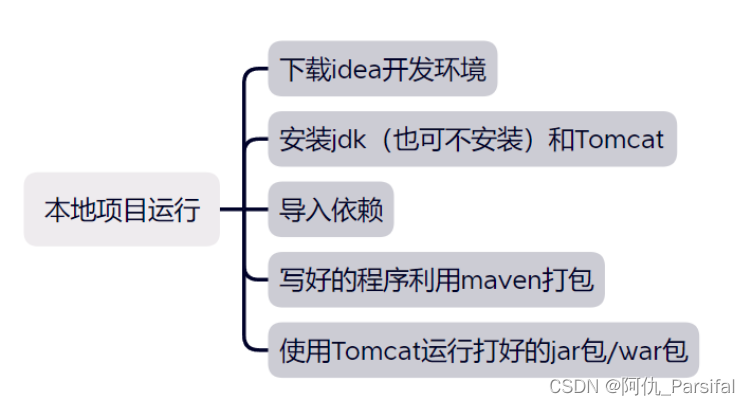
文章目录
- 1 什么是大数据?
- 1.1 大数据计算模式及代表产品
- 1.2 云计算与物联网
- 1.2.1 云计算
- 1.2.1.1 虚拟化
- 1.2.1.2 分布式存储
- 1.2.1.3 分布式计算
- 1.2.1.4 多租户
- 1.3 物联网
- 1.3.1 识别和感知技术
- 1.3.2 网络与通信技术
- 1.3.3 数据挖掘与融合技术
- 1.4 大数据与云计算、物联网的关系
- 2 Hadoop概述
- 2.1 Hadoop基础功能
- 2.1.1 HDFS
- 2.1.2 MapReduce
- 2.2 源码说明
- 2.3 Hadoop版本
- 2.3.1 Apache Hadoop
- 2.3.2 Cloudera Hadoop
- 2.3.3 Hortonworks Hadoop
- 2.4 Hadoop生态体系
- 2.4.1 HDFS
- 2.4.2 HBase
- 2.4.3 MapReduce
- 2.4.4 Hive
- 2.4.5 Pig
- 2.4.6 Mahout
- 2.4.7 Zookeeper
- 2.4.8 Flume
- 2.4.9 Sqoop
- 2.4.10 Ambari
- 3 Apache Hadoop版本介绍
- 3.1 Hadoop1.X
- 3.1.1 容错机制
- 3.1.2 Hadoop1.x时代的HDFS架构
- 3.1.3 Hadoop1.x的HDFS架构的局限
- 3.1.4 NameNode HA(高可用)
- 3.1.5 Hadoop1.x时代的MapReduce
- 3.2.Hadoop2.X
- 3.2.1 Hadoop2.x的HDFS Federation
- 3.2.2 HDFS Federation与老HDFS架构的比较
- 3.2.3 NameNode的HA(高可用)
- 3.2.4 Hadoop2中新方案YARN+MapReduce
- 4 Hadoop集群安全策略
- 4.1 用户权限管理
- 4.2 HDFS安全策略
- 4.3.MapReduce安全策略
现在的时代,数据量比之前几年有了很大的增长。无论是做业务分析,还是数据挖掘,如何处理巨大的数据量是需要面临的问题,从本章开始学习Hadoop,逐渐深入到大数据领域中来。
1 什么是大数据?
首先,我们先要了解什么叫大数据。
当人们谈到大数据时,往往并非仅指数据本身,而是数据和大数据技术这二者的综合。所谓大数据技术,是指伴随着大数据的采集、存储、分析和应用的相关技术,是一系列使用非传统的工具来对大量的结构化、半结构化和非结构化数据进行处理,从而获得分析和预测结果的一系列数据处理和分析技术。
大数据的基本处理流程,主要包括数据采集、存储、分析和结果呈现等环节。而大数据技术则是则这些处理流程中,不断涌现的技术。
| 流程 | 技术说明 |
|---|---|
| 数据采集与预处理 | 利用ETL工具将分布的,异构数据源中的数据,如关系数据,平面数据文件等,抽取到临时中间层后进行清晰,转换,集成,最后加载到数据仓库或数据集市中,成为联机分析处理,数据挖掘的基础;也可以利用日志采集工具(如FLume,Kafka等)把实时采集的数据作为流计算系统的输入,进行实时处理分析 |
| 数据存储和管理 | 利用分布式文件系统,数据仓库,关系数据库,NoSQL数据库,云数据库等,实现对结构化,半结构化和非结构化海来数据的存储和管理 |
| 数据处理与分析 | 利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析;对分析结果进行可视化呈现,帮助人们更好地理解数据,分析数据 |
| 数据安全和隐私 | 在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全 |
1.1 大数据计算模式及代表产品
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce,Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm,S4,Flume,Streams,Puma,DStream,SuperMario,银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel,GraphX,Giraph,PowerGraph,Hama,GoldenOrb等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel,Hive,Cassandra,Impla等 |
1.2 云计算与物联网
云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者相辅相成,既有联系又有区别。
1.2.1 云计算
云计算实现了通过网络提供可伸缩的、廉价的分布式计算能力,用户只需要在具备网络接入条件的地方,就可以随时随地获得所需的各种IT资源。
云计算代表了以虚拟化技术为核心、以低成本为目标的、动态可扩展的网络应用基础设施,是近年来最有代表性的网络计算技术与模式。
云计算包括3种典型的服务模式:
- IaaS(基础设施即服务): 将基础设施(计算资源和存储)作为服务出租。
- PaaS(平台即服务): 把平台作为服务出租。
- SaaS(软件即服务): 把软件作为服务出租。
云计算包括公有云、私有云和混合云3种类型:
- 公有云:面向所有用户提供服务,只要是注册付费的用户都可以使用,比如Amazon AWS;
- 私有云:只为特定用户提供服务,比如大型企业出于安全考虑自建的云环境,只为企业内部提供服务;
- 混合云:综合了公有云和私有云的特点,因为对于一些企业而言,一方面出于安全考虑需要把数据放在私有云中,另一方面又希望可以获得公有云的计算资源,为了获得最佳的效果,就可以把公有云和私有云进行混合搭配使用。
云计算的关键技术包括虚拟化、分布式存储、分布式计算、多租户等。
1.2.1.1 虚拟化
虚拟化技术是云计算基础架构的基石,是指将一台计算机虚拟为多台逻辑计算机,在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响。
虚拟化的资源可以是硬件(如服务器、磁盘和网络),也可以是软件。以服务器虚拟化为例,它将服务器物理资源抽象成逻辑资源,让一台服务器变成几台甚至上百台相互隔离的虚拟服务器,不再受限于物理上的界限,而是让CPU、内存、磁盘、I/O等硬件变成可以动态管理的“资源池”,从而提高资源的利用率,简化系统管理,实现服务器整合,让IT对业务的变化更具适应力。
Hyper-V、VMware、KVM、Virtualbox、Xen、Qemu等都是非常典型的虚拟化技术。
- Hyper-V是微软的一款虚拟化产品,旨在为用户提供成本效益更高的虚拟化基础设施软件,从而为用户降低运作成本,提高硬件利用率,优化基础设施,提高服务器的可用性。
- VMware(威睿)是全球桌面到数据中心虚拟化解决方案的领导厂商。
- Docker 是不同于VMware等传统虚拟化技术的一种新型轻量级虚拟化技术(也被称为“容器型虚拟化技术”),具有启动速度快、资源利用率高、性能开销小等优点。
1.2.1.2 分布式存储
面对“数据爆炸”的时代,集中式存储已经无法满足海量数据的存储需求,分布式存储应运而生。
- GFS(Google File System)是谷歌公司推出的一款分布式文件系统,可以满足大型、分布式、对大量数据进行访问的应用的需求。
- HDFS(Hadoop Distributed File System)是对GFS的开源实现,它采用了更加简单的“一次写入、多次读取”文件模型,文件一旦创建、写入并关闭了,之后就只能对它执行读取操作,而不能执行任何修改操作;同时,HDFS是基于Java实现的,具有强大的跨平台兼容性,只要是JDK支持的平台都可以兼容。
- 以GFS为基础开发了分布式数据管理系统BigTable,它是一个稀疏、分布、持续多维度的排序映射数组,适合于非结构化数据存储的数据库,具有高可靠性、高性能、可伸缩等特点,可在廉价PC服务器上搭建起大规模存储集群。HBase是针对BigTable的开源实现。
1.2.1.3 分布式计算
面对海量的数据,传统的单指令单数据流顺序执行的方式已经无法满足快速数据处理的要求,进而产生了一些新颖的计算模式。
- 并行编程模型MapReduce,让任何人都可以在短时间内迅速获得海量计算能力,它允许开发者在不具备并行开发经验的前提下也能够开发出分布式的并行程序,并让其同时运行在数百台机器上,在短时间内完成海量数据的计算。
1.2.1.4 多租户
多租户技术目的在于使大量用户能够共享同一堆栈的软硬件资源,每个用户按需使用资源,能够对软件服务进行客户化配置,而不影响其他用户的使用。多租户技术的核心包括数据隔离、客户化配置、架构扩展和性能定制。
1.3 物联网
物联网是物物相连的互联网,是互联网的延伸,它利用局部网络或互联网等通信技术把传感器、控制器、机器、人员和物等通过新的方式连在一起,形成人与物、物与物相连,实现信息化和远程管理控制。
从技术架构上来看,物联网可分为四层:感知层、网络层、处理层和应用层。如下图:
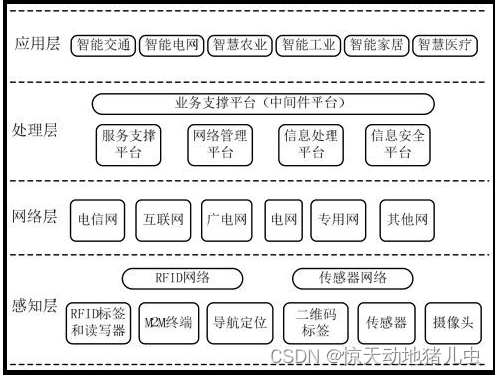
| 层次 | 功能 |
|---|---|
| 感知层 | 用来感知物理世界,采集来自物理世界的各种信息。包含大量的传感器,如温度传感器,湿度传感器,应力传感器,加速度传感器,重力传感器,气体浓度传感器,二维码标签,RFID标签和读写器,摄像头,GPS等 |
| 网络层 | 用于信息传输,包括各种类型的网络,如互联网,移动通信网络,卫星通信网络等 |
| 处理层 | 用于储存和处理信息,包括数据存储,管理和分析平台 |
| 应用层 | 直接面向客户,满足各种应用需求,如智能交通,智慧农业等 |
物联网中的关键技术包括识别和感知技术(二维码、RFID、传感器等)、网络与通信技术、数据挖掘与融合技术等。
1.3.1 识别和感知技术
- 二维码是物联网中一种很重要的自动识别技术,是在一维条码基础上扩展出来的条码技术。二维码包括堆叠式/行排式二维码和矩阵式二维码,后者较为常见。
- RFID 技术用于静止或移动物体的无接触自动识别,具有全天候、无接触、可同时实现多个物体自动识别等特点。如平时使用的公交卡、门禁卡、校园卡等都嵌入了 RFID 芯片,可以实现迅速、便捷的数据交换。
