目录:权重衰减
- 一、理论知识
- 二、高维线性回归的实现步骤
- 2.1 准备数据
- 2.2 初始化模型参数
- 2.3 定义 L 2 L_2 L2范数惩罚
- 2.4 定义训练代码实现
- 2.5 是否加入正则化
- 2.5.1 忽略正则化
- 2.5.2 加入正则化
- 三、简单实现
- 四、源代码
一、理论知识
前面我们已经介绍学习了过拟合的问题,这次我们来讲讲一个正则化模型的技术。
我们总是可以通过去收集更多的训练数据来缓解过拟合,但这可能成本很高,耗时颇多,或者完全超出我们的控制,因而在短期内不可能做到。
假设我们已经拥有了尽可能多的高质量的数据,我们便可以把重心放在正则化技术上。
在多项式回归的例子中,我们可以通过调整拟合多项式的阶数来限制模型的容量。
实际上,限制特征的数量是缓解过拟合的一种常用技术。然而,简单的丢弃特征对于这项工作来说可能过于生硬。我们继续思考多项式回归的例子,考虑高维输入可能发生的情况。 多项式对多变量数据的自然扩展称为单项式(monomials), 也可以说是变量幂的乘积。 单项式的阶数是幂的和。例如, x 1 2 x 2 x_1^2x_2 x12x2和 x 3 x 5 2 x_3x_5^2 x3x52都是三次多项式。
注意,随着结束 d d d的增长,带有结束 d d d的项数迅速增加。给定 k k k个变量,阶数为 d d d的项的个数为 ( k − 1 + d k − 1 ) \binom{k-1+d}{k-1} (k−1k−1+d),即 C k − 1 + d k − 1 = ( k − 1 + d ) ! d ! ( k − 1 ) ! {C_{k-1+d}^{k-1}} =\frac{(k-1+d)!}{d!(k-1)!} Ck−1+dk−1=d!(k−1)!(k−1+d)!。因此,即便是阶数上的微小变化,比如从2到3,也会显著增加我们模型的复杂性。
在之前的学习中,我们已经接触了 L 2 L_2 L2范数和 L 1 L_1 L1范数,它们是更为一般的 L p L_p Lp范数的特殊情况。
在训练参数化机器学习模型时, 权重衰减(weight decay)是最广泛使用的正则化的技术之一, 它通常也被称为 L 2 L_2 L2正则化。 这项技术通过函数与零的距离来衡量函数的复杂度, 因为在所有函数 f f f中,函数 f = 0 f=0 f=0(所有输入都得到值0)在某种意义上是最简单的。 但是我们应该如何精确地测量一个函数和零之间的距离呢? 没有一个正确的答案。 事实上,函数分析和巴拿赫空间理论的研究,都在致力于回答这个问题。
一种简单的方法是通过线性函数
f
(
X
)
=
w
T
X
f(\textbf{X})=\textbf{w}^T\textbf{X}
f(X)=wTX中的权重向量的某个范数来度量其复杂性, 例如
