ChunJun(原FlinkX)是一个基于 Flink 提供易用、稳定、高效的批流统一的数据集成工具。2018年4月,秉承着开源共享的理念,数栈技术团队在github上开源了FlinkX,承蒙各位开发者的合作共建,FlinkX得到了快速发展。
两年后的2022年4月,技术团队决定对FlinkX进行整体升级,并更名为ChunJun,希望继续和各位优秀开发者合作,进一步推动数据集成/同步的技术发展。
因该文创作于于FlinkX更名为ChunJun之前,因此文中仍用FlinkX来进行分享,重要的事情说三遍:
FlinkX即是ChunJun
FlinkX即是ChunJun
FlinkX即是ChunJun
进入正文分享⬇️⬇️⬇️

分享嘉宾:冯江涛 中国移动云能力中心
编辑整理:陈凯翔 亚厦股份
出品平台:DataFunTalk
导读:
随着本地数据迁移上云、云上数据交换等多源异构数据源数据同步需求日益增多,传统通过编写脚本进行数据同步的方式投入高、效率低、运维管理困难;在公司内部,多款移动云数据库和大数据类产品根据客户需求迫切希望集成数据同步能力,但缺少易用的框架,从0开始研发投入研发成本高。
针对上述问题,基于FlinkX多源异构数据同步框架,实现了用户自建和移动云上消息中间件、数据库、对象存储等多种异构数据源双向读写,基于社区版实现了On k8s改造,需简单配置即可满足用户数据快速上云及云上数据高效交换需求,降低开发运维投入,该成果已在移动云至少3款产品中应用。
本文的主要内容包括:
FlinkX简介
功能及原理
云上入湖改造
展望
一、FlinkX简介
1. 背景介绍

