范围检索的场景,适合使用 B+树,比如数据库。而对于大量的单个索引查询的场景,可以考虑 B 树,比如 nosql 的MongoDB
MySQL 中的 B+ 树
MySQL 的存储方式根据存储引擎的不同而不同,我们最常用的就是 Innodb 存储引擎,它就是采用了 B+ 树作为了索引的数据结构。
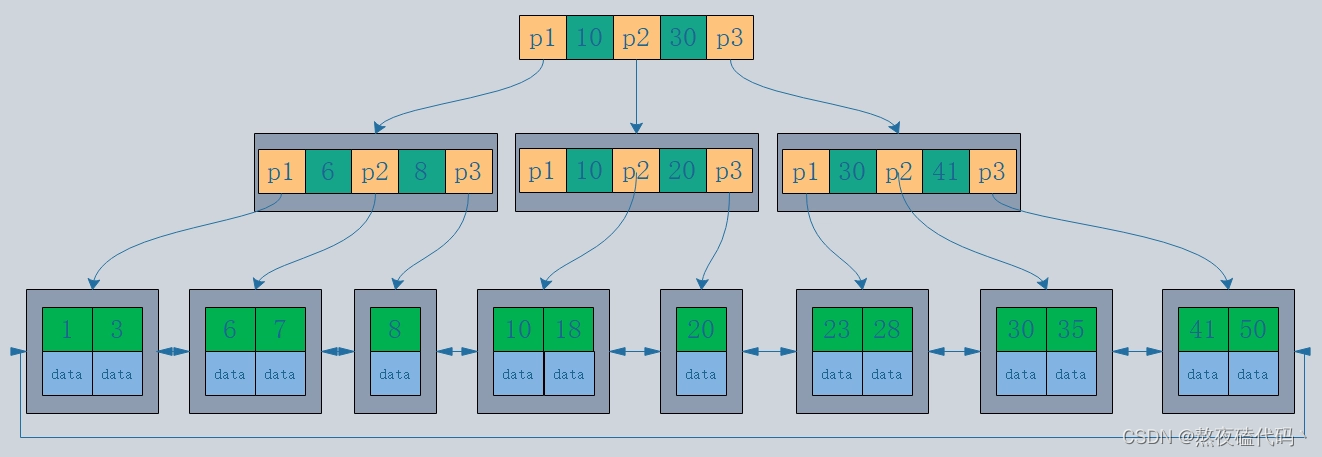
下图就是 Innodb 里的 B+ 树:
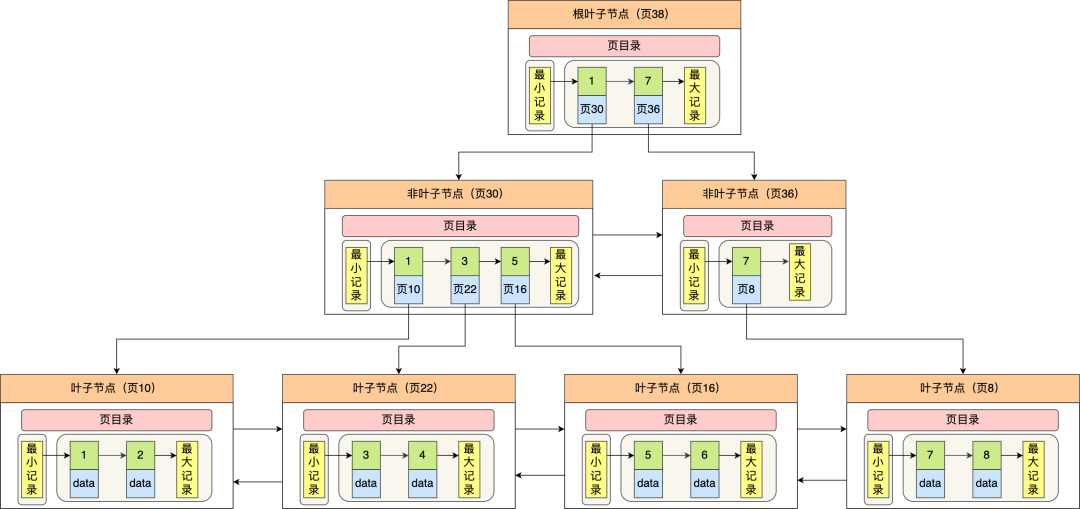
但是 Innodb 使用的 B+ 树有一些特别的点:
1. B+ 树的叶子节点之间是用「双向链表」进行连接,这样的好处是既能向右遍历,也能向左遍历
2. B+ 树点节点内容是数据页,数据页里存放了用户的记录以及各种信息,每个数据页默认大小是 16 KB
Innodb 根据索引类型不同,分为聚集和二级索引。他们区别在于,聚集索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚集索引的叶子节点,而二级索引的叶子节点存放的是主键值,而不是实际数据。
因为表的数据都是存放在聚集索引的叶子节点里,所以 InnoDB 存储引擎一定会为表创建一个聚集索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个,而二级索引可以创建多个。
InnoDB存储数据
存储数据--页
InnoDB 是如何存储数据的呢?我们都知道,我们在查询MYSQL的时候看到的都是一行一行的,难道MYSQL读取的时候以行为单位吗?