∣
∣
w
∣
∣
2
||\textbf{w}||^2
∣∣w∣∣2。 要保证权重向量比较小, 最常用方法是将其范数作为惩罚项加到最小化损失的问题中。 将原来的训练目标最小化训练标签上的预测损失, 调整为最小化预测损失和惩罚项之和。 现在,如果我们的权重向量增长的太大, 我们的学习算法可能会更集中于最小化权重范数
∣
∣
w
∣
∣
2
||\textbf{w}||^2
∣∣w∣∣2。这正是我们想要的。我们的损失由下式给出:
L
(
w
,
b
)
=
1
n
∑
i
=
1
n
1
2
(
w
T
x
(
i
)
+
b
−
y
(
i
)
)
L(\textbf{w},b)=\frac{1}{n}\sum_{i=1}^{n}\frac{1}{2}(\textbf{w}^T\textbf{x}^{(i)}+b-y^{(i)} )
L(w,b)=n1i=1∑n21(wTx(i)+b−y(i))
回想一下,
x
(
i
)
\textbf{x}^{(i)}
x(i)是样本
i
i
i的特征,
y
(
i
)
y^{(i)}
y(i)是样本
i
i
i的标签,
(
w
,
b
)
(\textbf{w},b)
(w,b)是权重和偏置参数。 为了惩罚权重向量的大小, 我们必须以某种方式在损失函数中添加
∣
∣
w
∣
∣
2
||\textbf{w}||^2
∣∣w∣∣2, 但是模型应该如何平衡这个新的额外惩罚的损失? 实际上,我们通过正则化常数
λ
\lambda
λ来描述这种权衡, 这是一个非负超参数,我们使用验证数据拟合:
L
(
w
,
b
)
+
λ
2
∣
∣
w
∣
∣
2
L(\textbf{w},b)+\frac{\lambda }{2}||\textbf{w}||^2
L(w,b)+2λ∣∣w∣∣2
对于
λ
=
0
\lambda=0
λ=0,我们恢复了原来的损失函数。
对于 λ > 0 \lambda>0 λ>0,我们限制 ∣ ∣ w ∣ ∣ ||\textbf{w}|| ∣∣w∣∣的大小。
这里我们仍然除以2,当我们取一个二次函数的导数时,2和1/2会抵消掉。以确保更新表达式看起来既漂亮又简单。 你可能会想知道为什么我们使用平方范数而不是标准范数(即欧几里得距离)? 我们这样做是为了便于计算。 通过平方 L 2 L_2 L2范数,我们去掉平方根,留下权重向量每个分量的平方和。 这使得惩罚的导数很容易计算:导数的和等于和的导数。
L
2
L_2
L2正则化回归的小批量随机梯度下降更新如下式:
w
←
(
1
−
η
λ
)
w
−
η
∣
β
∣
∑
i
∈
β
x
(
i
)
(
w
T
x
(
i
)
+
b
−
y
(
i
)
)
