这里写目录标题
- Deep Few-Shot Learning for Hyperspectral Image Classification
- Introduction
- Method
- Experiment
Deep Few-Shot Learning for Hyperspectral Image Classification
我看的第一篇 few-shot learning 文章,记录一下,看看能不能说明few-shot 是什么东西,难道只是样本少,没有自己独特的学习方法吗?
Introduction
背景介绍的逻辑链条:
The categories of HSI classification methods: supervised classification, unsupervised classification, and semi-supervised classification.
Supervised classification -> The curse of dimensionality ->
Feature extraction -> The problem of lacking labeled samples -> Semi-supervised algorithms
Deep learning -> The lack of labeled samples -> A pixel-pair method -> A semi-supervised CNN -> few shot learning
few shot learning
- Matching network
- Meta-learning approach
- Prototypical networks
The proposed method
a deep few-shot learning - DFSL:
- S-CNN to learn a metric space + Euclidean Distance = an embedding function(用了1个样本)
- To extract features of all samples in the testing data set by means of a pretrained D-Res-3-D CNN(用5个样本)
- SVM -> To classify the testing samples
注意:用额外的高光谱数据集训练出一个网络,20-way 1-shot (下面会有提及这是什么),然后利用5个训练样本配合19个测试样本,在各自的样本上训练,最后用SVM分类。
补充:few-shot learning 的一种学习模式
N-way K -shot 问题: 在训练阶段,会在训练集中随机抽取 N 个类别,每个类别 K 个样本(总共 N*K 个数据),再从这 N 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象。即要求模型从 N*K 个数据中学会如何区分这 N 个类别,这样的任务被称为 N-way K-shot 问题。
比如:10个类别,抽取5个类别出来,每个类别抽取一个,再从这个5个类中剩余的样本中抽取m个样本作为预测,就构成了5 way 1 shot 问题。这好像只是一种学习方法,训练所有的类别,预测所有的类别,只要能训练的好,也不是不行。一般通过不断学习这些子任务,就能够学到一个好的模型。详细地,请参考上面的链接。
Method
方法部分无需多言,只是这里的loss function 直接利用分布函数得出来,感觉很难理解。应该由概率密度函数得出来吧。
Experiment
试验:对比一下在这里的试验和作者在其它论文中的试验。都是5个训练样本,差别不大,可以接受。
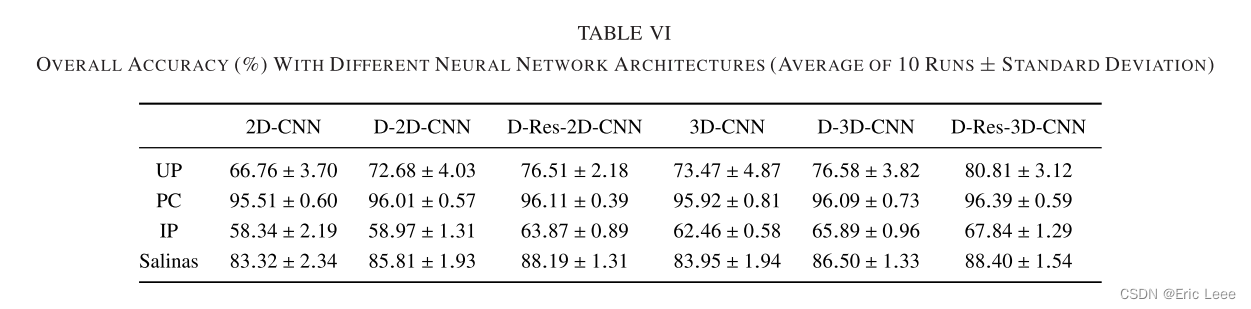
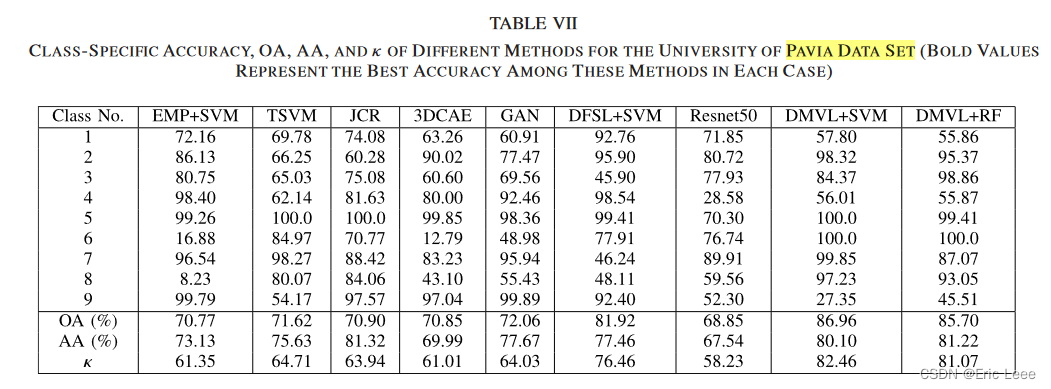
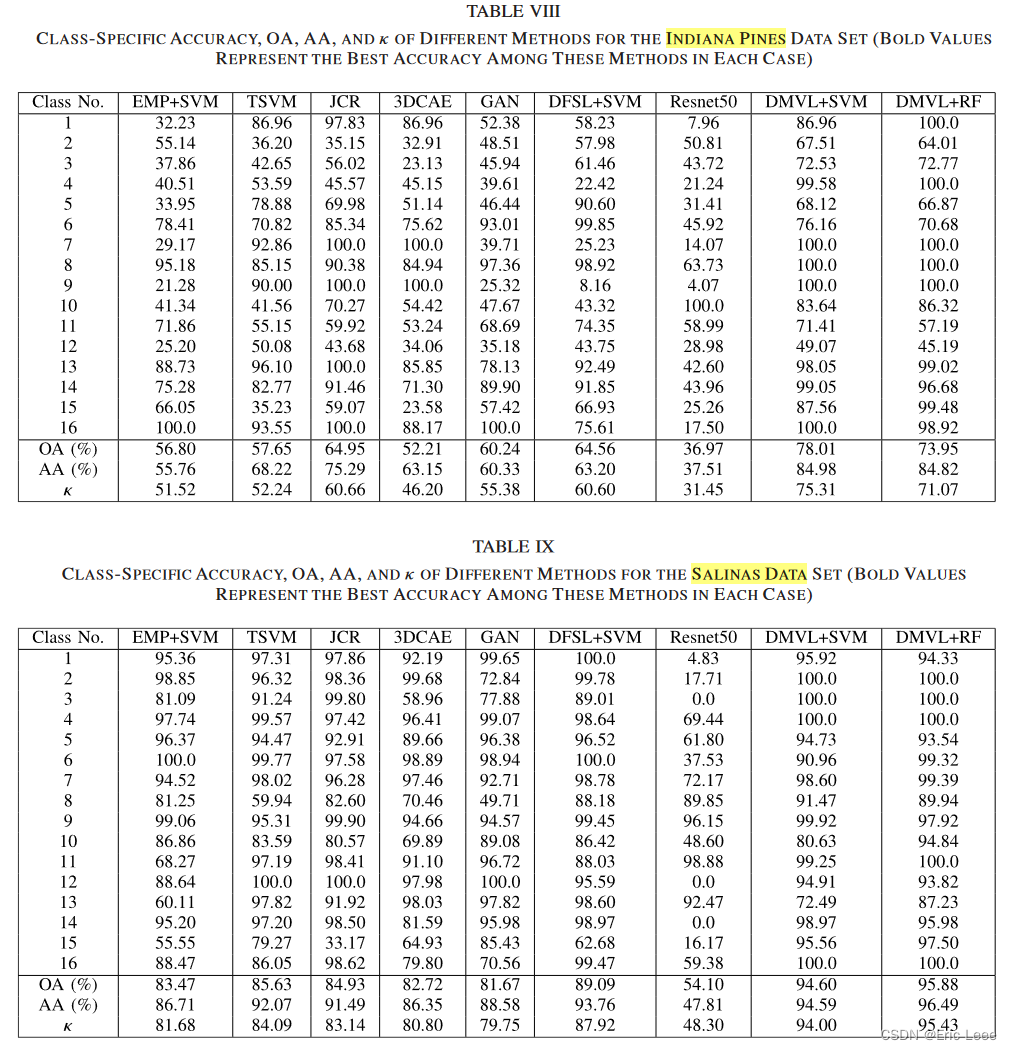
但是有很多疑问。
1:两次训练都训练了多少轮?10000?
2:两次训练都是用了多少类别?采用了一样的模式,只是数据集变了吗?
3:如果每次都要选择样本,那不是需要大量的标签吗?
感觉看完了和没有看一样。