- Dai Quoc Nguyen, Tu Dinh Nguyen, Dinh Phung
- The ACM Web Conference 2022 (WWW '22)
- Computer Vision and Pattern Recognition
- 论文地址
本文介绍的论文是《Universal Graph Transformer Self-Attention Networks》。
该篇文章的主要贡献是将Transformer应用在GNN中用于学习图的表示,作者在此基础上提出了两种UGformer变体,实验结果表明第一个UGformer变体在归纳学习上取得了较好的准确率,而第二个变体在文本分类任务上获得较好的精度。
| 🍁 一、背景 🍁 |
图是一种由节点和边组成的数据类型,这种数据在生活中无处不在,例如药物发现、分子学、社交关系等领域,从图中学习和推理一直是最热门的研究课题之一。
对于传统的图学习方法大多不能够满足现在图数据的复杂性,利用丰富的上下文信息以及使用大规模图进行扩展,目前深度学习在不断发展,图表示学习作为一种新的范式出现,它旨在学习一个参数化的映射函数,能够将节点、子图或者整个图嵌入到一个低维连续向量空间中。
近几年,Transformer在自然语言处理领域中得到了认可,并且广泛使用。受次启发,作者考虑到使用Transformer来嵌入到GNN中,提取图的信息。
| 🍁 二、模型方法 🍁 |
作者提出了一种基于Transformer的GNN模型UGformer来学习图表示,特别地,设计了两种模型变体:
- 在每个输入节点的采样邻居集合上利用Transformer
- 在所有输入节点上利用Transformer
1.单个输入节点:变体1

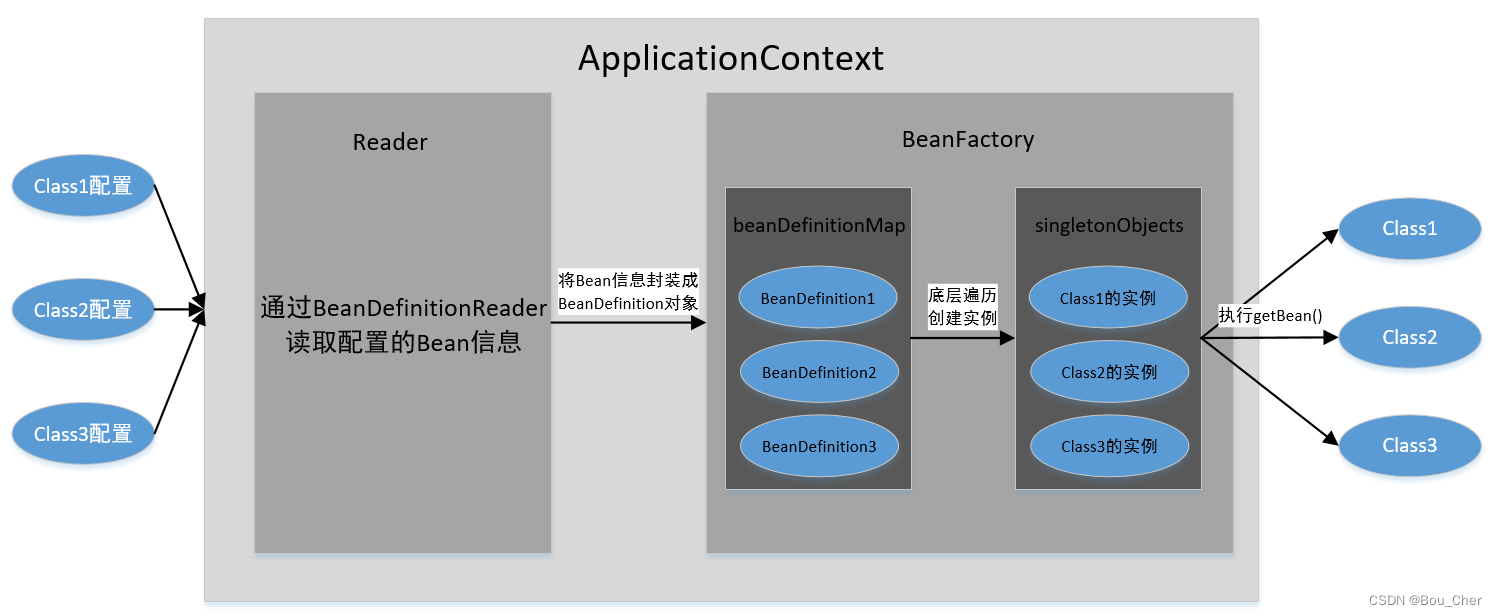
对于第一个变体来将,它会对每个节点使用Transformer进行聚合信息,从上图来看,他会将中心节点3的邻居特征传入Transformer层,然后经过该层后,将3节点位置处加权后的特征信息传出作为3的新的特征表示,可以使用多个Transformer层进行堆叠,获得更高层次的图节点的特征表示。
1.1 计算隐层输出
计算残差输出
1.2 计算注意力分数
获得其它位置对于当前位置的注意力分数
1.3 归一化注意力分数
将注意力分数进行归一化,用于特征加权
2.所有输入节点:变体2