\textbf{w}\leftarrow (1-\eta \lambda )\textbf{w}-\frac{\eta }{|\beta|}\sum_{i\in \beta}\textbf{x}^{(i)}(\textbf{w}^T\textbf{x}^{(i)}+b-y^{(i)})
w←(1−ηλ)w−∣β∣ηi∈β∑x(i)(wTx(i)+b−y(i))
根据之前章节所讲的,我们根据估计值与观测值之间的差异来更新
w
\textbf{w}
w。 然而,我们同时也在试图将
w
\textbf{w}
w的大小缩小到零。 这就是为什么这种方法有时被称为权重衰减。 我们仅考虑惩罚项,优化算法在训练的每一步衰减权重。 与特征选择相比,权重衰减为我们提供了一种连续的机制来调整函数的复杂度。 较小的
λ
\lambda
λ值对应较少约束的
w
\textbf{w}
w, 而较大的
λ
\lambda
λ值对
w
\textbf{w}
w的约束更大。
是否对相应的偏置 b b b进行惩罚在不同的实践中会有所不同, 在神经网络的不同层中也会有所不同。 通常,网络输出层的偏置项不会被正则化。
二、高维线性回归的实现步骤
我们通过一个简单的例子来演示权重衰减。
2.1 准备数据
import torch
from torch import nn
from d2l import torch as d2l
首先,我们像以前一样生成一些数据,生成公式如下:
y
=
0.05
+
∑
i
=
1
d
0.01
x
i
+
ϵ
w
h
e
r
e
ϵ
∈
N
(
0
,
0.0
1
2
)
y=0.05+\sum_{i=1}^{d}0.01x_i+\epsilon \quad where\quad \epsilon \in N(0,0.01^2)
y=0.05+i=1∑d0.01xi+ϵwhereϵ∈N(0,0.012)
我们选择标签是关于输入的线性函数。 标签同时被均值为0,标准差为0.01高斯噪声破坏。 为了使过拟合的效果更加明显,我们可以将问题的维数增加到
d
=
200
d=200
d=200, 并使用一个只包含20个样本的小训练集。
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False) # 这里的is_train是表示是否打乱
2.2 初始化模型参数
首先,我们将定义一个函数来随机初始化模型参数。
def init_params():
w = torch.normal(0, 1, size = (num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
2.3 定义 L 2 L_2 L2范数惩罚
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和。