- 传感器是一种能感受规定的被测量件并按照一定的规律(数学函数法则)转换成可用信号的器件或装置,具有微型化、数字化、智能化、网络化等特点。
1.3.2 网络与通信技术
物联网中的网络与通信技术包括短距离无线通信技术和远程通信技术。短距离无线通信技术包括ZigBee、NFC、蓝牙、Wi-Fi、RFID等。远程通信技术包括互联网、2G/3G/4G移动通信网络、卫星通信网络等。
1.3.3 数据挖掘与融合技术
物联网中存在大量数据来源、各种异构网络和不同类型系统,如此大量的不同类型数据,如何实现有效整合、处理和挖掘,是物联网处理层需要解决的关键技术问题。今天,云计算和大数据技术的出现,为物联网数据存储、处理和分析提供了强大的技术支撑,海量物联网数据可以借助于庞大的云计算基础设施实现廉价存储,利用大数据技术实现快速处理和分析,满足各种实际应用需求。
1.4 大数据与云计算、物联网的关系
云计算、大数据和物联网代表了IT领域最新的技术发展趋势,三者既有区别又有联系。
第一,大数据、云计算和物联网的区别。大数据侧重于对海量数据的存储、处理与分析,从海量数据中发现价值,服务于生产和生活;云计算本质上旨在整合和优化各种IT资源,并通过网络以服务的方式廉价地提供给用户;物联网的发展目标是实现物物相连,应用创新是物联网发展的核心。
第二,大数据、云计算和物联网的联系。从整体上看,大数据、云计算和物联网这三者是相辅相成的。大数据根植于云计算,大数据分析的很多技术都来自于云计算,云计算的分布式数据存储和管理系统(包括分布式文件系统和分布式数据库系统)提供了海量数据的存储和管理能力,分布式并行处理框架MapReduce提供了海量数据分析能力,没有这些云计算技术作为支撑,大数据分析就无从谈起。反之,大数据为云计算提供了“用武之地”,没有大数据这个“练兵场”,云计算技术再先进,也不能发挥它的应用价值。物联网的传感器源源不断产生的大量数据,构成了大数据的重要数据来源,没有物联网的飞速发展,就不会带来数据产生方式的变革,即由人工产生阶段转向自动产生阶段,大数据时代也不会这么快就到来。同时,物联网需要借助于云计算和大数据技术,实现物联网大数据的存储、分析和处理。
2 Hadoop概述
Hadoop则是学习大数据相关知识首先要必须先掌握的。
Hadoop原来是Apache Lucene下的一个子项目,它最初是从Nutch项目中分离出来的专门负责分布式存储以及分布式运算的项目。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。其核心是分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce。
下面列举hadoop主要的一些特点:
- 扩容能力(Scalable):能可靠地(reliably)存储和处理千兆字节(PB)数据。
- ** 成本低(Economical)**:可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
- 高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行地(parallel)处理它们,这使得处理非常的快速。
- 靠性(Reliable):hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
2.1 Hadoop基础功能
2.1.1 HDFS
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。是针对谷歌文件系统(Google File System,GFS)的开源实现,是面向普通硬件环境的分布式文件系统,具有较高的读写速度、很好的容错性和可伸缩性,支持大规模数据的分布式存储,其冗余数据存储的方式很好地保证了数据的安全性。
HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
2.1.2 MapReduce
Hadoop还实现了MapReduce分布式计算模型。是针对谷歌 MapReduce 的开源实现,允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,采用MapReduce来整合分布式文件系统上的数据,可保证分析和处理数据的高效性。
MapReduce将应用程序的工作分解成很多小的工作小块(small blocks of work)。HDFS为了做到可靠性(reliability)创建了多份数据块(data blocks)的复制(replicas),并将它们放置在服务器群的计算节点中(compute nodes),MapReduce就可以在它们所在的节点上处理这些数据了。
2.2 源码说明
Hadoop API被分成(divide into)如下几种主要的包(package):
| 包路径 | 说明 |
|---|---|
| org.apache.hadoop.conf | 定义了系统参数的配置文件处理API |
| org.apache.hadoop.fs | 定义了抽象的文件系统API |
| org.apache.hadoop.dfs | Hadoop分布式文件系统(HDFS)模块的实现 |