现在市面上有很多种数据库产品,包括传统的RDB和大数据相关的NoSQL,一般企业稍微大一点规模都会同时有各种各样的数据库。为什么会有这么多数据源?是因为不同的数据源适应不同的场景,但这么多数据源会给开发带来困难。
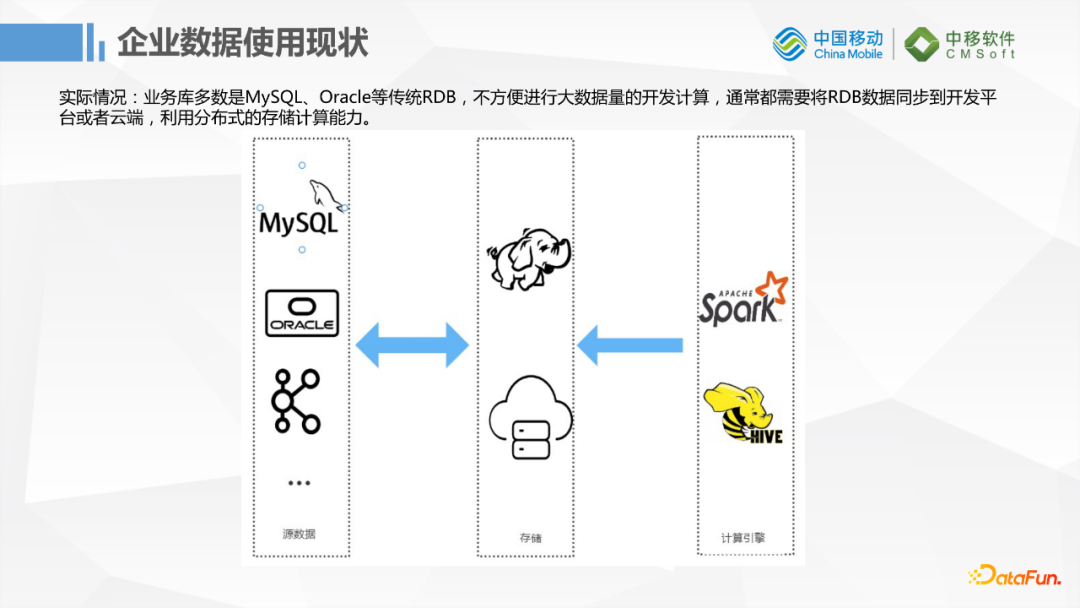
传统的企业业务库多数还是MySQL,Oracle这种传统RDB,如果进行简单的增删改查是没有问题的,但遇到大批量的数据计算这些RDB就无法支持了,所以就需要大数据的存储。但是业务数据又在传统数据库中,所以传统数据库和大数据之间需要一个同步迁移的工具。
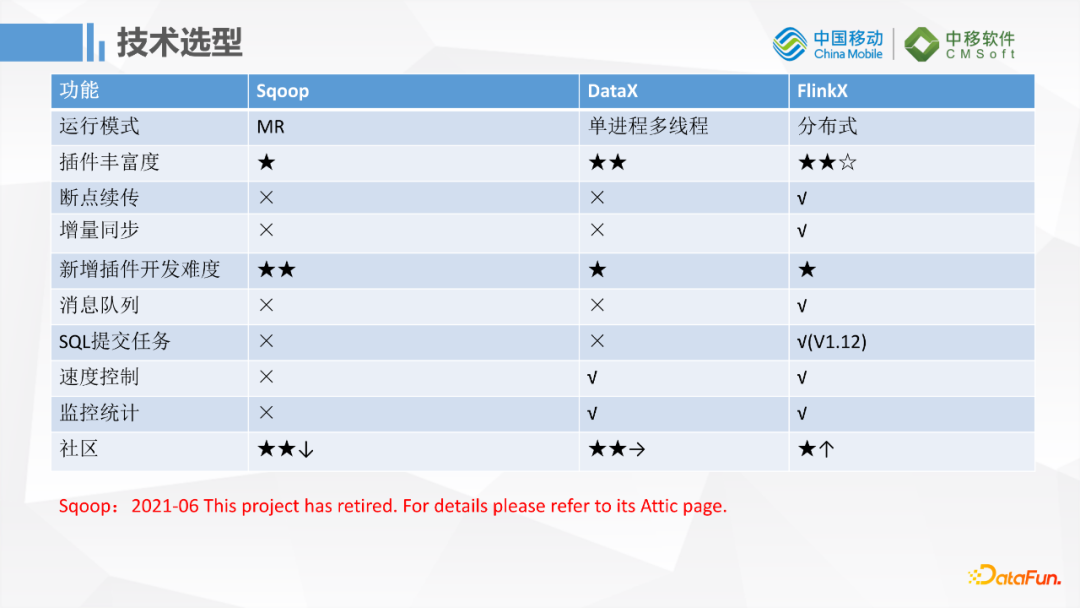
FlinkX这个工具相对比较小众,是袋鼠云开源的项目。更熟悉的工具可能是Sqoop和阿里开源的DataX,上图是一个简单的对比,我们开始选型的时候也做过调研,包括它的运行模式,插件丰富度,是否支持断点续传等功能,特别是我们是做数据湖的,需要对数据湖插件的支持,还有考虑新增插件开发的难度。综合调研下来,我们最终选择了FlinkX。多数传统的企业使用Sqoop比较多,因为他们只会在RDB和大数据之间做迁移,但是Sqoop已经在今年6月份被移除了Apache 顶级项目,上一次更新是在2019年1月份,已经2年多没有任何的开发更新了,所以这个项目已经没有新功能开发,这也不满足我们的需求。之前我们也在移动云上基于Sqoop做了一个插件,但是发现Sqoop在开发、运行上不太符合我们的场景。最终我们选定了FlinkX这个工具。
2. Flink简介
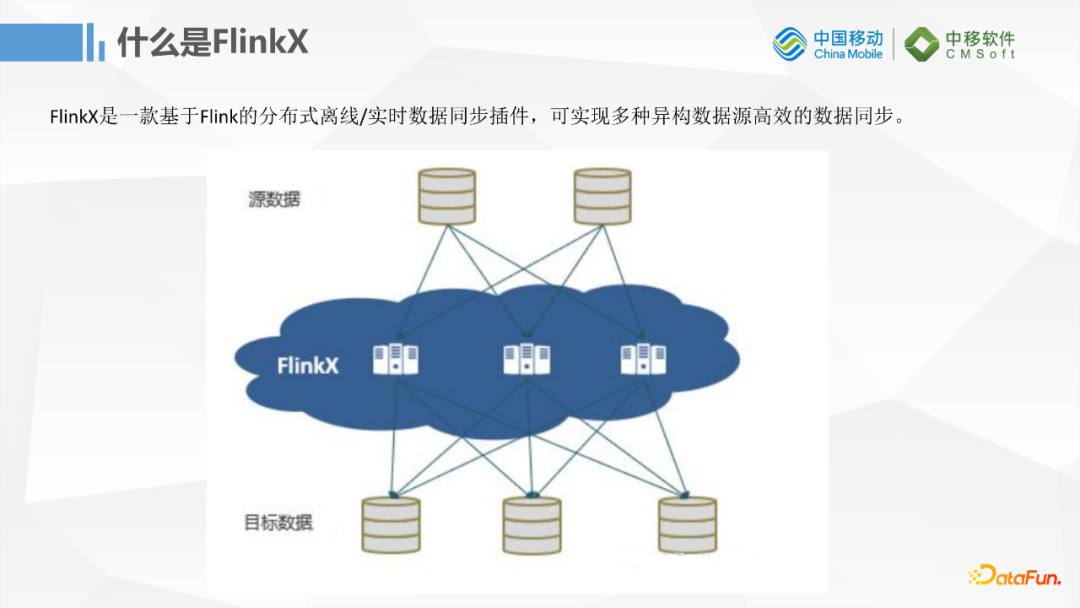
什么是FlinkX呢?FlinkX是一个基于Flink流计算框架实现的数据同步插件,它可以实现多种数据源高效的数据同步,基本功能和DataX和Sqoop差不多。