def l2_penalty(w):
return torch.sum(w.pow(2) / 2)
2.4 定义训练代码实现
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估。 线性网络和平方损失没有变化, 所以我们通过d2l.linreg和d2l.squared_loss导入它们。 唯一的变化是损失现在包括了惩罚项。
def train(lambd):
w, b = init_params()
net, loss = lambda X : d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.01
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w))
d2l.plt.show()
2.5 是否加入正则化
2.5.1 忽略正则化
train(0)
输出结果为:
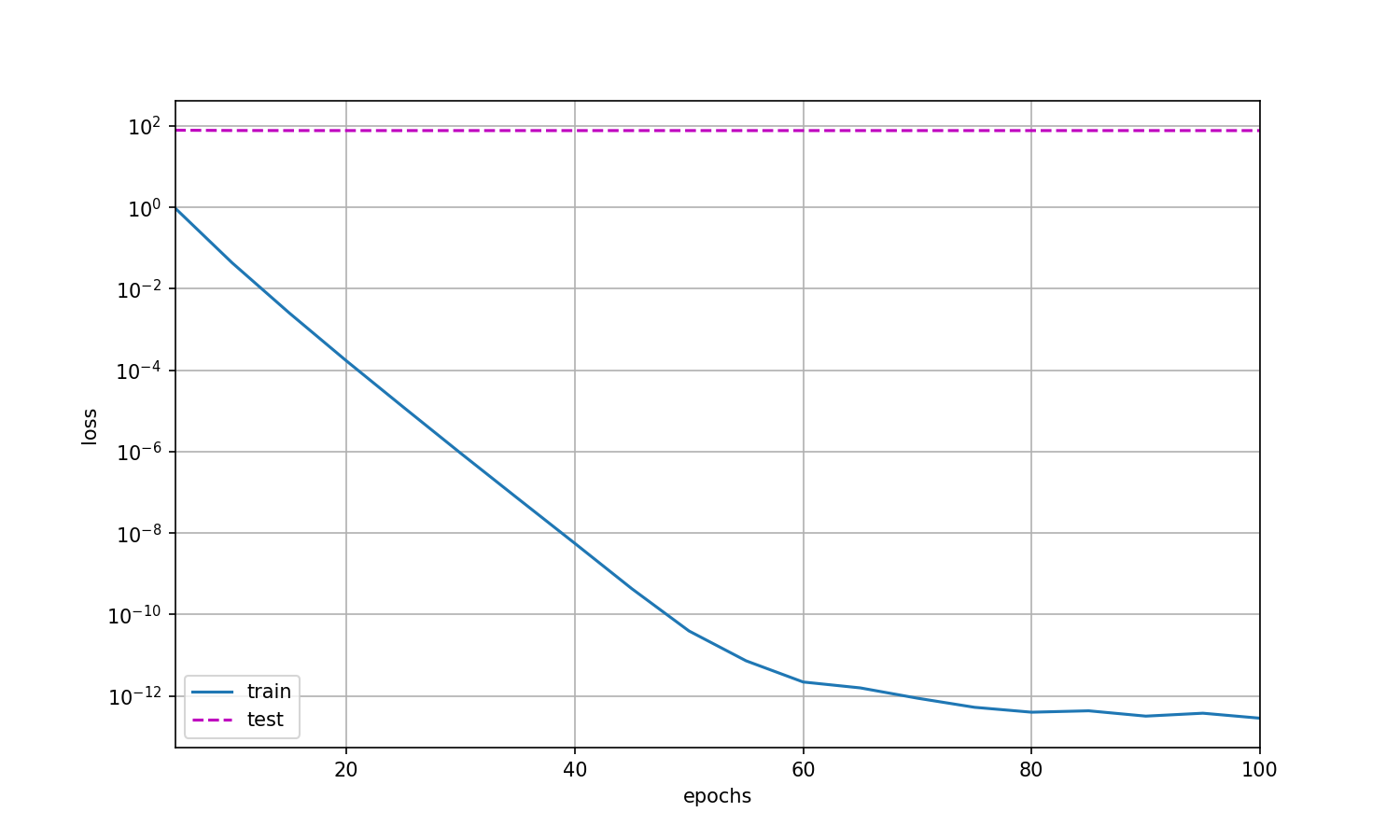
此时:
w的L2范数是: tensor(13.1169, grad_fn=<CopyBackwards>)
2.5.2 加入正则化
选择 λ = 1 \lambda = 1 λ=1
train(1)
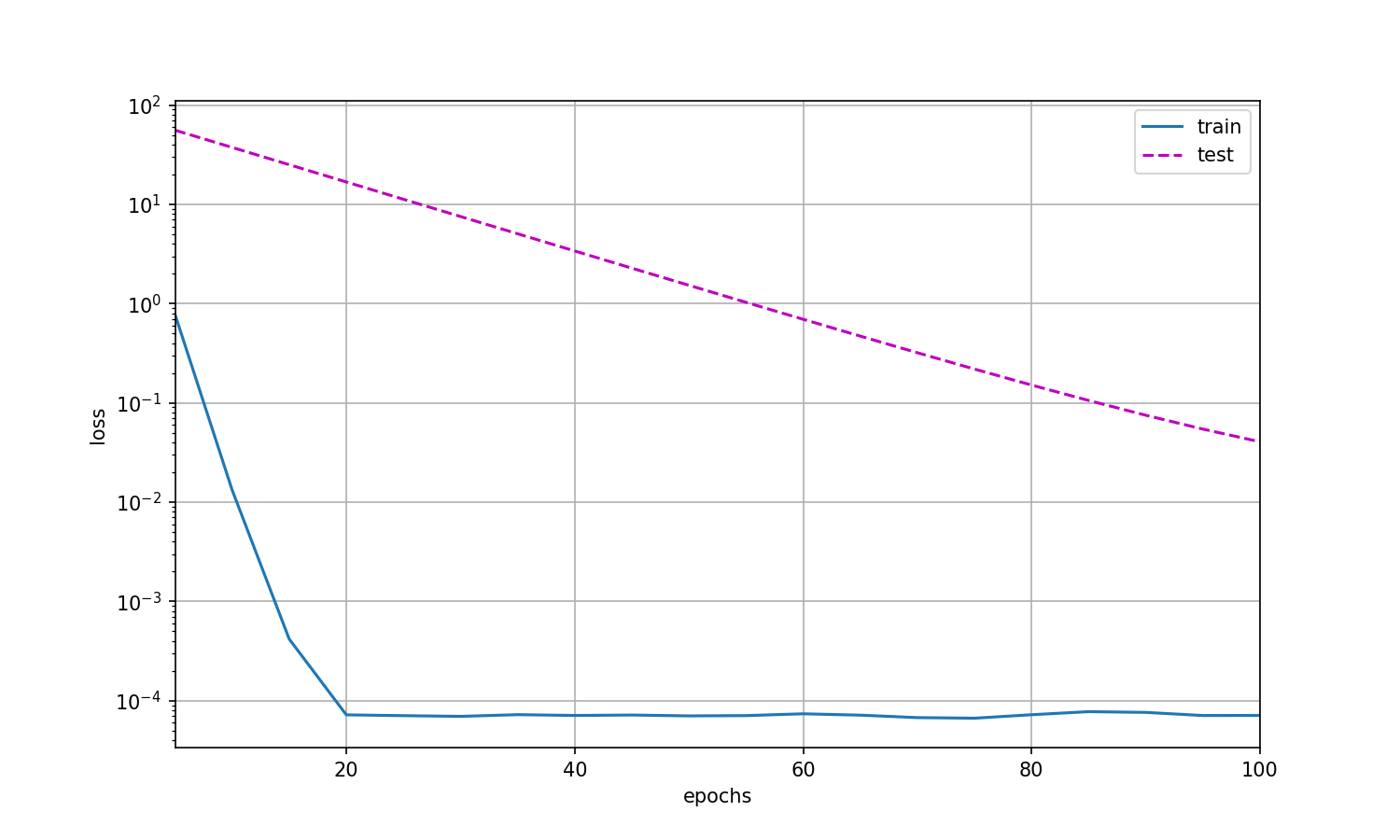
此时:
w的L2范数是: tensor(0.2394, grad_fn=<CopyBackwards>)
三、简单实现
由于权重衰减在神经网络优化中很常用, 深度学习框架为了便于我们使用权重衰减, 将权重衰减集成到优化算法中,以便与任何损失函数结合使用。 此外,这种集成还有计算上的好处, 允许在不增加任何额外的计算开销的情况下向算法中添加权重衰减。 由于更新的权重衰减部分仅依赖于每个参数的当前值, 因此优化器必须至少接触每个参数一次。
在下面的代码中,我们在实例化优化器时直接通过weight_decay指定weight decay超参数。 默认情况下,PyTorch同时衰减权重和偏移。 这里我们只为权重设置了weight_decay,所以偏置参数 b b b不会衰减。
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.01
trainer = torch.optim.SGD([
{"params":net[0].weight, 'weight_decay':wd},
{"params":net[0].bias}
], lr = lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:',net[0].weight.norm())
d2l.plt.show()
