目录
一、树的存储结构
1、双亲表示法(顺序存储):
2、孩子表示法(顺序+链式)
3、孩子兄弟表示法(链式存储)
二、树、森林的遍历
1、树的先根遍历
2、树的后根遍历
3、层序遍历(队列实现)
4、森林的遍历
三、二叉排序树
1、二叉排序树定义
2、二叉排序树的操作
四、平衡二叉树
编辑1、平衡二叉树定义
2、平衡二叉树的插入
五、哈夫曼树
1、哈夫曼树定义
2、哈夫曼树的构造(重点)
3、哈杜曼编码(重点)
一、树的存储结构

1、双亲表示法(顺序存储):
- 每个结点中保存指向双亲的指针
//数据域:存放结点本身信息。
//双亲域:指示本结点的双亲结点在数组中的位置。
#define MAX_TREE_SIZE 100 //树中最多结点数
typedef struct{ //树的结点定义
ElemType data;
int parent; //双亲位置域
}PTNode;
typedef struct{ //树的类型定义
PTNode nodes[MAX_TREE_SIZE]; //双亲表示
int n; //结点数
}PTree;
增:新增数据元素,无需按逻辑上的次序存储;(需要更改结点数n)
删:(叶子结点):
- ① 将伪指针域设置为-1;
- ②用后面的数据填补;(需要更改结点数n)
查询:
- ①优点-查指定结点的双亲很方便;
- ②缺点-查指定结点的孩子只能从头遍历,空数据导致遍历更慢;
优点: 查指定结点的双亲很方便
缺点:查指定结点的孩子只能从头遍历
2、孩子表示法(顺序+链式)
- 孩子表示法:顺序存储各个节点,每个结点中保存孩子链表头指针。
struct CTNode{
int child; //孩子结点在数组中的位置
struct CTNode *next; // 下一个孩子
};
typedef struct{
ElemType data;
struct CTNode *firstChild; // 第一个孩子
}CTBox;
typedef struct{
CTBox nodes[MAX_TREE_SIZE];
int n, r; // 结点数和根的位置
}CTree;
3、孩子兄弟表示法(链式存储)
typedef struct CSNode{
ElemType data; //数据域
struct CSNode *firstchild, *nextsibling; //第一个孩子和右兄弟指针, *firstchild 看作左指针,*nextsibling看作右指针
}CSNode. *CSTree;
二、树、森林的遍历
1、树的先根遍历
- 若树非空,先访问根结点,再依次对每棵子树进行先根遍历;(与对应二叉树的先序遍历序列相同)
void PreOrder(TreeNode *R){
if(R!=NULL){
visit(R); //访问根节点
while(R还有下一个子树T)
PreOrder(T); //先跟遍历下一个子树
}
}
2、树的后根遍历
- 若树非空,先依次对每棵子树进行后根遍历,最后再返回根节点;(与对应二叉树的中序遍历序列相同)
void PostOrder(TreeNode *R){
if(R!=NULL){
while(R还有下一个子树T)
PostOrder(T); //后跟遍历下一个子树
visit(R); //访问根节点
}
}
3、层序遍历(队列实现)
- 若树非空,则根结点入队;