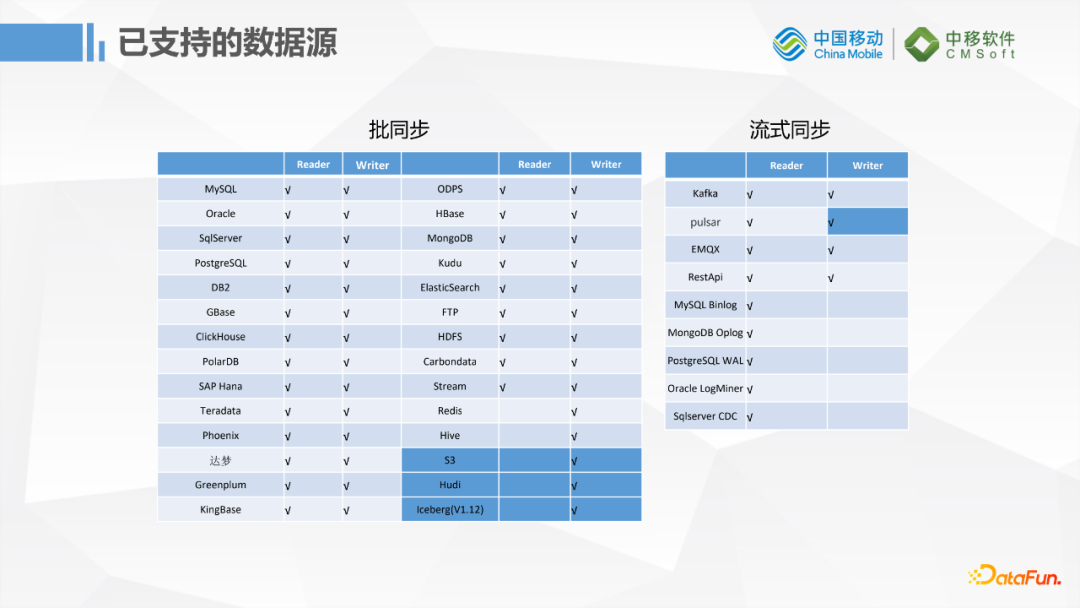
批同步方面支持的数据源跟DataX相当,但是在流式同步方面比较有优势,因为它是基于Flink开发的,所以在流式数据方面支持的数据源比较全,比如Kafka,Pulsar这种消息队列,还有数据库的Binlog这种增量更新的数据同步,功能非常强大。基于开源社区1.11版本我们自己又开发了一些插件:对S3的写入、Hudi数据湖的写入、对Pulsar的写入。Pulsar部门已经开源提交到社区了,S3和Hudi暂时还没有提交。
二、功能及原理
接下来看一下FlinkX的功能和简单的原理。
1. 断点续传
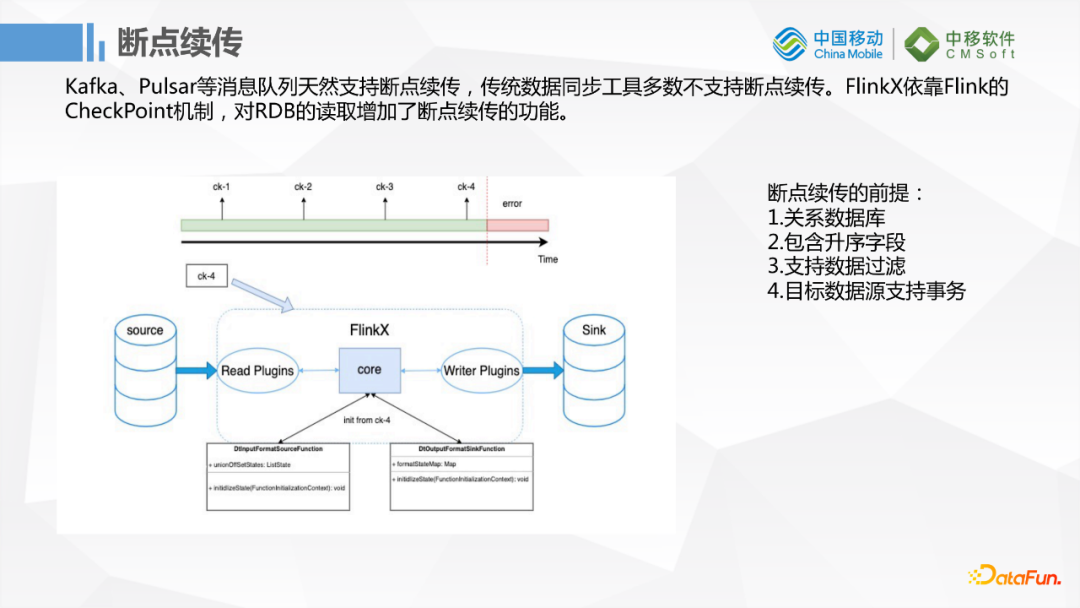
首先一个很棒的功能是断点续传,当然这个断点续传不是针对消息队列来说的,因为消息队列天然支持断点续传。FlinkX依赖Flink的checkpoint机制,对RDB扩展了断点续传的功能。但是它有一个前提,首先是关系型数据库需要包含升序的字段,然后是需要支持数据的过滤,最后是需要支持事务。比如使用MySQL时如果需要断点续传,配置了这个功能后它会根据字段做一个取模,然后在数据搬运的过程中当前节点的数据会在checkpoint里面保存,当需要重新运行任务的时候它会取上一次失败的节点开始的那个点,因为它还需要根据保存失败的id的数据做一下过滤,最后再从那个节点重新开始运行任务,这样数据量比较大的时候会稍微节约一点时间。
2. 指标监控
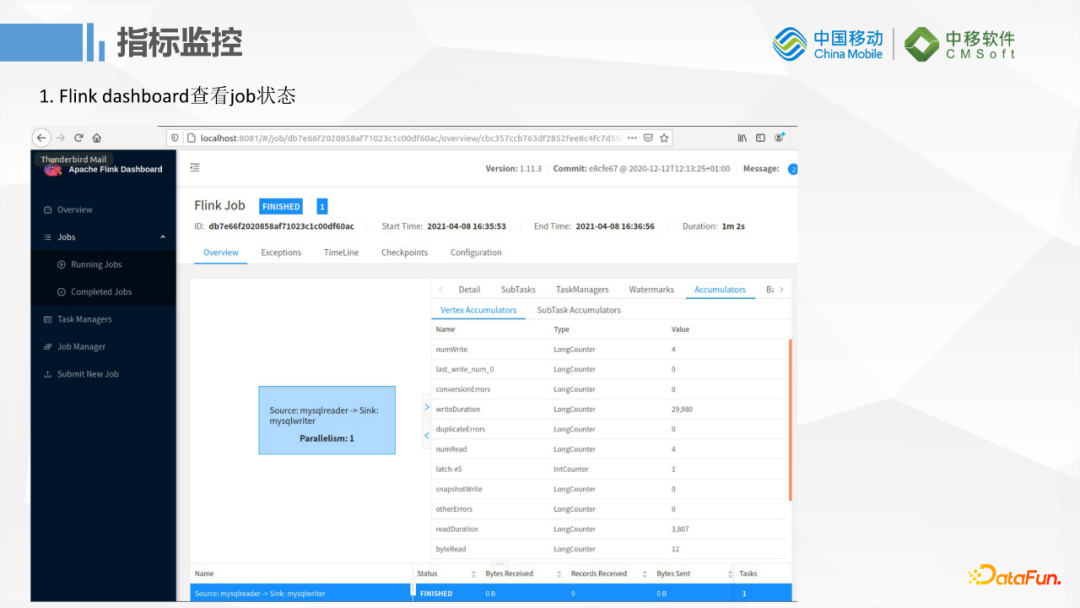