答案:当然不是了,如果真的以行为单位,那么每读取一次就进行一次I/O,那效率也太低了。那么读取数据以什么为单位呢?
其实,InnoDB的读写数据是以页为单位的,那就是说每次读取都是一页一页的读,然后存放在内存中。所以数据库磁盘I/O最小单位为页,InnoDB数据页默认大小为16k,这也就是说在InnoDB中每次操作磁盘I/O(读写)都是16k的数据。那么数据页长什么样呢?如下图:
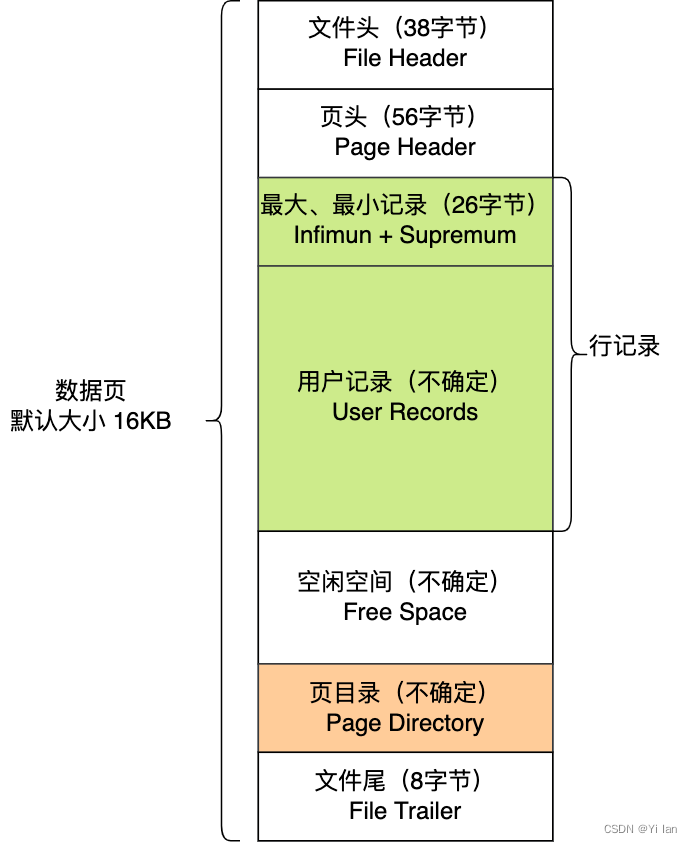
数据页解释说明:
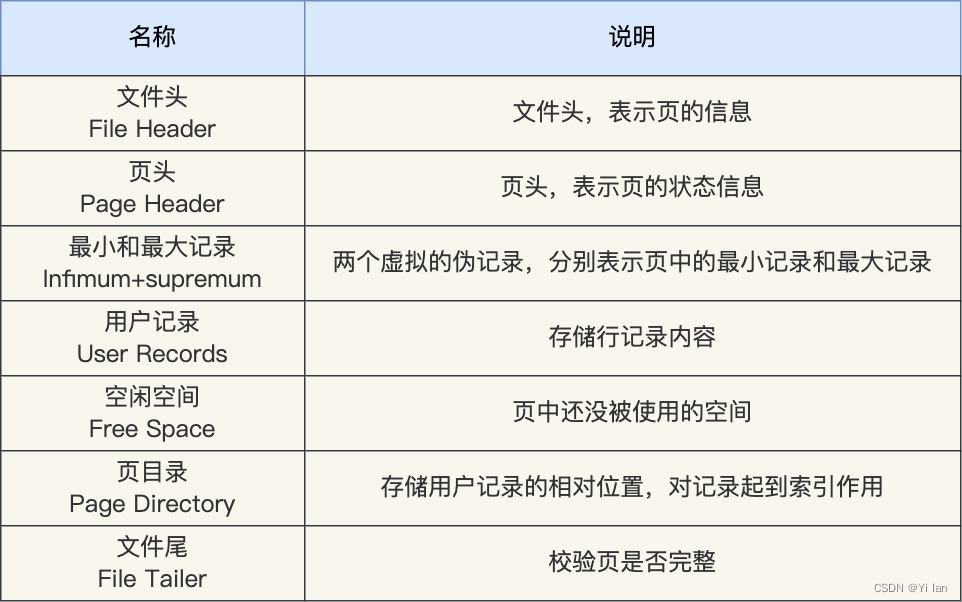
在 File Header文件头中有两个指针,分别指向上一个数据页和下一个数据页,从而形成了双向的链表,如下图:
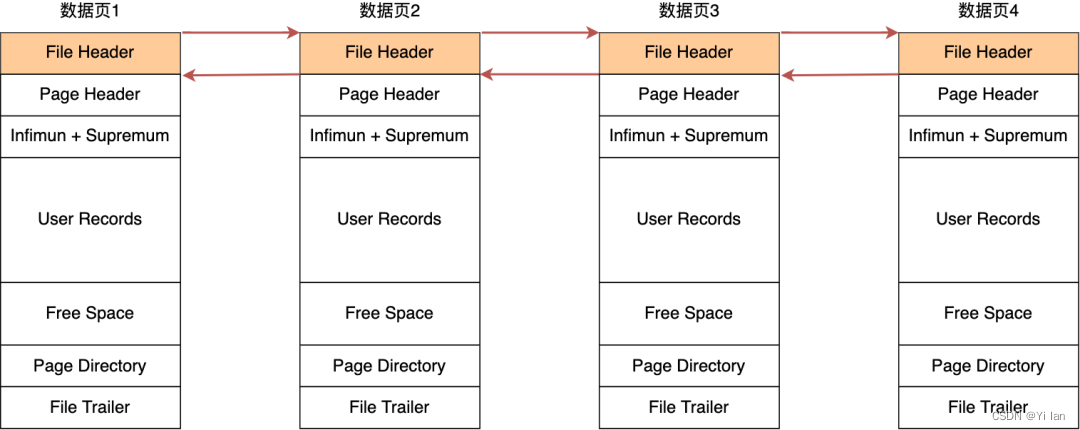
从图我们可以知道,数据页之间不需要是物理上的连续的,而是逻辑上的连续。
在这个数据页中,最重要也是最关心的是User Records用户记录。它就是用于存储记录(即数据库数据或者索引页的索引数据),那它是怎么组织起来的呢?