| org.apache.hadoop.io | 定义了通用的I/O API,用于针对网络,数据库,文件等数据对象做读写操作 |
| org.apache.hadoop.ipc | 用于网络服务端和客户端的工具,封装了网络异步I/O的基础模块 |
| org.apache.hadoop.mapred | Hadoop分布式计算系统(MapReduce)模块的实现,包括任务的分发调度等 |
| org.apache.hadoop.metrics | 定义了用于性能统计信息的API,主要用于mapred和dfs模块 |
| org.apache.hadoop.record | 定义了针对记录的I/O API类以及一个记录描述语言翻译器,用于简化将记录序列化成语言中性的格式(language-neutral manner) |
| org.apache.hadoop.tools | 定义了一些通用的工具 |
| org.apache.hadoop.util | 定义了一些公用的API |
2.3 Hadoop版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。
- Cloudera在大型互联网企业中用的较多。
- Hortonworks文档较好。
其他还有很多公司又二次封装的版本,例如星环Hadoop等。
2.3.1 Apache Hadoop
Apache Hadoop版本分为三代,第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0,第三代是Hadoop3.0。
- 第一代Hadoop包含0.20.x、0.21.x和0.22.x三大版本,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了HDFS HA等重要的新特性。
- 第二代Hadoop包含0.23.x和2.x两大版本,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN(Yet Another Resource Negotiator)两个系统。
- 第三代Hadoop 3.0对Hadoop的管理脚本进行了重构,修复了大量bug,增加了新特性,支持动态命令等。 使用方式上则和之前版本的一致。3.x中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
- 官网地址
- 下载地址
- Hadoop3.x官方文档
2.3.2 Cloudera Hadoop
- 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
- 官网地址
- 下载地址
2.3.3 Hortonworks Hadoop
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- ortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的Microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
- 官网地址
- 下载地址
2.4 Hadoop生态体系
光靠Hadoop无法完成各种各样的大数据任务,除了Hadoop还有很多组件一起组成了Hadoop的生态系统。
经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包含了多个子项目。除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括Zookeeper、HBase、Hive、Pig、Mahout、Sqoop、Flume、Ambari等功能组件。
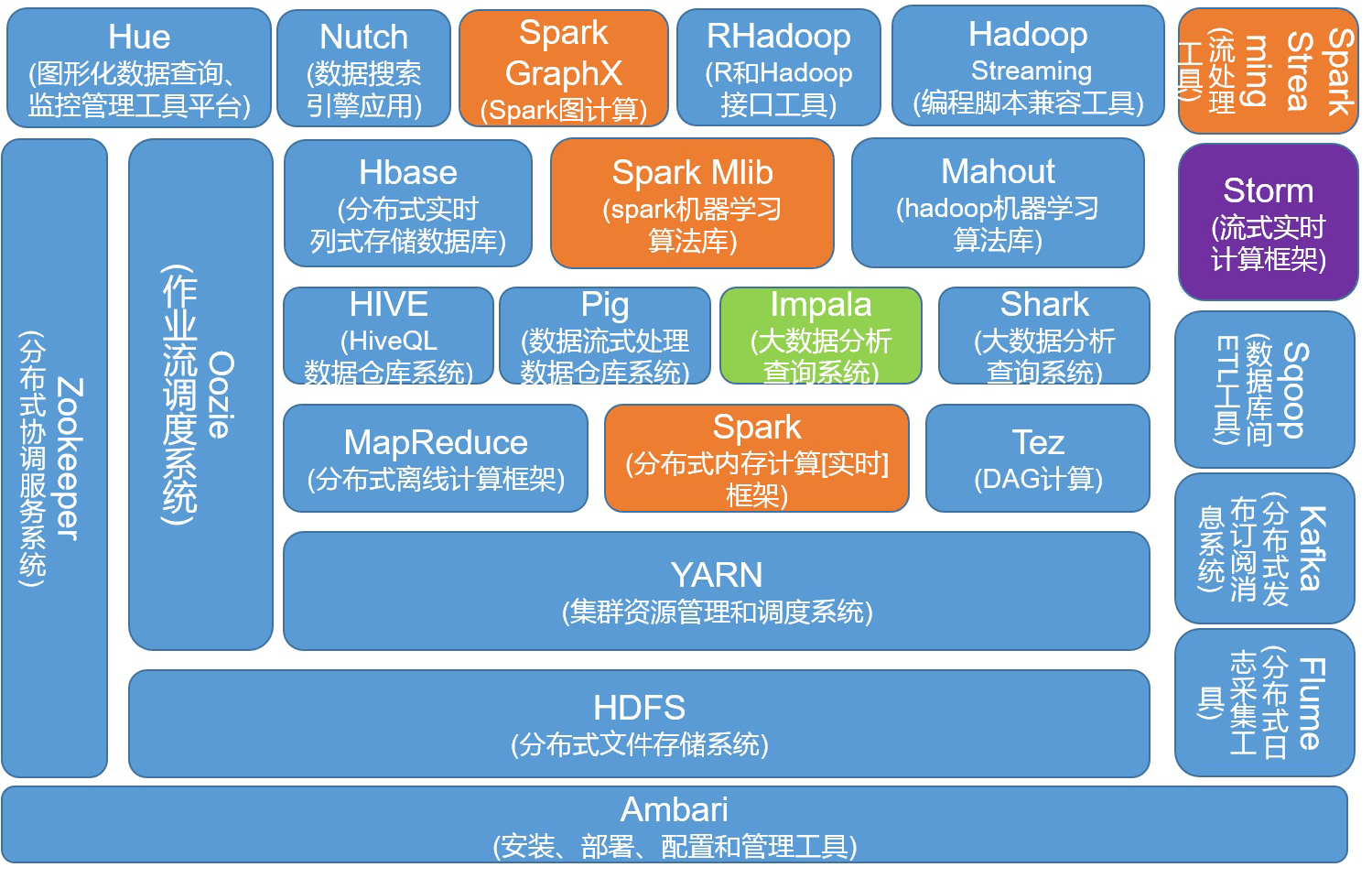
2.4.1 HDFS
Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop项目的两大核心之一,是针对谷歌文件系统(Google File System,GFS)的开源实现。HDFS具有处理超大数据、流式处理、可以运行在廉价商用服务器上等优点。
HDFS 在设计之初就是要运行在廉价的大型服务器集群上,因此在设计上就把硬件故障作为一种常态来考虑,可以保证在部分硬件发生故
2.4.2 HBase
HBase是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,一般采用HDFS作为其底层数据存储。HBase是针对谷歌BigTable的开源实现,二者都采用了相同的数据模型,具有强大的非结构化数据存储能力。HBase与传统关系数据库的一个重要区别是,前者采用基于列的存储,而后者采用基于行的存储。HBase具有良好的横向扩展能力,可以通过不断增加廉价的商用服务器来增加存储能力。
2.4.3 MapReduce
Hadoop MapReduce是针对谷歌MapReduce的开源实现。MapReduce是一种编程模型,用于大规模数据集(大于1 TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数——Map 和 Reduce 上,并且允许用户在不了解分布式系统底层细节的情况下开发并行应用程序,并将其运行于廉价计算机集群上,完成海量数据的处理。通俗地说,MapReduce 的核心思想就是“分而治之”,它把输入的数据集切分为若干独立的数据块,分发给一个主节点管理下的各个分节点来共同并行完成;最后,通过整合各个节点的中间结果得到最终结果。