监控方面它会依赖Flink本身的监控功能,Flink内部有一些Accumulators和metric统计指标,如果把它运行在Flink上的话就可以通过Flink的DashBoard来查看Job的状态。
或者是把一些指标数据收集到Prometheus里面,例如基本的条数,统计的数据量和错误的数据量都可以通过Prometheus收集之后再通过Grafana这样的一些工具做展示。目前线上的这个功能还在开发中。
3. 错误统计和数据限制
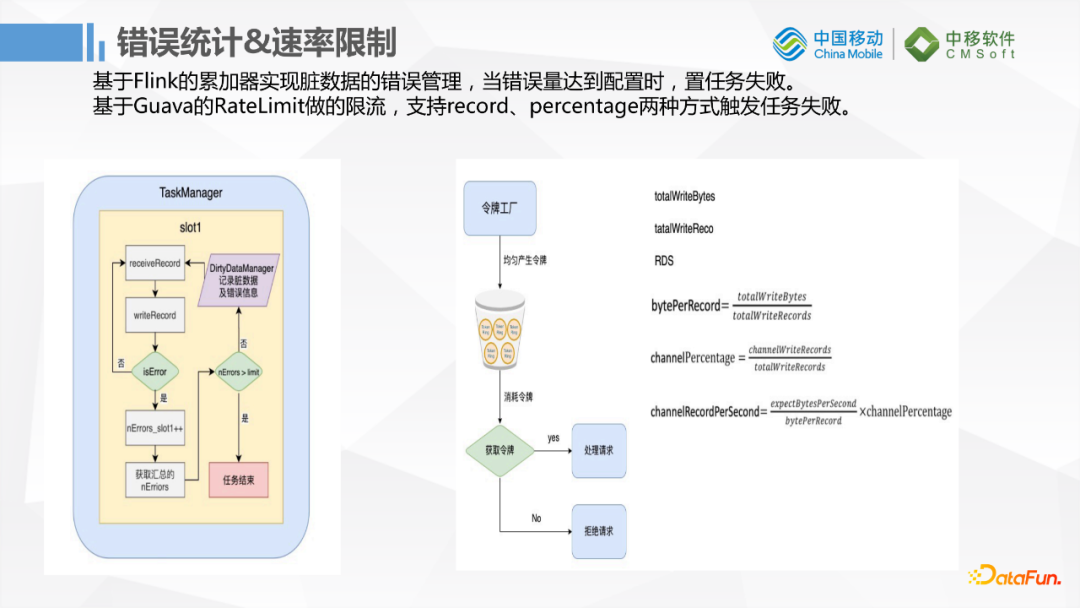
它还有一个比较好的功能是速率限制。当我们读取数据写入的时候,很多用户首先担心的问题是它会影响到生产库,因为多数企业的库可能没有主从策略,生产库是单实例运行的。如果这种搬运数据的任务影响到生产库的话用户基本上是不能接受的。所以做速率限制的功能对传统用户就非常友好。它的速率限制是基于Guava的RateLimit,根据令牌工厂生产令牌的方式做的速率限制,跟另外的漏斗算法稍微有一点差别。缺点是峰值还是会很高,因为它保证的是平均速率限制在某一个范围之内。
4. 插件式开发
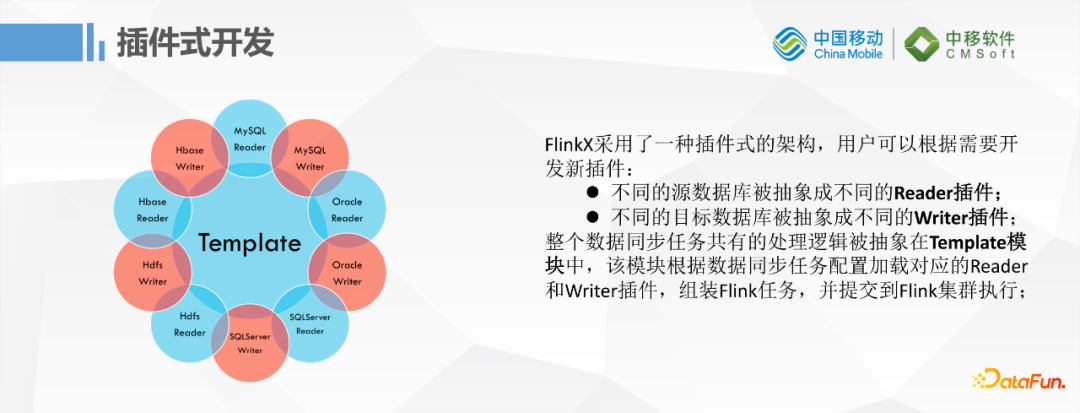
FlinkX的插件式开发模式,与Sqoop和DataX类似,不同的数据源都抽象成一个Reader插件和一个Writer插件,然后整个数据同步的任务和公有的逻辑就被抽象在一个统一的模块中。一个模块再根据同步任务的配置加载相应的Reader,Writer最后组装成Flink任务,并提交到Flink集群去执行。

我们可以简单看一下任务配置,都是基于JSON的方式配置基础的Reader,Writer,然后是一些综合的错误条数限制和速率限制,这边的代码就会根据配置文件通过Reader生成一个Flink Source,再通过Writer生成Sink,熟悉Flink代码的小伙伴对这块应该比较熟悉,其实就是Flink从Source端读数据然后往Sink端写数据,相对来说比较简单。