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
InnoDB中页目录与记录的关系,如下图:
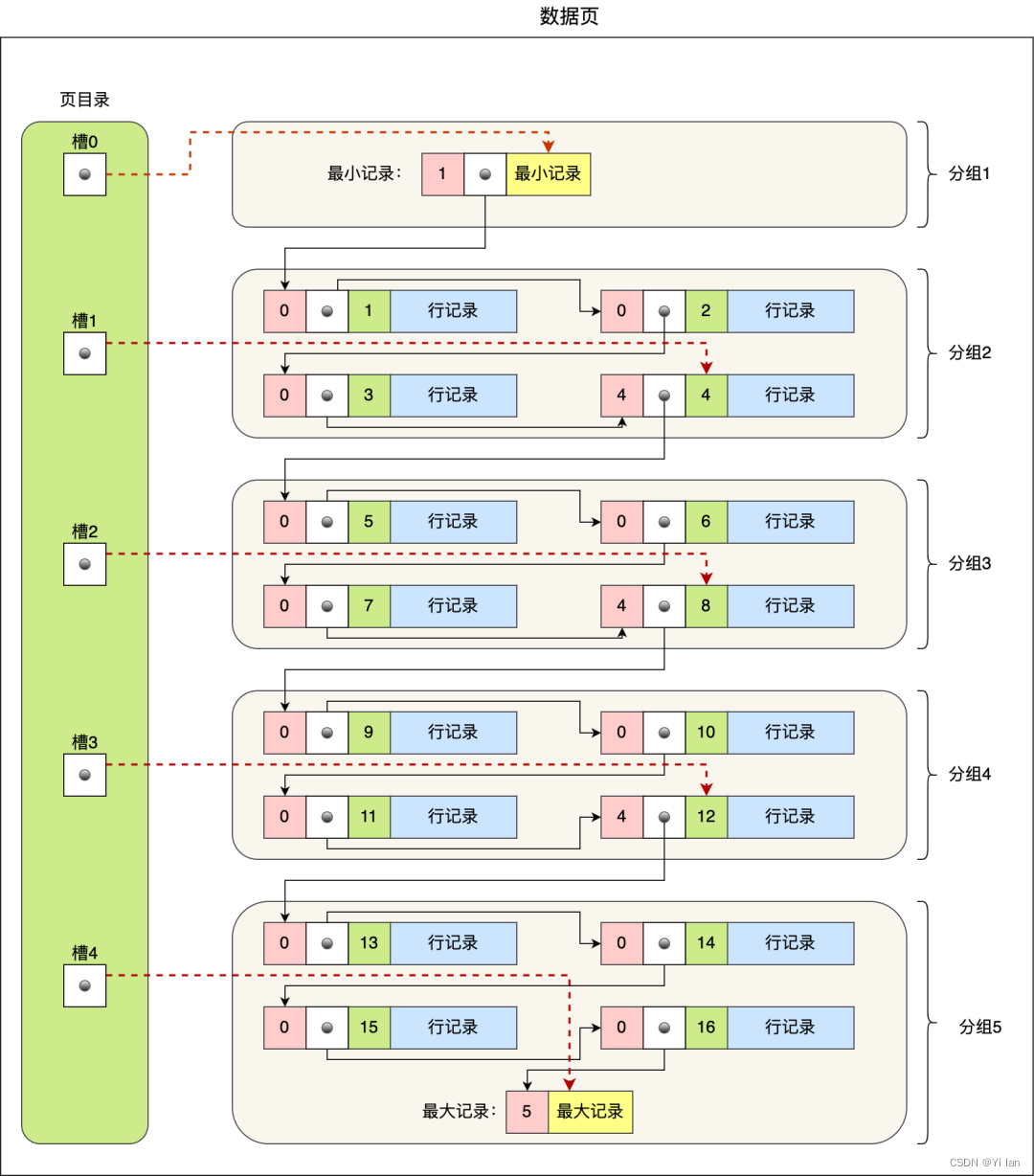
说明:
将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
而且我们也不用担心某个槽内的记录很多,因为在InnoDB 对每个分组中的记录条数都是有规定的,如下:
第一个分组中的记录只能有 1 条记录
最后一个分组中的记录条数范围只能在 1-8 条之间
剩下的分组中记录条数范围只能在 4-8 条之间
一棵B+树可以存放多少条数据
假设B+树高度为2,一行数据记录大小为1k(实际上很多互联网业务数据就是1k左右),单个叶子节点(页)中记录数16K/1K=16。又假设主键为bigint,长度为8字节,指针大小在InnoDB源码中为6字节,这样一共14字节,我们一个页中存放16384/14=1170。那么一棵高度为2的B+树,能存放1170*16=18720条这样的数据。
以此类推,一个高度为3的B+树可以存放:1170*1170*16=21902400条这样的记录。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。通过主键索引查询通常只需要1-3次IO操作即可查找到数据。这也是MySQL 单表最好不要超过 2000w的来源,当然了,如果一行数据记录大小不为1k,那么具体的值要具体计算。
B+树查询
从上面我们知道InnoDB 采用了 B+ 树作为索引存储结构的,那么从数据页的角度看B+树查询过程是怎么样的呢?如下图:
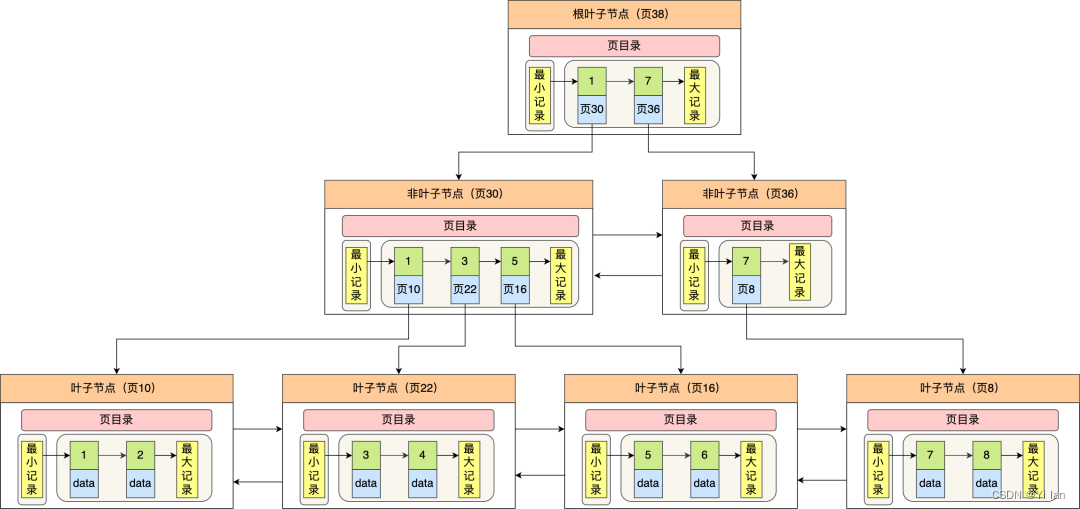
说明:
1. 只有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他上层节)仅用来存放目录项作为索引。
2. 非叶子节点分为不同层次,通过分层来降低每一层的搜索量;