2.4.4 Hive
Hive是一个基于Hadoop的数据仓库工具,可以用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储。Hive 的学习门槛较低,因为它提供了类似于关系数据库 SQL 语言的查询语言——Hive QL,可以通过Hive QL语句快速实现简单的MapReduce统计,Hive自身可以将Hive QL语句转换为MapReduce任务进行运行,而不必开发专门的MapReduce应用,因而十分适合数据仓库的统计分析。
2.4.5 Pig
Pig是一种数据流语言和运行环境,适合于使用Hadoop和MapReduce平台来查询大型半结构化数据集。虽然MapReduce应用程序的编写不是十分复杂,但毕竟也是需要一定的开发经验的。Pig的出现大大简化了Hadoop常见的工作任务,它在MapReduce的基础上创建了更简单的过程语言抽象,为Hadoop应用程序提供了一种更加接近结构化查询语言(SQL)的接口。Pig是一个相对简单的语言,它可以执行语句,因此当我们需要从大型数据集中搜索满足某个给定搜索条件的记录时,采用 Pig要比 MapReduce具有明显的优势,前者只需要编写一个简单的脚本在集群中自动并行处理与分发,而后者则需要编写一个单独的MapReduce应用程序。
2.4.6 Mahout
Mahout是Apache软件基金会旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
2.4.7 Zookeeper
Zookeeper是针对谷歌Chubby的一个开源实现,是高效和可靠的协同工作系统,提供分布式锁之类的基本服务(如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等),用于构建分布式应用,减轻分布式应用程序所承担的协调任务。Zookeeper使用Java编写,很容易编程接入,它使用了一个和文件树结构相似的数据模型,可以使用Java或者C来进行编程接入。
2.4.8 Flume
Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统。Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理并写到各种数据接受方的能力。
2.4.9 Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。通过Sqoop可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(可以导入HDFS、HBase或Hive),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。Sqoop主要通过JDBC(Java DataBase Connectivity)和关系数据库进行交互,理论上,支持JDBC的关系数据库都可以使Sqoop和Hadoop进行数据交互。Sqoop 是专门为大数据集设计的,支持增量更新,可以将新记录添加到最近一次导出的数据源上,或者指定上次修改的时间戳。
2.4.10 Ambari
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的安装、部署、配置和管理。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、HBase、Zookeeper、Sqoop等。
3 Apache Hadoop版本介绍
3.1 Hadoop1.X
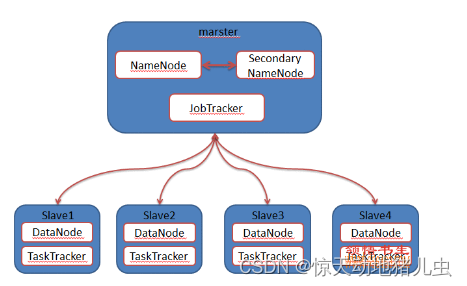
对于Hadoop1.X版本, HDFS的架构是基于一组特定的节点构建(如下图)。这些节点包括 NameNode(仅一个),它在HDFS内部提供元数据服务;DataNode(若干),它为HDFS提供存储块。由于仅存在一个 NameNode,因此这是HDFS的一个缺点(单点故障)。
3.1.1 容错机制
- 将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
- 运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
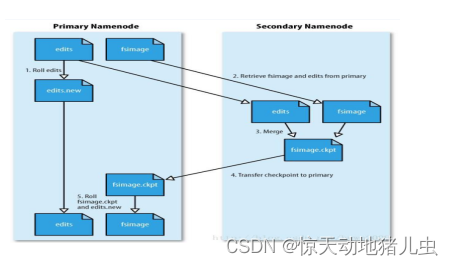
3.1.2 Hadoop1.x时代的HDFS架构
在Hadoop1.x中的NameNode只可能有一个,虽然可以通过SecondaryNameNode与NameNode进行数据同步备份,但是总会存在一定的时延,如果NameNode挂掉,但是如果有部份数据还没有同步到SecondaryNameNode上,还是可能会存在着数据丢失的问题。该架构如图1所示:
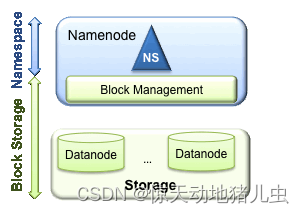