三、云上入湖改造
云上入湖这里我们做了一些改造。
1. K8s

首先是K8S的改造,因为社区的1.11版本支持的是Local,Standalone,YARN Session,YARN Perjob的模式,对云原生方式的开发不是太友好。并且Flink原生的1.12版本已经支持K8S调度运行了,所以我们把基于FlinkX的1.11版本Flink升级到了1.12,让它原生就可以支持K8S运行,这样的话对我们任务的弹性扩缩容就更加友好,对入湖的任务资源隔离也比较友好,相互之间没有影响。这里也是基于Flink 1.12把里面的ApplicationClusterDeployer这部分代码做了一些简单的改造,来适配我们的一些系统。基本上是把K8S的一些配置组装一下,然后把FlinkX的一些Jar包的路径写进去,最后提交任务到我们的K8S集群。
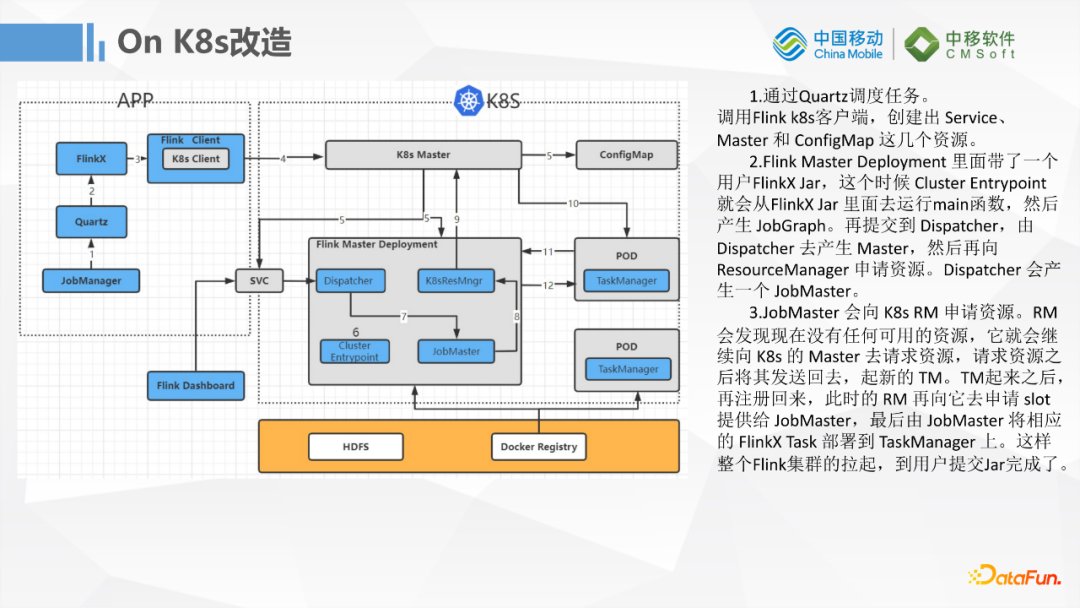
我们的JobManager会通过Quartz来做FlinkX任务的调度,然后通过Flink的客户端调用K8S的客户端,最终把任务提交到K8S上去执行。
2. Hudi写入
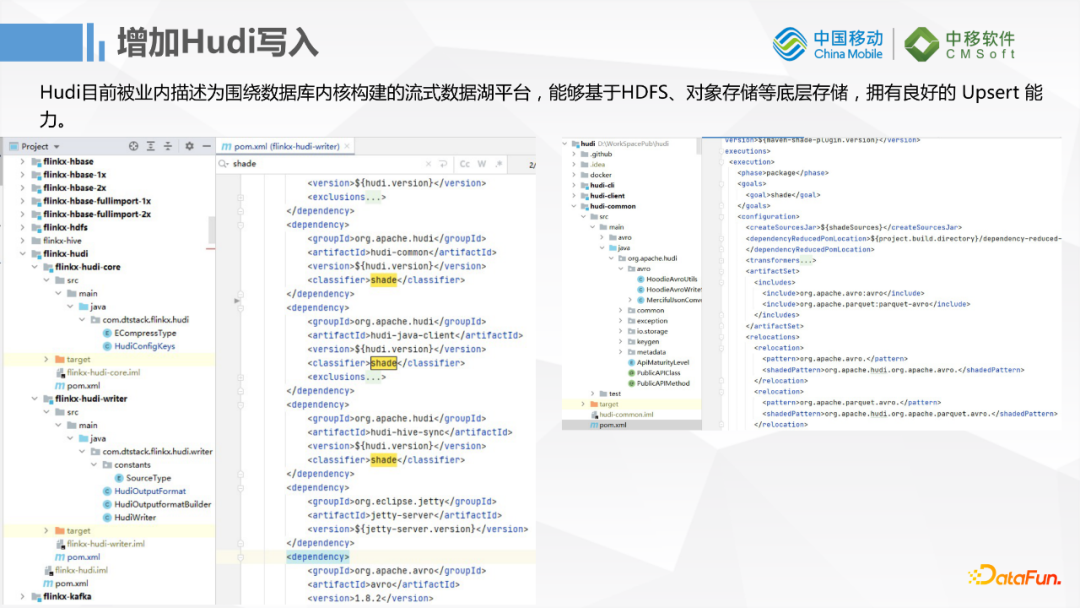
我们扩展了一个Hudi的插件,因为FlinkX里面插件非常多,我们这边会考虑到写HBase和写Hive之类的情况,开发过程中遇到了很多Jar包冲突的问题,所以我们给Hudi社区版0.09版本打了非常多的shade Jar,保证我们的线上运行没有冲突,主要是avro的版本依赖问题。我们这边HBase和Hive依赖的avro版本跟Hudi的版本会不一致,版本兼容性之间有一些问题。
