正文
我遇到了这个项目,它的目标是成为一个比Redis有着更好性能和更易用的克隆版。我发现它很有趣,因为它主要的卖点之一就是它是在多线程模式下运行(而不是像Redis那样是单线程)。他们使用memtier_benchmark(Redis项目的一部分)来测试性能。所以我很好奇,如果我使用C#来构建自己的Redis克隆版,会有怎么样的性能?
我构建的第一个版本非常简单。我的想法是使用高抽象的API来编写它,看看它的性能到底怎么样。为了使事情变得有趣,下面是它的测试方案:
- 客户端:memtier_benchmark将在aws的c6g.2xlarge实例上运行,使用8核32G内存
- 服务端:测试的实例将在aws的c6g.4xlarge上运行,使用16核64G内存
客户端要运行的命令如下所示:
memtier_benchmark –s $SERVER_IP -t 8 -c 16 --test-time=30 --distinct-client-seed -d 256 --pipeline=30
上面的命令说明我们将使用8个线程(客户端实例上的CPU核心数),每个线程创建32个链接,20%的场景写入,80的场景读取,数据大小为256字节,将不断的把更多的数据推送到测试的实例中。
服务端使用以下命令运行:
dotnet run –c Release
以下是此测试在服务器的实例:

我选择30秒作为测试的持续时间,以收集更多的信息让我们感受正在发生的事情(比如GC周期),同时保持测试的持续时间足够短,这样我不会感觉到无聊。
以下是简单版本的测试结果:
因此,使用C#构建的简单版本,即使什么优化都不做,也有几乎100w/s的性能。从另外的角度来说,延时并不是那么的好。P99延时将近100ms。
现在我用数字和漂亮的图表引起了你的注意,让我向你展示我正在运行的实际代码。这是一个不到100行代码的“Redis克隆”。
using System.Collections.Concurrent;
using System.Net.Sockets;
var listener = new TcpListener(System.Net.IPAddress.Any, 6379);
listener.Start();
var redisClone = new RedisClone();
while (true)
{
var client = listener.AcceptTcpClient();
var _ = redisClone.HandleConnection(client); // run async
}
public class RedisClone
{
ConcurrentDictionary<string, string> _state = new();
public async Task HandleConnection(TcpClient client)
{
using var _ = client;
using var stream = client.GetStream();
using var reader = new StreamReader(stream);
using var writer = new StreamWriter(stream)
{
NewLine = "\r\n"
};
try
{
var args = new List<string>();
while (true)
{
args.Clear();
var line = await reader.ReadLineAsync();
if (line == null) break;
if (line[0] != '*')
throw new InvalidDataException("Cannot understand arg batch: " + line);