该架构包含两层:Namespace 和 Block Storage Service
- Namespace 层面包含目录、文件以及块的信息,支持对Namespace相关文件系统的操作,如增加、删除、修改以及文件和目录的展示;
- 而Block Storage Service层面又包含两个部分:
- Block Management(块管理)维护集群中DataNode的基本关系,它支持数据块相关的操作,如:创建数据块,删除数据块等,同时,它也会管理副本的复制和存放。
- Physical Storage(物理存储)存储实际的数据块并提供针对数据块的读写服务。;
当前HDFS架构只允许整个集群中存在一个Namespace,而该Namespace被仅有的一个NameNode管理。这个架构使得HDFS非常容易实现,但是,它(见上图)在具体实现过程中会出现一些模糊点,进而导致了很多局限性(下面将要详细说明),当然这些局限性只有在拥有大集群的公司,像baidu,腾讯等出现。
3.1.3 Hadoop1.x的HDFS架构的局限
-
Block Storage和namespace高耦合
当前namenode中的namespace和block management的结合使得这两层架构耦合在一起,难以让其他可能namenode实现方案直接使用block storage。 -
NameNode扩展性
HDFS的底层存储是可以水平扩展的(解释:底层存储指的是datanode,当集群存储空间不够时,可简单的添加机器已进行水平扩展),但namespace不可以。当前的namespace只能存放在单个namenode上,而namenode在内存中存储了整个分布式文件系统中的元数据信息,这限制了集群中数据块,文件和目录的数目。 -
NameNode性能
文件操作的性能制约于单个Namenode的吞吐量,单个Namenode当前仅支持约60K的task,而下一代Apache MapReduce将支持多余100K的并发任务,这隐含着要支持多个Namenode。 -
隔离性
现在大部分公司的集群都是共享的,每天有来自不同group的不同用户提交作业。单个namenode难以提供隔离性,即:某个用户提交的负载很大的job会减慢其他用户的job,单一的namenode难以像HBase按照应用类别将不同作业分派到不同namenode上。
3.1.4 NameNode HA(高可用)
在Hadoop1.x,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。
主要在两方面影响了HDFS的可用性:
- 在不可预测的情况下,如果NN所在的机器崩溃了,整个集群将无法利用,直到NN被重新启动;
- 在可预知的情况下,比如NN所在的机器硬件或者软件需要升级,将导致集群宕机。
3.1.5 Hadoop1.x时代的MapReduce
在Hadoop1.x时代,Hadoop中的MapReduce实现是做了很多的事情,而该框架的核心Job Tracker则是既当爹又当妈的意思,如图4所示:
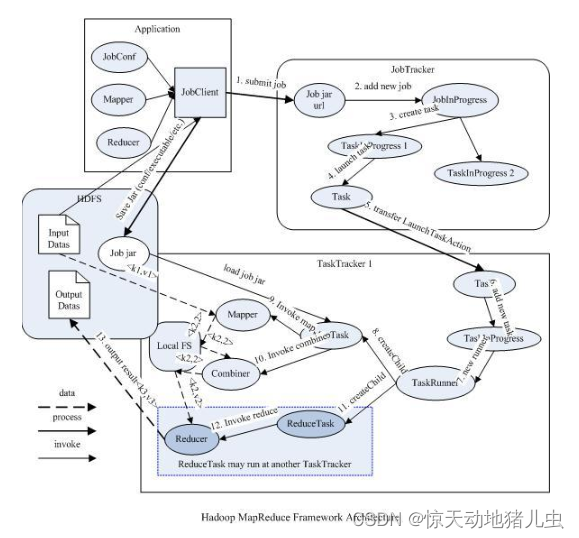
- 首先用户程序(JobClient)提交了一个job,job的信息会发送到Job Tracker中,Job Tracker是Map-reduce框架的中心,他需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有job失败、重启等操作。
- TaskTracker是Map-reduce集群中每台机器都有的一个部分,他做的事情主要是监视自己所在机器的资源情况。
- TaskTracker同时监视当前机器的tasks运行状况。TaskTracker需要把这些信息通过heartbeat发送给JobTracker,JobTracker会搜集这些信息以给新提交的job分配运行在哪些机器上。
Hadoop1.x的MapReduce框架的主要局限:
- JobTracker 是 Map-reduce 的集中处理点,存在单点故障;
- JobTracker 完成了太多的任务,造成了过多的资源消耗,当map-reduce job非常多的时候,会造成很大的内存开销,潜在来说,也增加了JobTracker失效的风险,这也是业界普遍总结出老Hadoop的Map-Reduce只能支持4000节点主机的上限;
3.2.Hadoop2.X
3.2.1 Hadoop2.x的HDFS Federation
在Hadoop2.x中,HDFS的变化主要体现在增强了NameNode的水平扩展(Horizontal Scalability)及高可用性(HA),可以同时部署多个NameNode,这些NameNode之间是相互独立,也就是说他们不需要相互协调,DataNode同时在所有NameNode中注册,作为他们共有的存储节点,并定时向所有的这些NameNode发送心跳块使用情况的报告,并处理所有NameNode向其发送的指令。该架构如图2所示:
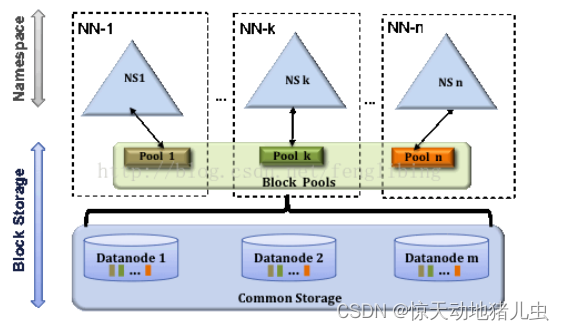
该架构引入了两个新的概念:存储块池(Block Pool) 和 集群ID(ClusterID);
-