无正则化的时候:
train_concise(0)
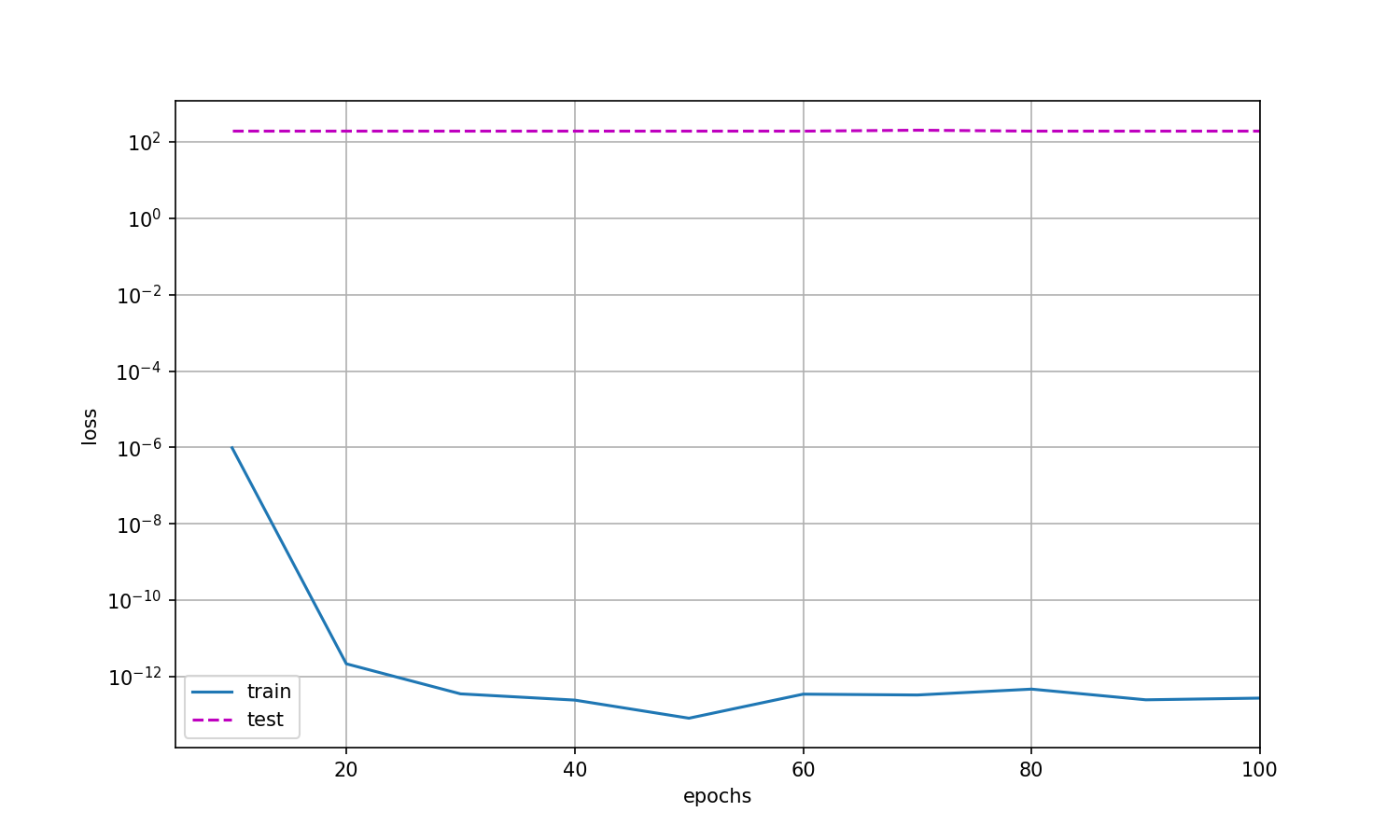
w的L2范数: tensor(13.3643, grad_fn=<CopyBackwards>)
加上正则化的时候:
train_concise(3)

w的L2范数: tensor(0.1036, grad_fn=<CopyBackwards>)
四、源代码
# 通过一个例子来演示权重衰减
import torch
from torch import nn
from d2l import torch as d2l
def init_params():
w = torch.normal(0, 1, size = (num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
def l2_penalty(w):
return torch.sum(w.pow(2) / 2)
def train(lambd):
w, b = init_params()
net, loss = lambda X : d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.01
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w))
d2l.plt.show()
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.01
trainer = torch.optim.SGD([
{"params":net[0].weight, 'weight_decay':wd},
{"params":net[0].bias}
], lr = lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:',net[0].weight.norm())
d2l.plt.show()
if __name__ == '__main__':
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False) # 这里的is_train是表示是否打乱
train_concise(3)
![[附源码]java毕业设计宿舍管理系统](https://img-blog.csdnimg.cn/6e4f7c7dc8c14d3eb20dc3f898a03a96.png)







![[附源码]java毕业设计研究生管理系统](https://img-blog.csdnimg.cn/83fd3b22199744d78eb2ddd5b51d3396.png)