var argsv = int.Parse(line.Substring(1));
for (int i = 0; i < argsv; i++)
{
line = await reader.ReadLineAsync();
if (line == null || line[0] != '$')
throw new InvalidDataException("Cannot understand arg length: " + line);
var argLen = int.Parse(line.Substring(1));
line = await reader.ReadLineAsync();
if (line == null || line.Length != argLen)
throw new InvalidDataException("Wrong arg length expected " + argLen + " got: " + line);
args.Add(line);
}
var reply = ExecuteCommand(args);
if(reply == null)
{
await writer.WriteLineAsync("$-1");
}
else
{
await writer.WriteLineAsync($"${reply.Length}\r\n{reply}");
}
await writer.FlushAsync();
}
}
catch (Exception e)
{
try
{
string? line;
var errReader = new StringReader(e.ToString());
while ((line = errReader.ReadLine()) != null)
{
await writer.WriteAsync("-");
await writer.WriteLineAsync(line);
}
await writer.FlushAsync();
}
catch (Exception)
{
// nothing we can do
}
}
}
string? ExecuteCommand(List<string> args)
{
switch (args[0])
{
case "GET":
return _state.GetValueOrDefault(args[1]);
case "SET":
_state[args[1]] = args[2];
return null;
default:
throw new ArgumentOutOfRangeException("Unknown command: " + args[0]);
}
}
}
只是关于实现的几个注意事项。我实际上并没有做太多事情。大部分代码用于解析 Redis 协议。代码充满了内存分配。每个命令解析都是使用多个字符串拆分和连接来完成的。对客户端的回复需要更多的连接。系统的“存储”实际上只是一个简单的 ConcurrentDictionary,没有任何避免锁竞争或高成本的东西。
我们处理I/O的方式非常糟糕,而且......我想你明白我的想法,对吧?我的目标是看看如何使用这个(非常简单的)示例来获得更高的性能,而不必处理很多额外的细节。
鉴于我最初的尝试已经接近100万QPS,这是一个非常好的开始,即使我自己这么说。
我想采取的下一步是处理这里多余的内存分配。我们也许可以在内存分配这方面做得更好,虽然我的目标只是尝试。但我将在下一篇文章中这样做。
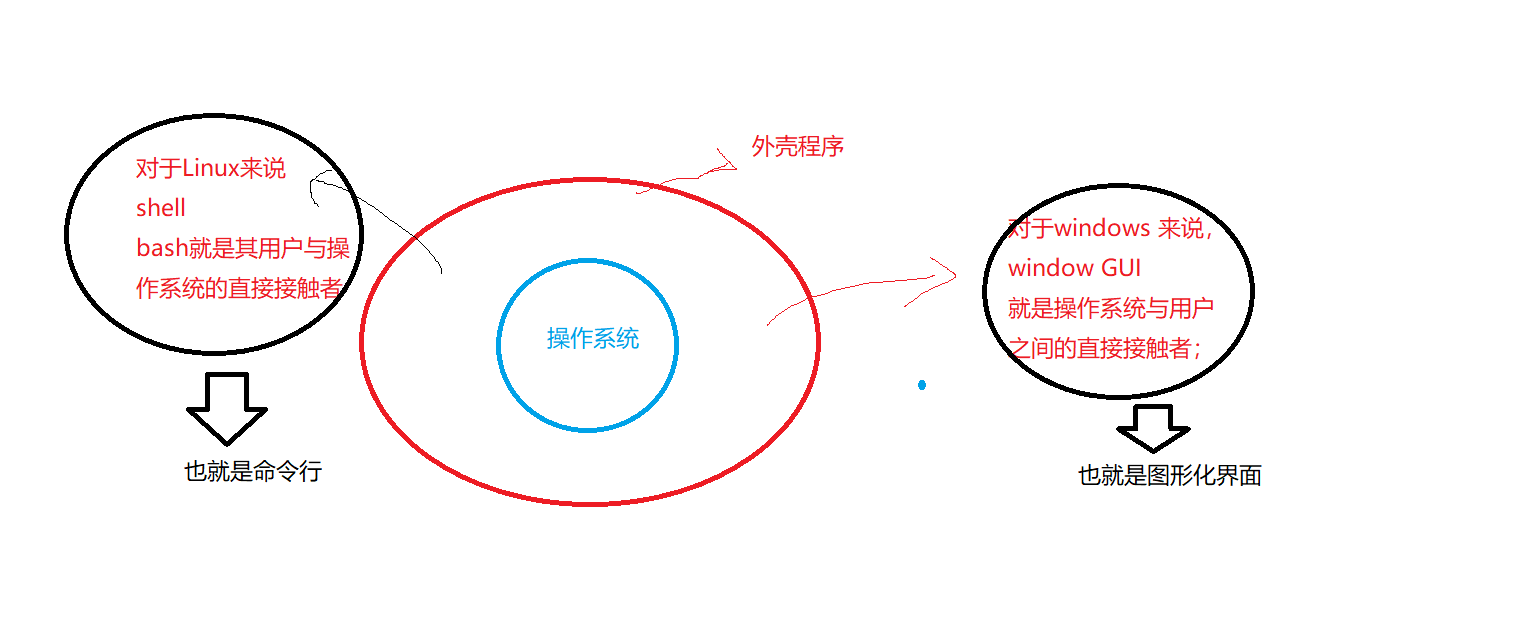

![[AI] LRTA*(K) 搜索算法](https://img-blog.csdnimg.cn/b945c2c962534daebdc25a9dc5103019.png#pic_center)