一个Bock Pool是块的集合,这些块属于一个单一的Namespace。DataNode存储着集群中所有Block Pool中的块。Block Pool的管理相互之间是独立的。这意味着一个Namespace可以独立的生成块ID,不需要与其他Namespace协调。一个NameNode失败不会导致Datanode的失败,这些Datanode还可以服务其他的Namenode。一个Namespace和它的Block Pool一起称作命名空间向量(Namespace Volume)。这是一个自包含单元。当一个NameNode/Namespace删除后,对应的Block Pool也会被删除。当集群升级时,每个Namespace Volume也会升级。
-
集群ID(ClusterID)的加入,是用于确认集群中所有的节点,也可以在格式化其它Namenode时指定集群ID,并使其加入到某个集群中。
3.2.2 HDFS Federation与老HDFS架构的比较
- 老HDFS架构只有一个命名空间(Namespace),它使用全部的块。而HDFS Federation 中有多个独立的命名空间(Namespace),并且每一个命名空间使用一个块池(block pool)。
- 老HDFS架构中只有一组块。而HDFS Federation 中有多组独立的块。块池(block pool)就是属于同一个命名空间的一组块。
- 老HDFS架构由一个Namenode和一组datanode组成。而HDFS Federation 由多个Namenode和一组Datanode,每一个Datanode会为多个块池(block pool)存储块。
3.2.3 NameNode的HA(高可用)
HDFS的高可用性将通过在同一个集群中运行两个NN(active NN & standby NN)来解决上面两个问题,这种方案允许在机器破溃或者机器维护快速地启用一个新的NN来恢复故障。
在典型的HA集群(即一主一备模式)中,有两台不同的机器充当NN。在任何时间,只有一台机器处于Active状态;另一台机器是处于Standby状态。Active NN负责集群中所有客户端的操作;而Standby NN主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
为了让Standby NN的状态和Active NN保持同步,即元数据保持一致,它们都将会和JournalNodes守护进程通信。当Active NN执行任何有关命名空间的修改,它需要持久化到一半以上的JournalNodes上(通过edits log持久化存储),而Standby NN负责观察edits log的变化,它能够读取从JNs中读取edits信息,并更新其内部的命名空间。一旦Active NN出现故障,Standby NN将会保证从JNs中读出了全部的Edits,然后切换成Active状态。Standby NN读取全部的edits可确保发生故障转移之前,是和Active NN拥有完全同步的命名空间状态,使用Zookeeper来进行心跳监测监控,在Active NN失效时自动切换Standby NN为Active状态。
为了提供快速的故障恢复,Standby NN也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的Database将配置好Active NN和Standby NN的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
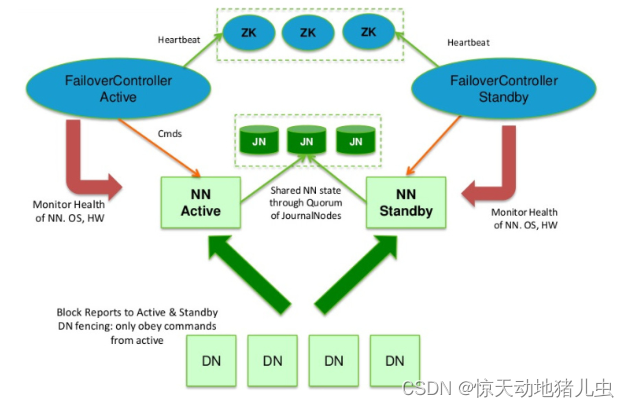
在任何时候,集群中只有一个NN处于Active 状态是极其重要的。否则,在两个Active NN的状态下NameSpace状态将会出现分歧,这将会导致数据的丢失及其它不正确的结果。为了保证这种情况不会发生,在任何时间,JNs只允许一个NN充当writer。在故障恢复期间,将要变成Active 状态的NN将取得writer的角色,并阻止另外一个NN继续处于Active状态,这应该也是由Zookeeper保证的。
为了部署HA集群,你需要准备以下事项:
- NameNode machines:运行Active NN和Standby NN的机器需要相同的硬件配置;
- JournalNode machines:也就是运行JN的机器。JN守护进程相对来说比较轻量,所以这些守护进程可以和其他守护线程(比如NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行3个JN守护进程,这将使得系统有一定的容错能力。当然,你也可以运行3个以上的JN,但是为了增加系统的容错能力,你应该运行奇数个JN(3、5、7等),当运行N个JN,系统将最多容忍(N-1)/2个JN崩溃。
在HA集群中,Standby NN也执行namespace状态的checkpoints,所以不必要运行Secondary NN、CheckpointNode和BackupNode;事实上,运行这些守护进程是错误的。
3.2.4 Hadoop2中新方案YARN+MapReduce
首先的不要被YARN给迷惑住了,它只是负责资源调度管理。而MapReduce才是负责运算的家伙,所以YARN != MapReduce2.