- 若队列非空,队头元素出队并访问,同时将该元素的孩子依次入队;
- 重复以上操作直至队尾为空;
4、森林的遍历
- 先序遍历:等同于依次对各个树进行先根遍历;也可以先转换成与之对应的二叉树,对二叉树进行先序遍历;
- 中序遍历:等同于依次对各个树进行后根遍历;也可以先转换成与之对应的二叉树,对二叉树进行中序遍历;
三、二叉排序树
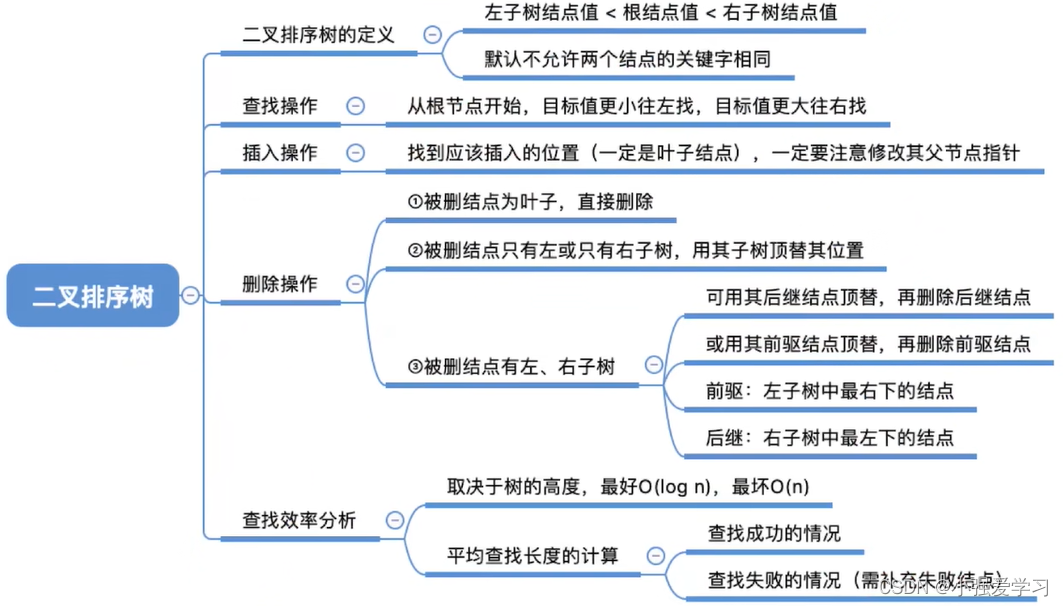
1、二叉排序树定义
二又排序树,又称二叉查找树(BST,Binary Search Tree)棵二叉树或者是空二叉树,或者是具有如下性质的二叉树:
- 左子树上所有结点的关键字均小于根结点的关键字;
- 右子树上所有结点的关键字均大于根结点的关键字。
- 左子树和右子树又各是一棵二叉排序树。
- 左子树结点值< 根结点值< 右子树结点值。
- 进行中序遍历,可以得到一个递增的有序序列。
2、二叉排序树的操作
【二叉排序树的查找】
- 若树非空,目标值与根结点的值比较:
- 若相等,则查找成功;
- 若小于根结点,则在左子树上查找,
- 否则在右子树上查找。
- 查找成功,返回结点指针;查找失败返回NULL
typedef struct BSTNode{
int key;
struct BSTNode *lchild, *rchild;
}BSTNode, *BSTree;
//在二叉排序树中查找值为key的结点(非递归)
//最坏空间复杂度:O(1)
BSTNode *BST_Search(BSTree T, int key){
while(T!=NULL && key!=T->key){ //若树空或等于跟结点值,则结束循环
if(key<T->key) //值小于根结点值,在左子树上查找
T = T->lchild;
else //值大于根结点值,在右子树上查找
T = T->rchild;
}
return T;
}
//在二叉排序树中查找值为key的结点(递归)
//最坏空间复杂度:O(h)
BSTNode *BSTSearch(BSTree T, int key){
if(T == NULL)
return NULL;
if(Kry == T->key)
return T;
else if(key < T->key)
return BSTSearch(T->lchild, key);
else
return BSTSearch(T->rchild, key);
}
【二叉排序树的插入操作】
- 若原二叉排序树为空,则直接插入结点;否则,
- 若关键字k小于根结点值,则插入到左子树,
- 若关键字k大于根结点值,则插入到右子树
//在二叉排序树中插入关键字为k的新结点(递归)
//最坏空间复杂度:O(h)
int BST_Insert(BSTree &T, int k){
if(T==NULL){ //原树为空,新插入的结点为根结点
T = (BSTree)malloc(sizeof(BSTNode));
T->key = k;
T->lchild = T->rchild = NULL;
return 1; //插入成功
}
else if(K == T->key) //树中存在相同关键字的结点,插入失败
return 0;
else if(k < T->key)
return BST_Insert(T->lchild,k);
else
