文章目录
- 表过大
- 深度分页
- count(*) 与 count(列名)
- 唯一索引
- 分库分表
- 只分库不分表
- 不分库只分表
- 分库也分表
- 查询分离
- 使用方法
- 查询分离的适用场景
- 冷热分离
- 适用场景
- 实现方案
- 数据库连接池优化
- 主键无序
- buffer pool 太小
- MySQL频繁抖动的性能优化
- 原因
- 解决
表过大
历史数据进行归档
深度分页
- 合理
建表,避免 大表的产生 - 冷热 数据分离
- 分库分表
- 避免跳转,比如 跳到第1000页,引发深度分页
限制 最大分页数- 数据更新 不频繁,可以放入缓存!!!
count(*) 与 count(列名)
count(*) 不会忽略null
count(列名) 会忽略null
唯一索引
创建唯一索引的字段,不能为NULL 否则 唯一索引失效
逻辑删除的表,不方便建 唯一索引
逻辑删除表加个字段:deleteID 默认值为1
逻辑删除时,给deleteID设为当前的主键ID
把 name,model,deleteStatus,deleteID四个字段同时做成唯一索引
任何一个字段
数值不同代表不是相同的数据, 可以保证数据唯一性
分库分表
只分库不分表
当数据库的读或者 写的QPS过高,导致数据库连接不足,考虑分库,增加 数据库实例的方式,提供更多的数据库连接提升系统并发度
不分库只分表
当单表数据量非常大,因为并发不高,数据库的连接可能还够,但存储和查询性能遇到瓶颈,考虑水平分表,将数据 拆分到多张表中,减少单表的数据量
分库也分表
- 数据库的读或者 写的QPS过高,导致数据库连接不足
- 单表数据量非常大
查询分离
使用方法
写请求使用主库,mysql等关系型数据库
读请求查询读库,采用nosql 如:es、mongodb、hbase
写读数据库的同步,采用binlog订阅
查询分离的适用场景
当在业务中遇到一下情形,考虑使用查询分离
- 数据
量大 写请求效率ok读请求效率低- 所有数据任何时候可能被修改
- 希望
优化查询数据的性能
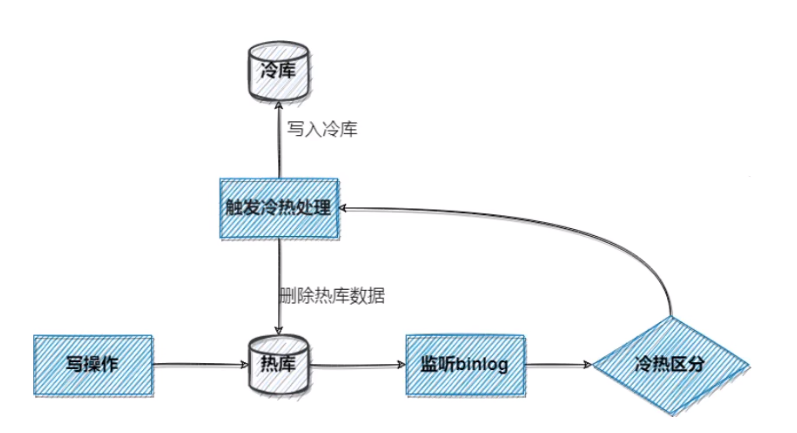
冷热分离
适用场景
- 主业务
响应延迟 太大 - 数据走到
终态,没有 更新的需求。只有读的需求,比如订单的完成状态 - 接受
新旧数据分开,比如 携程的订单查询30天之前 需要使用手机号
两个概念:
- 冷数据:
不允许更新,偶尔查询,响应时间无要求 - 热数据:被频繁更新,响应时间
有要求
实现方案
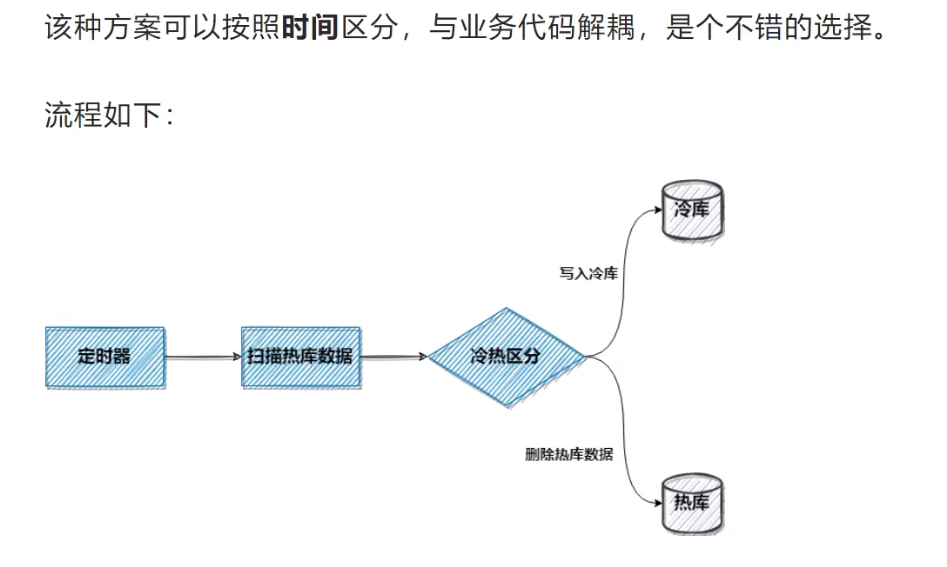
数据库连接池优化
连接数 = ((核心数 * 2) + 有效磁盘数)
主键无序
导致页分裂,会去重新挪数据,影响性能
分布式id,每秒一个机器大概4000个id,跟时间线性相关的,如果时钟回拨会导致无序
高并发情况下可以先批量生成,再使用,根据业务情况估计
比如
每秒100万的id,内存挂掉,将id持久化,或者扔掉重新生成~影响也不大redis的自增id
buffer pool 太小
可以通过下面的命令查询到 buffer pool 的大小,单位是 Byte。
mysql> show global variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
1 row in set (0.01 sec)
mysql> set global innodb_buffer_pool_size = 536870912;
Query OK, 0 rows affected (0.01 sec)
mysql> show global variables like 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 536870912 |
+-------------------------+-----------+
1 row in set (0.01 sec)
怎么知道 buffer pool 是不是太小了?