3. 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询
图例子 B+ 树如何实现快速查找主键为 6 的记录 说明:
从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在[1, 7)范围之间,所以到页 30 中查找更详细的目录项;
在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页16)查找记录;
接着,在叶子节点(页16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找
聚集索引和非聚集索引(二级索引)
如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获得数据行,这个过程就叫作「回表」,也就是说要查两个 B+ 树才能查到数据。不过,当查询的数据是主键值时,因为只在二级索引就能查询到,不用再去聚簇索引查,这个过程就叫作「索引覆盖」,也就是只需要查一个 B+ 树就能找到数据。更加详细的说明可以查看MYSQL索引详解和优化
总结
讲解了MYSQL的InnoDB为什么要使用B+ tree作为索引存储结构,然后从InnoDB存储数据 ---数据页的角度了解内部存储的结构
![[附源码]计算机毕业设计JAVA某城市参军和退役军人信息管理系统](https://img-blog.csdnimg.cn/415fd09bd51b4090943704fd9d1ba0f7.png)





![[附源码]java毕业设计医疗预约系统](https://img-blog.csdnimg.cn/eb6d2c0baa4249049b763bc872188fef.png)



![[附源码]java毕业设计疫情防控期间人员档案追寻系统设计与实现论文](https://img-blog.csdnimg.cn/d87e22bcb2104277adecdb7ae3df6f7e.png)