return BST_Insert(T->rchild,k);
}
【二叉排序树的构造】
//按照str[]中的关键字序列建立二叉排序树
void Crear_BST(BSTree &T, int str[], int n){
T = NULL; //初始时T为空树
int i=0;
while(i<n){
BST_Insert(T,str[i]); //依次将每个关键字插入到二叉排序树中
i++;
}
}
【二叉排序树的删除】
先搜索找到目标结点:
- 若被删除结点z是叶结点则直接删除,不会破坏二叉排序树的性质
- 若结点z只有一棵左子树或右子树,则让z的子树成为z父结点的子树,替代z的位置
- 若结点z有左、右两棵子树,则令z的直接后继 (或直接前驱) 替代z,然后从二叉排序树中删去这个直接后继(或直接前驱),这样就转换成了第一或第二种情况。
查找长度--在查找运算中,需要对比关键字的次数称为查找长度,反映了查找操作时间复杂度
四、平衡二叉树
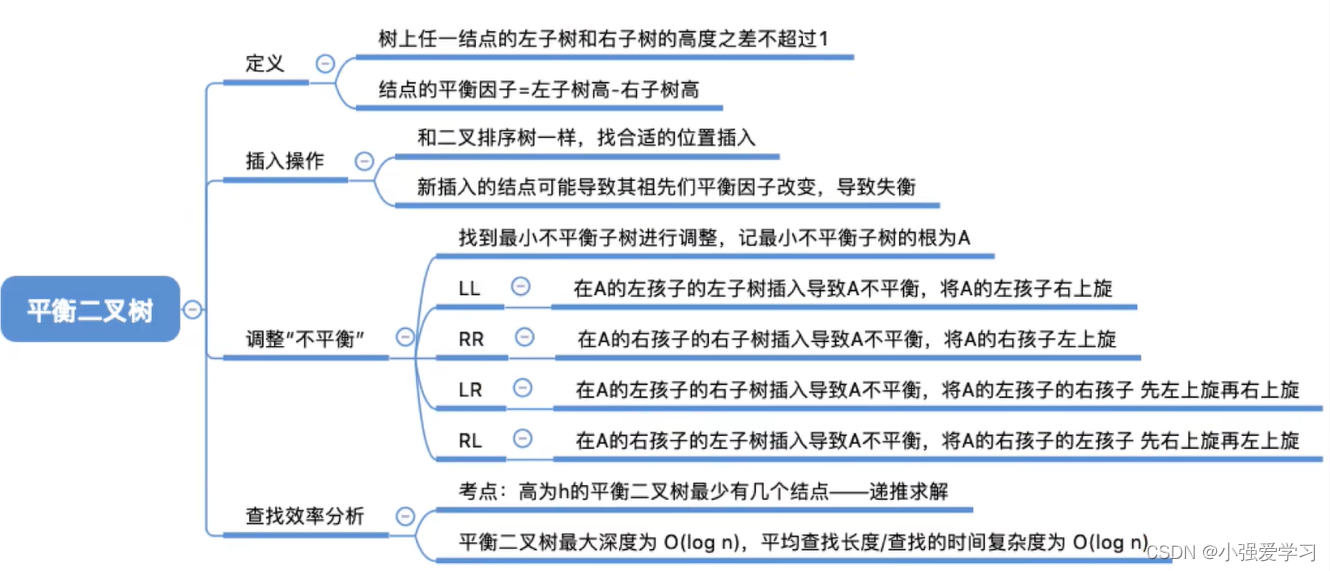 1、平衡二叉树定义
1、平衡二叉树定义
- 平衡二叉树(Balanced Binary Tree),简称平衡树(AVL树)--上任一结点的左子树和右子树的高度之差不超过1。
//平衡二叉树结点
typedef struct AVLNode{
int key; //数据域
int balance; //平衡因子
struct AVLNode *lchild; *rchild;
}AVLNode, *AVLTree;
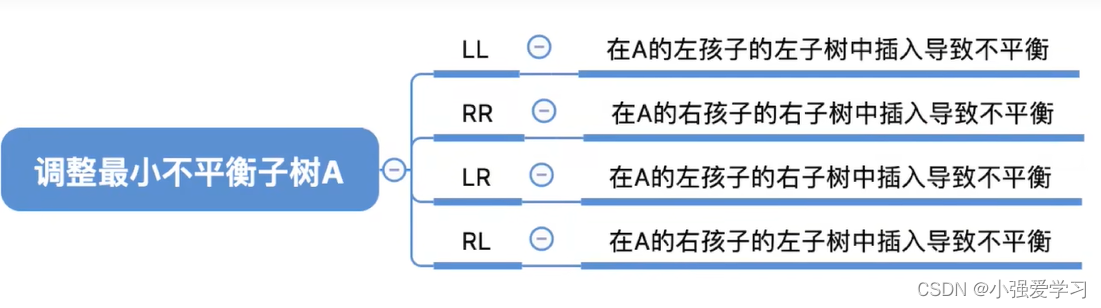
2、平衡二叉树的插入
- 每次调整的对象都是“最小不平衡子树“
- 在插入操作中,只要将最小不平衡子树调整平衡,则其他祖先结点都会恢复平衡。
五、哈夫曼树
1、哈夫曼树定义
- 结点的权:有某种现实含义的数值(如:表示结点的重要性等)
- 结点的带权路径长度:从树的根到该结点的路径长度(经过的边数)与该结点上权值的乘积。
- 树的带权路径长度:树中所有叶结点的带权路径长度之和 (WPL,Weighted Path Length)。
- 哈夫曼树的定义:在含有n个带权叶结点的二叉树中,其中带权路径长度(WPL) 最小的二叉树,也称最优二叉树。
2、哈夫曼树的构造(重点)
给定n个权值分别为w1, W2,..., w,的结点,构造哈夫曼树的算法描述如下:
- 1.将这n个结点分别作为n棵仅含一个结点的二叉树,构成森林F。
- 2.构造一个新结点,从F中选取两棵根结点权值最小的树作为新结点的左、右子树,并且将新 结点的权值置为左、右子树上根结点的权值之和。
- 3.从F中删除刚才选出的两棵树,同时将新得到的树加入F中
- 4.重复步骤2和3,直至F中只剩下一棵树为止。
- 每个初始结点最终都成为叶结点,且权值越小的结点到根结点的路径长度越大
- 哈夫曼树的结点总数为2n - 1
- 哈夫曼树中不存在度为1的结点。
- 哈夫曼树并不唯一,但WPL必然相同且为最优
3、哈杜曼编码(重点)
- 固定长度编码:每个字符用相等长度的二进制位表示
- 可变长度编码:允许对不同字符用不等长的二进制位表示
- 若没有一个编码是另一个编码的前缀,则称这样的编码为前缀编码
曼树得到哈夫曼编码--字符集中的每个字符作为一个叶子结点,各个字符出现的频度作为结点的权值,根据之前介绍的方法构造哈夫曼树 。