定义
什么是Stream流,Java doc中是这样写的
A sequence of elements supporting sequential and parallel aggregate operations
翻译一下就是一个支持顺序和并行聚合操作的元素序列。
可以把它理解成一个迭代器,但是只能遍历一次,就像是流水一样,要处理的元素在流中传输,并且可以在流中设置多个处理节点,元素在经过每个节点后会被节点的逻辑所处理。比如可以进行过滤、排序、转换等操作。
Stream流的使用可以分为三个步骤:
- 数据源,创建流
- 中间操作,可以有多个,生成一个新的流
- 终端操作,只能有一个,放在最后,代表流中止。
Stream流有几个特点:
1、Stream流一般不会改变数据源,只会生成一个新的数据流。
2、Stream流不会存储数据,只会根据设置的操作节点处理数据。
3、Stream流是延迟执行的,只有在调用终端操作后才会进行流转。
看一下Stream的结构

使用
数据源生成流
- 如果是集合的话,可以直接使用
stream()创建流。 - 如果是数组的话,可以使用
Arrays.stream()或Stream.of()来创建流。
// 集合生成流
List<String> strList = new ArrayList<>();
Stream<String> stream = strList.stream();
//数据生成流
String[] strs = new String[]{"1","2","3"};
Stream<String> stream1 = Arrays.stream(strs);
Stream<String> stream2 = Stream.of(strs);
中间操作
在上边Stream定义中,返回是Stream类型的大多数都是中间操作,入参大多数都是函数式编程,不熟悉的可以看看这篇Java函数式编程。常用的中间操作有
- 过滤操作
filter()
Arrays.stream(strs).filter(s -> s.equals("1"));
- 排序操作
sorted()
Arrays.stream(strs).sorted();
- 去重操作
distinct()
Arrays.stream(strs).distinct();
- 映射操作,将流中元素转换成新的元素
mapToInt()转换成Integer类型mapToLong()转换成Long类型mapToDouble()转换成Double类型map()自定义转换类型,这是一个使用频率非常高的方法。
//将字符串转换成Integer
Arrays.stream(strs).mapToInt(s -> Integer.valueOf(s));
//将字符串转换成Long
Arrays.stream(strs).mapToLong(s -> Long.valueOf(s));
//将字符串转换成Doublde
Arrays.stream(strs).mapToDouble(s -> Double.valueOf(s));
//自定义转换的类型
Arrays.stream(strs).map(s -> new BigDecimal(s));
中间操作是可以有多个的,我们可以根据业务功能组合多个中间操作,比如求数组中字符串包含s的字符串长度排序
Arrays.stream(strs).filter(e->e.contains("s")).map(String::length).sorted();
终端操作
终端操作,表示结束流操作,是在流的最后,常用的有
- 统计
count()
long count = Arrays.stream(strs).count();
// count=3
- 获取最小值
min()
// 将字符串转换成Interger类型再比较大小
OptionalInt min = Arrays.stream(strs).mapToInt(Integer::valueOf).min();
System.out.println(min.getAsInt());
// 1
- 获取最大值
max()
OptionalInt max = Arrays.stream(strs).mapToInt(Integer::valueOf).max();
System.out.println(max.getAsInt());
// 3
- 匹配
anyMatch(),只要有一个匹配就返回trueallMatch(),只有全部匹配才返回truenoneMatch(),只要有一个匹配就返回false
boolean all = Arrays.stream(strs).allMatch(s -> s.equals("2"));
boolean any = Arrays.stream(strs).anyMatch(s -> s.equals("2"));
boolean none = Arrays.stream(strs).noneMatch(s -> s.equals("2"));
// all = false
// any = true
// none = false
- 组合
reduce()将Stream 中的元素组合起来,有两种用法Optional reduce(BinaryOperator accumulator)没有起始值只有运算规则T reduce(T identity, BinaryOperator accumulator),有运算起始值和运算规则、返回的是和起始值一样的类型
Integer[] integers = new Integer[]{1,2,3};
Optional<Integer> reduce1 = Arrays.stream(integers).reduce((i1, i2) -> i1 + i2);
Integer reduce2 = Arrays.stream(integers).reduce(100, (i1, i2) -> i1 + i2);
// reduce1.get() = 6
// reduce2 = 106
- 转换
collect(),转换作用是将流再转换成集合或数组,这也是一个使用频率非常高的方法。
collect()一般配合Collectors使用,Collectors是一个收集器的工具类,内置了一系列收集器实现,比如toList()转换成list集合,toMap()转换成Map,toSet()转换成Set集合,joining()将元素收集到一个可以用分隔符指定的字符串中。
String[] strs = new String[]{"11111", "222", "3"};
//统计每个字符串的长度
List<Integer> lengths = Arrays.stream(strs).map(String::length).collect(Collectors.toList());
String s = Arrays.stream(strs).collect(Collectors.joining(","));
// lengths=[5,3,1]
// s = 11111,222,3
合理的组合Steam操作,可以很大的提升生产力
原理