对于第二个变体是将所有节点信息传入Transformer层,用于获取每个节点的特征表示,每个节点的特征表示就是每个位置经过Transformer层后的输出,但是这样知识单纯考虑了所有节点的特征输入,没有考虑到图的拓扑结构,所以在经过Transformer层之后,又加入了一个GNN层来提取图的空间特征,该GNN层的输入就是Transformer的输出,将二者结合能够学习更好的图的嵌入表示。
| 🍁 三、实验结果 🍁 |
1.UGformer Variant 1用于归纳场景下的图形分类
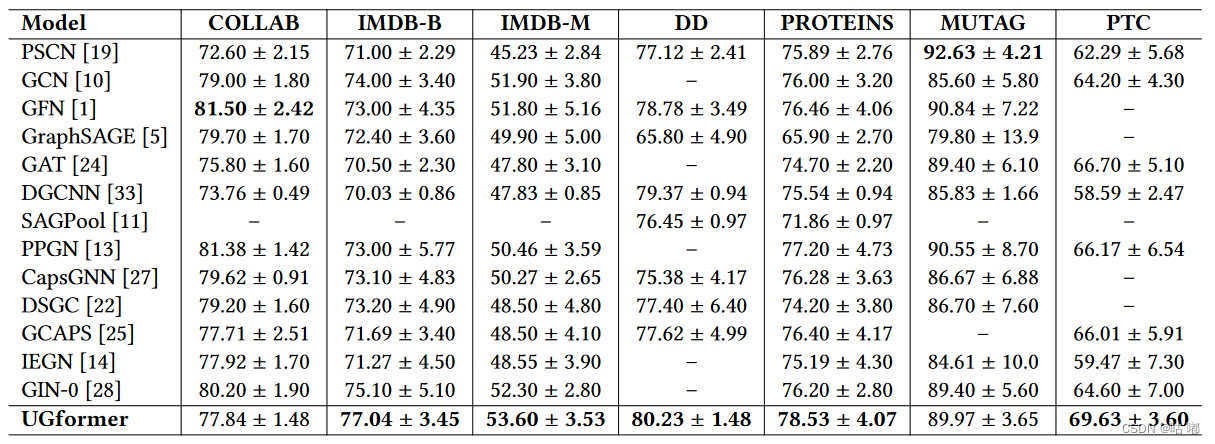
该表给出了UGformer和其他强基线模型在基准数据集上的实验结果。总的来说,UGformer在社交网络数据集上获得了具有竞争力的准确率。特别地,UGformer在IMDB - B和IMDB - M上分别取得了目前最好的精度,优于其他现有模型。在生物信息学数据集上,UGformer分别在DD、PROTEINS和PTC上获得了最高的准确率。此外,由于该数据集仅包含188张图,UGformer与MUTAG上的基线没有显著差异。
2.UGformer Variant 2进行归纳式文本分类
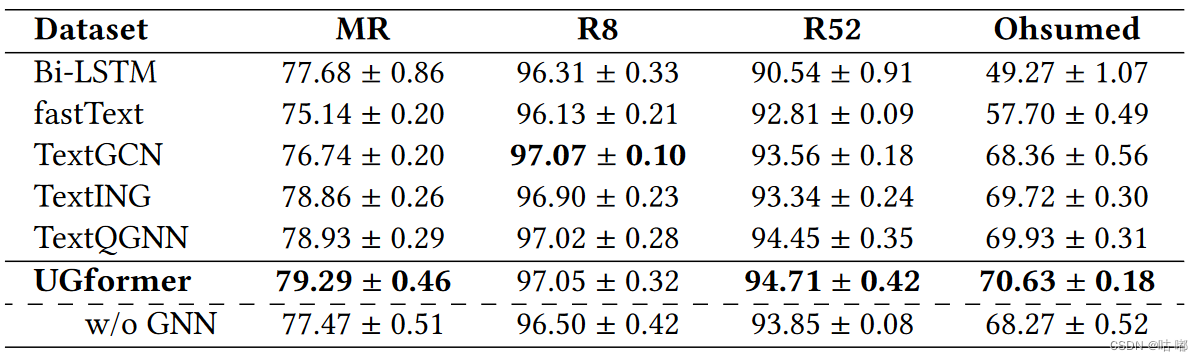
该表给出了本文UGformer与基准模型的分类精度结果。总体而言,UGformer模型优于基准模型,在三个基准数据集R52、Ohsumed和MR上取得了最先进的精度,在R8上获得了极具竞争力的精度。
3.UGformer Variant 1用于"无监督直推"环境下的图分类

该表展示了在无监督直推式环境下的实验结果,其中无监督UGformer和uGCN在基准数据集上获得了新的最新精度。显著的收益表明了无监督直推式学习方法的显著影响。
| 🍁 四、总结 🍁 |
作者提出了一个基于Transformer的GNN模型UGformer来学习图表示。
设计了两种UGformer变体:
- 在每个输入节点的采样邻居集合上利用Transformer
- 在所有输入节点上利用Transformer
实验结果表明,图转换器UGformer在图分类和文本分类的著名基准数据集上产生了先进的精度。此外,还希望未来的GNN工作可以考虑无监督的直推式设置来解决类标签的有限可用性。