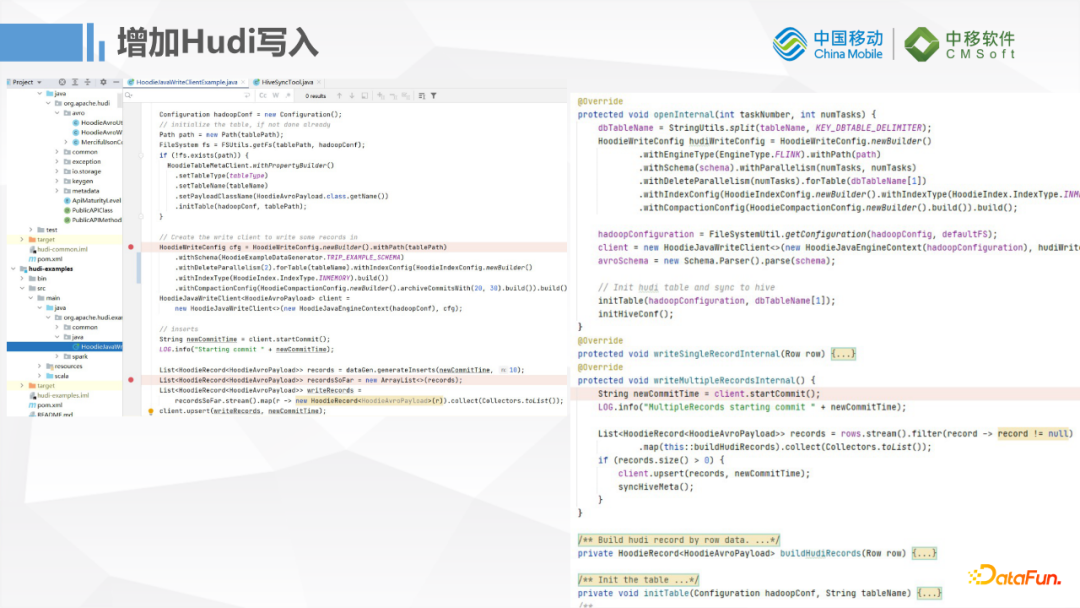
这里看一下Hudi插件预览的样子,参考了Hudi源码里面加了Client的Example,也就是先加载Hudi配置,初始化表和Hive的配置,最后通过Kafka做实时数据写入。目前只提供Upsert的支持,后期考虑MySQL Binlog支持的话会增加Delete功能的支持。
3. 日志
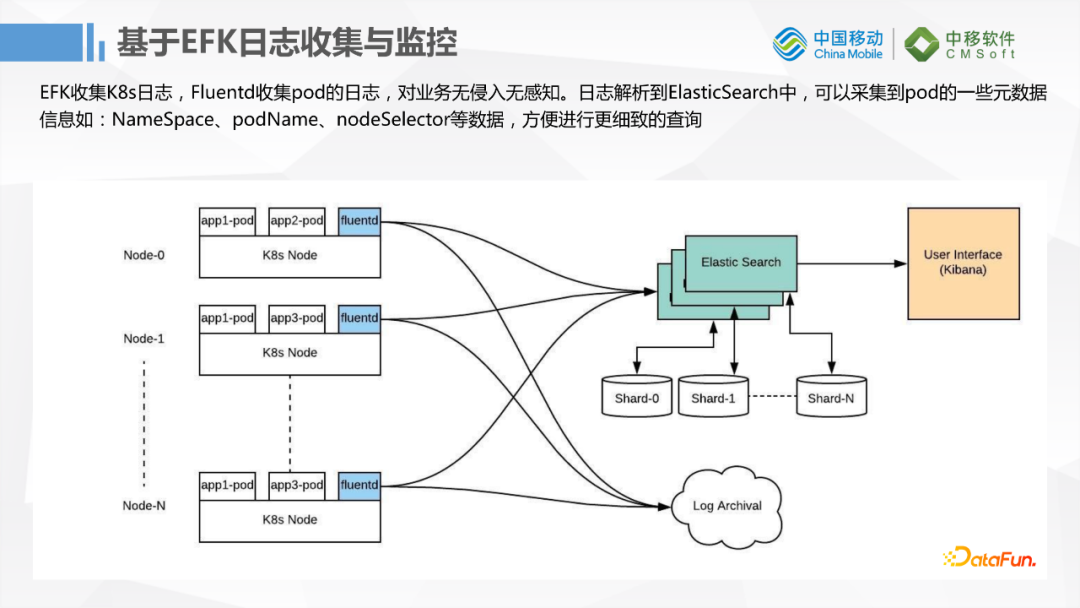
还有一个改造可能不属于FlinkX,就是我们的日志功能,基于K8S Fluentd的一个小工具,EFK这套系统去收集日志。整个过程对我们的业务是没有入侵,没有感知的,最终我们的日志解析收集到ES中。Fluentd跟K8S结合的比较好的地方就是它可以采集到NameSpace,PodName, NodeSelector等数据,为后面查询错误日志提供了方便。
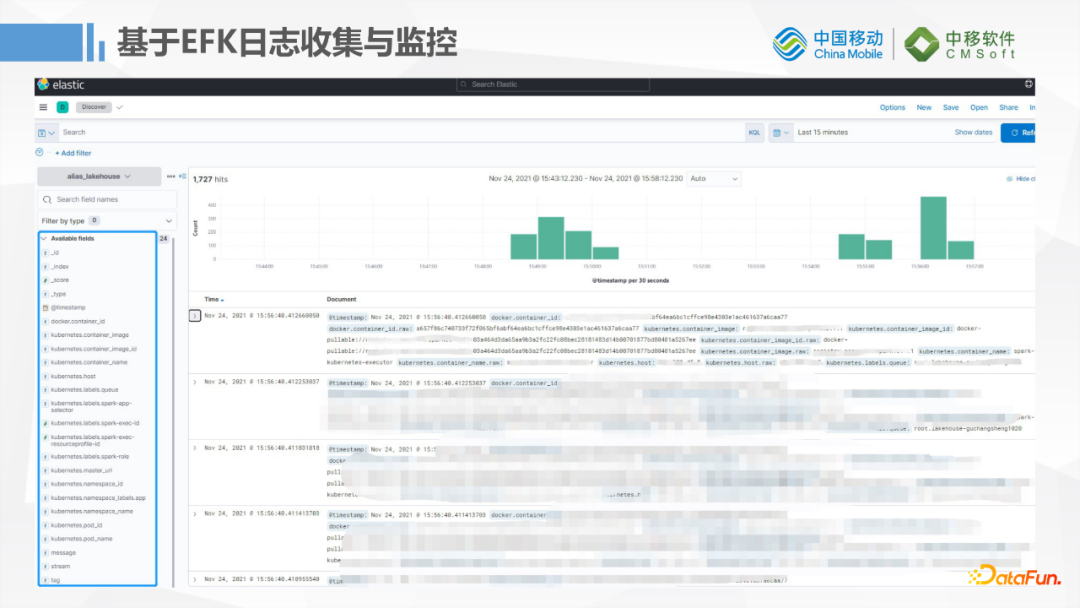
上图就是使用Fluentd收集到的一些Pod的日志,左侧这边看到有很多K8S的元数据信息,例如ContainerName,镜像,NodeSelector,PodId等等这些数据。当然这个Kibana是我们留给后端开发用来排错的,目前给前端用户展示的还是把原始日志数据做了汇总之后,通过页面对应到任务上去查看。
四、展望
最后一部分是我们对于FlinkX的一些展望,先来看一下FlinkX V1.12的一些新特性:
与FlinkStreamSQL融合;