这个我们可以看 buffer pool 的缓存命中率
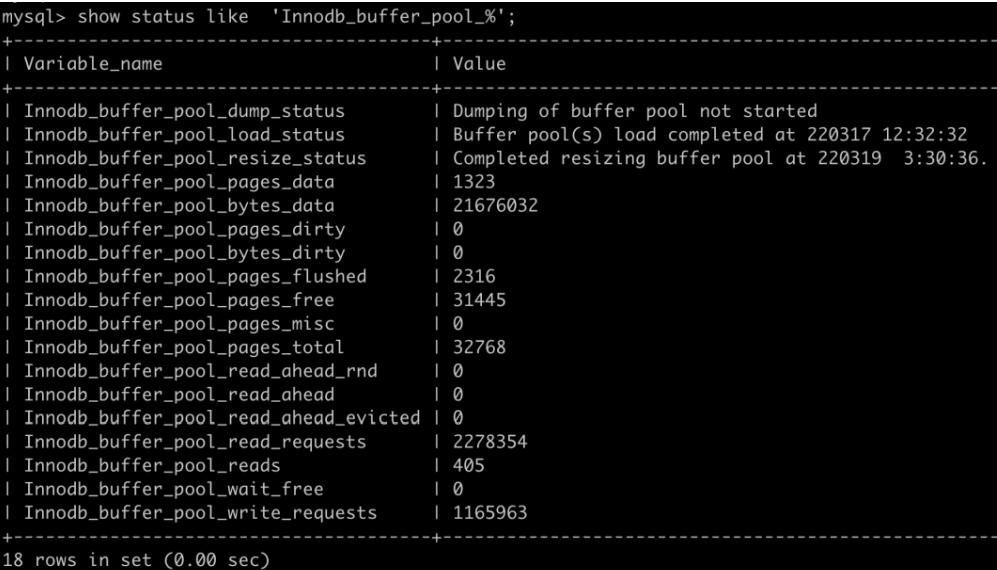
查看 buffer pool 命中率
show status like 'Innodb_buffer_pool_%';
可以看到跟 buffer pool 有关的一些信息。
Innodb_buffer_pool_read_requests 表示读请求的次数。
Innodb_buffer_pool_reads 表示从 物理磁盘中 读取数据的请求次数。
所以 buffer pool 的命中率就可以这样得到:
buffer pool 命 中率 =
1 - (Innodb_buffer_pool_reads/Innodb_buffer_pool_read_requests) * 100%
比如我上面截图里的就是,1 - (405/2278354) = 99.98%。可以说命中率非常高了。
一般情况下 buffer pool 命中率都在 99% 以上,如果低于这个值,才需要考虑加大innodb buffer pool的大小
MySQL频繁抖动的性能优化
原因
在DB里执行查询或更新语句时,可能SQL语句性能会莫名抖动,根本原因:
- BP缓存页都满了,此时执行一个SQL查询大量数据,一下
将大量缓存页flush到磁盘,刷磁盘太慢,导致你的查询语句执行就很慢
因为你必须 等大量缓存页都flush到磁盘,才能执行查询 从磁盘 将你所需数据页加载到BP缓存页
- 执行更新语句时,
redo log在磁盘上的所有文件都写满了
此时需要回到第一个redo log文件覆盖写,覆盖写时可能涉及到第一个redo log文件里有很多redo log日志对应的更新操作改动了缓存页,那些缓存页还没刷盘,就必须把它们刷盘了,才能执行更新语句,而你这一等待,必然会导致更新执行的很慢
所以上述两个场景导致的大量缓存页flush到磁盘,就会导致莫名SQL性能抖动。
解决
假设 SSD能承载的随机 I/O 600 次/s,结果你把数据库的 innodb_io_capacity就设为300,即刷盘时随机I/O最多执行300次/s,那你速度就还是很慢啊,根本没压榨完SSD随机I/O性能
所以推荐对DB部署机器的SSD能承载的最大随机I/O速率做个测试,fio工具常用来 测试磁盘最大随机I/O速率
即MySQL性能随机抖动问题,关键就是:
将 innodb_io_capacity 设为SSD 固态硬盘的IOPS,让他刷缓存页尽量快
同时设置 innodb_flush_neighbors 为0,让他每次 别刷临近缓存页,减少要刷缓存页的数量







![[附源码]java毕业设计新能源汽车租赁管理系统](https://img-blog.csdnimg.cn/758cd49a6d9d4e5f981fcc4b93b28195.png)