Stream的实现类中,将Stream划分成了Head、StatelessOp和StatefulOp,Head控制数据流入,中间操作分为了StatelessOp和StatefulOp。
StatelessOp代表无状态操作:每个数据的处理是独立的,不会影响或依赖之前的数据。像filter()、map()等。
StatefulOp代表有状态操作::处理时会记录状态,比如后面元素的处理会依赖前面记录的状态,或者拿到所有元素才能继续下去等这样有状态的操作,像sorted()。
现在已下面代码为例,分析一下Stream的原理
list.stream()
.filter(e -> e.length() > 1)
.sorted()
.filter(e -> e.equals("333"))
.collect(Collectors.toList());
数据源生成流
首先,进入到list.stream()里
//Collection#stream
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
//StreamSupport#stream
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
将原数据封装成Spliterator,同时生成一个Head,将Spliterator放到Head中。

中间操作
接着分析中间操作.filter(e -> e.length() > 1)的代码
//ReferencePipeline#filter
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
返回的是一个无状态操作StatelessOp,查看StatelessOp的构造函数
// AbstractPipeline#AbstractPipeline
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
构造函数中有previousStage.nextStage = this;和this.previousStage = previousStage;,相当于将当前的StatelessOp操作拼接到Head后面,构成了一条双向链表。
再看后面的.sorted().filter(e -> e.equals("333")).limit(10),也会将操作添加到了双向链表后面。.sorted()在链表后面添加的是StatefulOp有状态操作。

终端操作
最后走到终端操作.collect(Collectors.toList())。进入到collect() 中
//ReferencePipeline#collect
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) {
A container;
if (isParallel()
&& (collector.characteristics().contains(Collector.Characteristics.CONCURRENT))
&& (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) {
container = collector.supplier().get();
BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator();
forEach(u -> accumulator.accept(container, u));
}
else {
container = evaluate(ReduceOps.makeRef(collector));
}
return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)
? (R) container
: collector.finisher().apply(container);
}
并发操作先不看,直接看container = evaluate(ReduceOps.makeRef(collector));,ReduceOps.makeRef()返回是TerminalOp,代表的是终端操作。

进evaluate()中
//AbstractPipeline#evaluate
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
先不管并行,进串行入evaluateSequential()中
//ReduceOps#evaluateSequential
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
makeSink()将返回一个Sink实例,并作为参数和 spliterator 一起传入最后一个节点(terminalOp)的 wrapAndCopyInto() 方法
//AbstractPipeline#wrapAndCopyInto
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
wrapSink()将最后一个节点创建的 Sink 传入,并且看到里面有个 for 循环。这个 for 循环是从最后一个节点开始,到第二个节点结束。每一次循环都是将上一节点的 combinedFlags 和当前的 Sink 包起来生成一个新的 Sink 。这和前面拼接各个操作很类似,只不过拼接的是 Sink 的实现类的实例,方向相反。