增加了transformer算子,支持SQL的转换;
插件向Flink社区看齐,不再区分Reader、Writer,统一命名成Connector,遵循Flink社区的规范,这样统一以后FlinkX就可以和社区保持兼容。理论上在使用FlinkX时可以使用Flink的原生Connector。Flink也可以调用FlinkX的Connector,这样的话FlinkX就可以做成插件放到Flink的集群里面,后面对于做湖仓一体或者Server开发就会非常的方便。
数据结构优化
支持二阶段提交、数据湖Iceberg和提交kubernetes
对于数据入湖来说,目前的FlinkX有一个缺点,就是只支持结构化数据的传输,还不能原生支持二进制文件的同步。如果数据要入湖,会有很多媒体文件,Excel、Word、图片、视频等等,这一块后期可能会自己去开发一些插件支持。
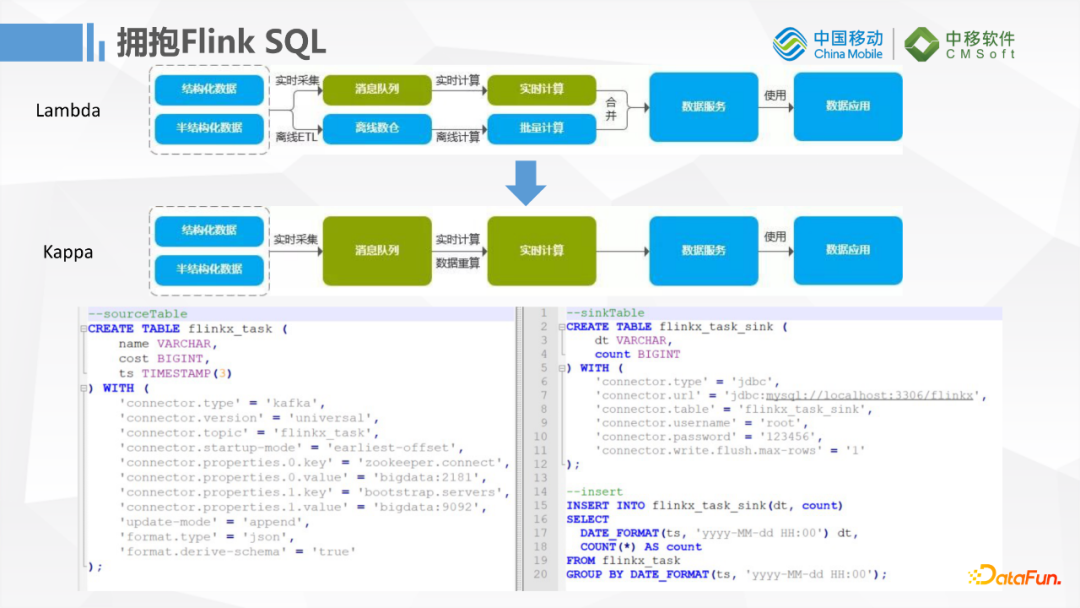
升级到1.12后对FlinkSQL的支持会更加友好,这样传统的Lambda升级到Kappa架构,对于习惯写SQL做数据抽取转换的用户就非常友好,基本上可以靠一条SQL去实现流批一体化的任务,进一步降低开发维护的难度。我们可以从Kafka读取一条数据,中间做一些简单的转换后写到MySQL。我们后面数据库肯定要支持越来越多的实时数据写入,所以后期用SQL的方式开发这些任务就会更加便捷。
五、问答环节
Q:一般情况下FlinkX作业分配多少CPU和内存资源?
A:我们这边一般定义一个Slot是一核2g,普通的一个MySQL到MySQL这样的一个任务默认三个并发,用户更多的是担心我们的速度太快影响生产库,目前自定义还没有开放,后面具体的并发度会开放可以让用户自定义,目前Slot是固定的一核2g。