YARN 并不是下一代MapReduce(MRv2),下一代MapReduce与第一代MapReduce(MRv1)在编程接口、数据处理引擎(MapTask和ReduceTask)是完全一样的, 可认为MRv2重用了MRv1的这些模块,不同的是资源管理和作业管理系统,MRv1中资源管理和作业管理均是由JobTracker实现的,集两个功能于一身,而在MRv2中,将这两部分分开了。 其中,作业管理由ApplicationMaster实现,而资源管理由新增系统YARN完成,由于YARN具有通用性,因此YARN也可以作为其他计算框架的资源管理系统,不仅限于MapReduce,也是其他计算框架(例如Spark)的管理平台。
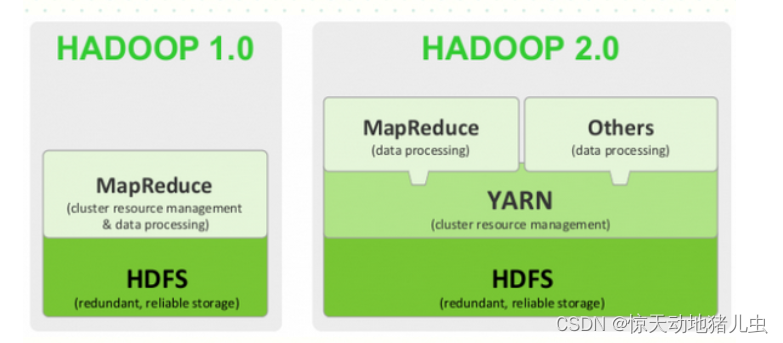
从上图中也可以看出,Hadoop1时代中MapReduce可以说是啥事都干,而Hadoop2中的MapReduce的话则是专门处理数据分析,而YARN则做为资源管理器而存在。
该架构将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的服务,用于管理全部资源的ResourceManager以及管理每个应用的ApplicationMaster,ResourceManager用于管理向应用程序分配计算资源,每个ApplicationMaster用于管理应用程序、调度以及协调。一个应用程序可以是经典的MapReduce架构中的一个单独的Job任务,也可以是这些任务的一个DAG(有向无环图)任务。ResourceManager及每台机上的NodeManager服务,用于管理那台主机的用户进程,形成计算架构。每个应用程序的ApplicationMaster实际上是一个框架具体库,并负责从ResourceManager中协调资源及与NodeManager(s)协作执行并监控任务。如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OOwErOLy-1669204517835)(https://note.youdao.com/yws/res/40106/WEBRESOURCE50acb0847c8a6ac2c80a7c923e1d1264)]](https://img-blog.csdnimg.cn/037a372cc6444f719fd6266b8bbcce8a.png)
- ResourceManager包含两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager)。
- 定时调度器(Scheduler):定时调度器负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且它不保证会重启由于应用程序本身或硬件出错而执行失败的应用程序。
- 应用管理器(ApplicationManager):应用程序管理器负责接收新任务,协调并提供在ApplicationMaster容器失败时的重启功能。
- ApplicationMaster:每个应用程序的ApplicationMaster负责从Scheduler申请资源,以及跟踪这些资源的使用情况以及任务进度的监控。
- NodeManager:NodeManager是ResourceManager在每台机器的上代理,负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),以及向 ResourceManager/Scheduler提供这些资源使用报告。
- Container:对一个节点的内存、CPU等资源的描述的整体描述。
YARN相对于MapReduce v1的优势:
- JobTracker所承担的庞大负担被分割,资源管理和任务调度分配在不同的节点,并且实现程序的分布化、最优化
- ResourceManager资源分配不再凭借slot的个数,而是根据节点的内存是分配任务,使得负载均衡更在完善
- ResourceManager节点上有一个ApplicationMasters进程,负责管理每个ApplicationMatser进程的状态,从而实现监督任务。
4 Hadoop集群安全策略
从Hadoop1.0.0版本后,引入了安全机制和授权机制(Simple和Kerberos)。下面从用户权限管理,HDFS安全策略和MapReduce安全策略三个方面简要介绍Hadoop的集群安全策略。
4.1 用户权限管理
Hadoop上的用户权限管理主要涉及用户分组管理,为更高层的HDFS访问,服务访问,Job提交和配置Job等操作提供认证和控制基础
Hadoop上的用户和用户组名均由用户自己指定,如果用户没有指定,那么Hadoop会调用Linux的whoami命令获取当前Linux系统的用户名和用户组名作为当前用户的对应名,并将其保存在Job的user.name和group.name两个属性中。这样用户所提交Job的后续认证和授权以及集群服务的方位都讲基于此用户和用户组的权限及认证信息进行。
4.2 HDFS安全策略
用户和HDFS服务之间的交互主要有两种情况:用户机和NameNode之间的RPC交互获取待通信的DataNode位置,客户机和DataNode交互传输数据块。
RPC交互可以通过Kerberos或授权令牌来认证。在认证和NameNode的连接时,用户需要使用Kerberos证书来通过初试认证,获取授权令牌。
授权令牌可以在后续用户Job与NameNode连接的认证中使用,而不必再次方位Kerberos Key Server。
数据块的传输可以通过块访问令牌来认证,每一个块访问令牌都由NameNode生成,它们都是特定的。块访问令牌代表数据访问容量,一个块访问令牌保证用户可以访问指定的数据库。
块访问令牌由NameNode签发被用在DataNode上,其传输过程就是将NameNode上的认证信息传输到DataNode上。块访问令牌是基于对称加密模式生成的,NameNode和DataNode共享了密钥。
对于每个令牌,NameNode基于共享密钥计算一个消息认证码,接下来,这个消息认证码就会作为令牌验证器成为令牌的主要组成部分。当一个DataNode接收到一个令牌时,它会使用自己的共享密钥重新计算一个消息认证码,如果这个认证码同令牌中的认证码匹配,那么认证成功。
4.3.MapReduce安全策略
MapReduce安全策略主要涉及Job提交,Task和Shuffle三个方面。
对于Job提交,用户需要将Job配置,输入文件和输入文件的元数据等写入用户home文件夹下,这个文件夹只能由该用户读,写和执行。接下来用户将home文件夹位置和认证信息发送给JobTracker。
在执行过程中,Job可能需要访问多个HDFS节点或其他服务,因此,Job的安全凭证将以<String key,binary value>形式保存在一个Map数据结构中,在物理存储介质上将保存在HDFS中JobTracker的系统目录下,并分发给每个TaskTracker。
Job的授权令牌将NameNode的URL作为其关键信息,为了防止授权令牌过期,JobTracker会定期更新授权令牌。Job结束之后所有的令牌都会失效,为了获取保持在HDFS上的配置细腻,JobTracker需要使用用户的授权令牌访问HDFS,读取必须的配置信息。