到现在整个流水已经拼接完成。真正的数据处理在copyInto()中。
//AbstractPipeline#copyInto
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
Sink中有三个方法:
begin:节点开始准备accept: 节点处理数据end: 节点处理结束
Sink与操作是相关的,不同的Sink有不同的职责,无状态操作的 Sink 接收到通知或者数据,处理完了会马上通知自己的下游。有状态操作的 Sink 则像有一个缓冲区一样,它会等要处理的数据处理完了才开始通知下游,并将自己处理的结果传递给下游。
比如filter这种无状态的操作,处理完数据会直接交给下游,而像sorted这种无有状态的操作在begin阶段会先创建一个容器,accept会将流转过来的数据保存起来,最后在执行 end方法时才正在开始排序。排序之后再将数据,采用同样的方式依次传递给下游节点。
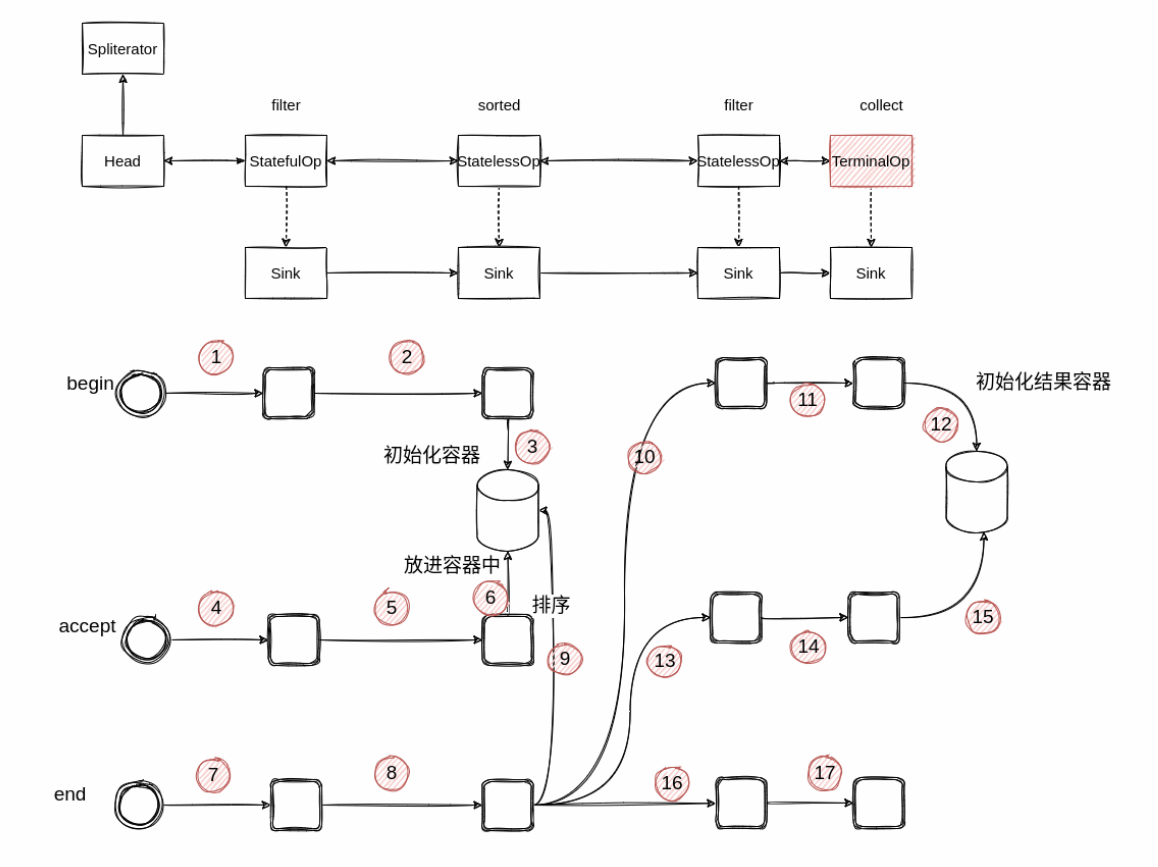
wrapAndCopyInto() 返回了 TerminalOps 创建的 Sink,这时候它里面已经包含了最终处理的结果。调用它的 get() 方法就获得了最终的结果。
Steam还可以支持并行流,把list.stream()换成list.parallelStream()即可使用并行操作。
并行过程中,构建操作链的双向链表是不变的,区别实在构建完后的操作
//AbstractPipeline#evaluate
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
这次进入到 evaluateParallel()中
//ReduceOps#evaluateSequential
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
ReduceTask继承自ForkJoinTask,Steam的并行底层用的是ForkJoin框架。