Q:现在流批一体的应用范围广吗?
A:我认为是挺广的,对于移动集团的一些项目,其实我们在适配他们的一些场景,主要还是基于消息队列和MySQL的Binlog。我们之前遇到的用户他在阿里云上订购了结构化数据,现在他想上移动云,但是他的生产库又不能断,他想做这样的一个迁移,这就是需要流批一体的场景。他需要先做一个批的任务,把他历史的数据搬运过来,再基于他的Binlog增量订阅,实时同步更新他的增量数据,这就是一个很典型的传统用户的场景。再一个就是有一些大批量数据走Kafka,原始数据还是需要落一份到HDFS,但是需要实时的做一些汇总,这也算是一个比较典型的场景,会做流批一体的任务,我目前主要是针对这两种场景做一些开发。
Q:FlinkX相较于FlinkCDC优势在哪里?
A:单说FlinkCDC他只是支持结构化数据增量更新,FlinkX如果是1.12版本它跟FlinkCDC之间的插件一些是共用的,然后他相较于原生的FlinkCDC做了一些扩展,特别是它会支持很多国产的数据库,比如达梦,FlinkCDC目前还不支持。任务配置方式的话,FlinkX是基于JSON的,对于写Flink代码的的普通用户更加友好。总结一句话就是扩展了更多插件。
Q:流批一体真的会减少机器的预算吗?计算资源减少了还是存储资源减少了?
A:存储会减少一点,计算可能不会减少,因为流批一体的话,是在用同一套代码维护批任务和流任务,中间的数据如果没有必要的话是不用落地的,这块肯定是节省存储资源的。计算资源跟原来分开跑的话可能是相当的,不会有明显的减少,主要是节省了存储资源。
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack/Taier